
作者介绍
azurezhao(赵阳),腾讯云数据库高级工程师,具备多年存储经验,包括文件存储、kv存储、数据库存储等。目前在腾讯专注于CDW PG数据库内核相关的研发。
1. 整体架构和设计目标
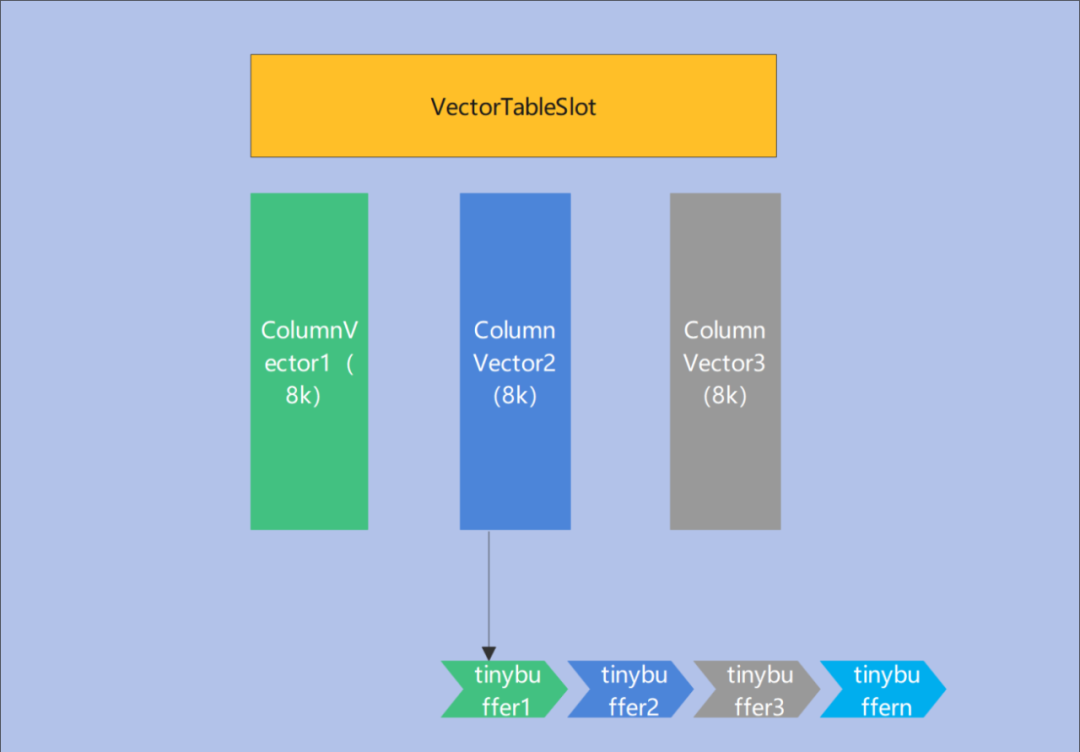
向量化计算层缓存(VectorTableSlot Cache, 下面简称VTS-Cache)。和传统的OLTP数据按行聚簇方式不同,在OLAP场景下,查询大多数是对某些列进行的,数据存储按照列式存储,查询运算时的数据也是按照列式存储,如下图所示。当前每次执行都需要去存储层读取数据,会有开销,所以考虑引入一层缓存层。但是在OLAP场景下,因为数据很大,如果使用一个类似OLTP下的BufferPool的磁盘-内存映射缓存,会因为频繁的换入换出导致缓存几乎不生效。所以考虑引入一层执行层的缓存,缓存的粒度是如下的ColumnVector,因为缓存的数据会带Qualification,所以能比较大的过滤一些数据,从而减少数据cache的量,并且支持DML,不影响数据的一致性,支持缓存的LRU淘汰机制,目前只对Estore支持,后续会考虑支持Heap表,从而为HTAP提供统一的缓存层。
