GeaFlow(品牌名TuGraph-Analytics) 已正式开源,欢迎大家关注!!! 欢迎给我们 Star 哦! GitHub👉https://github.com/TuGraph-family/tugraph-analytics
更多精彩内容,关注我们的博客 https://tugraph-analytics.github.io/
6月18日-23日,数据库国际顶会 2023 ACM SIGMOD 在美国西雅图举行,蚂蚁流式图计算团队一篇论文入选。
ACM SIGMOD 数据管理国际会议是由美国计算机协会(ACM) 数据管理专业委员会(SIGMOD) 发起,与 VLDB、ICDE 并称为数据库业界的三大顶级学术会议。
其收录论文代表了数据库领域的最高水平,也是未来数据库技术发展的重要风向标。
蚂蚁流式图计算团队本次的论文 《GeaFlow: A Graph Extended and Accelerated Dataflow System》 被 SIGMOD 2023 收录,代表蚂蚁流式图计算团队的成果不仅在工业界有界广泛的应用,同时也在学术界得到进一步认可。

图片注:GeaFlow 为蚂蚁流式图计算引擎 TuGraph Analytics 内部代号,本文将沿用论文中所用 “GeaFlow”,便于读者对应。
图片项目代码地址:https://github.com/TuGraph-family/tugraph-analytics
背景介绍
伴随着流处理技术的不断发展,它被各大应用领域广泛的使用,例如监控、推荐、广告等。虽然现有的流处理系统已经被证明对处理窗口类型的集合查询非常有效,但当面临更复杂的数据结构,例如图结构数据时,却面临非常多的挑战。
首先在流计算中 join 是一个开销非常大的操作,特别是对于动态变化的数据,因为每来一条数据都需要从另外一条流中找到其所对应的数据,另外还涉及到数据物化和 shuffle。而流式图计算中通常需要成百上千次图迭代才能得到结果,对应流计算就是成百上千次 join 操作。
其次流计算中数据聚集的中间状态,通常在固定窗口或者滑动窗口中,需要维护的数据量是远小于窗口的原始数据大小,且窗口通常不会特别大。而流式图计算中通常需要维持一个较长窗口且动态变化的图,比如在风险识别中需要回溯到几个月甚至几年的数据。
为了解决上述的这些问题,蚂蚁流式图计算团队开发和设计了一款
流图计算引擎 Geaflow,它能很好的解决流式动态图分析、遍历和计算的诉求,同时支持长窗口数据图数据状态管理、DSL 化流图任务研发等特性。
Geaflow 在蚂蚁的风控、营销等场景也得到了非常广泛的应用,同时也在双十一大促中大放异彩。下面我们来剖析下 Geaflow 的运行场景和内部技术。
运行场景
