背景
在大数据领域,随着技术的不断进步和数据的爆炸性增长,数据分析和数据探查已成为企业和组织决策制定的关键因素。在当前的数据分析场景中,Notebook 类的数据分析和探索工具已经成为数据科学家和分析师们的首选。市面上常用的交互式数据分析 Notebook 工具有 Jupyter Notebook、Apache Zeppelin和Databricks Notebook 等,它们在数据分析和探索领域都有自己独特的特点和适用场景,其中最火的当属 Jupyter Notebook。
1.Jupyter Notebook 介绍
Jupyter Notebook 是最受欢迎的开源 notebook 工具,广泛应用于数据清理转换、统计建模、数据分析可视化、机器学习模型训练等方面,支持多种编程语言如 Python、R 和 Julia 等,并提供了交互式的开发环境,结合了代码管理、文档管理及结果可视化展示等功能,对于数据科学家和分析师来说,Jupyter 更是已经成为事实上的标准。

开源的 Jupyter 主要包含以下几部分功能模块:
● JupyterLab:前端 IDE 开发环境,提供 Notebook 编辑器、terminal 终端、文件浏览器,还会提供丰富的前端接口,方便用户开发扩展。
● Jupyter Server:后台服务,前端应用和后台通信的主要接口都在 jupyter_server 中。
● IPython Kernel:也即 Jupyter Kernel,运行内核,提供 Python 运行时环境。
● JupyterHub:提供多用户集中管理 Notebook 服务场景,以支持协作、教学和数据分析等应用场景。
2.腾讯云 WeData Notebook 介绍
当前痛点
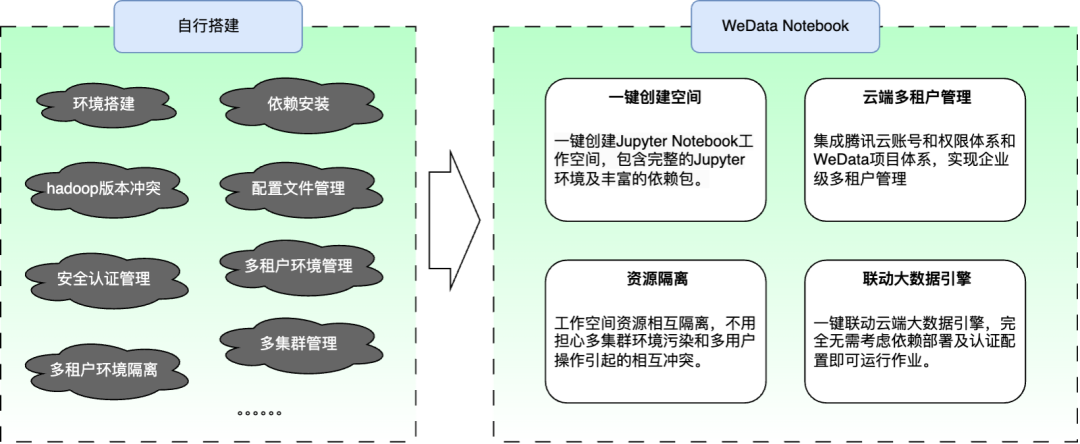
设想这么一种场景,如果需要使用开源 Jupyter 工具编写脚本读取 EMR-hadoop 大数据集群的数据进行交互式数据分析、建模以及数据训练,我们需要做这些工作才能达到目的:
● 环境准备:搭建 Jupyter 需要的 Pyt—hon / Anaconda 环境,处理各种繁琐的环境问题,并维护数据分析探查需要的各种 python 依赖。
● 服务搭建:搭建 Jupyter Notebook 服务,处理安装问题及配置问题。
● 配置管理:准备 Hadoop 集群相关配置文件及依赖包并设置多个 Hadoop 相关的环境变量,处理 pyspark 的 Hadoop 客户端 jar 版本冲突,若是 kerberos 集群还需要准备 kerberos 配置及 keytab 认证信息,连接不同的 Hadoop 集群还需要做到处理环境隔离问题。
● 其他问题:如果是搭建企业级 Notebook 应用,还需要处理多租户隔离和登录认证等周边功能性问题,需要搭建 Jupyter Hub 等服务,并同时兼顾上面提到的环境和配置等问题。
针对以上痛点,腾讯云 WeData 数据开发治理平台推出了 Notebook 探索功能,解决了上面提到的各种需要处理的繁琐问题,能够很方便地通过 Jupyter Notebook 工具对腾讯云大数据引擎 EMR / DLC 的数据进行交互式数据分析、数据探查和机器学习训练:
适用场景
腾讯云 WeData Notebook 主要定位于联动云端大数据引擎 EMR/DLC 开展不同的工作:
1)数据探索和可视化:WeData Notebook 提供了一个交互式的环境,可以使用 PySpark 或其他大数据处理框架来探索和分析 EMR 和 DLC 中的大规模数据集,您可以使用 WeData Notebook 内置的可视化库(如 Matplotlib、Seaborn 等)创建图表和可视化,以更好地理解和展示数据。
2)数据预处理和清洗:编写和运行脚本处理和清洗大规模数据集,例如使用 PySpark 的强大功能进行数据转换、过滤和聚合等工作,来准备数据以供后续分析和建模使用。
