词云是一种文本数据的可视化形式,它富有表现力,通过大小不一,五颜六色,随机紧挨在一起的文本形式,可以在众多文本中直观地突出出现频率较高的关键词,给予视觉上的突出,从而过滤掉大量的文本信息,在实际项目中,我们可以选择使用wordcloud2、VueWordCloud等开源库来实现,但是你有没有好奇过它是怎么实现的呢,本文会尝试从0实现一个简单的词云效果。
最终效果抢先看:https://wanglin2.github.io/simple-word-cloud/。
基本原理
词云的基本实现原理非常简单,就是通过遍历像素点进行判断,我们可以依次遍历每个文本的每个像素点,然后再依次扫描当前画布的每个像素点,然后判断这个像素点的位置能否容纳当前文本,也就是不会和已经存在的文本重叠,如果可以的话这个像素点的位置就是该文本显示的位置。
获取文本的像素点我们可以通过canvas的getImageData方法。
最终渲染你可以直接使用canvas,也可以使用DOM,本文会选择使用DOM,因为可以更方便的修改内容、样式以及添加交互事件。
计算文字大小
假如我们接收的源数据结构如下所示:
const words = [
['字节跳动', 33],
['腾讯', 21],
['阿里巴巴', 4],
['美团', 56],
]每个数组的第一项代表文本,第二项代表该文本所对应的权重大小,权重越大,在词云图中渲染时的字号也越大。
那么怎么根据这个权重来计算出所对应的文字大小呢,首先我们可以找出所有文本中权重的最大值和最小值,那么就可以得到权重的区间,然后将每个文本的权重减去最小的权重,除以总的区间,就可以得到这个文本的权重在总的区间中的所占比例,同时,我们需要设置词云图字号允许的最小值和最大值,那么只要和字号的区间相乘,就可以得到权重对应的字号大小,基于此我们可以写出以下函数:
// 根据权重计算字号
const getFontSize = (
weight,
minWeight,
maxWeight,
minFontSize,
maxFontSize
) => {
const weightRange = maxWeight - minWeight
const fontSizeRange = maxFontSize - minFontSize
const curWeightRange = weight - minWeight
return minFontSize + (curWeightRange / weightRange) * fontSizeRange
}获取文本的像素数据
canvas有一个getImageData方法可以获取画布的像素数据,那么我们就可以将文本在canvas上绘制出来,然后再调用该方法就能得到文本的像素数据了。
文本的字体样式不同,绘制出来的文本也不一样,所以绘制前需要设置一下字体的各种属性,比如字号、字体、加粗、斜体等等,可以通过绘图上下文的font属性来设置,本文简单起见,只支持字号、字体、加粗三个字体属性。
因为canvas不像css一样支持单个属性进行设置,所以我们写一个工具方法来拼接字体样式:
// 拼接font字符串
const joinFontStr = ({ fontSize, fontFamily, fontWeight }) => {
return `${fontWeight} ${fontSize}px ${fontFamily} `
}接下来还要考虑的一个问题是canvas的大小是多少,很明显,只要能容纳文本就够了,所以也就是文本的大小,canvas同样也提供了测量文本大小的方法measureText,那么我们可以写出如下的工具方法:
// 获取文本宽高
let measureTextContext = null
const measureText = (text, fontStyle) => {
// 创建一个canvas用于测量
if (!measureTextContext) {
const canvas = document.createElement('canvas')
measureTextContext = canvas.getContext('2d')
}
measureTextContext.save()
// 设置字体样式
measureTextContext.font = joinFontStr(fontStyle)
// 测量文本
const { width, actualBoundingBoxAscent, actualBoundingBoxDescent } =
measureTextContext.measureText(text)
measureTextContext.restore()
// 返回文本宽高
const height = actualBoundingBoxAscent + actualBoundingBoxDescent
return { width, height }
}measureText方法不会直接返回高度,所以我们要通过返回的其他属性计算得出,关于measureText更详细的介绍可以参考measureText。
有了以上两个方法,我们就可以写出如下的方法来获取文本的像素数据:
// 获取文字的像素点数据
export const getTextImageData = (text, fontStyle) => {
const canvas = document.createElement('canvas')
// 获取文本的宽高,并向上取整
let { width, height } = measureText(text, fontStyle)
width = Math.ceil(width)
height = Math.ceil(height)
canvas.width = width
canvas.height = height
const ctx = canvas.getContext('2d')
// 绘制文本
ctx.translate(width / 2, height / 2)
ctx.font = joinFontStr(textStyle)
ctx.textAlign = 'center'
ctx.textBaseline = 'middle'
ctx.fillText(text, 0, 0)
// 获取画布的像素数据
const image = ctx.getImageData(0, 0, width, height).data
// 遍历每个像素点,找出有内容的像素点
const imageData = []
for (let x = 0; x < width; x++) {
for (let y = 0; y < height; y++) {
// 如果a通道不为0,那么代表该像素点存在内容
const a = image[x * 4 + y * (width * 4) + 3]
if (a > 0) {
imageData.push([x, y])
}
}
}
return {
data: imageData,
width,
height
}
}首先为了避免出现小数,我们将计算出的文本大小向上取整作为画布的大小。
然后将画布的中心点从左上角移到中心进行文本的绘制。
接下来通过getImageData方法获取到画布的像素数据,获取到的是一个数值数组,依次保存着画布从左到右,从上到下的每一个像素点的信息,每四位代表一个像素点,分别为:r、g、b、a四个通道的值。

