深度强化学习实验室
官网:http://www.neurondance.com/
论坛:http://deeprl.neurondance.com/
人们普遍认为,将传统强化学习与深度神经网络相结合的深度强化学习研究的巨大增长始于开创性的DQN算法的发表。这篇论文展示了这种组合的潜力,表明它可以产生可以非常有效地玩许多 Atari 2600 游戏的智能体。从那时起,已经有几种 方法建立在原始 DQN 的基础上并对其进行了改进。流行的Rainbow 算法结合了这些最新进展,在ALE 基准测试中实现了最先进的性能. 然而,这一进步带来了非常高的计算成本,不幸的副作用是扩大了拥有充足计算资源的人和没有计算资源的人之间的差距。
在“重温Rainbow:促进更具洞察力和包容性的深度强化学习研究”中,作者在一组中小型任务上重新审视了该算法。首先讨论与 Rainbow 算法相关的计算成本。作者探索了如何通过较小规模的实验得出关于结合各种算法组件的好处的相同结论,并将该想法进一步推广到在较小的计算预算上进行的研究如何提供有价值的科学见解。
Rainbow 的成本 计算成本高的一个主要原因是学术出版的标准通常需要在大型基准测试上评估新算法,例如ALE,其中包含 57 个 Atari 2600 游戏,强化学习智能体可能会学习玩这些游戏。对于典型的游戏,使用Tesla P100 GPU训练模型大约需要五天时间. 此外,如果想要建立有意义的置信界限,通常至少执行五次独立运行。因此,在全套 57 款游戏上训练 Rainbow 需要大约 34,200 个 GPU 小时(或 1425 天)才能提供令人信服的经验性能统计数据。换句话说,这样的实验只有在能够在多个 GPU 上并行训练时才可行,这对于较小的研究小组来说是望而却步的。
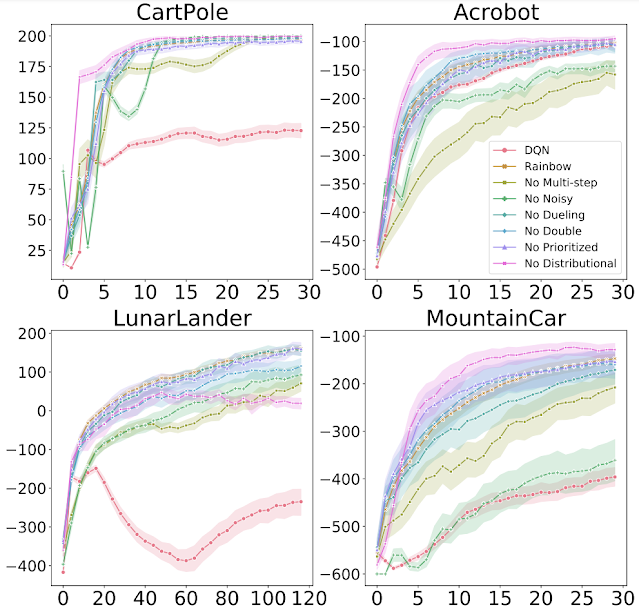
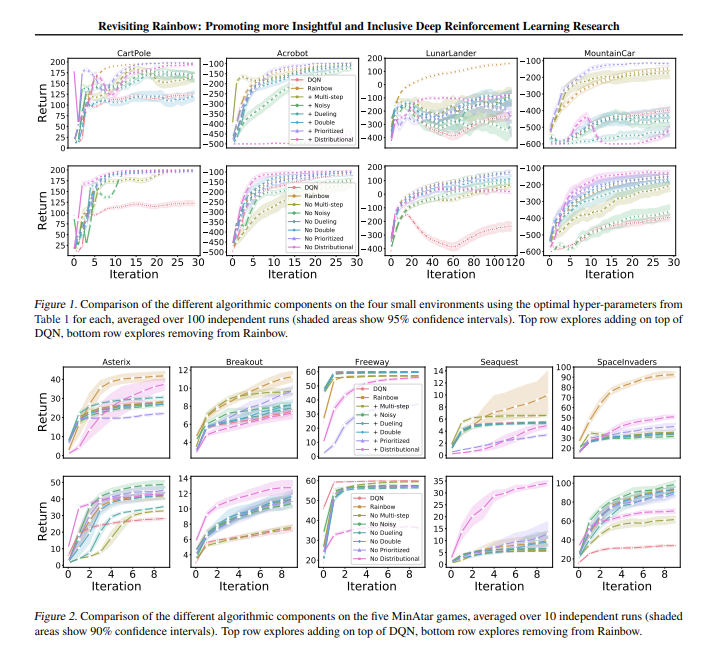
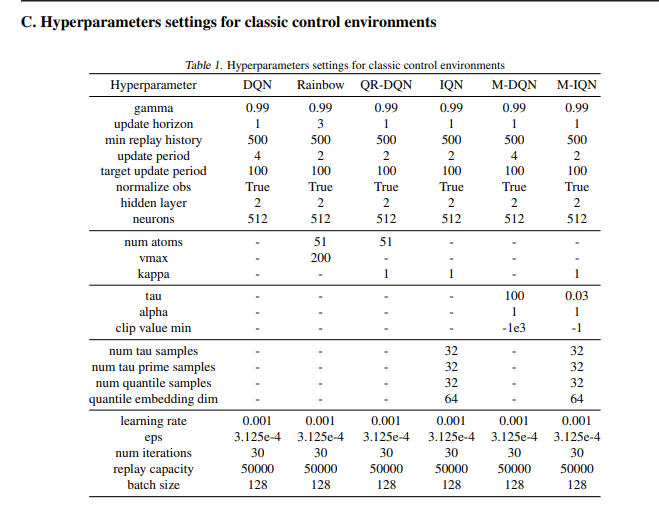
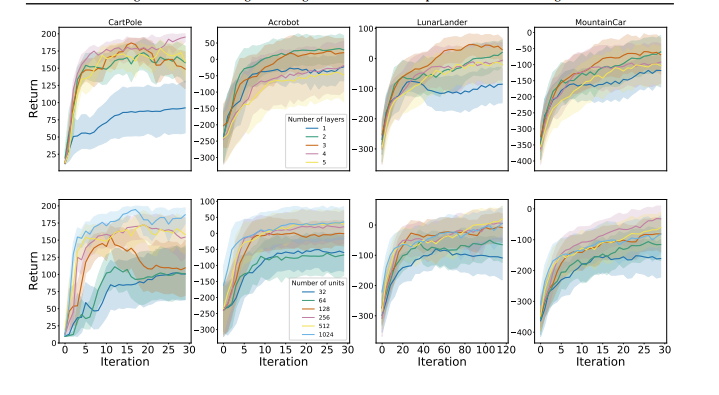
