腾讯AI Lab计算机视觉中心人脸&OCR团队是2016年11月底开始组建和开展工作,我们以研发业界领先的算法为目标驱动,逐步克服人手不足、训练数据不足等困难,不断夯实基础,做既有原创性又能落地应用的国际前沿研究。在上一期(腾讯AI Lab 计算机视觉中心人脸&OCR团队近期成果介绍(1))中已经介绍了我们团队的一些研究成果,近期,我们团队有一些新的成果再和大家进一步分享。
1
人脸研究进展
人脸研究的两大关键任务是人脸检测与人脸识别。在上一期中,我们主要介绍了我们团队在人脸检测的两个国际权威评测平台(WIDER FACE和FDDB)上的研究成果。近期,我们团队在人脸识别的关键任务上也取得突破,在人脸识别的国际权威评测平台(Megaface Challenge)中取得了国际领先的成果。同时,在人脸检测中,我们进一步提高了检测精度,重新刷新了记录。以下具体介绍。
1.1 人脸识别
人脸识别的国际权威评测平台Megaface是由美国华盛顿大学(University of Washington)发布并维护的一个著名的人脸评测平台。它以百万规模人脸注册情况下的1:N和1:1比对作为最重要的性能评定指标。Megaface一共有两个Challenge:Challenge 1可以使用任何外部的人脸数据来训练参赛模型,而Challenge 2严格限定使用官方提供的训练集来训练模型,因此Challenge 2上的评测结果更能体现参赛的人脸算法的性能。每个Challenge都有两个测试集(常规识别测试集和跨年龄识别测试集)。如表1到表4所示,我们原创的人脸算法在常规识别测试集(Facescrub)和跨年龄识别测试集(FGNet)这两项任务中的所有评测指标:识别准确率( 1:N Identification)和验证准确率( 1:1 Verification )均取得第一。该结果已于8月底发表在MegaFace的官网上。
(http://megaface.cs.washington.edu/results/facescrub_challenge2.html)。
表1. Megaface Challenge 2的常规识别测试集的识别准确率结果对比

表2. Megaface Challenge 2的常规识别测试集的验证准确率结果对比

表3. Megaface Challenge 2的跨年龄测试集的识别准确率结果对比
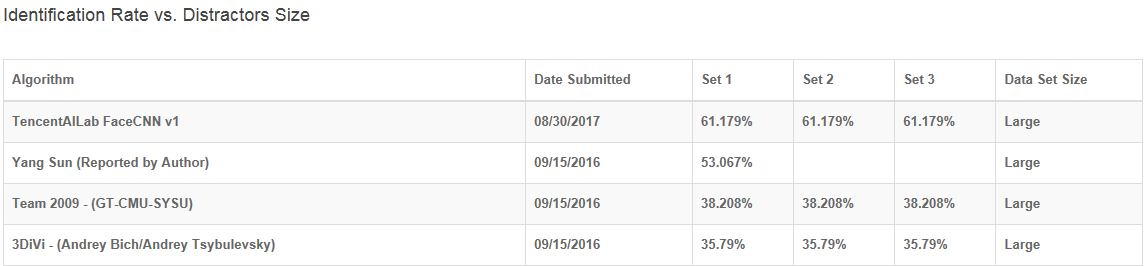
表4. Megaface Challenge 2的跨年龄测试集的验证准确率结果对比

1.2 人脸检测
人脸检测是人脸识别的前提和基础,在做人脸识别之前,需要先做人脸检测以检测出目标人脸的存在和精准位置信息。正如上一期介绍中所述,我们团队之前已经在人脸检测中取得佳绩,近期我们进一步改进了方法,在人脸检测的两大国际权威评测平台(WIDER FACE和FDDB)上取得了更好的结果。
在人脸检测国际权威评测平台WIDER FACE(这也是目前国际上难度最大的人脸检测的评测平台)上,如图1所示,我们的最新方法Face R-FCN在WIDER FACE的验证集和测试集的所有三个子集(Easy, Medium, and Hard)上都取得了第一名的佳绩,这个结果新近发布于WIDER FACE官网:
(http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/WiderFace_Results.html)。
相关技术文档(Yitong Wang, Xing Ji, Zheng Zhou, Hao Wang, Zhifeng Li. Detecting Faces Using Region-based Fully Convolutional Networks. arXiv preprint arXiv:1709.05256, 2017.)也已发布于arXiv网站,链接请见:
(https://arxiv.org/abs/1709.05256)。图2是一些人脸检测结果的样例,对于很多极具挑战性的人脸,我们的人脸检测模型也能很好的检测出来。


图1. 人脸检测国际权威评测平台WIDER FACE上的结果对比。第一行的三张图代表验证集的三个子集(Easy, Medium, and Hard)的结果对比,第二行的三张图代表测试集的三个子集(Easy, Medium, and Hard)的结果对比。我们的方法Face R-FCN在验证集和测试集的所有三个子集中都领先竞争对手。


