腾讯云 ES 目前提供了自定义 yml 配置。其中 indices.fielddata.cache.size 和 indices.query.bool.max_clause_count 支持通过界面修改,其他参数需要自己传入,每次的配置修改都需要重启集群后生效。针对一些集群常见问题,可通过调整参数来解决。以下案例仅针对腾讯云现阶段支持的自定义参数。
集群熔断
现象
十个集群有八个熔断,还有两个正在熔断的边缘试探。日志中较为常见的报错:
Data too large, data for [<transport_request>] would be [16913285988/15.7gb]pressure too high, (smooth) bulk request circuit break腾讯云 ES 中导致熔断的原因通常是 jvm old 区负载较高,当使用率超过85%时开始写拒绝,使用率超过90%时开始读拒绝。
解决方案
- 清理 fielddata cache
GET /_cat/indices?v&h=index,fielddata.memory_size&s=fielddata.memory_size:desc
POST /${fielddata占用内存较高的索引}/_cache/clear?fielddata=true2.调整参数
修改 indices.fielddata.cache.size 参数
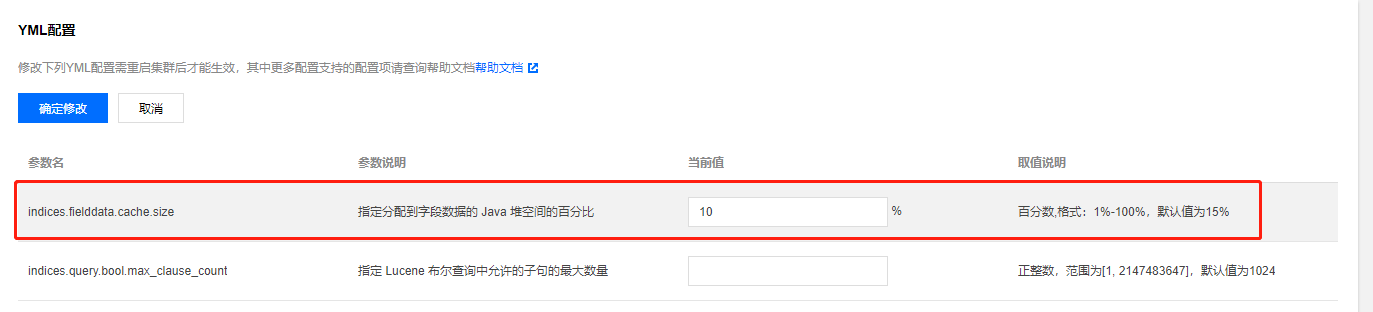
这个参数限制分配的 fielddata 堆空间大小,单位%,默认为15%。为避免有过多 fielddata 堆积导致占用 jvm old,可适当调小此参数。
和集群索引熔断相关的参数还有 accounting_requests,inflight_requests 的限制等。但目前腾讯云 ES 暂不支持此类参数的自定义修改。
