前几天写了一篇《如何设计一个电子计算器》,一个朋友看了之后说实在太low,好吧,依照他的意思,那我就采用文中FPGA设计的方式,然后自己从指令集设计、cpu设计、汇编器设计、汇编程序设计一路设计过去,完全从零开始设计,再多写个几篇水文,组一个系列,取名就叫《深入设计电子计算器》。基本的计算器原理方面,还是先看一下《如何设计一个电子计算器》。
- CPU整体结构
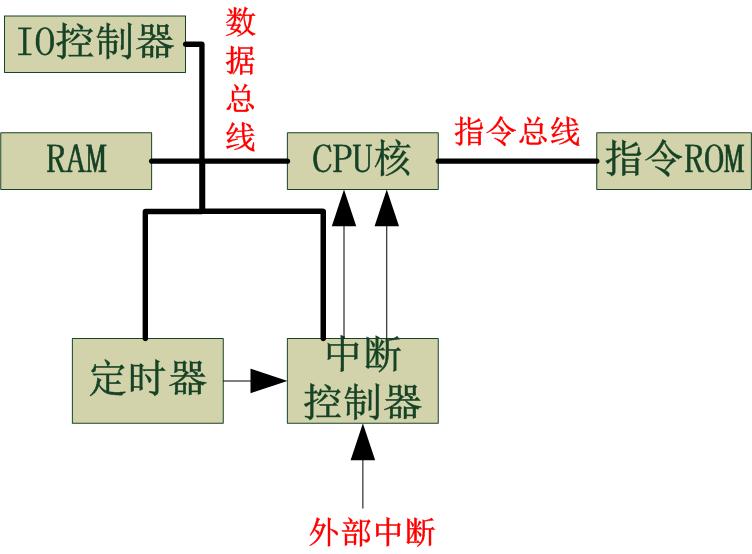
我设计的第一步,是设计CPU整体的框架。我打算采用哈佛结构,即指令存储和数据存储分离,两套总线。
虽然这是一个简单的演示处理器,当然也是要引入中断机制,外部接两个中断信号,应该是足够的,一个用于定时器用,一个用于外部中断。另外,考虑到中断的方式以及中断嵌套、排队等关系,使用一个中断控制器会比较方便。
另外,CPU最终目的用来控制IO,得有一个IO控制器来做所有通用IO的管理。
为了方便的控制定时器、中断控制器、IO控制器,可以把这三者都接到数据总线上,简单便利。有的处理器的数据总线只访问RAM,其他硬件的访问再开一套通信借口,这可能是基于历史的原因,这使得在不嵌入汇编或者引入库的情况下无法用C语言完成所有的操作。我这里设计的虽然不是完全按RISC来,但也还是使用RISC的逻辑,不会为设备独立开一套通信机制。
总而言之,整个CPU架构如下:
- CPU核的考虑
CPU核是CPU的关键所在。想起09年时想在chinaunix的CPU与编译器版召集大家一起来设计一个32位处理器来学习学习,并移植gcc或者llvm来编译C语言,当时考虑做一个RISC,采用三条流水线,最终移植编译器有人而一起设计CPU没人,所以不得不作罢,想来也有些可惜。当然,本系列只是一个抛砖引玉,我并不打算用较深的原理来设计这个例子CPU,那会花费很多的时间与精力,而是以此作为一个例子。
但虽为例子,也是应该可以完好的运行才行,这里可以采取早年的单片机思路。早年的单片机并非流水线架构,每条指令的执行过程取指令、译码、取操作数、执行等是顺序关系,虽然效率低,但对于单片机的很多应用来说足够了。
另外一点,RISC的等长指令是很值得考虑的,否则取指令的过程都是一个包含译码在内的状态机,所以等长指令还是很吸引人的。
于是,考虑到这里,我打算设计此CPU为16位处理器,CPU核中有8个通用寄存器,为r0~r7,都为16位寄存器。当然,指令存储和数据存储分开,采用哈佛结构,两套总线,这个之前已经提过。另外,指令为等长指令,每个指令2个字节,也就是16bits。有个2字节的PC代表当前指令的ROM地址/2。
另外,所有通用寄存器上复位之后初始值全为0。
- 中断向量
指令ROM上提供三个地址,分别用于复位、定时器中断、外部中断起始运行指令地址。
这三个地址分别是:
复位 | 0X00000000 |
|---|---|
定时器中断 | 0X00000006 |
外部中断 | 0X0000000C |
之所以我设计此处,每两个中断之间差6个字节,是因为可以足够写上三条指令,从而跳转到任意指令地址。
- 标志
共有Z、G、L、I四个标志。
指令集中,所有的赋值指令、算术指令、逻辑指令都会影响ZGL三个标志,相关的会根据结果设置,不相关的会清零。所有的赋值指令、算术指令(mul/unul/div/udiv除外)、逻辑指令计算得到零的,都会设置Z标志。sub/subi/cmp/ucmp/cmpi/ucmpi同时也与GL两个标志关联,G意味着大于,L意味着小于,sub/subi的GL标志设置是由无符号来判断的。
所有的条件跳转指令(bz/bnz/bg/bl/bgz/blz)如果跳转成功,则ZGL都被清零,否则不变。
b/br/call/callr/ret会清零ZGL。
I标志在中断时被设置,reti调用之后恢复中断前压栈的所有寄存器、标志(见后,不排除存在中断嵌套的情况,使得reti之后紧接着依然是I标志被设置)。
- 栈
r7为栈指针。
压栈是指将指定的值传入r7*2所指向的数据RAM,然后r7自加1。