重温 Rainbow 与最初的 Rainbow 论文一样,作者评估了向原始 DQN 算法添加以下组件的效果:双 Q 学习、优先体验重放、决斗网络、多步学习、分布式 RL和噪声网络。并对一组四个经典控制环境进行评估,这些环境可以在 10-20 分钟内完成完全训练(而 ALE 游戏则需要 5 天):
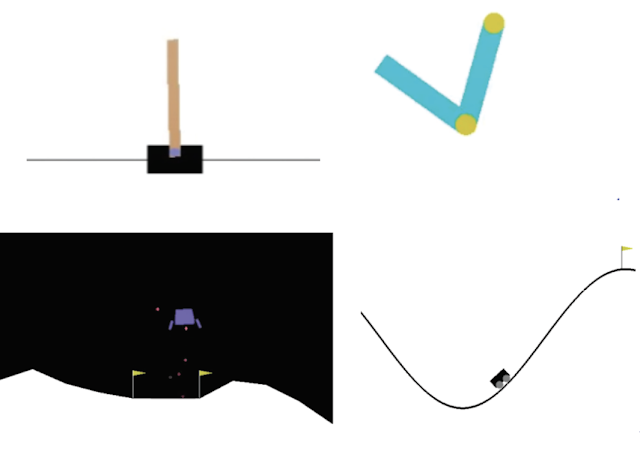
左上:在CartPole 中,任务是平衡推车上的一根杆子,使代理可以左右移动。右上:在Acrobot 中,有两条手臂和两个关节,代理向两条手臂之间的关节施加力以将下臂抬高到阈值以上。左下:在LunarLander 中,代理旨在将飞船降落在两面旗帜之间。右下:在MountainCar 中,agent 必须在两座山丘之间建立动量才能开车到最右边的山顶。 |
|---|
研究了将每个组件独立添加到 DQN 以及从完整 Rainbow 算法中删除每个组件的效果。正如在最初的 Rainbow 论文中一样,作者发现,总的来说,这些算法中的每一个的添加确实改进了对基础 DQN 的学习。然而也发现了一些重要的差异,例如分布式强化学习——通常被认为是一个积极的加法——本身并不总是产生改进。实际上,与 Rainbow 论文中的 ALE 结果相反,在经典控制环境中,分布式 RL 仅在与另一个组件结合时才会产生改进。

每个图都显示了将各种组件添加到 DQN 时的训练进度。x 轴是训练步骤,y 轴是性能(越高越好)。 |
|---|
作者还在MinAtar 环境中重新运行了 Rainbow 实验,该环境由一组五个小型化的 Atari 游戏组成,并发现了定性相似的结果。MinAtar 游戏的训练速度大约比评估原始 Rainbow 算法的常规 Atari 2600 游戏快 10 倍,但仍具有一些有趣的方面,例如游戏动态和基于像素的代理输入。因此,它们提供了一个具有挑战性的中级环境,介于经典控制和完整的 Atari 2600 游戏之间。
综合来看,发现的结果与原始 Rainbow 论文的结果一致——每个算法组件产生的影响可能因环境而异。如果建议使用一个单一的智能体来平衡不同算法组件的权衡,作者的 Rainbow 版本可能与原始版本一致,因为将所有组件组合在一起会产生更好的整体代理。然而,在不同算法组件的变化中有重要的细节值得更彻底的调查。
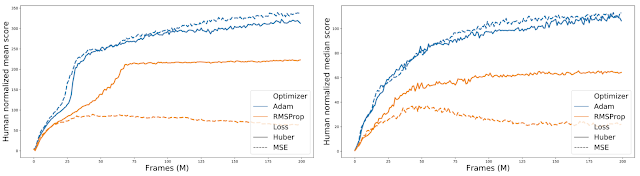
