前言
上一篇简要介绍了CNN的启蒙和基本结构,
而近年来随着CNN的性能不断改进,
已经被成功应用于许多不同计算机视觉任务中,
并发展得比较成熟。
一、
图像分类
图像分类,这个是计算机视觉的基础任务,主要包含通用图像分类和细粒度图像分类,其中细粒度分类,需进一步从大类中进行细分类,比如识别狗是哪个品种。
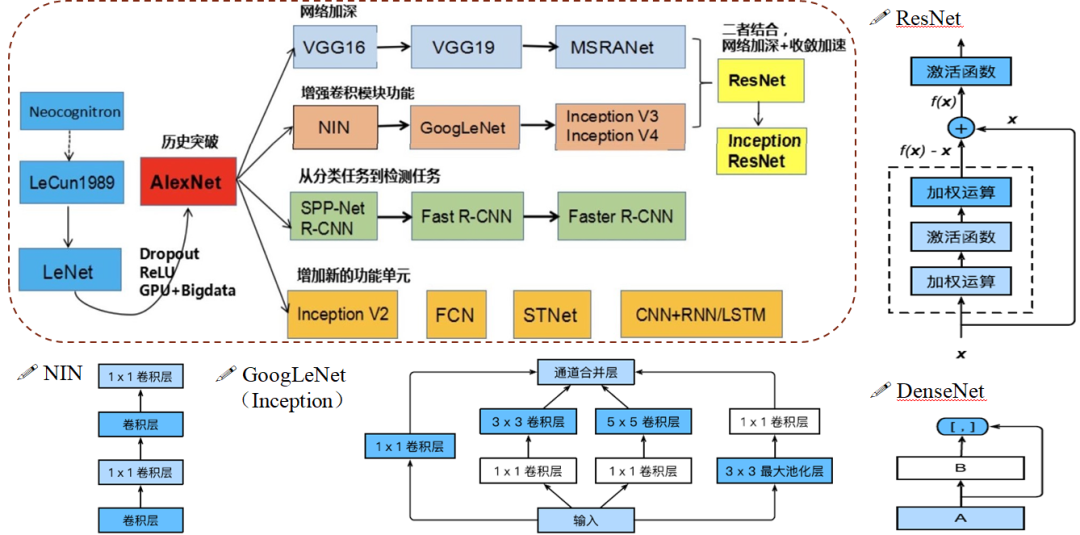
图 1
如图1所示,前面已经说到早期CNN解决图像分类的历史,当AlexNet在ImageNet比赛中一鸣惊人之后,许多研究者开始尝试各种改进,比如:1)增加网络深度的VGG、2)在卷积层之间嵌入1*1卷积微型网络并用全局平均池化来替代全连接的NIN(这样减少很多参数)、3)增加网络宽度以在同一层整合了不同感受野信息的GoogLeNet、4)针对模型深度增加后梯度消失问题利用跨层跳转方式的ResNet(残差网络)、5)直接将所有层连接起来的DenseNet(稠密连接网络)。另外,还有一些针对细分任务所改进的变体,比如针对检测任务设计的RCNN网络,针对时空预测任务设计的STNet,针对图像语义分割任务的FCN,使用多小卷积核来替换大卷积核的Inception V2。
二、
目标检测与识别
目标检测与识别应用广泛,比如人脸检测与识别、文本检测与识别。其首先检测出图中主体所在位置,用矩形框的两个对角线坐标或左上角坐标加矩形框长宽表示,同时时给出所检测主体的类别。目前深度学习在目标检测和识别方面主要有两大流派,即候选框和回归法。候选框流派主要使用某种算法获取主体所在的候选区域,然后再对这块区域进行分类;回归法则直接进行边界框回归与主体分类。
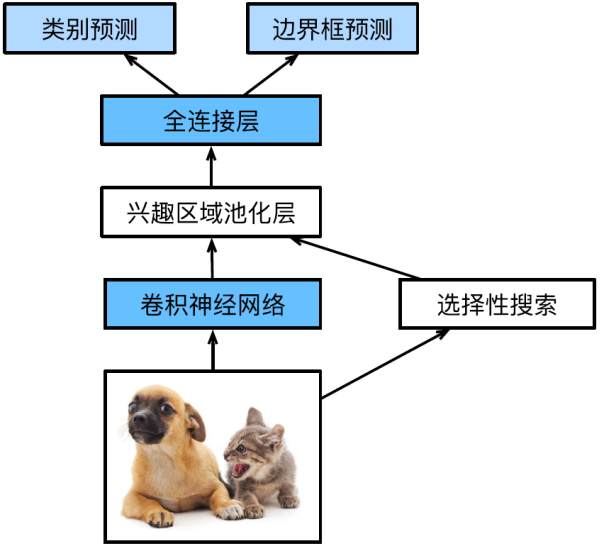
图 2
第一类方法中的区域/局部卷积神经⽹络(R-CNN)是将深度模型应用于目标检测的开创性工作之一,其中比较经典的Faster RCNN(如图2所示)首先使用一种称为候选区域提取网络(Region Proposal Network,RPN)的技术,将图像中需要处理和分类的区域局部化,基于CNN提取特征并扫描图像选取若干候选区域,标注二元分类和边界框,然后采用兴趣区域池化层(ROI Pooling)对提取的CNN特征图按候选区域池化,最后输入至全连接神经网络,进行精确地分类和回归。
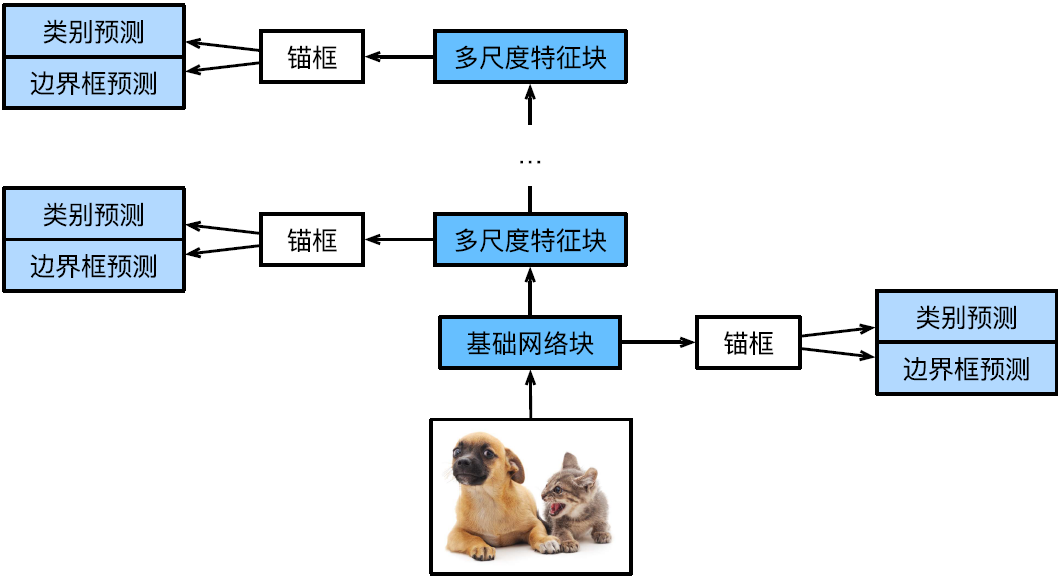
图 3
第二类方法中,比如图3所示的单发多框检测(SSD)模型,主要由一个基础网络块和若干多尺度特征块串联而成,在各层都进行分类和回归预测,从而实现多尺度预测,其中锚框是以每个像素为中心生成多个大小和宽高比不同的边界框,就需要考虑减少锚框个数,比如只均匀采样一小部分像素来锚框,其中预测类别时,采用N+1类别预测,当类别为0表示锚框只包含背景,最终还需通过NMS(非极大值抑制)筛选,即在几个部分重叠的预测框中只保留如图4所示的IOU(交并比)最高的那个。