bulk 拒绝
当集群出现 bulk 拒绝时,通常都是因为 queue 线程池满了,queue 默认值为1024。
现象
{"reason":"rejected execution of org.elasticsearch.transport.TransportService$7@5436e129 on EsThreadPoolExecutor[bulk, queue capacity = 1024, org.elasticsearch.common.util.concurrent.EsThreadPoolExecutor@6bd77359[Running, pool size = 12, active threads = 12, queued tasks = 2390, completed tasks = 20018208656]]","type":"es_rejected_execution_exception"}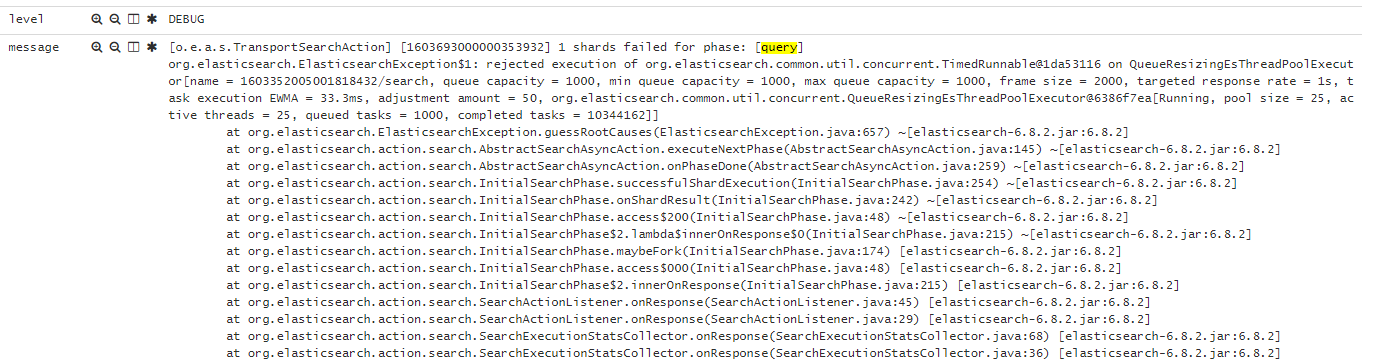
解决方案
1.优化集群索引分片
保证索引主分片和副本数之和为节点数的整数倍,并且单分片 size 保持在50G 以内
2.调整参数
修改 thread_pool.write.queue_size、thread_pool.search.queue_size 参数
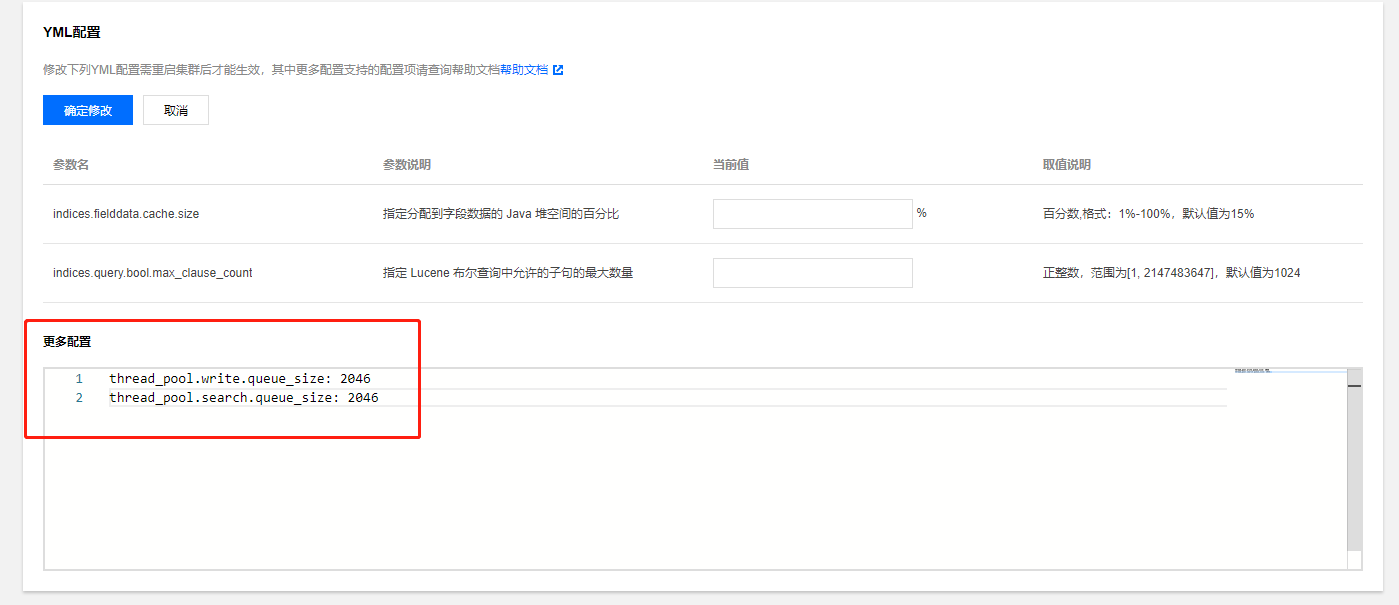
两者分别对应文档的写入队列参数和文档的查询队列参数,缺省值都为1024。当出现线程池满的情况,可针对这两个值进行适当调大,但增大线程池的同时也会带来集群 CPU 和 内存的消耗,因此调大线程池只适用于短时间内出现读写突增情况。