退栈是指r7先自减1,然后r7*2所指向的数据RAM传出到指定的寄存器。
中断的压栈比较特殊,因为中断之后要恢复之前所有一切不包括RAM在内的CPU状态,包括所有通用寄存器、标志、PC,reti之后也会把这些退栈恢复。
- 指令集
指令集的设计基于以下两个原则:
(1)指令完备
要涵盖赋值、计算、跳转以及RAM和寄存器之间的互传,还要考虑如何支持中断处理以及对过程调用(C语言函数)的支持。
(2)指令等长
每条指令2个字节,也就是16bits,每条指令尽量可以表达更多的信息,也就是尽量用满这16bits。我们的指令数范围大约16~31,于是操作用5bits编码,通用寄存器有8个,所以指定寄存器用3bits编码。
设置以下指令:(rn、rm这里,n、m为寄存器数字编号;i为立即数,但不同指令范围有区别;=>代表将左边的值赋值给右边;[rn]在这里代表rn*2地址的数据RAM里的数据)
赋值指令:
mov rn,rm,i | rm+i=>rn | 此处i为立即数,范围-16~15 |
|---|---|---|
movi rn,i | i=>rn | 此处i为立即数,范围0~255 |
movli rn,i | i=>rn[7:0] | 此处i为立即数,范围0~255 |
movhi rn,i | i=>rn[15:8] | 此处i为立即数,范围0~255 |
movtr rn,rm | rm=>[rn] | |
movfr rn,rm | [rm]=>rn | |
movitr rn,rm | ROM[rm]=>rn | 将rm*2地址的指令ROM内容取出放进rn寄存器,主要为了兼容C语言 |
算术指令:
很多单片机未必有乘法和除法指令,我考虑了一下还是加上这两类指令。而对于很多CPU都有的除零错误,我这里决定不给出。
add rn, rm,i | rn+rm+i=>rn | 此处i为立即数,范围-16~15 |
|---|---|---|
sub rn,rm,i | rn-rm-i=>rn | 此处i为立即数,范围-16~15 |
addi rn,i | rn+i=>rn | 此处i为立即数,范围0~255 |
subi rn,i | rn-i=>rn | 此处i为立即数,范围0~255 |
mul rn,rm | rnXrm=>r2:r3 | 此为有符号整数乘法,结果中r2为高16位,r3为低16位 |
umul rn,rm | rnXrm=>r2:r3 | 此为无符号整数乘法,结果中r2为高16位,r3为低16位 |
div rn,rm,rq | r2:r3/rn=>rm,rq | 有符号除法,rn为除数,rm为商,rq为余数 |
udiv rn,rm,rq | rnXrm=>r2:r3 | 无符号除法,rn为除数,rm为商,rq为余数 |
cmp rn,rm | 有符号比较,并设置ZGL标志 | 不影响通用寄存器的值,具体语意见后面 |
ucmp rn,rm | 无符号比较,并设置ZGL标志 | 不影响通用寄存器的值,具体语意见后面 |
cmpi rn,i | 有符号比较,并设置ZGL标志 | 不影响通用寄存器的值,i范围-128~127 |
ucmpi rn,i | 无符号比较,并设置ZGL标志 | 不影响通用寄存器的值,i范围0~255 |
逻辑指令:
and rn, rm, rq | rm&rq=>rn | |
|---|---|---|
or rn, rm, rq | rm|rq=>rn | |
xor rn, rm, rq | rm^rq=>rn | |
not rn, rm | ~rm=>rn | |
sl rn,rm,i | rm<<i=>rn | i为立即数,范围0~15 |
sr rn,rm,i | rm>>i=>rn | i为立即数,范围0~15 |
slr rn,rm,rq | rm<<rq[3:0]=>rn | |
srr rn,rm,rq | rm>>rq[3:0]=>rn | |
testb rn,i | 用寄存器rn的第i位取反的值设置Z标志 | 本指令不影响通用寄存器,i范围为0~15 |