图 4
三、
图像分割
图像分割需要把图像分成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术和过程。简单而言就是给定一张图片,预测图像中每一个像素所属的类别或者物体。从数学角度来看,图像分割是将数字图像划分成互不相交的区域的过程。近年的自动驾驶技术中也需要用到这种技术,车载摄像头探查到图像,后台计算机可以自动将图像分割归类,以避让行人和车辆等障碍。
根据不同的分割粒度,该任务可分为三类:
第一类,物体分割,是要求将图像的前景和背景进行分割,往往是根据图像的颜色纹理、几何形状等特征进行区域划分。这个时期的图像分割(大概2010年前),由于计算机计算能力有限,早期只能处理一些灰度图,后来才能处理RGB图,这个时期的分割主要是通过提取图片的低级特征,然后进行分割,涌现了一些方法:Ostu、FCM、分水岭、N-Cut等。这个阶段一般是非监督学习,分割出来的结果并没有语义的标注,换句话说,分割出来的东西并不知道是什么。
比如图5所示的图分割算法,首先将图像中的像素点转换为无向图<V, E>中的顶点,相邻像素间用实边连接。然后添加两个顶点S和T,分别对应前景和背景,每条相连的边都带一个非负的权值,然后通过网络流最小割找边集合里的前景、背景边的子集,使得两个子集内所有边的权值之和最小,从而找两个互补的割集分别给S和T,完成图像分割。
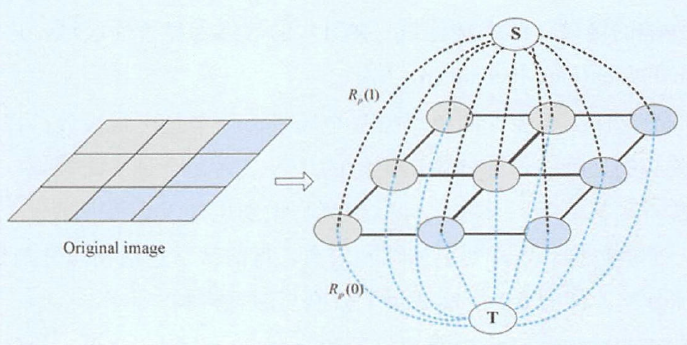
图 5
第二类,语义分割,就是关注如何在像素级上更精确地将图像分割成属于不同语义类别的区域。例如将人、车等目标从图像中分割出来,如果目标存在多种颜色,在分割中往往是分割成多个区域。其在普通分割的基础上,分类出每一块区域的语义(即这块区域是什么物体)。如把画面中的所有物体都指出它们各自的类别。2010年之后,随着计算能力的提高,人们开始考虑获得图像的语义分割,这里的语义目前是低级语义,主要指分割出来的物体的类别,这个阶段(大概是2010年到2015年)人们考虑使用机器学习的方法进行图像语义分割。
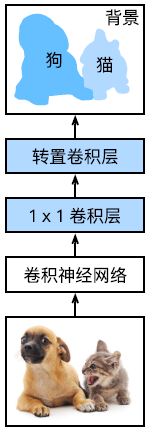
图 6