为了减少后续比对的工作量,我们过滤出存在内容的像素点,也就是存在文本的像素点,空白的像素点可以直接舍弃。因为我们没有指定文本的颜色,所以默认为黑色,也就是rgb(0,0,0),那么只能通过a通道来判断。
另外,除了返回存在内容的像素点数据外,也返回了文本的宽高信息,后续可能会用到。
文本类
接下来我们来创建一个文本类,用于保存每个文本的一些私有状态:
// 文本类
class WordItem {
constructor({ text, weight, fontStyle, color }) {
// 文本
this.text = text
// 权重
this.weight = weight
// 字体样式
this.fontStyle = fontStyle
// 文本颜色
this.color = color || getColor()// getColor方法是一个返回随机颜色的方法
// 文本像素数据
this.imageData = getTextImageData(text, fontStyle)
// 文本渲染的位置
this.left = 0
this.top = 0
}
}很简单,保存相关的状态,并且计算并保存文本的像素数据。
词云类
接下来创建一下我们的入口类:
// 词云类
class WordCloud {
constructor({ el, minFontSize, maxFontSize, fontFamily, fontWeight }) {
// 词云渲染的容器元素
this.el = el
const elRect = el.getBoundingClientRect()
this.elWidth = elRect.width
this.elHeight = elRect.height
// 字号大小
this.minFontSize = minFontSize || 12
this.maxFontSize = maxFontSize || 40
// 字体
this.fontFamily = fontFamily || '微软雅黑'
// 加粗
this.fontWeight = fontWeight || ''
}
}后续的计算中会用到容器的大小,所以需要保存一下。此外也开放了字体样式的配置。
接下来添加一个计算的方法:
class WordCloud {
// 计算词云位置
run(words = [], done = () => {}) {
// 按权重从大到小排序
const wordList = [...words].sort((a, b) => {
return b[1] - a[1]
})
const minWeight = wordList[wordList.length - 1][1]
const maxWeight = wordList[0][1]
// 创建词云文本实例
const wordItemList = wordList
.map(item => {
const text = item[0]
const weight = item[1]
return new WordItem({
text,
weight,
fontStyle: {
fontSize: getFontSize(
weight,
minWeight,
maxWeight,
this.minFontSize,
this.maxFontSize
),
fontFamily: this.fontFamily,
fontWeight: this.fontWeight
}
})
})
}
}run方法接收两个参数,第一个为文本列表,第二个为执行完成时的回调函数,会把最终的计算结果传递回去。
首先我们把文本列表按权重从大到小进行了排序,因为词云的渲染中一般权重大的文本会渲染在中间位置,所以我们从大到小进行计算。
然后给每个文本创建了一个文本实例。
我们可以这么使用这个类:
const wordCloud = new WordCloud({
el: el.value
})
wordCloud.run(words, () => {})
计算文本的渲染位置