3)分布式计算和并行处理:使用 WeData Notebook 交互式环境能够充分利用大数据集群的分布式计算和并行处理的能力,编写和运行分布式计算代码并利用大数据集群资源来处理大规模数据集。
4)机器学习和数据挖掘:进行机器学习和数据挖掘任务,使用内置的 Spark 机器学习库(如MLlib)来构建和训练机器学习模型,WeData Notebook提供的交互式环境可以很方便地编写、运行和调试机器学习代码,并通过可视化和报告等功能来展示结果。
5)数据科学实验和模型迭代:WeData Notebook 工作空间是数据科学实验和模型迭代的理想工具,你可以编写和运行数据预处理、特征工程、模型训练和评估等数据科学代码,通过与大数据解决方案的结合,可以在大规模数据集上进行实验和迭代,以改进和优化数据科学工作流程。
在本文的第3节将以一个详细的案例讲解如何使用时间序列算法进行股票价格预测模型的训练,并进行模型准确性评估及模型持久化。
技术实现
腾讯云 WeData Notebook 探索整体架构图如下:
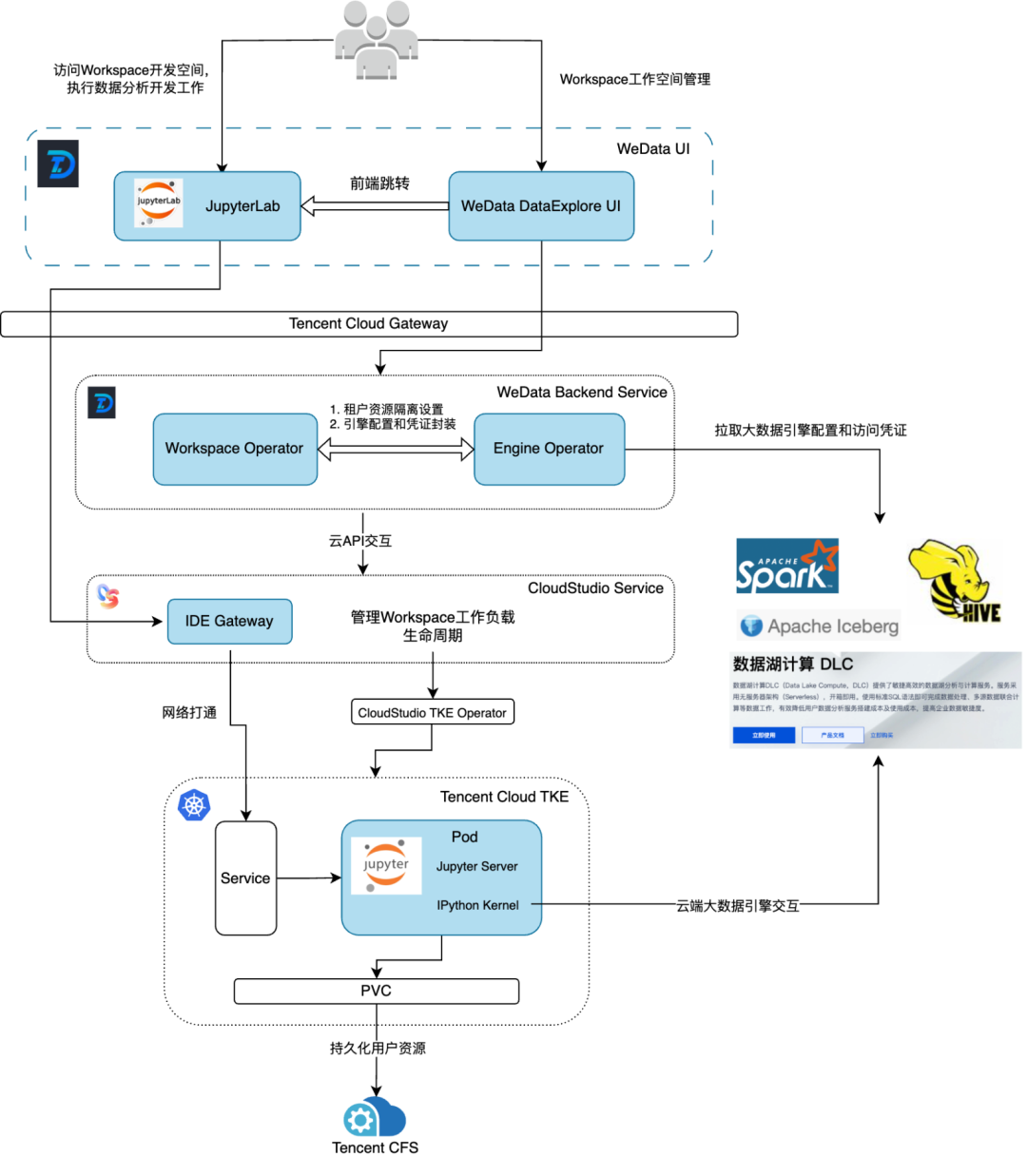
1.关键实现: 联动 Cloudstudio 共建云端 Jupyter 运行环境
WeData 团队联合了腾讯云 CloudStudio 云端IDE团队共建了一套 Jupyter 集成开发环境,云端 IDE 的前端交互环境基于 Visual Studio Code 进行定制化开发,具备开源VSCode 的绝大部分能力,安装 JupyterLab 插件后就能实现 Jupyter 相关功能。
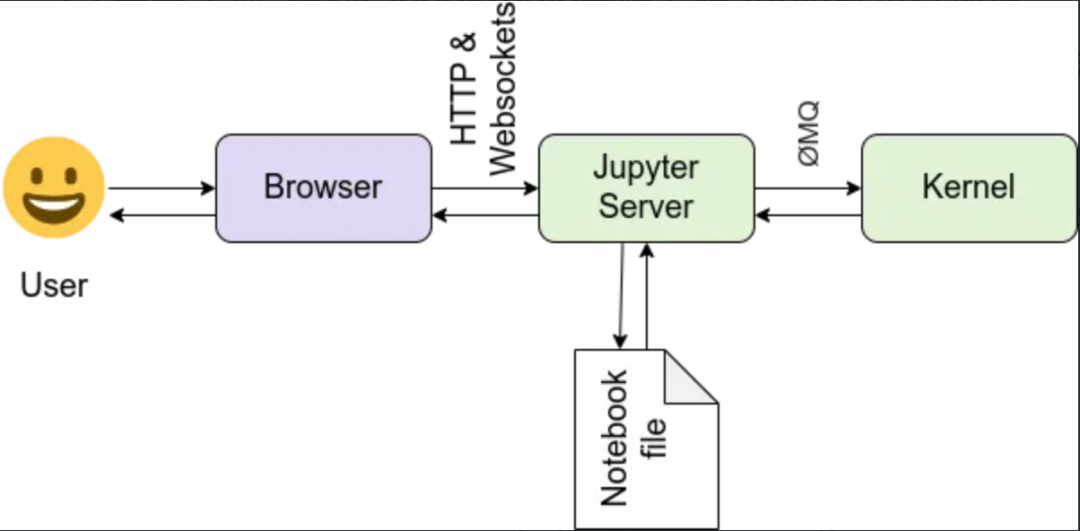
WeData Notebook 的交互场景和 Jupyter 官网介绍的交互架构图基本一致,主要包含两部分核心功能:
● 脚本内容的管理以及内核的管理,其中 Jupyter Kernel 在用户创建 ipynb 脚本并指定内核版本后会自动拉起。
● 代码的交互式执行及可视化展示。