之后,随着全卷积网络FCN的提出,使得深度学习正式进入图像语义分割领域。如图6所示,FCN将最后的全连接层修改成转置卷积层,基于双线性插值法扩大中间变小的数据,然后卷积实现上采样,来得到所需大小的输出,即每个像素的分类。如图7(a)所示,之后提出来的SegNet,与FCN的最大差别就是,下采样阶段记录池化操作选出的最大值的相对位置,在上采样的过程中会依据该信息插值。再到如图7(b)所示的金字塔场景解析网络PSPNet,其主要考虑了通过使用多尺度池化得到不同尺度的特征图,然后连结起来得到多尺度特征,以此提取了更多的上下文信息以及不同的全局信息,来分类。

图 7
第三类,实例分割,不仅需要区分语义,还要区分不同的目标实例。比如一排车连在一起,语义分割的结果是整个一排车在一个分割区域里,而实例分割还要将车与车分割开来,即其在语义分割的基础上,给每个物体编号。
其中,如图8所示,径聚合网络PANet,是获得了COCO2017实例分割第一名的模型,它首先自顶向下将高层的强语义特征传递下来,对整个金字塔进行语义增强,又自底向上传递底层的强定位特征,具体是采用自适应特征池化来融合(逐像素相加或取最大)各个层次特征,最后补充一个小全连接层,捕捉不同层次的特征,分别预测ROI(感兴趣区域)所属类别、其矩形框坐标值,以及不同类别对应的像素分割标记矩阵。
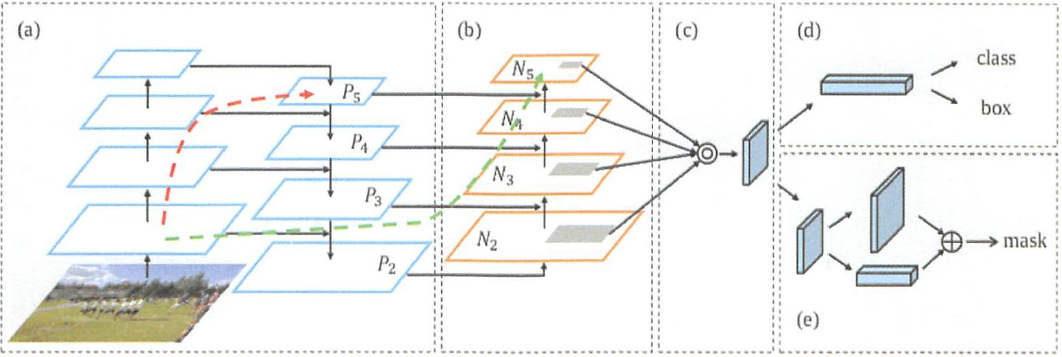
图 8
四、
图像说明
图像说明,是融合计算机视觉与自然语言处理的一项应用,例如为图像生成一个最适合图像的标题。其主要流程就是基本图像检测+字幕生成。图像检测通过前面所述的Faster R-CNN方法完成,字幕生成使用RNN/LSTM完成。
该应用比较有代表性的深度学习方法是NIC(Neural Image Caption, 神经图像字幕),如图9所示,它由提取图像特征的深层CNN和递归生成描述文本的RNN构成,可以生成高精度的图像标题。另外,这种组合图像和自然语言等多种信息进行的处理,属于多模态处理技术,也是近年备受关注的一个领域。

图9
五、
图像搜索
图像搜索,是为了从视觉信息丰富的海量图片中快速准确地搜索到用户所需要的图片,应用很广泛。传统一般是基于文本搜索图片,主要利用关键字对图像进行描述,然后进行关键字比对,比对成功后将结果返回给用户,其缺点是给图像标关键字需要人力标注,面对海量数据则费时费力,还面临增量的问题,且人为判断干扰因素难以估计。
而另一种方式是基于内容的搜索,是利用计算机对图像进行分析,提取出图像的特征,计算两两图像之间的相似度,再排序选出相似度高的几张图片输出。比如淘宝的“拍立淘“,谷歌/百度的以图搜图。该类方法包括图像描述和相似度计算及排序。特征描述传统采用特征描述算子,但需要人为设定。于是,基于CNN自动提取特征的优势,提出了很多深度学习方法。其中比较经典的是Siamese Network,其思想比较朴素,实质是一个二分类过程。如图10所示,其同时输入两种图片,用同一个CNN提取特征,得到对应的特征后,进行相似度计算,根据最后是否相似计算损失,训练模型。然后在应用阶段,可以预先用CNN提取数据库所有图像的特征向量,并保存在特征库中,最后当要搜索某张图片时,使用同样的特征提取方法提取,再与特征库中的特征作对比,达到图像搜索的效果。