testbr rn,rm | 用寄存器rn的第rm[3:0]位取反的值设置Z标志 | 本指令不影响通用寄存器,i范围为0~15 |
栈指令:
pushi i | 将i压栈 | 压栈的意义见说明,i的范围为0~2047 |
|---|---|---|
push rn | 将rn的值压栈 | 压栈的意义见说明 |
pop rn | 退栈,值赋给rn | 退栈的意义见说明 |
跳转指令:
这里的跳转指令考虑了我两周,主要是希望C语言的兼容,以及指令的完备。从而涉及到一些标志问题,从而要返到前面去考虑前面指令的意图,另外又在前面添加了cmp指令和testb指令。
b i | 无条件跳转到当前指令地址+i*2 | 此处i范围为-1024~1023 |
|---|---|---|
br rn | 无条件跳转到rn*2的指令地址 | 此处i范围为-1024~1023 |
bz i | 如果Z标志被置起则跳转到当前指令地址+i*2 | 此处i范围为-1024~1023 |
bnz i | 如果Z标志未置起则跳转到当前指令地址+i*2 | 此处i范围为-1024~1023 |
bg i | 如果G标志被置起则跳转到当前指令地址+i*2 | 此处i范围为-1024~1023 |
bl i | 如果L标志被置起则跳转到当前指令地址+i*2 | 此处i范围为-1024~1023 |
bgz i | 如果G标志或Z标志被置起则跳转到当前指令地址+i*2 | 此处i范围为-1024~1023 |
blz i | 如果L标志或Z标志被置起则跳转到当前指令地址+i*2 | 此处i范围为-1024~1023 |
call i | 把下一条指令地址压栈,并跳转到当前指令地址+i*2的指令地址 | 此处i范围为-128~127 |
callr rn | 把下一条指令地址压栈,并跳转到rn*2的指令地址 | |
ret | 出栈两个字节,然后跳转到这2个字节的值*2的指令地址 | |
reti | 中断例程返回 | 具体语意见“栈”、“标志” |
这些指令对于CPU基本是完备了。
- 机器码指令
每个指令编码2个字节,如下所示,op就是编码的2个字节16bits,其中没有被编的bit,填0即可。
mov rn,rm,i | 0=>op[4:0],n=>op[7:5],m=>op[10:8],i=>op[15:11] |
|---|---|
movi rn,i | 1=>op[4:0],n=>op[7:5],i=>op[15:8] |
movli rn,i | 2=>op[4:0],n=>op[7:5],i=>op[15:8] |
movhi rn,i | 3=>op[4:0],n=>op[7:5],i=>op[15:8] |
movtr rn,rm | 4=>op[4:0],n=>op[7:5],m=>op[10:8],0=>op[15:14] |
movfr rn,rm | 4=>op[4:0],n=>op[7:5],m=>op[10:8],1=>op[15:14] |
movitr rn,rm | 4=>op[4:0],n=>op[7:5],m=>op[10:8],2=>op[15:14] |
add rn, rm,i | 5=>op[4:0],n=>op[7:5],m=>op[10:8],i=>op[15:11] |
sub rn,rm,i | 6=>op[4:0],n=>op[7:5],m=>op[10:8],i=>op[15:11] |
addi rn,i | 7=>op[4:0],n=>op[7:5],i=>op[15:8] |
subi rn,i | 8=>op[4:0],n=>op[7:5],i=>op[15:8] |
mul rn,rm | 9=>op[4:0],n=>op[7:5],m=>op[10:8],0=>op[15:14] |
umul rn,rm | 9=>op[4:0],n=>op[7:5],m=>op[10:8],1=>op[15:14] |
