❝基因家族分析是生物信息学入门学习的基石,由于其对硬件要求不高个人电脑均可进行,不仅投入小、操作简单,而且产出效果显著,因此受到了广大生物信息学初学者的喜爱。虽然相关的研究文章层出不穷,但许多内容趋于雷同,缺乏创新性。为了突破这一局限,「本次在第三版的基础上进行了全面的内容优化,并引入了多个Python自动化脚本,来简化分析过程」,本节来介绍如何使用R包一键化计算蛋白理化性质 ❞
原理介绍
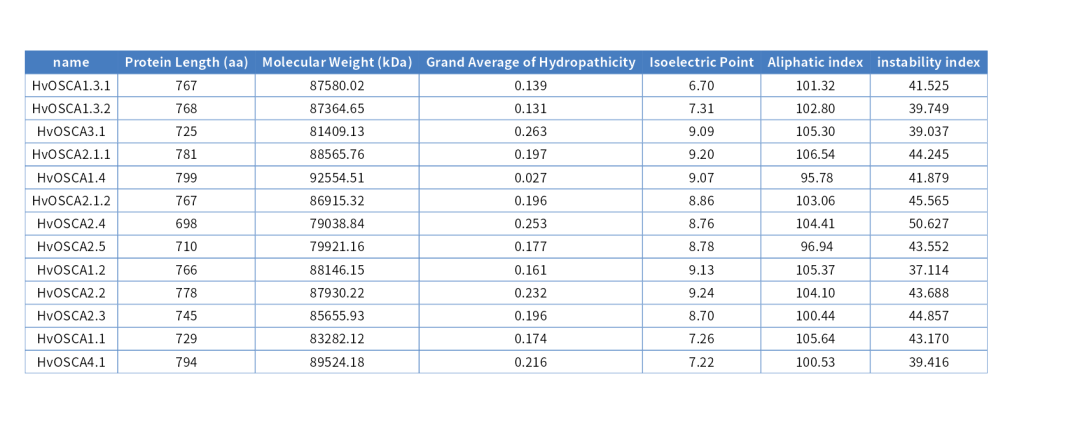
❝主要包括氨基酸长度、分子量、等电点、 脂肪族指数、不稳定指数及疏水性指数等,以往这些内容的分析主要通过网页工具进行分析,一旦数据序列较多则费时 费力。基于此类情况小编制作了一款 R 包 ggGenesfa 用于各种理化指标的计算,用此包可以很方便的计算出多种理化信息, 下面来主要介绍如何使用。 ❞
本地安装R包
代码语言:javascript
复制
install.packages("ggGenesfa_1.0.tar.gz",repos = NULL)
加载包
代码语言:javascript
复制
library(seqinr)
library(Peptides)
library(tidyverse)
library(magrittr)
library(ggGenesfa)
library(ggpubr)
计算理化性质
通过calculate_sequence_features函数可以很方便的计算,HvOSCA.pep.fasta为目标物种的蛋白序列文件。
代码语言:javascript
复制
calculate_sequence_features("HvOSCA.pep.fasta") %>%
set_colnames(c("name","Protein Length (aa)","Molecular Weight (kDa)",
"Grand Average of Hydropathicity",
"Isoelectric Point","Aliphatic index","instability index")) %>%
ggtexttable(rows=NULL,theme = ttheme("lBlueWhite"))+
theme(plot.margin=unit(c(0,5,0,5),units="cm"))