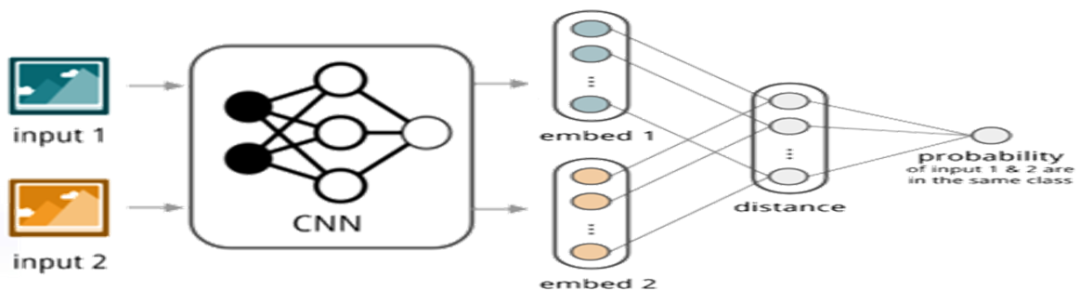
图 10
六、
图像风格迁移
图像风格迁移,就是给一张风格图片a,和一张内容图片p,融合生成一张新的图片x,希望新图片x与图片a在风格上尽量相似,与图片p在内容上尽量相似。因此,为了衡量这种相似差异,需要权衡a与x之间的风格差异以及p与x之间的内容差异,来定义总损失函数:
losstotal(a, p, x) = α×lstyle(a, x) + β×lcontent(p, x)
当然,对于图像的内容和风格的理解其实是非常主观的一个过程,故在数学上对这两种Loss也很难有统一且准确的定义,目前内容Loss常常使用每个像素间的累积均方误差,即让像素间的差异越小越好;而风格Loss ,则首先使用类似协方差的相关性计算特征图的纹理/Gram矩阵,再基于该矩阵计算风格图片与生成图片之间的差异。
2015年8月发布的论文《A Neural Algorithm of Artistic Style》,揭开了使用深度学习做图像风格迁移的序幕。如图11所示,其一方面基于CNN提取内容图像的高层特征,表征内容图像信息,另一方面采用CNN得到风格图像的各层次特征图,计算对应的纹理矩阵,多尺度表征风格信息。然后初始化一张白噪声图片,也用VGG16分别提取其高层内容特征和各层次纹理矩阵,与内容图像信息计算内容Loss,与每层纹理矩阵计算平均风格Loss,融合为目标损失,以此调整初始输入的白噪声图像的像素值。

图 11
参考文献
[1]Aston Zhang, Mu Li, Zachary C. Lipton, Alexander J. Smola.动手学深度学习[M]. 人民邮电出版社, 2019.
[2]缪鹏. 深度学习实践:计算机视觉[M]. 清华大学出版社, 2019.
[3]Gatys,L.A., Ecker,A.S., Bethge,M.: A neural algorithm of artistic style. Computer Science. 2015.
[4]Khan A, Sohail A, Zahoora U, et al. A Survey of the Recent Architectures of Deep Convolutional Neural Networks[J]. arXiv preprint arXiv: 1901.06032, 2019.