超越Rainbow 当 DQN 被引入时,它利用了Huber 损失和RMSProp 优化器。研究人员在构建 DQN 时使用这些相同的选择是很常见的做法,因为他们的大部分精力都花在了其他算法设计决策上。本着重新评估这些假设的精神,重新审视了DQN在低成本、小规模经典控制和 MinAtar 环境中使用的损失函数和优化器。作者使用Adam 优化器进行了一些初步实验,它是最近最流行的优化器选择,结合更简单的损失函数,均方误差损失(MSE)。由于在开发新算法时经常忽略优化器和损失函数的选择,作者观察到所有经典控制和 MinAtar 环境的显着改进。
因此,在完整的 ALE 套件(60 个 Atari 2600 游戏)上评估将两个优化器(RMSProp 和 Adam)与两个损失(Huber 和 MSE)相结合的不同方式。发现 Adam+MSE 是比 RMSProp+Huber 更好的组合。
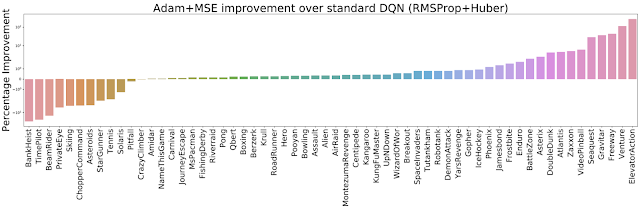
此外,当比较各种优化器-损失组合时,发现使用 RMSProp 时,Huber 损失往往比 MSE 表现更好(由实线和橙色虚线之间的差距说明)。
结论 在有限的计算预算下,作者能够在高层次上重现Rainbow 论文的发现,并发现新的有趣现象。显然,重新审视某事比首先发现它容易得多。然而开展这项工作的目的是论证中小型环境实证研究的相关性和重要性。这些计算密集度较低的环境非常适合对新算法的性能、行为和复杂性进行更关键和更彻底的分析。
作者绝不是呼吁减少对大规模基准的重视。只是敦促研究人员将小规模环境视为他们调查中的宝贵工具,并且审阅者避免忽视专注于小规模环境的实证工作。通过这样做,除了减少实验对环境的影响之外,我们还将更清楚地了解研究前景,并减少来自多样化且通常资源不足的社区的研究人员的障碍,这只会有助于使我们的社区和科学进步更加强大.
论文部分

链接:https://arxiv.org/pdf/2011.14826.pdf
本文链接:
https://ai.googleblog.com/2021/07/reducing-computational-cost-of-deep.html
论文:https://arxiv.org/pdf/2011.14826.pdf