2. 竞品对比
2.1 查询结果缓存(MySQL)
缓存语句,通过配置项和规则(内存大小、语句条件是否含有变量等等)将满足要求的语句和结果缓存在query_cache中,并且使用LRU规则做内存替换。
- 优点:对于前端透明,如果缓存命中,能有很大的收益。
- 缺点:必须语句一模一样,发生DDL、DML后数据全部失效,导致命中率不高。
在高版本MySQL中已经去除了这个特性。
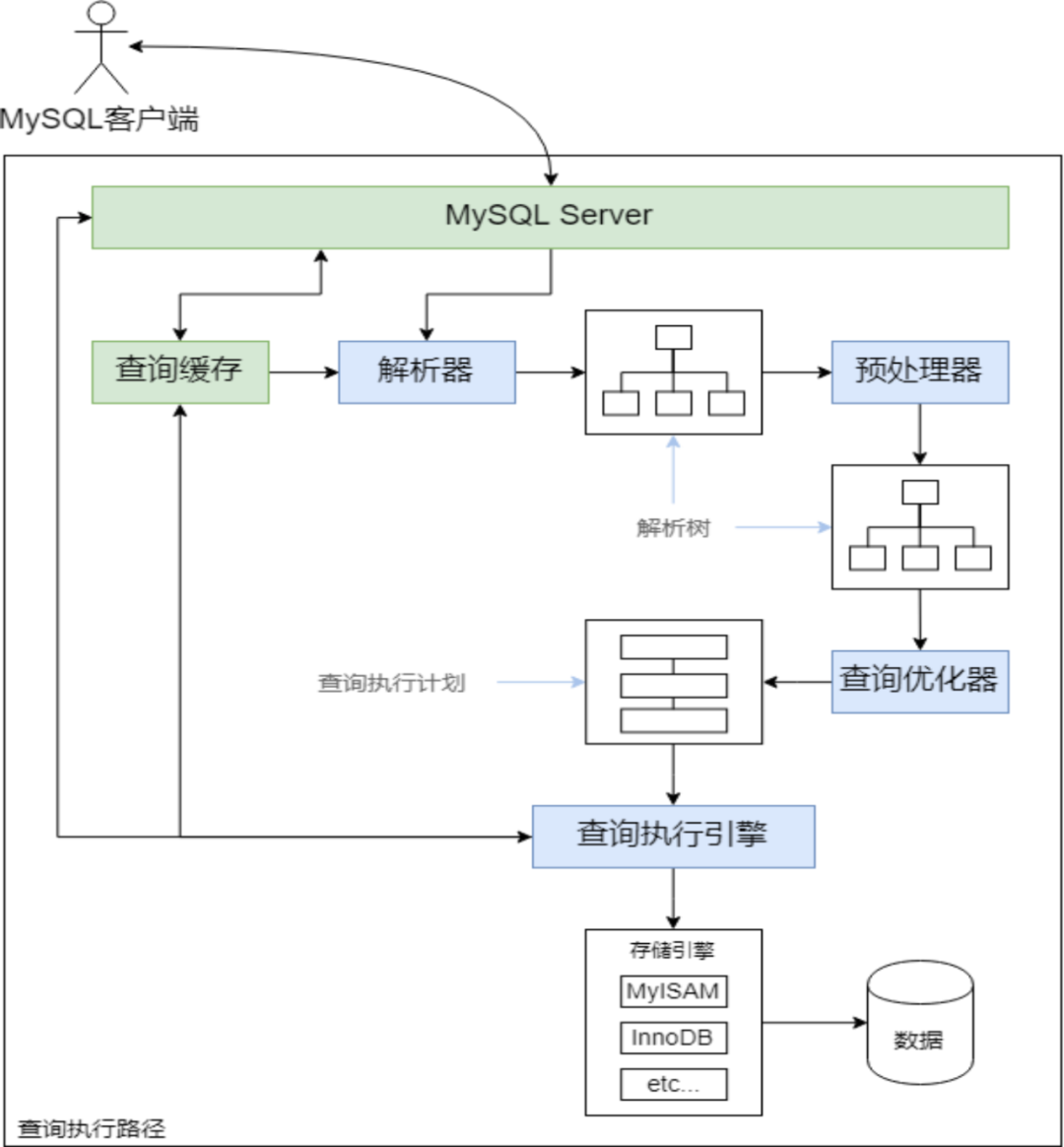
2.2 物理文件映射(PG)
通过内存块和物理文件按照block大小做映射,数据访问如果没有在内存中,则在磁盘中读取到内存中,再返回给上层。
- 优点:粒度很细,不同query可以复用。在OLTP系统下,数据量不多,并且大多数是点查点写的SQL,TP数据遵循LRU的假设,所以cache的命中率很高。