接下来到了核心部分,即如何计算出每个文本的渲染位置。
具体逻辑如下:
1.我们会维护一个map,key为像素点的坐标,value为true,代表这个像素点已经有内容了。
2.以第一个文本,也就是权重最大的文本作为基准,你可以想象成它就是画布,其他文本都相对它进行定位,首先将它的所有像素点保存到map中,同时记录下它的中心点位置;
3.依次遍历后续的每个文本实例,对每个文本实例,从中心点依次向四周扩散,遍历每个像素点,根据每个文本的像素数据和map中的数据判断当前像素点的位置能否容纳该文本,可以的话这个像素点即作为该文本最终渲染的位置,也就是想象成渲染到第一个文本形成的画布上,然后将当前文本的像素数据也添加到map中,不过要注意,这时每个像素坐标都需要加上计算出来的位置,因为我们是以第一个文本作为基准。以此类推,计算出所有文本的位置。
添加一个compute方法:
class WordCloud { run(words = [], done = () => {}) { // ... // 计算文本渲染的位置 this.compute(wordItemList) // 返回计算结果 const res = wordItemList.map(item => { return { text: item.text, left: item.left, top: item.top, color: item.color, fontStyle: item.fontStyle } }) done(res) }// 计算文本的位置 compute(wordItemList) { for (let i = 0; i < wordItemList.length; i++) { const curWordItem = wordItemList[i] // 将第一个文本的像素数据保存到map中 if (i === 0) { addToMap(curWordItem) continue } // 依次计算后续的每个文本的显示位置 const res = getPosition(curWordItem) curWordItem.left = res[0] curWordItem.top = res[1] // 计算出位置后的每个文本也需要将像素数据保存到map中 addToMap(curWordItem) } }
}
调用compute方法计算出每个文本的渲染位置,计算完后我们会调用done方法把文本数据传递出去。
compute方法就是前面描述的2、3两步的逻辑,接下来我们的任务就是完成其中的addToMap、getPosition两个方法。
addToMap方法用于保存每个文本的像素数据,同时要记录一下第一个文本的中心点位置:
let pxMap = {}
let centerX = -1
let centerY = -1
// 保存每个文本的像素数据
const addToMap = curWordItem => {
curWordItem.imageData.data.forEach(item => {
const x = item[0] + curWordItem.left
const y = item[1] + curWordItem.top
pxMap[x + '|' + y] = true
})
// 记录第一个文本的中心点位置
if (centerX === -1 && centerY === -1) {
centerX = Math.floor(curWordItem.imageData.width / 2)
centerY = Math.floor(curWordItem.imageData.height / 2)
}
}
很简单,遍历文本的像素数据,以坐标为key添加到map对象中。
可以看到每个像素点的坐标会加上当前文本的渲染坐标,初始都为0,所以第一个文本保存的就是它原始的坐标值,后续每个文本都是渲染在第一个文本形成的画布上,所以每个像素点要加上它的渲染坐标,才能转换成第一个文本形成的画布的坐标系上的点。
接下来是getPosition方法,首先来看一下示意图:

遍历的起点是第一个文本的中心点,然后不断向四周扩散:

每次扩散形成的矩形的四条边上的所有像素点都需要遍历判断是否符合要求,即这个位置能否容纳当前文本,所以我们需要四个循环。
这样不断扩散,直到找到符合要求的坐标。
因为要向四周扩散,所以需要四个变量来保存:
const getPosition = (curWordItem) => {
let startX, endX, startY, endY
// 第一个文本的中心点
startX = endX = centerX
startY = endY = centerY
}以第一个文本的中心点为起始点,也就是开始遍历的位置。初始startX和endX相同,startY和endY相同,然后startX和startY递减,endX和endY递增,达到扩散的效果。
针对每个像素点,我们怎么判断它是否符合要求呢,很简单,遍历当前文本的每个像素点,加上当前判断的像素点的坐标,转换成第一个文本形成的坐标系上的点,然后去map里面找,如果某个像素点已经在map中存在了,代表这个像素点已经有文本了,那么当前被检查的这个像素所在的位置无法就完全容纳当前文本,那么进入下一个像素点进行判断,直到找到符合要求的点。
// 判断某个像素点所在位置能否完全容纳某个文本
const canFit = (curWordItem, [cx, cy]) => {
if (pxMap[${cx}|${cy}]) return false
return curWordItem.imageData.data.every(([x, y]) => {
const left = x + cx
const top = y + cy
return !pxMap[${left}|${top}]
})
}首先判断这个像素位置本身是否已经存在文字了,如果没有,那么遍历文本的所有像素点,需要注意文本的每个像素坐标都要加上当前判断的像素坐标,这样才是以第一个文本为基准的坐标值。
有了这个方法,接下来就可以遍历所有像素点节点判断了:

const getPosition = (curWordItem) => {
let startX, endX, startY, endY
startX = endX = centerX
startY = endY = centerY
// 判断起始点是否符合要求
if (canFit(curWordItem, [startX, startY])) {
return [startX, startY]
}
// 依次扩散遍历每个像素点
while (true) {
// 向下取整作为当前比较的值
const curStartX = Math.floor(startX)
const curStartY = Math.floor(startY)
const curEndX = Math.floor(endX)
const curEndY = Math.floor(endY)// 遍历矩形右侧的边 for (let top = curStartY; top < curEndY; ++top) { const value = [curEndX, top] if (canFit(curWordItem, value)) { return value } } // 遍历矩形下面的边 for (let left = curEndX; left > curStartX; --left) { const value = [left, curEndY] if (canFit(curWordItem, value)) { return value } } // 遍历矩形左侧的边 for (let top = curEndY; top > curStartY; --top) { const value = [curStartX, top] if (canFit(curWordItem, value)) { return value } } // 遍历矩形上面的边 for (let left = curStartX; left < curEndX; ++left) { const value = [left, curStartY] if (canFit(curWordItem, value)) { return value } } // 向四周扩散 startX -= 1 endX += 1 startY -= 1 endY += 1 }
}
因为我们是通过像素的坐标来判断,所以不允许出现小数,都需要进行取整。
对矩形边的遍历我们是按下图的方向:

当然,你也可以调整成你喜欢的顺序。
到这里,应该就可以计算出所有文本的渲染位置了,我们将文本渲染出来看看效果:
import { ref } from 'vue'const el = ref(null)
const list = ref([])
const wordCloud = new WordCloud({
el: el.value
})
wordCloud.run(exampleData, res => {
list.value = res
})
<div class="container" ref="el">
<div
class="wordItem"
v-for="(item, index) in list"
:key="index"
:style="{
left: item.left + 'px',
top: item.top + 'px',
fontSize: item.fontStyle.fontSize + 'px',
fontFamily: item.fontStyle.fontFamily,
color: item.color
}"
>
{{ item.text }}
</div>
</div>.container {
width: 600px;
height: 400px;
border: 1px solid #000;
margin: 200px auto;
position: relative;.wordItem { position: absolute; white-space: nowrap; }
}
以上是Vue3的代码示例,容器元素设为相对定位,文本元素设为绝对定位,然后将计算出来的位置作为left和top值,不要忘了设置字号、字体等样式。效果如下:

为了方便的看出每个文本的权重,把权重值也显示出来了。
首先可以看到有极少数文字还是发生了重叠,这个其实很难避免,因为我们一直在各种取整。
另外可以看到文字的分布是和我们前面遍历的顺序是一致的。
适配容器
现在我们看一下文本数量比较多的情况:

可以看到我们给的容器是宽比高长的,而渲染出来云图接近一个正方形,这样放到容器里显然没办法完全铺满,所以最好我们计算出来的云图的比例和容器的比例是一致的。
解决这个问题可以从扩散的步长下手,目前我们向四周扩散的步长都是1,假如宽比高长,那么垂直方向已经扩散出当前像素区域了,而水平方向还在内部,那么显然最后垂直方向上排列的就比较多了,我们要根据容器的长宽比来调整这个步长,让垂直和水平方向扩散到边界的时间是一样的:
class WordCloud {
compute(wordItemList) {
for (let i = 0; i < wordItemList.length; i++) {
const curWordItem = wordItemList[i]
// ...
// 计算文本渲染位置时传入容器的宽高
const res = getPosition({
curWordItem,
elWidth: this.elWidth,
elHeight: this.elHeight
})
// ...
}
}
}const getPosition = ({ elWidth, elHeight, curWordItem }) => {
// ...
// 根据容器的宽高来计算扩散步长
let stepLeft = 1,
stepTop = 1
if (elWidth > elHeight) {
stepLeft = 1
stepTop = elHeight / elWidth
} else if (elHeight > elWidth) {
stepTop = 1
stepLeft = elWidth / elHeight
}
// ...
while (true) {
// ...
startX -= stepLeft
endX += stepLeft
startY -= stepTop
endY += stepTop
}
}计算文本渲染位置时传入容器的宽高,如果宽比高长,那么垂直方向步长就得更小一点,反之亦然。
此时我们再来看看效果:

是不是基本上一致了。
现在我们来看下一个问题,那就是大小适配,我们将最小的文字大小调大一点看看:

可以发现词云已经比容器大了,这显然不行,所以最后我们还要来根据容器大小来调整词云的大小,怎么调整呢,根据容器大小缩放词云整体的位置和字号。
首先我们要知道词云整体的大小,这可以最后遍历map来计算,当然也可以在addToMap函数内同时计算:
let left = Infinity
let right = -Infinity
let top = Infinity
let bottom = -Infinityconst addToMap = curWordItem => {
curWordItem.imageData.data.forEach(item => {
const x = item[0] + curWordItem.left
const y = item[1] + curWordItem.top
pxMap[x + '|' + y] = true
// 更新边界
left = Math.min(left, x)
right = Math.max(right, x)
top = Math.min(top, y)
bottom = Math.max(bottom, y)
})
// ...
}
// 获取边界数据
const getBoundingRect = () => {
return {
left,
right,
top,
bottom,
width: right - left,
height: bottom - top
}
}
增加了四个变量来保存所有文本渲染后的边界数据,同时添加了一个函数来获取这个信息。
接下来给WordCloud类增加一个方法,用来适配容器的大小:
class WordCloud {
run(words = [], done = () => {}) {
// ...
this.compute(wordItemList)
this.fitContainer(wordItemList)// ++
const res = wordItemList.map(item => {
return {}
})
done(res)
}// 根据容器大小调整字号 fitContainer(wordItemList) { const elRatio = this.elWidth / this.elHeight const { width, height } = getBoundingRect() const wordCloudRatio = width / height let w, h if (elRatio > wordCloudRatio) { // 词云高度以容器高度为准,宽度根据原比例进行缩放 h = this.elHeight w = wordCloudRatio * this.elHeight } else { // 词云宽度以容器宽度为准,高度根据原比例进行缩放 w = this.elWidth h = this.elWidth / wordCloudRatio } const scale = w / width wordItemList.forEach(item => { item.left *= scale item.top *= scale item.fontStyle.fontSize *= scale }) }
}
根据词云的宽高比和容器的宽高比进行缩放,计算出缩放倍数,然后应用到词云所有文本的渲染坐标、字号上。现在再来看看效果:

现在还有最后一个问题要解决,就是渲染位置的调整,因为目前所有文本渲染的位置都是相对于第一个文本的,因为第一个文本的位置为0,0,所以它处于容器的左上角,我们要调整为整体在容器中居中。

如图所示,第一个文本的位置为0,0,所以左边和上边超出的距离就是边界数据中的left、top值,那么把词云移入容器,只要整体移动-left、-top距离即可。
接下来是移动到中心,这个只要根据前面的比例来判断移动水平还是垂直的位置即可:

所以这个逻辑也可以写在fitContainer方法中:
class WordCloud {
fitContainer(wordItemList) {
const elRatio = this.elWidth / this.elHeight
let { width, height, left, top } = getBoundingRect()
const wordCloudRatio = width / height
let w, h
// 整体平移距离
let offsetX = 0,
offsetY = 0
if (elRatio > wordCloudRatio) {} else {}
const scale = w / width
// 将词云移动到容器中间
left *= scale
top *= scale
if (elRatio > wordCloudRatio) {
offsetY = -top
offsetX = -left + (this.elWidth - w) / 2
} else {
offsetX = -left
offsetY = -top + (this.elHeight - h) / 2
}
wordItemList.forEach(item => {
item.left *= scale
item.top *= scale
item.left += offsetX
item.top += offsetY
item.fontStyle.fontSize *= scale
})
}
}
到这里,一个基本的词云效果就完成了。
加快速度
以上代码可以工作,但是它的速度非常慢,因为要遍历的像素点数据比较庞大,所以耗时是以分钟计的:

这显然是无法接受的,浏览器都无法忍受弹出了退出页面的提示,那么怎么减少一点时间呢,前面说了首先是因为要遍历的像素点太多了,那么是不是可以减少像素点呢,当然是可以的,我们最后有一步适配容器大小的操作,既然都是要最后来整体缩放的,那不如一开始就给所有的文本的字号缩小一定倍数,字号小了,那么像素点显然也会变少,进而计算的速度就会加快:
class WordCloud {
constructor({ el, minFontSize, maxFontSize, fontFamily, fontWeight, fontSizeScale }) {
// ...
// 文字整体的缩小比例,用于加快计算速度
this.fontSizeScale = fontSizeScale || 0.1
}run(words = [], done = () => {}) { // ... const wordItemList = wordList.map(item => { const text = item[0] const weight = item[1] return new WordItem({ text, weight, fontStyle: { fontSize: getFontSize() * this.fontSizeScale,// ++ fontFamily: this.fontFamily, fontWeight: this.fontWeight } }) }) }
}
这个比例你可以自己调整,越小速度越快,当然,也不能太小,太小文字都渲染不了了。现在来看一下耗时:

可以看到,耗时由分钟级减至毫秒级,效果还是非常不错的。
当然,这毕竟还是一个计算密集型任务,所以可以通过Web worker放在独立线程中去执行。
间距
目前文本之间基本是紧挨着,接下来添加点间距。
因为我们是通过检测某个像素点上有没有文字,所有只要在检测阶段让间距的位置上存在内容,最后实际显示文字时是空白,那么就实现了间距的添加。
前面获取文字的像素数据时我们是通过ctx.fillText来绘制文字,还有一个strokeText方法可以用于绘制文字的轮廓,它可以受lineWidth属性影响,当lineWidth设置的越大,文字线条也越粗,我们就可以通过这个特性来实现间距,只在获取文字的像素数据时设置lineWidth,比如设置为10,最终通过DOM渲染文字的时候没有这个设置,线宽为1,那么就多了9的间距。
这个lineWidth怎么设置呢,可以直接写死某个数值,也可以相对于文字的字号:
const getTextImageData = (text, fontStyle, space = 0) => {
// 相对于字号的间距
const lineWidth = space * fontStyle.fontSize * 2
let { width, height } = measureText(text, fontStyle, lineWidth)
// 线条变粗了,文字宽高也会变大
width = Math.ceil(width + lineWidth)
height = Math.ceil(height + lineWidth)
// ...
ctx.fillText(text, 0, 0)
//如果要设置间距,则使用strokeText方法绘制文本
if (lineWidth > 0) {
ctx.lineWidth = lineWidth
ctx.strokeText(text, 0, 0)
}
}线条两侧的间距各为字号的倍数,则总的线宽需要乘2。
线条加粗了,文字的宽高也会变大,增加的大小就是间距的大小。
最后使用strokeText方法绘制文本即可。
接下来给文本类添加上间距的属性:
// 文本类
class WordItem {
constructor({ text, weight, fontStyle, color, space }) {
// 间距
this.space = space || 0
// 文本像素数据
this.imageData = getTextImageData(text, fontStyle, this.space)
// ...
}
}WordCloud同样也加上这个属性,这里就略过了。
当space设置为0.5时的效果如下:

旋转
接下来我们让文字支持旋转。
首先要修改的是获取文字像素数据的方法,因为canvas的大小目前是根据文字的宽高设置的,当文字旋转后显然就不行了:

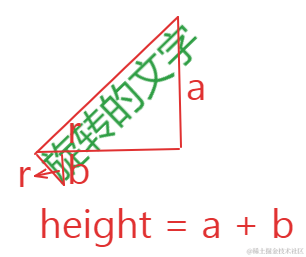
如图所示,绿色的是文字未旋转时的包围框,当文字旋转后,我们需要的是红色的包围框,那么问题就转换成了如何根据文字的宽高和旋转角度计算出旋转后的文字的包围框。
这个计算也很简单,只需要用到最简单的三角函数即可。

宽度的计算可以参考上图,因为文字是一个矩形,不是一条线,所以需要两段长度相加:
width * Math.cos(r) + height * Math.sin(r)高度的计算也是一样的:
width * Math.sin(rad) + height * Math.cos(rad)由此我们可以得到如下的函数:
// 计算旋转后的矩形的宽高
const getRotateBoundingRect = (width, height, rotate) => {
const rad = degToRad(rotate)
const w = width * Math.abs(Math.cos(rad)) + height * Math.abs(Math.sin(rad))
const h = width * Math.abs(Math.sin(rad)) + height * Math.abs(Math.cos(rad))
return {
width: Math.ceil(w),
height: Math.ceil(h)
}
}
// 角度转弧度
const degToRad = deg => {
return (deg * Math.PI) / 180
}
因为三角函数计算出来可能是负数,但是宽高总不能是负的,所以需要转成正数。
那么我们就可以在getTextImageData方法中使用这个函数了:
// 获取文字的像素点数据
const getTextImageData = (text, fontStyle, rotate = 0) => {
// ...
const rect = getRotateBoundingRect(
width + lineWidth,
height + lineWidth,
rotate
)
width = rect.width
height = rect.height
canvas.width = width
canvas.height = height
// ...
// 绘制文本
ctx.translate(width / 2, height / 2)
ctx.rotate(degToRad(rotate))
// ...
}不要忘了通过rotate方法旋转文字。
因为我们的检测是基于像素的,所以文字具体怎么旋转其实都无所谓,那么像素检测过程无需修改。
现在来给文本类添加一个角度属性:
// 文本类
class WordItem {
constructor({ text, weight, fontStyle, color, rotate }) {
// ...
// 旋转角度
this.rotate = rotate
// ...
// 文本像素数据
this.imageData = getTextImageData(text, fontStyle, this.space, this.rotate)
// ...
}
}然后在返回计算结果的地方也加上角度:
class WordCloud {
run(words = [], done = () => {}) {
// ...
const res = wordItemList.map(item => {
return {
// ...
rotate: item.rotate
}
})
done(res)
}
}最后,渲染时加上旋转的样式就可以了:
<div
class="wordItem"
v-for="(item, index) in list"
:key="index"
:style="{
// ...
transform: rotate(${item.rotate}deg)
}"
>
{{ item.text }}
</div>来看看效果:

可以看到很多文字都重叠了,这是为什么呢,首先自信一点,位置计算肯定是没有问题的,那么问题只能出在最后的显示上,仔细思考就会发现,我们计算出来的位置是文本包围框的左上角,但是最后用css设置文本旋转时位置就不对了,我们可以在每个文本计算出来的位置上渲染一个小圆点,就可以比较直观的看出差距:

比如对于文本网易46,它的实际渲染的位置应该如下图所示才对:

解决这个问题可以通过修改DOM结构及样式。我们给wordItem元素外面再套一个元素,作为文本包围框,宽高设置为文本包围框的宽高,然后让wordItem元素在该元素中水平和垂直居中即可。
首先给文本类添加两个属性:
// 文本类
class WordItem {
constructor({ text, weight, fontStyle, color, space, rotate }) {
// 文本像素数据
this.imageData = getTextImageData(text, fontStyle, this.space, this.rotate)
// 文本包围框的宽高
this.width = this.imageData.width
this.height = this.imageData.height
}
}然后不要忘了在适配容器大小方法中也需要调整这个宽高:
class WordCloud {
fitContainer(wordItemList) {
// ...
wordItemList.forEach(item => {
// ...
item.width *= scale
item.height *= scale
item.fontStyle.fontSize *= scale
})
}
}DOM结构调整为如下:
<div class="container" ref="el">
<div
class="wordItemWrap"
v-for="(item, index) in list"
:key="index"
:style="{
left: item.left + 'px',
top: item.top + 'px',
width: item.width + 'px',
height: item.height + 'px'
}"
>
<div
class="wordItem"
:style="{
fontSize: item.fontStyle.fontSize + 'px',
fontFamily: item.fontStyle.fontFamily,
fontWeight: item.fontStyle.fontWeight,
color: item.color,
transform: rotate(${item.rotate}deg)
}"
>
{{ item.text }}
</div>
</div>
</div>.wordItemWrap {
position: absolute;
display: flex;
justify-content: center;
align-items: center;.wordItem { white-space: nowrap; }
}
现在来看看效果:

解决文本超出容器的问题
有时右侧和下方的文本会超出容器大小,为了方便查看添加一个背景色:

这是为什么呢,原因可能有两个,一是因为我们获取文本像素时是缩小了文字字号的,导致最后放大后存在偏差;二是最后我们对文本的宽高也进行了缩放,但是文本宽高和文字字号并不完全成正比,导致宽高和实际文字大小不一致。
解决第二个问题可以通过重新计算文本宽高,我们将获取文本包围框的逻辑由getTextImageData方法中提取成一个方法:
// 获取文本的外包围框大小
const getTextBoundingRect = ({
text,
fontStyle,
space,
rotate
} = {}) => {
const lineWidth = space * fontStyle.fontSize * 2
// 获取文本的宽高,并向上取整
const { width, height } = measureText(text, fontStyle)
const rect = getRotateBoundingRect(
width + lineWidth,
height + lineWidth,
rotate
)
return {
...rect,
lineWidth
}
}然后在fitContainer方法中在缩放了文本字号后重新计算文本包围框:
class WordCloud {
fitContainer(wordItemList) {
wordItemList.forEach(item => {
// ...
item.fontStyle.fontSize *= scale
// 重新计算文本包围框大小而不是直接缩放,因为文本包围框大小和字号并不成正比
const { width, height } = getTextBoundingRect({
text: item.text,
fontStyle: item.fontStyle,
space: item.space,
rotate: item.rotate
})
item.width = width
item.height = height
})
}
}这样下方的文本超出问题就解决了,但是右侧还是会存在问题:

解决方式也很简单,直接根据文本元素的位置和大小判断是否超出了容器,是的话就调整一下位置:
class WordCloud {
fitContainer(wordItemList) {
wordItemList.forEach(item => {
// ...
item.fontStyle.fontSize *= scale
// 重新计算文本包围框大小而不是直接缩放,因为文本包围框大小和字号并不成正比
// ...
// 修正超出容器文本
if (item.left + item.width > this.elWidth) {
item.left = this.elWidth - item.width
}
if (item.top + item.height > this.elHeight) {
item.top = this.elHeight - item.height
}
})
}
}到这里,一个简单的词云效果就完成了:

总结
本文详细介绍了如何从零开始实现一个简单的词云效果,实现上部分参考了VueWordCloud这个项目。
笔者也封装成了一个简单的库,可以直接调用,感兴趣的可以移步仓库:https://github.com/wanglin2/simple-word-cloud。