图2. 人脸检测国际权威评测平台WIDER FACE上的人脸检测样例(绿框代表我们检测到的人脸,红框代表官方标注的人脸)
在人脸检测另一个国际权威评测平台FDDB上,我们也重新刷新了纪录,我们的最新方法Face R-FCN在FDDB评测的关键指标:离散得分曲线中,2000误检数时的召回率达到99.42%,位居第一。这个结果大幅超过了我们之前的结果(98.74%),进一步刷新了这个记录。更多细节可以参阅我们的技术报告:
https://arxiv.org/abs/1709.05256和FDDB官方网站:http://vis-www.cs.umass.edu/fddb/results.html#rocpub。
2
OCR研究进展
在上一期中我们介绍了我们团队在OCR的国际权威评测平台ICDAR(International Conference on Document Analysis and Recognition)竞赛里所取得的佳绩,我们当时在ICDAR的互联网图片(Born-Digital Images)数据集上的两个任务(文本定位和单词识别)上都取得国际领先。最近,我们在ICDAR竞赛的另一个核心数据集:对焦自然场景图片(Focused Scene Text Images),也取得突破。以下详细介绍。
2.1 对焦自然场景图片里的文本定位任务比赛(Task 1-Text Localization, ICDAR Focused Scene Text Images)
Focused Scene Text Image是用相机对准自然场景存在的文本拍摄得到的图像,这些文本包括海报、交通标志、告示牌、橱窗、店铺名称、衣服、铭牌等物体上的字符,文本定位任务就是确定图像中文本行的准确边界。该任务的训练集229幅,测试集233幅。由于自然场景中的文本定位和识别是OCR领域中的一个重要的研究方向,有一些研究机构和个人公布了自己收集和标注的数据集,通过搜集这些公开的数据集获得图像1560幅,作为补充训练集。在训练网络时,对训练集用了多种手段做了数据增强,实际训练集扩充到20000幅左右。我们的最新模型在该任务上取得了第一名的佳绩,如下图所示。

图3. 对焦自然场景图片里的文本定位任务比赛排名
(http://rrc.cvc.uab.es/?ch=2&com=evaluation&task=1)
部分检测结果如下图所示,全部的检测结果可在网站上查询,网址:
http://rrc.cvc.uab.es/ch=2&com=evaluation&view=method_samples&task=1&m=30717>v=1





图4. 部分文本检测结果
2.2. 对焦自然场景图片里的单词识别任务比赛(Task 3-Word Recognition,ICDAR Focused Scene Text Images)
Focused Scene Text Image单词识别任务需要在文本图像中抠出单词区域,四个边界向外扩展4个像素点,构成数据集,训练集848幅,测试集1095幅。在训练网络时,使用外部数据集约900万幅。采用CNN提取图像特征,采用RNN学习序列关系,进行识别。我们的最新模型在该任务上取得了第一名的佳绩,如下图所示。

图5. 对焦自然场景图片里的单词识别任务比赛排名
(http://rrc.cvc.uab.es/?ch=2&com=evaluation&task=3)
部分单词如下图所示,这些单词在字体、尺寸、排列间距、倾斜、阴影、背景、模糊等方面都有变化,我们一方面增强网络结构以适应这些变化,另一方面有针对性的生成大量的合成样本用于训练网络,最终克服了这些不利因素,正确识别出单词。

图6. 部分单词图像
2.3. 互联网场景图片里的文本定位任务比赛(Task 1-Text Localization,ICDAR Born Digital Images)
近期,我们改进了用于互联网图片文本检测的网络结构,再一次刷新了互联网场景图片里的文本定位任务比赛上的记录,如下图所示。

图7. 互联网图片文本检测任务上的排名
(http://rrc.cvc.uab.es/?ch=1&com=evaluation&task=1)
2.4. 互联网场景图片里的单词识别任务比赛(Task 3-Word Recognition,ICDAR Born Digital Images)
我们改进了用于互联网图片单词识别的网络结构,加入Attention机制来改善RNN的性能,再一次刷新了互联网场景图片里的单词识别任务比赛上的记录,如下图所示。

图8. 互联网图片单词识别任务上的排名
(http://rrc.cvc.uab.es/?ch=1&com=evaluation&task=3)
3
项目合作
人脸与OCR是计算机视觉领域应用非常广泛,受到工业界和学术界高度关注的一个研究领域和方向,不仅难度很大而且竞争非常激烈。因此我们团队研发的原创算法不仅需要在各种国际权威评测平台里验证算法的领先性,而且需要与业务部门开展项目合作,在产品侧落地应用以找出不足、补齐短板、提升性能,并利用海量业务数据不断迭代更新模型,以更好、更专业地服务伙伴部门。
就项目合作而言,我们人脸&OCR团队与TEG信安团队以及MIG互联网+合作事业部政企项目组都有着深入、密切的合作。由于团队人手紧张,近期我们主要聚焦于MIG互联网+合作事业部政企项目组的合作项目中。政企项目组旨在利用互联网技术,简化人们生活中的各种办事流程,让数据多跑路,百姓少跑腿,方便广大人民群众办事。其中,基于上传证件的身份认证是多项业务的基石。这种合作是双赢的,一方面,我们发挥自身的技术优势,提供稳定、准确、快速的证件人脸识别、人脸核对、文本识别等底层功能,政企项目组的同事利用这些功能展开上层业务逻辑,大幅提高服务效率并减少运营成本;另一方面,政企项目组的同事及时反馈合适的样本数据和失败案例给我们,我们则根据这些反馈改进算法和模型,并最终促进自身技术能力的提高。
关注《云端》专业号
TEG牛人牛事抢鲜看