- 缺点:对于磁盘文件远大于内存、并且数据访问很大的OLAP场景,cache命中率很低。
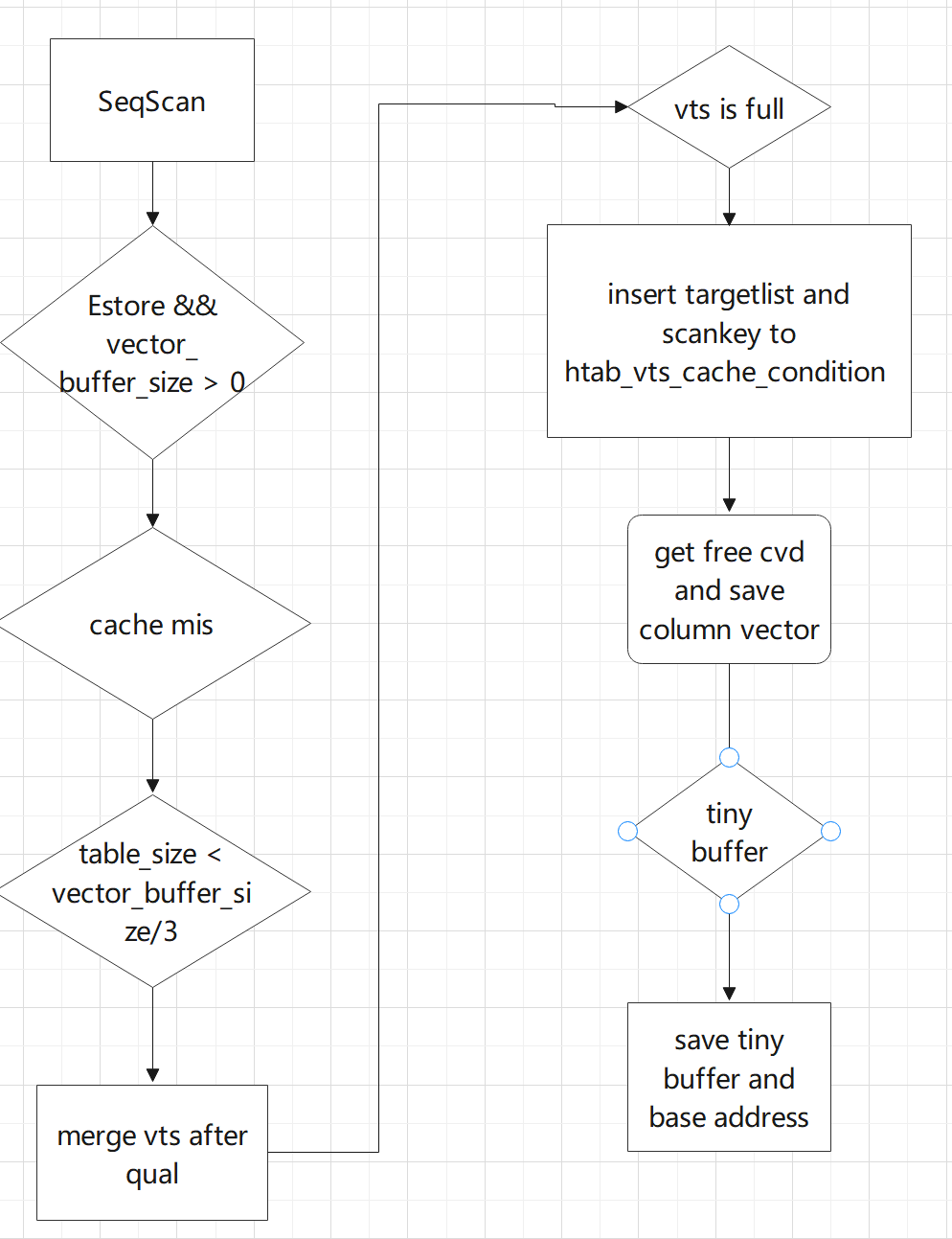
3. VTS-Cache生成
本章将介绍VTS-Cache生成原理和细节。如下图所示
- 只对EstoreseqScan生效。
- 是否是Estore并且vector_buffer_size大于0。
- 是否缓存没命中。
- 是否表的大小小于vector_buffer_size/3,分区表看整个表的大小。
- 做完Qualification之后,将数据merge进新开辟暂存区。
- 暂存区如果满了,则去freelist找到CVDItem,将暂存区存储下来,清空暂存区。
- 如果有tiny buffer,需要存下tinybuffer_freelist找到可用的tiny buffer,做内存拷贝,并且记录下每个tiny buffer原始的内存地址baseaddress。
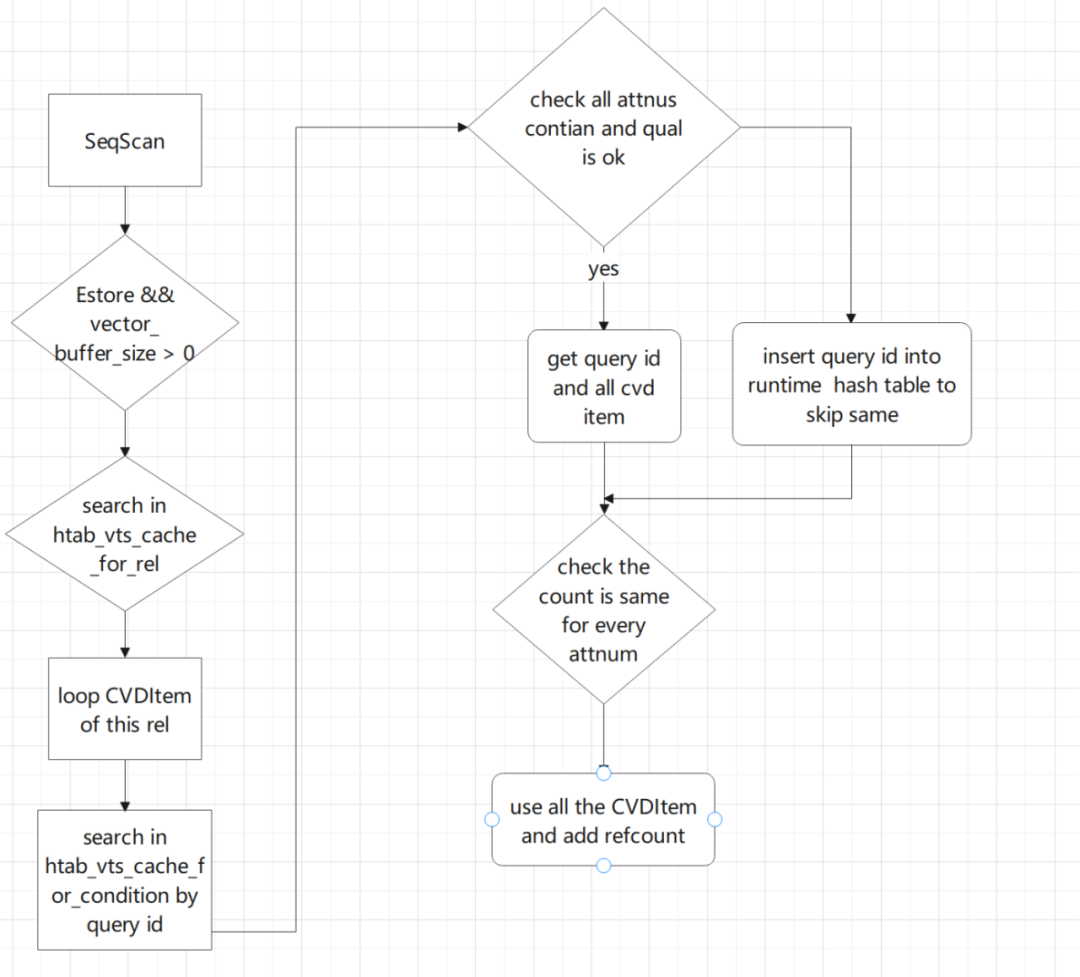
3.1 VTS-Cache使用