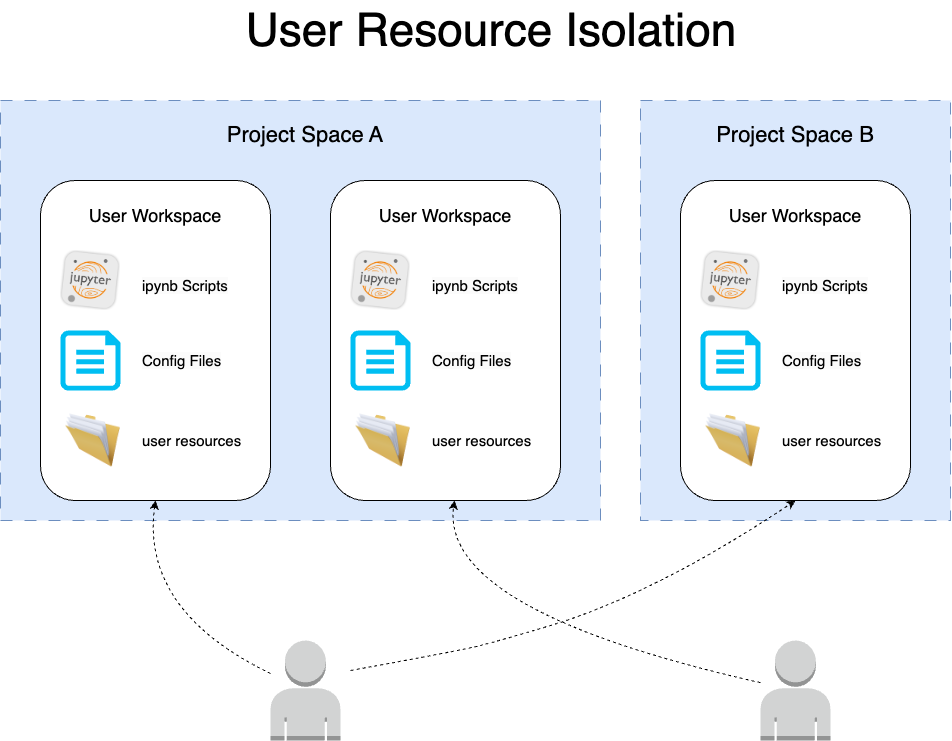
2.关键实现: 基于容器化和账号资源映射实现开发环境隔离
云端 IDE 工作空间容器化部署在云原生 TKE 集群,WeData 后台服务使用一个大账号对同一个地域所有用户的工作空间进行托管。为了实现不同租户不同用户之间的资源隔离,我们将用户工作空间基于项目ID-用户UIN进行隔离管理,不同用户独占一套或多套工作空间环境,一套工作空间独享一个 Jupyter Server,相互间完全隔离互不干扰:
3.关键实现: 打通大数据引擎
原生的云端 IDE 并不具有和用户大数据引擎交互的能力,为了能够支持用户在 Jupyter Notebook 开发环境中编写脚本和大数据引擎进行交互式分析联动,我们对云端 IDE 容器初始化流程进行了一系列改造,仅需简单配置即可访问云端大数据引擎,目前针对不同的引擎类型需要解决不同的问题。
为了将两个云端产品(腾讯云 WeData,Cloudstudio)的功能很好的组合到一起,且不能耦合得太重,我们将问题进行分解为多个子问题逐一解决:运行时配置预部署、网络打通、引擎认证打通。
预部署引擎依赖
针对不同的大数据引擎,需要在IDE运行环境中部署不同的配置文件和安装包:
● EMR hadoop 集群相关的配置文件,包括 core-site.xml、yarn-site.xml、spark-defaults.conf 等
● Hadoop 相关的各种jar包,用于支持 pyspark 作业分析
● DLC 引擎需要用到的 jupyter sdk python 依赖以及 sdk 需要用到的配置文件 tdlc.ini
为了将大数据引擎依赖丝滑地嵌入到 IDE 工作空间容器中,我们研究了云端 IDE 的初始化流程,针对两个不同的依赖类型,有不同的解决方案:
1)静态依赖( jar 包、python 包):
