编者按
云计算已经发展了20年,是到了变革的时候了。
但变革成什么样子,目前还在混沌中。
未来将形成的新的业态,我们姑且称之为“算力网络”吧!
趁着AI大模型的东风,智算基础设施建设如火如荼。以智算(智算”力”,是算力的一个子集)为重心,更综合更全面的算力网络和算力中心建设,24-26这几年会是一个高潮。
目前,行业发展过程中还存在不少问题。最核心的一个问题是,目前许多算力中心的业务模本本质上是“租赁”,而不是类似云计算的产品和服务。
虽说行业发展循环往复,但循环往复并不意味着倒退,而应是螺旋式上升。
那么算力网络的发展,一定是在基于云计算的整个分层服务体系的基础上的持续升级和演进。
1 云服务的价值在哪里?
云计算服务有一些非常关键、强大的能力,是裸机无法提供的。比如:
- 资源弹性。资源弹性是云计算最核心的能力。例如,用户可以根据自己业务的动态需求,非常方便的增加或降低主机资源需求。云主机支持非常强大的Scale up/down(增加或减少处理器核心、内存、存储和网络等能力)和Scale Out/In(增加或减少主机的数量)能力。
- 高可用性。云计算最初的诉求,就是基于成本低廉、可靠性较差的通用服务器,构建完全高可用的产品和服务。包括云主机在内的很多云服务,对外提供的都是完全高可用的服务。
- 多租户摊薄成本。通过虚拟化实现硬件资源共享,通过VPC实现不同租户、不同系统的网络域隔离,让不同用户不同系统共存于同一个物理数据中心。既保证了成本的均摊,又保证了业务的安全隔离,还保证了业务性能的稳定(不同业务所需资源隔离,相互不干扰)。
- 存储的性能和安全。通过分布式存储,实现高性能存储,以及存储的持久化,再通过各类数据冗余机制,保证了存储数据的安全。
- 以应用为中心。此外,随着容器虚拟化的广泛流行,云服务逐渐从以资源为中心过渡到以应用为中心。这进一步实现了业务软件和硬件资源的解耦,完全没有了硬件约束,业务客户可以更加专注于业务应用的创新。
2 云计算分层服务体系
2.1 传统的云计算分层服务体系
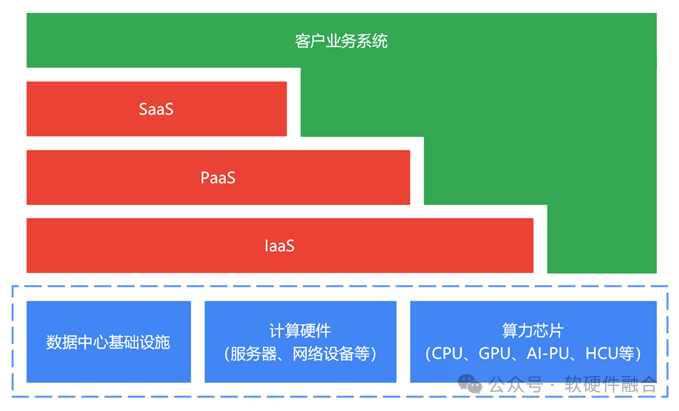
云计算是由各类硬件基础设施和基于硬件基础设施构建的软件产品和服务组成的分层服务体系,具体如下表所示。

2.2 以AWS为代表的全产业链模式

亚马逊AWS是全球最大的云计算公司,不仅对外提供各类IaaS、PaaS、SaaS服务,还持续向底层扩展。AWS大部分数据中心是自主建设,并且还自主定制服务器和交换机等计算设备。
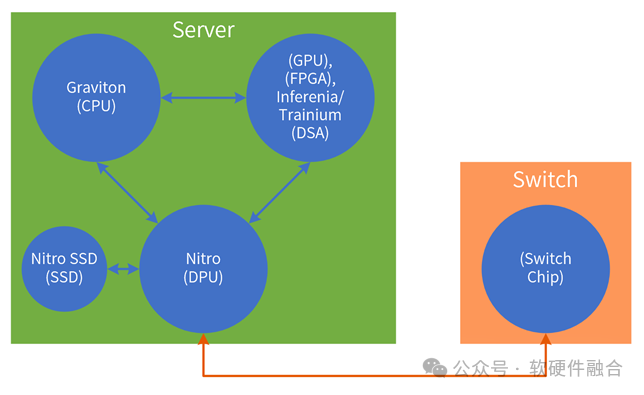
此外,AWS还自研用于数据中心的各类芯片,包括:
- CPU芯片 Graviton系列;
- AI加速芯片Trainium和Inferenia;
- DPU芯片Nitro系统;
- Nitro SSD控制器芯片。
亚马逊基于自研芯片,把底层软硬件深度结合,给用户提供更加具有竞争力的云服务。
2.3 算力网络,产业链分工的新模式
当行业处于变革期,行业中各大公司的业务模式倾向于向产业链上下游拓展;反过来,当行业逐渐趋向于成熟,则更倾向于专业分工。在分工模式下,产业链条的每个阶段都可能成就一批公司,通过专业分工实现更高效率更低成本,从而推动产业链再一次“创新”。云计算产业链也不例外:经过20年的发展,云计算到了行业变革的时候了。