不同于图数据库,Geaflow 解决的问题是高吞吐场景下复杂的图分析和计算问题,例如深度图遍历、子图匹配、全图分析等。Geaflow 使用流式事件驱动的方式进行计算和查询,同时利用查询优化技术进行查询合并和加速。下面我们来描述下 Geaflow 的运行场景。
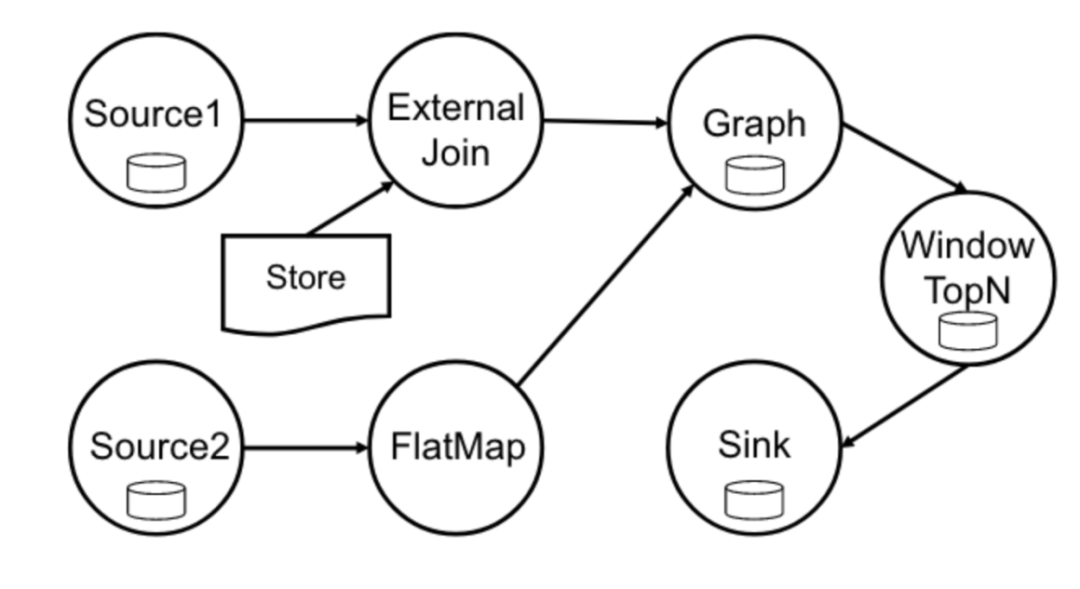
图1 所描述的就是一个典型的 Geaflow 数据流向图。从整体的流水线来看,它在进行流式的构图,构图的数据可以包括多种不同类型的数据,可以是消息队队列,也可以是日志系统。数据可以经过ETL处理,最后转换为点和边写入图存储,图存储会定期的进行 checkpoint 来保障 ExactlyOnce。
同时,它还基于增量和变化的数据进行驱动图计算,例如反套现场景中不断进行付款的用户id。和其他通用的流计算系统不同的是,由于图计算是迭代计算,GeaFlow 支持流式链路上的迭代图处理。最后可以将图计算的输出数据加工处理,例如上图中进行 Window TopN 计算后输出。
架构设计
为了支持以上的场景,Geaflow 做了如下的架构设计:
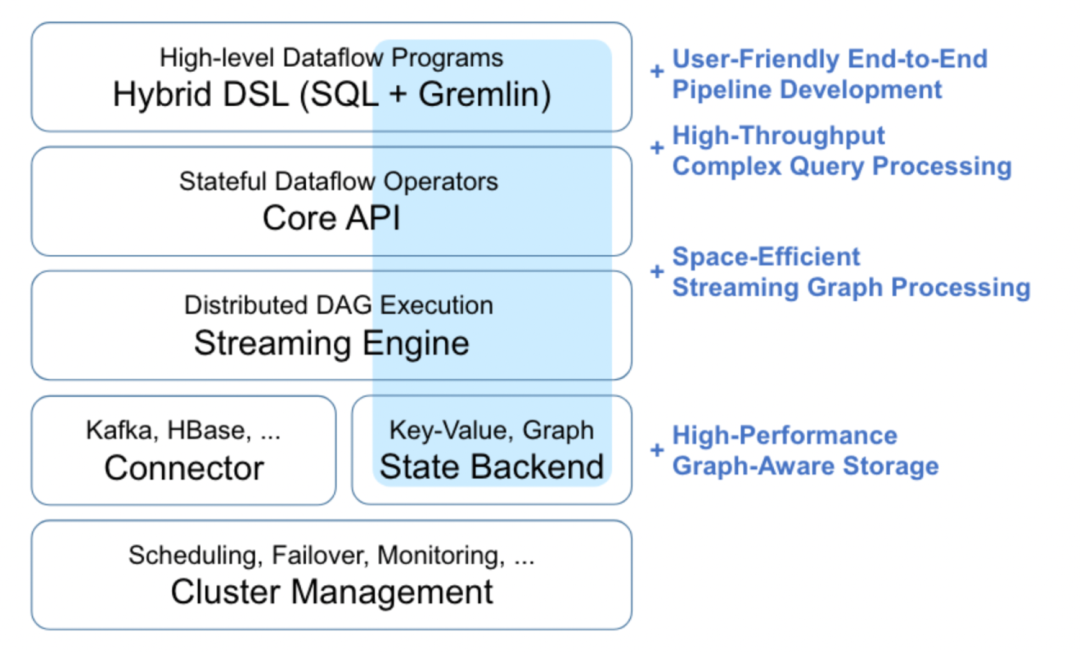
如图2所示,相对于典型的流系统,我们做了如下的扩展和补充。整体架构从上往下包含以下几层:
Hybird DSL
GeaFlow创新型的融合了表和图语义,利用表 DSL SQL以及图 DSL Gremlin 来描述,用户可以轻松通过类似SQL编程的方式编写实时图计算任务。同时,在 Query Planning 中,我们针对对逻辑执行计划和物理执行计划进行图语义优化;并且对多查询语句还 进行合并查询等优化。
Core API
GeaFlow 设计了一套带状态语义的算子,支持多种流、图语义,包括标准的流算子、vertex/edge-centric 的图算子。在图算子中,我们建立了很好的编程模型,支持用户各种不同的图结构,同时引入 session 来处理并发的图查询。
Streaming Engine
GeaFlow 运行时的分布式DAG执行层,可以灵活的在流图语义间切换,同时可以高效的支持多查询优化。在执行过程中,我们利用 off-heap 内存管理、sharing graph state 和批量执行等技术进行优化,极大的提升了整体的吞吐。
GeaFlow State
GeaFlow 的状态存储,用于存取流、图数据。可以使用 KV 语义的状态,也可以使用图语义的状态。在图状态中,我们设计了一套高效的 key layout,加速 vertex 和 edge 存取,兼容多种不同多模 backend。同时我们还开发了一套 graph-native 的 backend,利用类 CSR 的索引结构以及计算和存储分离架构支持更高效的图存取,与灵活的扩缩容。
实验结果