预定制化 IDE 工作空间镜像:jar 包和 python 包这部分依赖和用户选择绑定的大数据引擎实例没有关联,只和引擎版本有关联,因此可以准备多个定制化 docker 镜像用于适配不同版本的大数据引擎,定制化镜像预部署了对应大数据引擎版本所适配的所有固定依赖。
2)动态依赖(配置文件):
这部分依赖和用户选择的具体某个大数据引擎实例有关联,不同的引擎实例有不同的配置文件,这部分依赖只能在创建 IDE 工作空间时动态加载,我们采用了腾讯云 COS 作为配置中转媒介,IDE 工作空间启动时动态从 COS 上拉取所需要的配置。
整体实现流程如下:
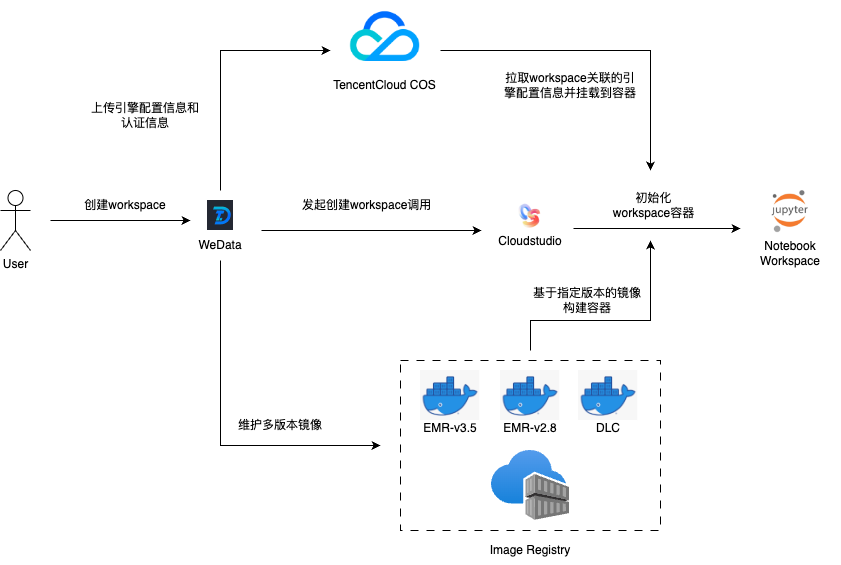
如图,WeData 已针对不同版本的大数据引擎维护了多套不同的 workspace 镜像,用户在创建 workspace 时,WeData 会根据用户绑定的大数据引擎实例,选择合适的镜像版本并将所需要的引擎配置和认证信息上传至 COS,Cloudstudio 基于指定的镜像版本初始化 workspace 容器,在容器初始化过程中就会从 COS 下载所需的配置信息,最终实现整个运行环境的初始化。
网络打通
需要解决的第二个重点问题是将IDE运行环境的网络和大数据引擎的网络打通,用户创建的 IDE 工作空间容器部署于 Cloudstudio 的托管 TKE 集群,该集群的 VPC 网络归属于 CS 云产品大账号,和用户的大数据引擎私有网络 VPC 相互之间无法连通,若不解决网络打通问题则无法在 IDE 运行环境中连通大数据引擎。
针对该问题我们联合 Cloudstudio 团队采用了腾讯云 TKE 提供的跨租户双网卡技术:
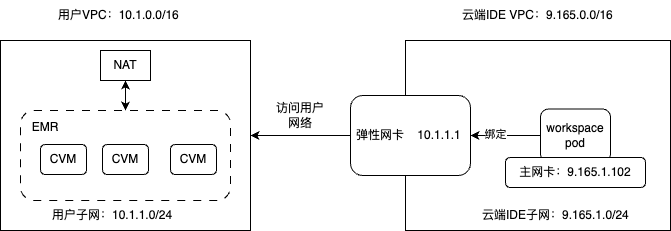
该方案简单描述就是将创建在 Cloudstudio 托管TKE集群上的 IDE 工作空间容器绑定了一张副网卡,用于和用户大数据引擎做双向通信,使用该方案能够完美解决云端 IDE 容器和用户大数据引擎网络无法互通的问题。
引擎认证打通