本章将介绍VTS-Cache使用原理和细节。如下图所示
- 判断是否满足使用VTS-Cache。
- 在htab_vts_cache_for_rel寻找是否有对应relation的缓存。
- 如果htab_vts_cache_for_rel有对应的cache,则遍历这个列表。
- 遍历每一个CVDItem里面的query_id,在htab_vts_cache_for_condition里面寻找,判断scankey是否满足并且query里面的attnums是否是cache里面的子集。
- 如果不满足,则将本次query_id插入临时hashtab,如果下次再遇到,则跳过。
- 找到满足条件的query_id,然后找到这个query_id所对应的全部CVDItem。
- 判断每个attnum对应的CVDItem数量是否一致,如果不一致,则说明发生过内存淘汰,需要重新选取满足的query_id。
- 将满足要求的CVDItem的refcount+1,使用完之后或者事务abort的时候 将refcount-1.
- 在拷贝tinybuffer的时候,需要同步将cv_vals里面的项跟baseaddress做相应偏移
3.2 VTS-Cache 的使用举例
图解如下:

3.2.1 原始数据
create table student(id int,varchar name,int age) with (orientation = column);select id, age from student where age > 15;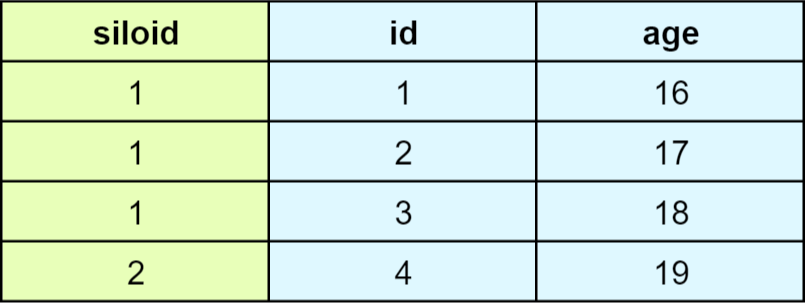
3.2.2 命中缓存场景1,列包含
select age from student where age > 15;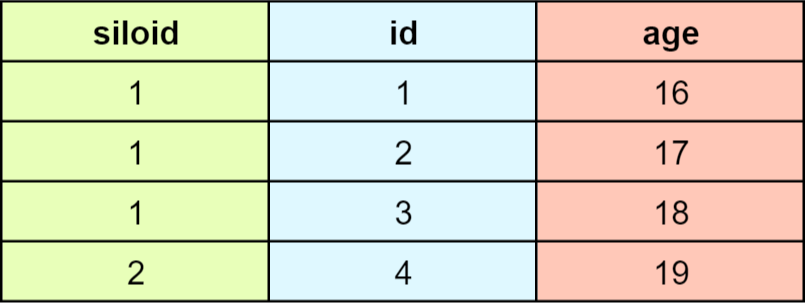
3.2.3 命中缓存场景2,qualification包含
select age from student where age > 16;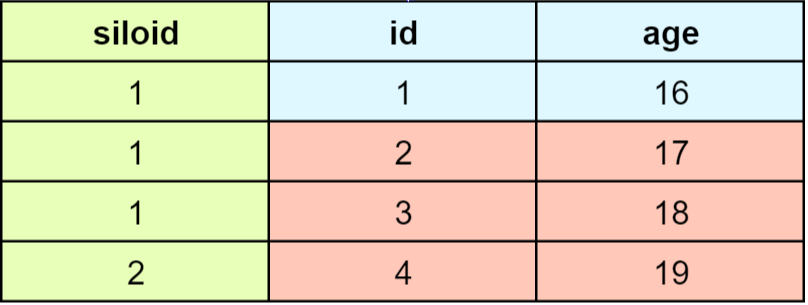