我们在这里列举了 Geaflow 和其他流计算引擎的对比。
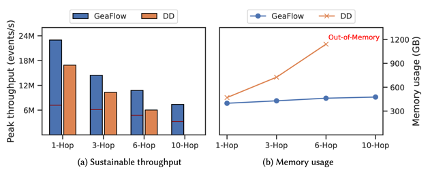
在 K-Hop Neighborhood 场景中,我们选在 LiveJournal 以及 Twitter-2010两个公开数据集,对比 Geaflow、 Flink 以及 Differential Dataflow。实验是在8个 container 的集群上做测试,其中每个 container 规格为8c16G。
通过实现,我们可以看到:
在多个 hop 的遍历场景下,GeaFlow 整个的内存保持平稳,并不会随着迭代深度增加而显著增加,而其他通用流式计算引擎,则会有显著的存储空间放大,从而在 hop 数过多是内存溢出。
GeaFlow 针对典型流式图场景,对于基于通用路计算引擎基于 Join 来实现的方式,吞吐显著提升。
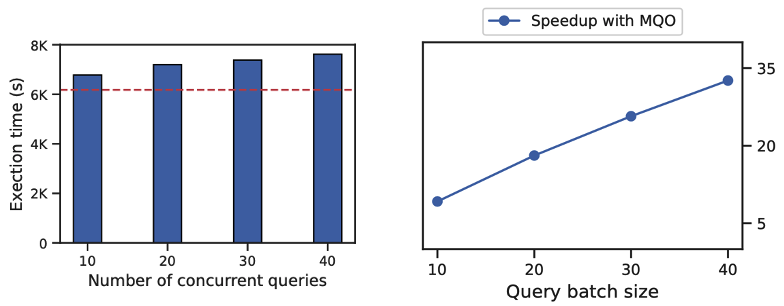
在图查询仿真场景中,我们验证查询时间和并发执行 query 数的关系。
在图4中我们看到随着批次中并发的查询数据量增大,执行时间增加的并不会特别明显。可以发现融合40个query的时间只增加了22.7%,达到32.6倍的提速效果。
总结及规划
Geaflow 源于6年前我们在蚂蚁业务场景的尝试,当时我们发现现有的流处理架构并不适合流式图处理,经过两年的孵化,Geaflow 成功的支持蚂蚁反欺诈业务,同时在2018年双十一期间达到每秒处理超过千万级事件的高吞吐量。在这些业务中的流式图查询和分析效果带来的业务效果也非常显著,证明了流式图处理在金融场景中可以提供非常多的帮助。之后我们引入 DSL 的支持,进一步减少用户开发成本,我们选择了 SQL + Gremlin 的组合,并不断改进器查询优化器,于是便有有大量的用户开始使用我们的DSL来查询和分析他们的图计算场景。如今 Geaflow 已成为蚂蚁最受欢迎的计算引擎之一。
接下来,我们计划在以下几个方面进一步发展 GeaFlow:
- 融合更多的图语义,例如具有增量语义的图计算算子。
- 探索更多声明式的图查询语言,例如 OpenCypher、GQL 和 SQL/PGQ 等。同时融入 CBO 优化,自动调参等能力。
- 探索使用 Rust/C++ 等语言改写我们执行引擎,进一步提高性能。
GeaFlow(品牌名TuGraph-Analytics) 已正式开源,欢迎大家关注!!!
欢迎给我们 Star 哦!
Welcome to give us a Star!
GitHub👉https://github.com/TuGraph-family/tugraph-analytics
更多精彩内容,关注我们的博客 https://tugraph-analytics.github.io/