最后一个重点问题是安全认证问题,如何能够让用户在云端 IDE 中运行数据分析作业访问大数据引擎资源时提供安全保障,针对不同的大数据引擎有不同的解决方案:
1)腾讯云 EMR 引擎认证打通:和EMR引擎进行安全通信需要依赖引擎打开kerberos认证,WeData侧会获取当前用户的keytab/principal/krb5.conf 等安全认证信息,2.3.2 中提到的配置文件预部署流程会将认证信息一同打包下发到 IDE 工作空间容器,并修改spark-defaults.conf 配置用于保证用户在运行 pypsark 作业时无需额外配置即可和 EMR 引擎建立安全通讯。
2)腾讯云 DLC 引擎认证打通:DLC 的 jupyter ipython sdk 需要使用用户的腾讯云ak/sk密钥对用于访问 DLC 云端 API,需要用户在 DLC sdk 脚本中明文填写 ak/sk 密钥对,该方案安全风险较高,使用不够方便,且企业子账号用户一般也无法获取固定秘钥,因此我们在 sdk 中内置了临时密钥对,并且设置了定期刷新机制,提升了安全性和便利性,整体流程如下:
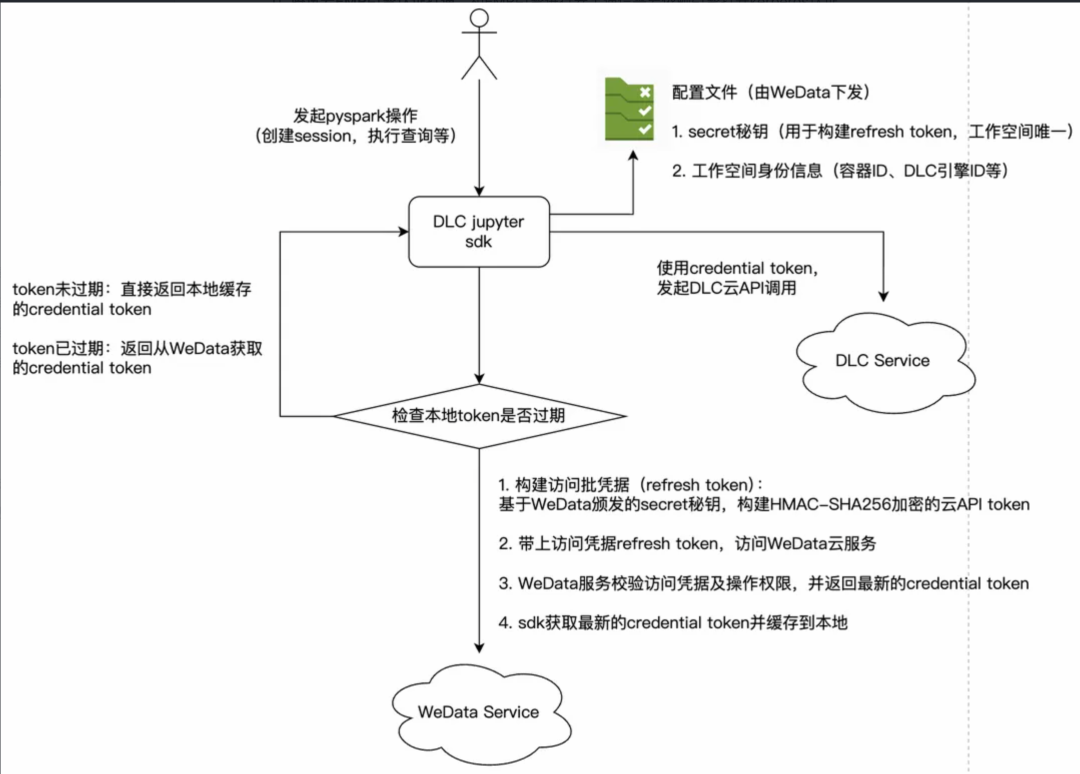
该方案关键点:
● Credential token:用于 DLC jupyter sdk 访问 DLC 云端引擎执行大数据分析操作,该 token 由 WeData 托管和下发,来源于用户授权 WeData 访问 DLC 引擎的 CAM policy,默认5分钟过期。
● Refresh token:sdk 访问 WeData 服务的凭证,用于定时刷新 credential token,该 token 是标准的 JWT 格式,payload 中包含 IDE 工作空间身份信息(容器 ID、DLC 引擎 ID 等),signature 部分是基于一串secret 秘钥使用 HMAC-SHA256 进行加密计算生成,默认 5 分钟过期。
● Secret 秘钥:WeData 在向工作空间下发配置时颁发的一套和工作空间绑定的秘钥串,用于校验 refresh token 的合法性。