3.3 VS-Cache 的DML
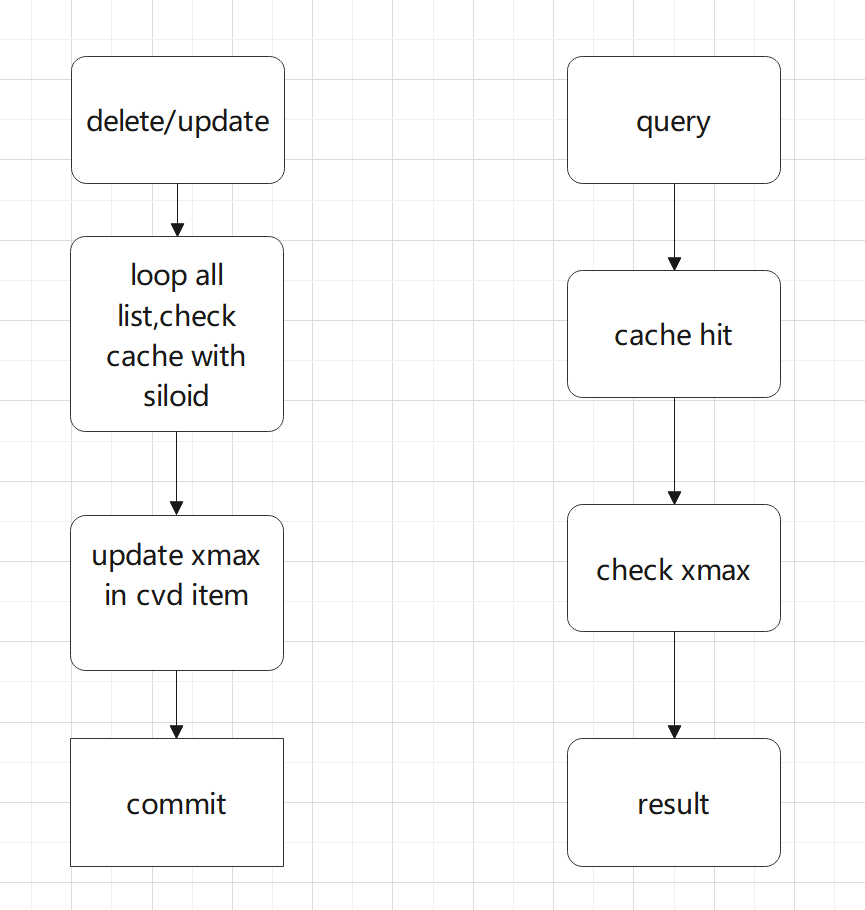
- 发生update或者delete。
- 将发生变更的relation的oid和siloid记录到链表invalid_list。
- 等待表结构自身变更完成。
- 遍历invalid_list,对比VTS-Cache里面的内容,如果有匹配的,则将CVDItem的xmax置位为当前的xid。
- 将事务提交。
- 查询时候需要对比CVDItem里面的xmax和当前的事务id,和普通的MVVC事务处理机制相同。
3.4 VTS-Cache 的内存回收逻辑
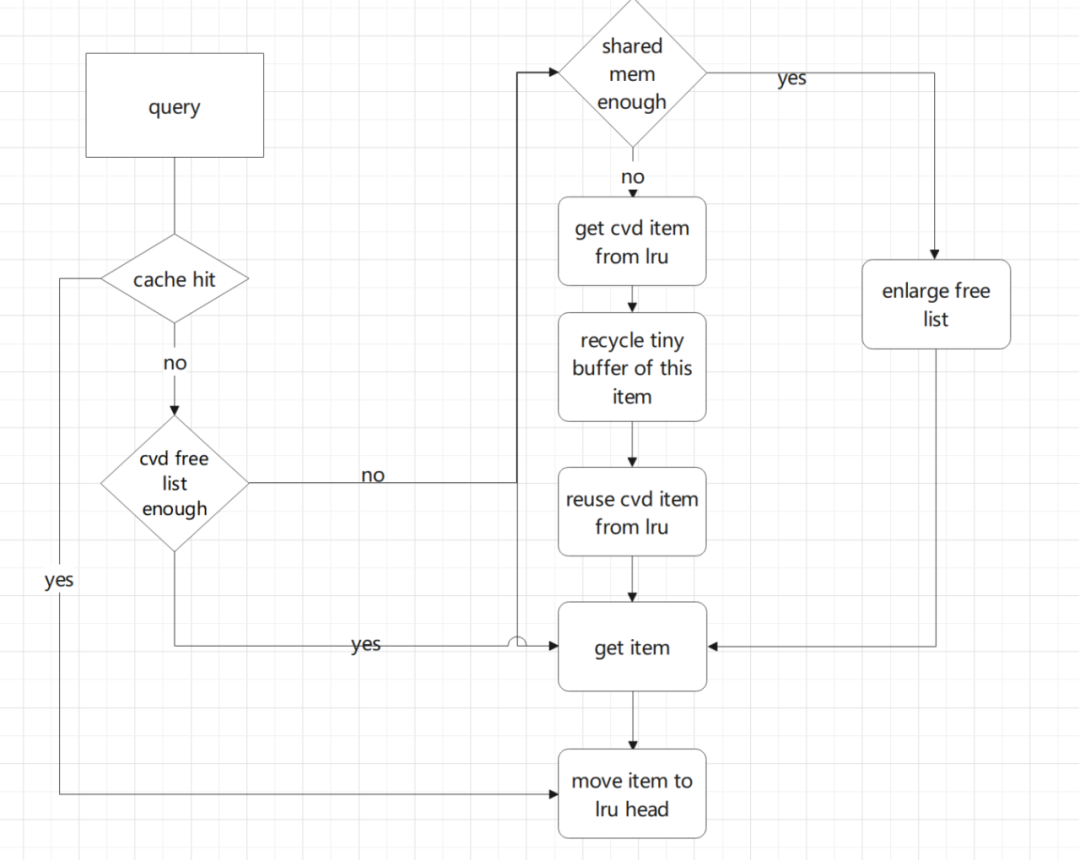
VTS-Cache的内存回收按照朴素的LRU算法进行回收,需要注意的是,缓存块需要按需被pin住,直到使用结束,并且考虑各种异常场景需要释放引用计数,否则会有缓存泄露。
此外,VTS-Cache和普通的缓存不同,它是由一条query产生多个有关联的cache,所以回收内存也需要按照query级别来回收关联所有cache块。
3.5 VTS-Cache在HTAP系统中的运用
对于一个典型的HTAP应用,我们会将普通heap表里面按行存储的数据存储到按列聚簇的内存数据结构VectorTableSlot中,然后按照向量化的方式做运算,加速运算过程,也就是所谓的“行转列”。
对于运算层来说,拿到的是VectorTableSlot这个数据结构,如果我们对于行存的查询也构建一套VTS-Cache,就能为OLTP和OLAP提供统一的运算层缓存,进而加速HTAP场景运算。
4. 总结
VTS-Cache是一个OLAP场景下向量化执行缓存,考虑OLAP场景下处理的数据量比较大,直接用传统的内存-文件映射的缓存难以解决缓存的低效命中。所以考虑使用执行层的缓存,能够过滤大多数的数据,并且比类似MySQL的语句缓存更加灵活,能够方便支持Heap表,为OLAP和OLTP提供统一的HTAP执行层缓存。
推荐阅读



关注腾讯云大数据公众号
邀您探索数据的无限可能

点击“阅读原文”,了解相关产品最新动态
↓↓↓