接下来,是我们对云计算分层服务体系,或者也可以说是云计算产业链,变革的分析(一家之言,供探讨):
- IDC公司。仍然专注于数据中心或算力中心的基础设施建设,通过优化土地、能耗、散热、电力、网络等方面的成本,给上层的客户提供更优质的基础设施。同时,通过规模化的方式进一步优化成本。
- 新型算力芯片公司。2009年,NVIDIA黄仁勋说NVIDIA是一家软件公司,此时,NVIDIA已经把更多的资源投入到CUDA的研发,如今,NVIDIA是全球市值最高的芯片公司,并且超过Intel、AMD以及高通等知名公司的市值之和。未来,芯片公司需要进一步进化,从软件公司进化成云计算公司,芯片公司要更加懂云,更加懂宏观计算(数以万计计算节点的超大规模计算,以及跨云边端的融合计算)。
- 计算和网络设备厂家。一方面,是AI大模型等业务的强需求;另一方面,随着AI芯片、DPU以及异构融合处理器HCU等新形态、新架构的处理器出现;还有一方面,就是随着算力网络、超大规模大模型训练等业务的发展,对高性能网络、可编程网络、确定性网络等方面的要求越来越高;未来一定时期,会是底层软硬件协同创新爆发的时间。计算和网络设备厂家,需要紧跟客户和供应商,共同推动创新形态的服务器和网络设备的发展和落地。
- 算力中心。算力中心可能会涵盖IDC的业务,但算力中心的核心竞争力不在数据中心基础设施方面(如果核心竞争力在基础设施,那本质上仍是IDC公司)。算力中心的核心竞争力在于通过软硬件整合的能力,给用户提供更低成本的算力。因此,算力中心会涉及到计算硬件和软件的协同优化,以及部分IaaS服务。
- 算力运营公司或新型云计算公司。轻量化运营,会涉及另一部分IaaS服务,以及PaaS和SaaS服务。并且聚焦在更上层的服务和各种场景的解决方案,帮助客户业务落地。随着客户业务越来越复杂,不仅仅涉及传统云的业务,还包括边缘和终端的一些服务支持。需要给客户提供云边端一揽子业务场景的整体解决方案。
2.4 算力网络三方分析
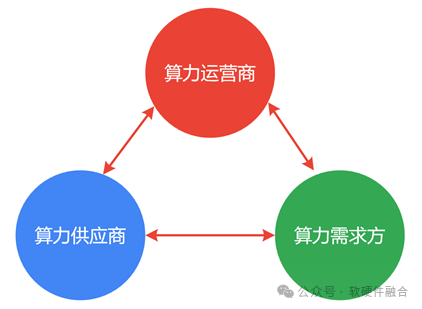
如同电商的平台、卖家和买家三方一样,算力网络相关方也可以分为三个:
- 算力供应方,算力中心。考虑的是如何从内在的软硬件方面做成本优化,同条件下把算力的成本降到最低。其次,需要考虑市场和销售,需要积极对接各大算力网络运营公司,以及直接对接大客户。
- 算力需求方,业务客户。首先,考虑的是能够拿到优质且低成本的算力资源,其次要考虑有服务商能够帮助自己做好各项业务的支撑,特别是云边端打通、软硬件结合,以及AI大算力场景的落地等。
- 算力运营商,算力平台。最大限度的利用算力资源,实现算力价值的最大化。以及对行业和业务更深层次的理解,帮助业务客户场景落地。
3 以云为中心的边缘计算
作者个人,在2015年IoT创业的时候,就设计了一套边缘计算(那个时候还没有边缘计算的概念)系统,在这系统里,有云、边缘和终端,各自有明确的分工和功能划分。但这个时候的分工是静态的,随着业务的发展,后期势必需要升级调整,这样就需要对云、边缘和终端的功能同时进行调整,非常复杂,成本很高,而且滞后。