该方案无需用户做任何配置即可完成 DLC sdk 到 DLC 引擎的安全通信,并将安全信息泄露风险降到最低。
大数据引擎分析演示
现在有一份经过前期数据加工得到的一份 Mercedes-Benz 股票价格趋势数据存储,使用 PySpark 读取 EMR-hive 表数据并结合 prophet 时间序列算法 (https://——facebook.github.io/prophet/docs/quick_start.html )来训练一个股票价格预测模型,最后进行模型准确性的评估和预测。
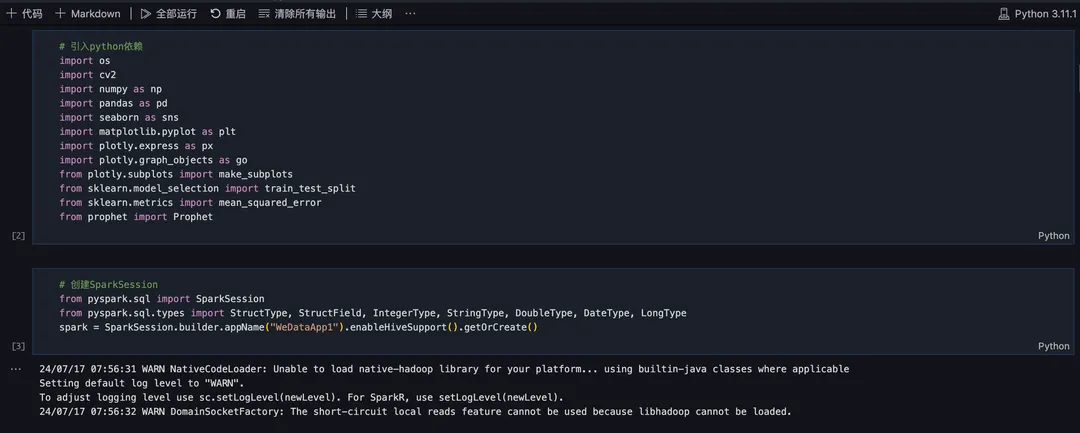
1)创建 ipynb 脚本并准备依赖环境
引入 python 依赖并创建 spark-session:
2)数据集导入 HIVE 表
数据集来自 kaggle: https://ww——w.kaggle.com/datasets/innocentmfa/mercedes-benz-historical-stock-dataset
将 CSV 格式的数据集导入 HIVE 表,数据集一共有 1100 行左右的数据:
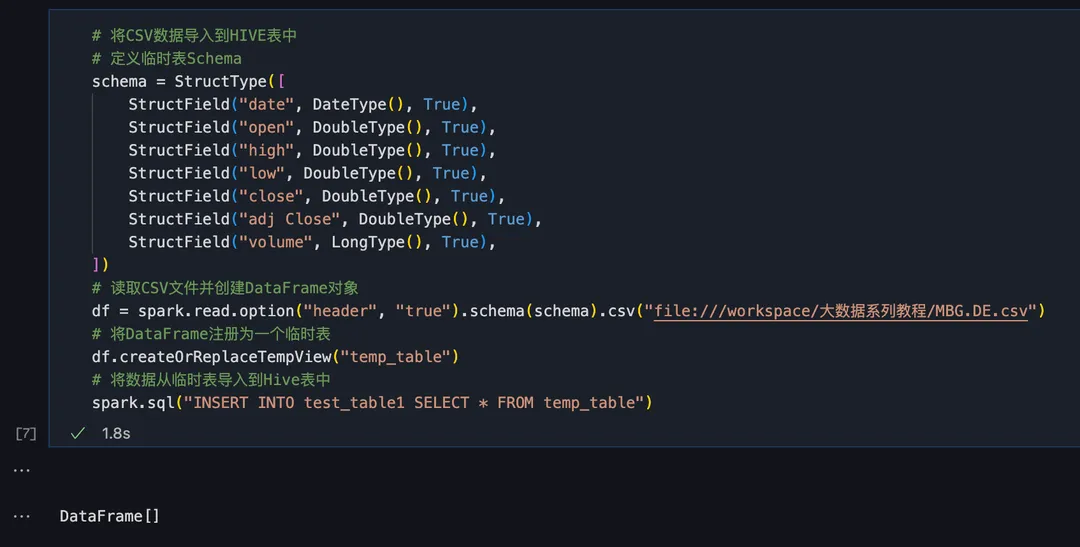
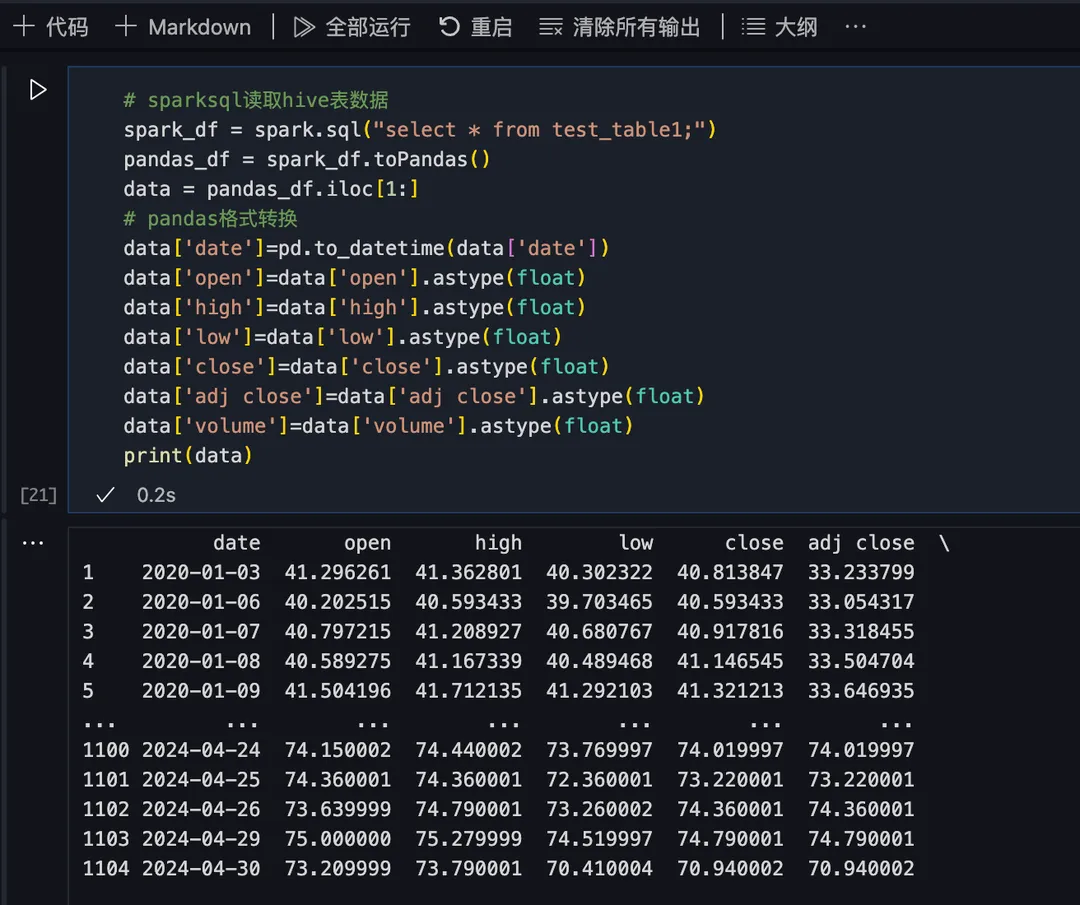
3)Sparksql 读取表数据并转换为 pandas 格式
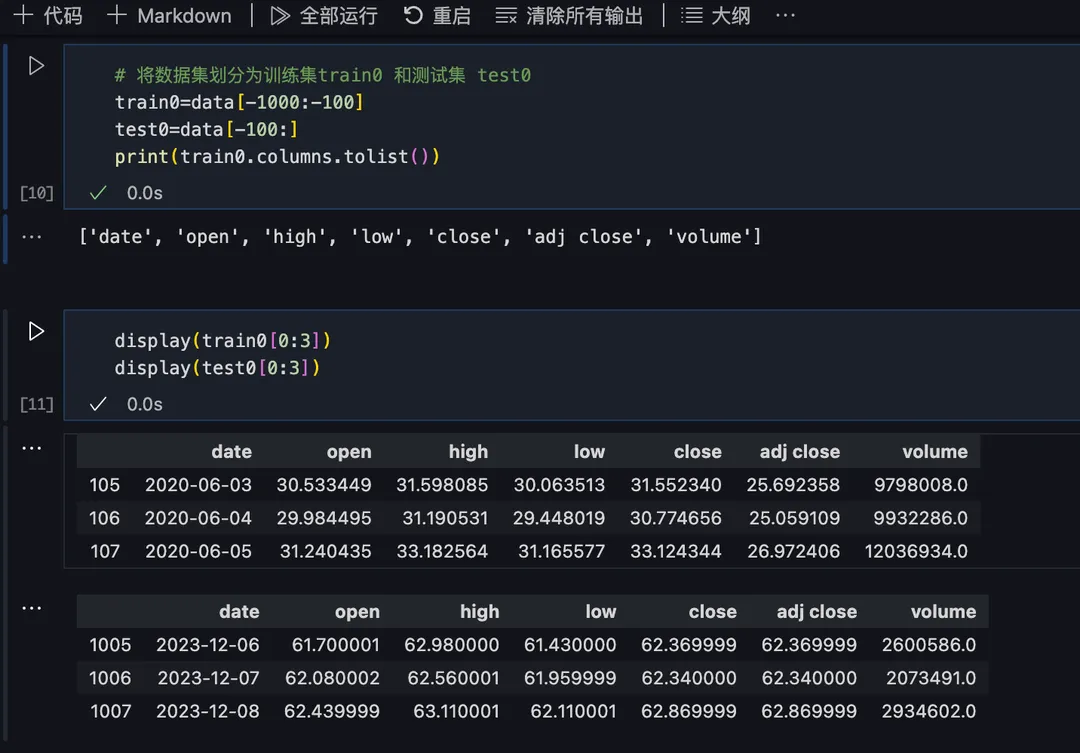
4)切分数据集
数据集划分为训练集 train0 和测试集 test0,用于后续训练预测模型及模型准确性评估:
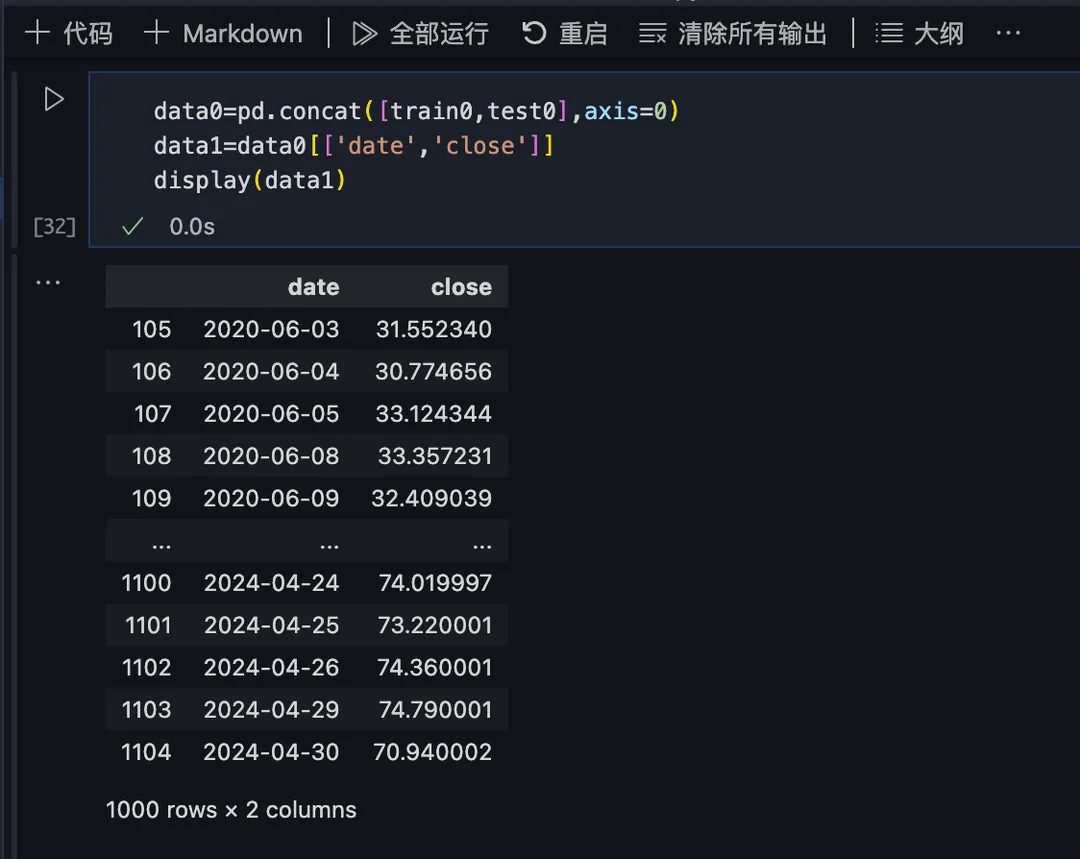
5)训练预测模型
准备训练数据,选取数据全集的 date 和 close字段作为训练数据(data1):