div rn,rm,rq | 9=>op[4:0],n=>op[7:5],m=>op[10:8],q=>op[13:11],2=>op[15:14] |
udiv rn,rm,rq | 9=>op[4:0],n=>op[7:5],m=>op[10:8],q=>op[13:11],3=>op[15:14] |
cmp rn,rm | 10=>op[4:0],n=>op[7:5],m=>op[10:8],0=>op[15] |
ucmp rn,rm | 10=>op[4:0],n=>op[7:5],m=>op[10:8],1=>op[15] |
cmpi rn,i | 11=>op[4:0],n=>op[7:5],i=>op[15:8] |
ucmpi rn,i | 12=>op[4:0],n=>op[7:5],i=>op[15:8] |
and rn, rm, rq | 13=>op[4:0],n=>op[7:5],m=>op[10:8],q=>op[13:11],0=>op[15:14] |
or rn, rm, rq | 13=>op[4:0],n=>op[7:5],m=>op[10:8],q=>op[13:11],1=>op[15:14] |
xor rn, rm, rq | 13=>op[4:0],n=>op[7:5],m=>op[10:8],q=>op[13:11],2=>op[15:14] |
not rn, rm | 13=>op[4:0],n=>op[7:5],m=>op[10:8],3=>op[15:14] |
sl rn,rm,i | 14=>op[4:0],n=>op[7:5],m=>op[10:8],i=>op[14:11],0=>op[15] |
sr rn,rm,i | 14=>op[4:0],n=>op[7:5],m=>op[10:8],i=>op[14:11],1=>op[15] |
slr rn,rm,rq | 15=>op[4:0],n=>op[7:5],m=>op[10:8],q=>op[13:11],0=>op[15] |
srr rn,rm,rq | 15=>op[4:0],n=>op[7:5],m=>op[10:8],q=>op[13:11],1=>op[15] |
testb rn,i | 16=>op[4:0],n=>op[7:5],i=>op[11:8],0=>op[15] |
testbr rn,rm | 16=>op[4:0],n=>op[7:5],m=>op[10:8],1=>op[15] |
pushi i | 17=>op[4:0],i=>op[15:5] |
push rn | 18=>op[4:0],n=>op[7:5],0=>op[15] |
pop rn | 18=>op[4:0],n=>op[7:5],1=>op[15] |
b i | 19=>op[4:0],i=>op[15:5] |
br rn | 20=>op[4:0],n=>op[7:5] |
bz i | 21=>op[4:0],i=>op[15:5] |
bnz i | 22=>op[4:0],i=>op[15:5] |
bg i | 23=>op[4:0],i=>op[15:5] |
bl i | 24=>op[4:0],i=>op[15:5] |
bgz i | 25=>op[4:0],i=>op[15:5] |
blz i | 26=>op[4:0],i=>op[15:5] |
call i | 27=>op[4:0],i=>op[15:5] |
callr rn | 28=>op[4:0],n=>op[7:5] |
ret | 29=>op[4:0],0=>op[15] |
reti | 29=>op[4:0],1=>op[15] |
还有30/31两个指令类型没有使用,将来有必要还可以扩展一下。其实testb/testbr可以和cmp/ucmp合用,这样就又可以多出来一个,不过看在两者有点区别的份上,就算了。
以上为本系列的第一篇,花了我一定的精力,我也尽力尽快补上接下来的几篇,过程中错误难免,希望大家给予指正。
《深入设计电子计算器》