如果通过云边端融合,把三者的运行和开发环境统一,再通过微服务的方式构建整个系统,那么就可以动态的构建云边端一体化系统。终端如果需要启动更高优先级的服务(比如自动驾驶服务),那么一些低优先级的服务(如游戏、音乐等)就可以动态的调度到边缘甚至云端。
静态的云边端,是协同,分彼此,你做什么,我做什么,大家分工明确,形成协同效应。动态的云边端,是融合,不分彼此,你可能做任何事情,我也可能做任何事情,大家是一个整体,在运行的过程中动态调整云边端每个节点具体做的事情。
此外,还需要注意的是,云边端需要以云为中心。像CDN一样,所有的服务端在云端,边缘端是云端的代理,代理云端为终端提供服务。所有的服务端最开始都在云端,然后根据需要,动态的服务端的副本会通过调度,运行在云端、边缘端甚至终端。
4 AI智算 or 综合计算?
如果把AI比做“主菜”,那么综合计算则是一桌“宴席”。
云计算、边缘计算和终端计算是计算的位置。而AI计算是计算的业务类型。
AI很重要,但围绕着AI,还有很多其他类型的计算。虽然,以AI为主要计算的AI+业务场景越来越多,但仍然有很多计算任务,不需要AI的参与,或者AI计算量占比较低。
因此,我们给出综合计算的概念:通过云计算、边缘计算、终端计算的方式,为所有的计算任务提供承载;这里的计算,既包括AI的计算,也包括其他任务的计算。这些计算任务并行不悖的混合运行在云、边或端。
5 租赁模式 or 产品和服务模式?
今年(2024年),随着AI大模型的火热,国内智算中心的建设如火如荼。深入的了解了行业情况后发现,目前的智算中心,大部分采用的是非常传统的业务模式:租赁。这是一种非常低层次的业务模式。
在目前,GPU算力非常紧俏的情况下,谁掌握了硬件资源,谁就有客户、有市场。这种情况下,租赁模式有一定可行性,但并不长久。
租赁模式无法解决如下一些典型问题(问题还有很多,无法一一列举):
- 问题一,拿到GPU服务器只是第一步,需要针对训练/推理场景,把GPU服务器整合成更适合训练/推理的AI计算集群。如果是训练,需要有高性能网络,能够让GPU发挥最大的性能效率;如果是推理,则需要考虑成本优化。因为一方面,推理是成本的大头,另一方面推理面向最终用户,而用户对成本敏感。推理需要通过虚拟化、容器和Serverless,以及其他各种方法来进行成本优化。
- 问题二,综合计算。上一个章节,我们探讨了综合计算的话题。如果以为客户提供完整服务为目标,那么智算就不仅仅只是智算,还需要通用计算的其他能力,如存储、网络、安全、数据库、大数据分析等等其他类型的产品或服务。
- 问题三,训练和推理服务。可行的情况下,需要给客户提供一站式AI大模型训练服务,并且具有丰富的数据集接入资源,使得用户的模型训练更加便利。此外,还要跟场景结合,为不同的场景提供预训练好的基础模型,客户仅需要针对场景预训练模型进行微调即可。推理,则需要更进一步封装,底层需要考虑如何通过非NV平台进一步给客户降成本,但客户无需关心底层硬件。
智算中心,需要尽可能的帮助最终服务的大模型客户解决底层的技术、模型、数据等方面的通用问题,让客户可以不关注底层,从而把更多的精力聚焦在自身大模型算法和业务创新。
总而言之,智算中心,不能仅提供服务器硬件,更应深入行业底层,长期深耕,为客户提供更加完善的产品和服务。