创建 Prophet 模型实例用于时间序列预测,用训练后的 Prophet 模型对 data1 数据集进行预测,将预测结果存在 forecast 中:
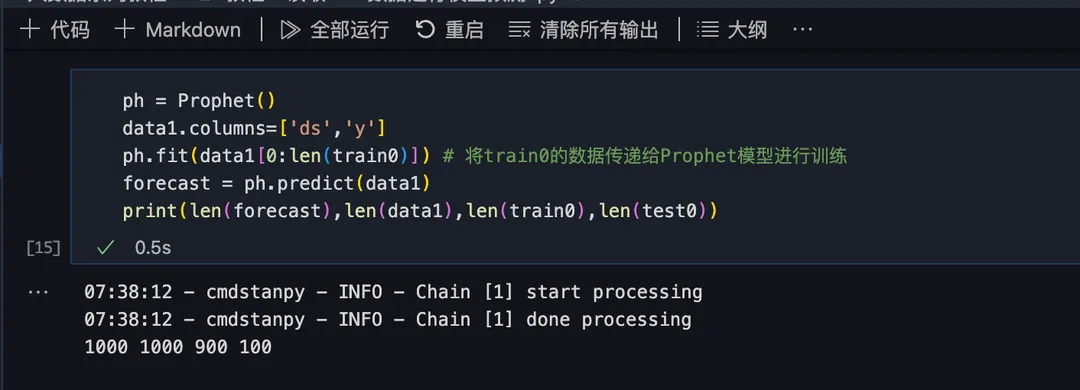
预览一下预测结果:
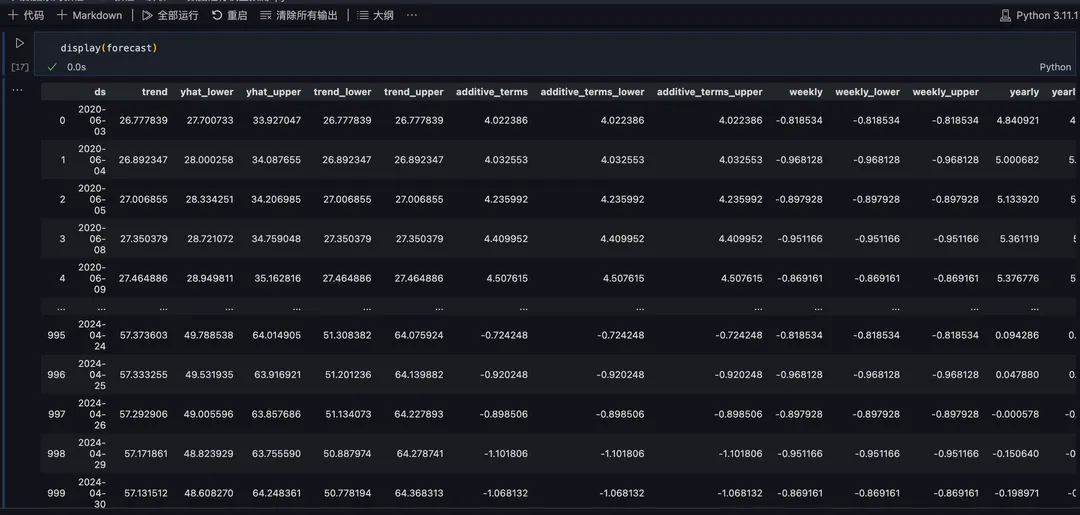
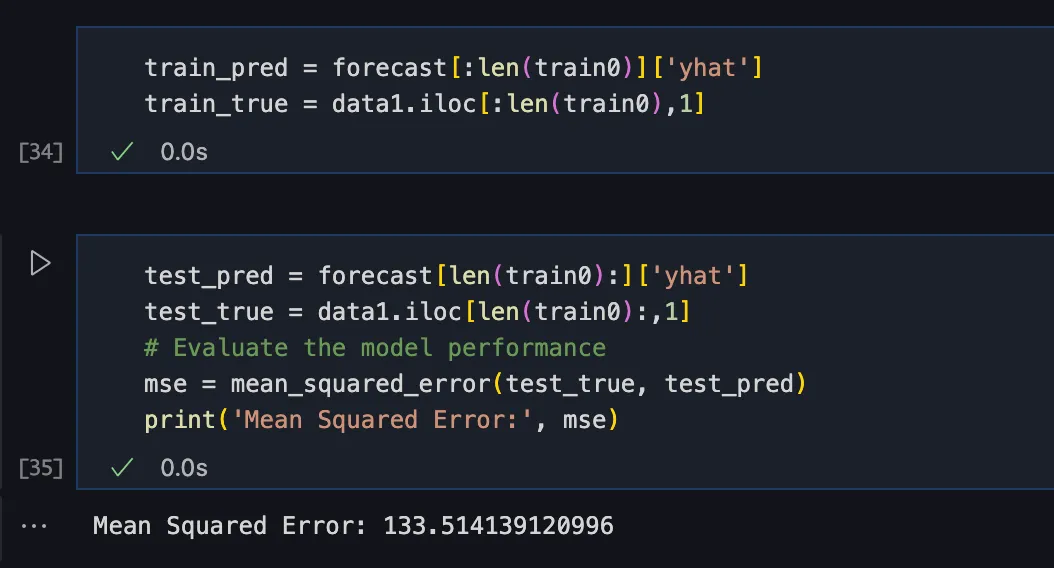
6)预测结果评价
用均方根误差对总计 100 条的预测结果进行评价:
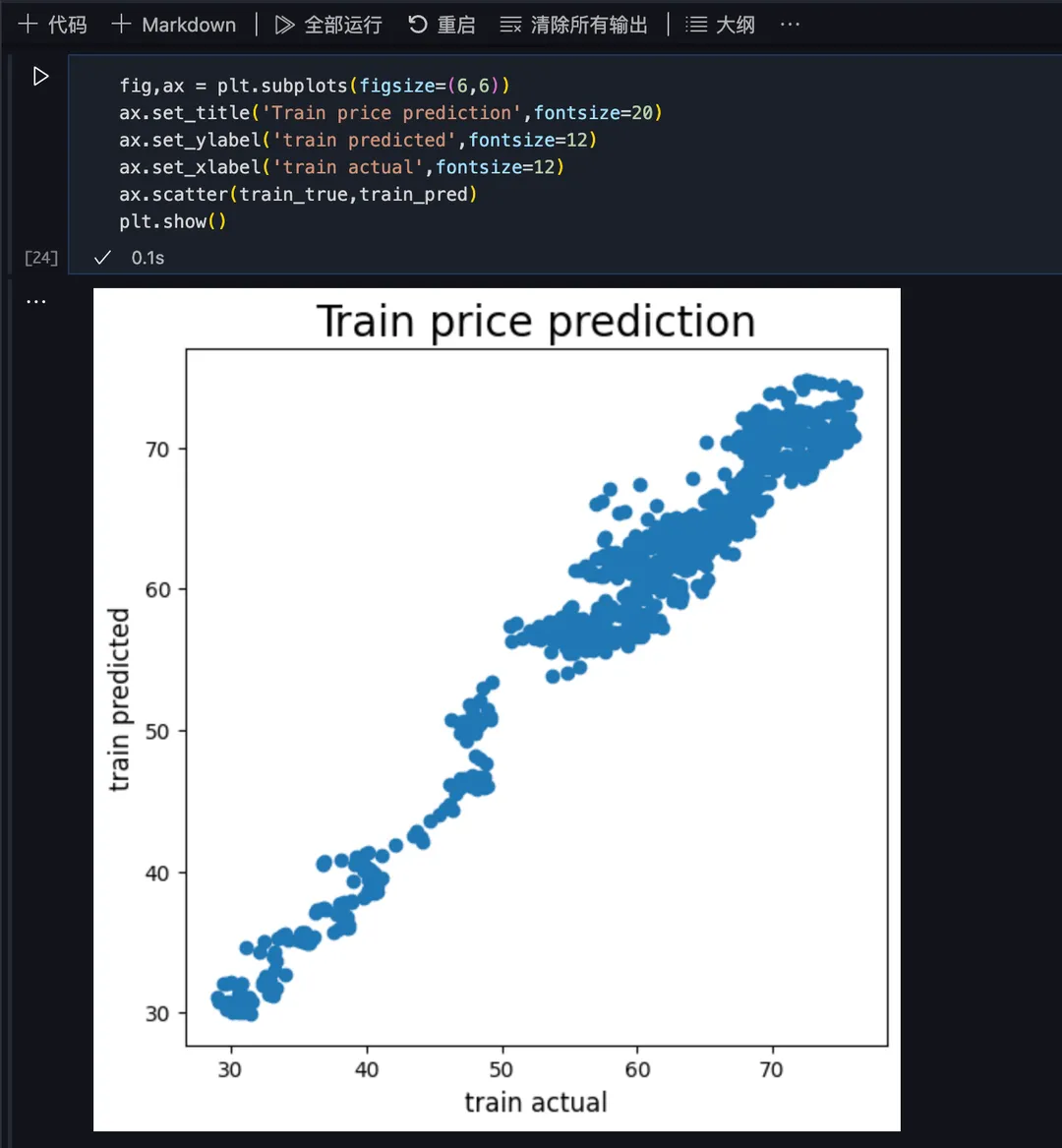
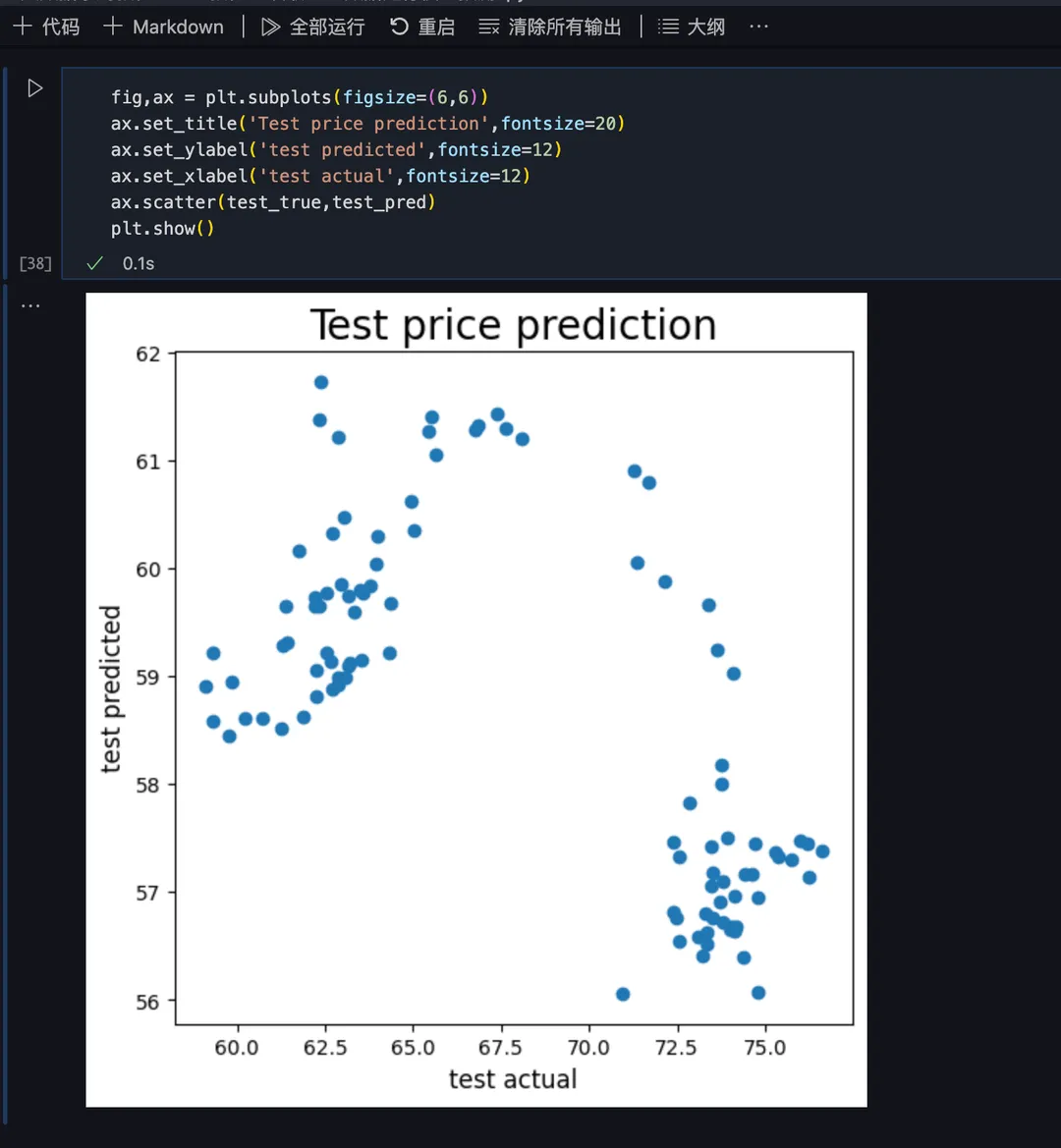
用 matplotlib.pyplot 库绘制散点图,x 轴为实际数据,y 轴为预测数据,数据越分散表明预测偏差越大,
先评价训练数据集的预测偏差情况,可以看出偏差相对较小:
再评价测试数据集的预测偏差情况,偏差就比较大了:
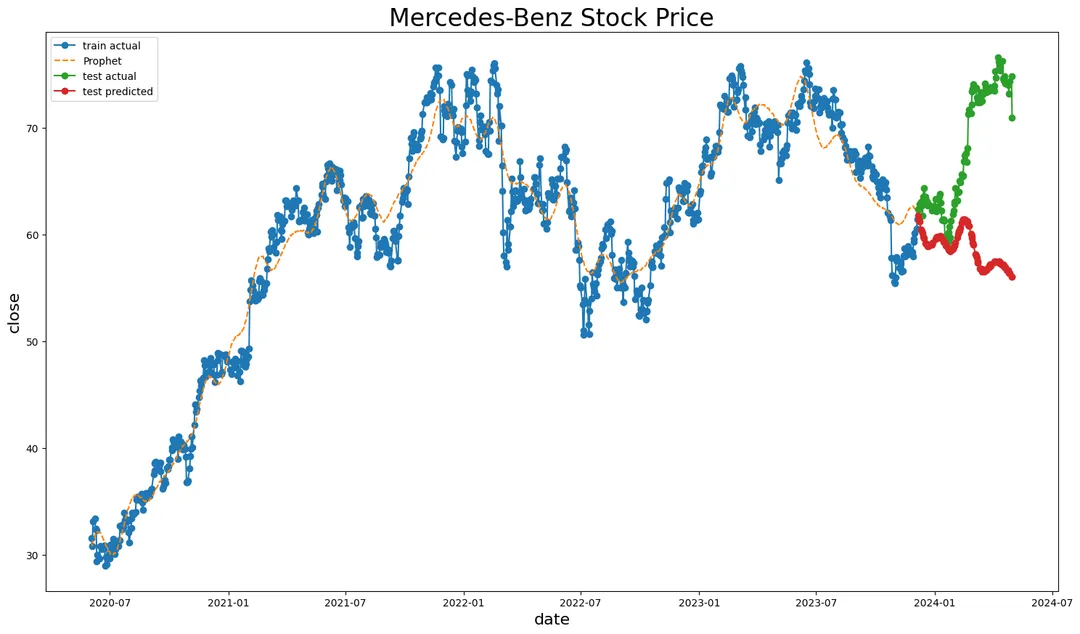
将训练数据集、测试数据集以及预测数据一起绘制折线图,可以具体看出预测数据偏差情况:

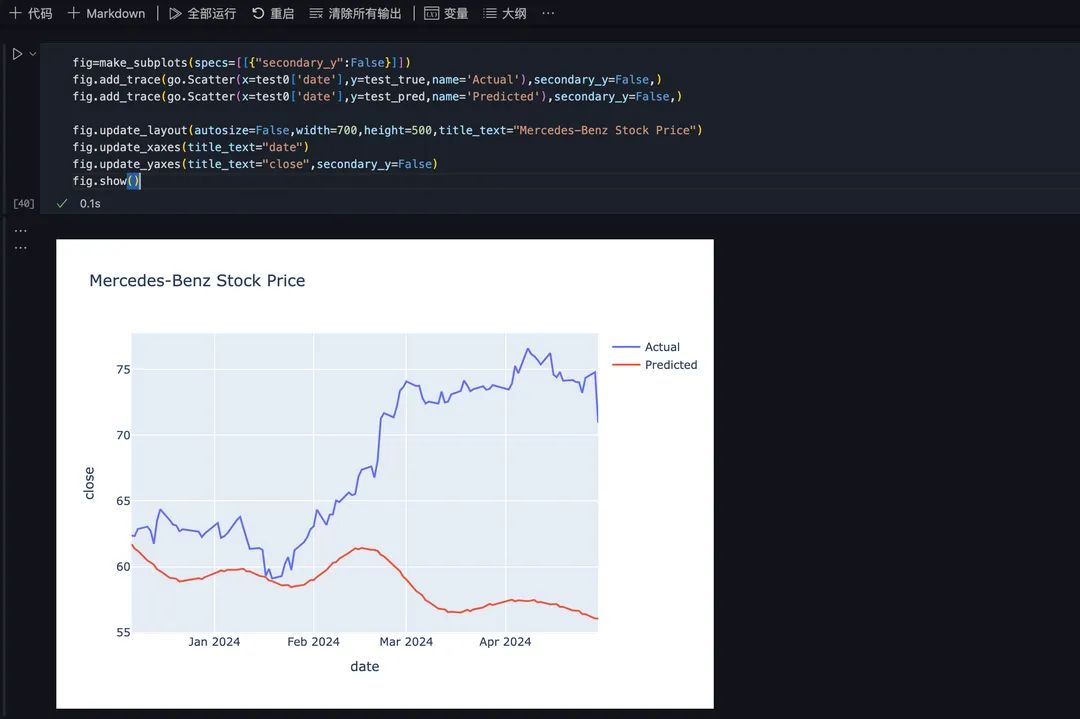
最后将 2023 年 12 月到 2024 年 5 月这段时间的预测数据和测试数据绘制成更详细的折线图进行对比:
7)保存模型
后续就是对模型进行进一步调优、训练及评价了,也可以将模型持久化保存到工作空间 /workspace 资源目录下,用于后续训练:

总结及展望
腾讯云 WeData Notebook 探索提供了一站式的集数据分析、数据生产、模型训练为一体的交互式 Jupyter Notebook 开发环境,和云端大数据引擎 EMR 和 DLC 进行了深度联动,实现了从数据生产到数据分析的全链路支持,未来将会在此基础上更进一步打造 Notebook 任务的调度编排及监控运维等一系列周边功能。
关注腾讯云大数据公众号
邀您探索数据的无限可能
