【导读】本篇文章是【最强ResNet改进系列】的第四篇文章,前面我们已经介绍了Res2Net和ResNeSt,具体见:【最强ResNet改进系列】Res2Net:一种新的多尺度网络结构,性能提升显著 和【CV中的注意力机制】史上最强"ResNet"变体--ResNeSt。本文我们将着重讲解IResNet,阿联酋起源人工智能研究院(IIAI)的研究人员,进一步深入研究了残差网络不能更深的原因,提出了改进版的残差网络(Improved Residual Networks for Image and Video Recognition),IResNet可训练网络超过3000层!相同深度但精度更高,与此同时,IResNet还能达到涨点不涨计算量的效果,在多个计算机视觉任务(图像分类,COCO目标检测,视频动作识别)中精度得到了显著提升。
IResNet

- 论文地址:https://arxiv.org/abs/2004.04989
- 代码地址:https://github.com/iduta/iresnet
摘要与创新点
残差网络(ResNet)是一种功能强大的卷积神经网络(CNN)结构,目前已被广泛应用于各种任务中。何恺明大神在2015年的深度残差网络(Deep Residual Network, 简写为 ResNet)可以说是过去几年中计算机视觉和深度学习领域最具开创性的工作。本文,我们提出了一个基于ResNet的改进版本。我们主要针对ResNet的三个主要组成部分进行了改进:通过网络层的信息流、the residual building block 和 the projection shortcut。IResNet能够在准确性和学习收敛性方面上都超过ResNet。例如,在ImageNet数据集上,使用具有50层的ResNet,对于top-1精度,本文方法可以比ResNet提高1.19%,而另一种配置则提高约2%。重要的是,无需增加模型复杂性即可获得这些改进。我们提出的方法允许我们训练极深的网络,而ResNet却有着严重的优化问题。我们报告了6个数据集上3个任务的结果:图像分类(ImageNet、CIFAR-10和CIFAR-100)、目标检测(COCO)和视频动作识别(Kinetics-400和Something-Something-v2)。在深度学习时代,我们为CNN的深度建立了一个新的里程碑。我们成功在ImageNet数据集上训练了404层网络的模型,在CIFAR-10和CIFAR-100数据集上训练了3002层网络的模型,而原始的残差网络在达到上述层数的时候已经无法收敛。
IResNet的主要创新点:
1)引入了一个新的网络结构,增强了信息流动和网络表达能力(Improved flow of information)
2)减少信息损失(Improved projection shortcut)
3)在不增加计算量的前提下,增强了残差模块的学习能力(Grouped building block)
因残差网络几乎已经成为所有深度卷积网络的标配,“涨点又不涨计算量”的iResNet的出现,或可影响深远。下面我们将着重来讲解一下这三大改进点。
主要改进点
1. Improved information flow through the network
残差网络 (ResNet) 是由许多残差块(ResBlocks)叠加而成的。图1(a)给出了一个残差块的例子。从公式上每个残差块可以定义为:
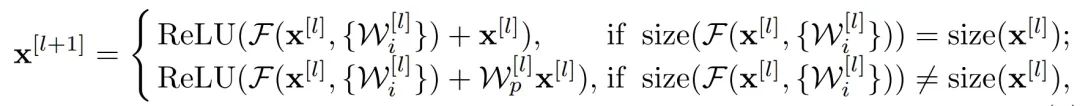
其其中,

和

分别是 第

个残差块的输入和输出向量,

代表激活函数。

是一个可学习的残差映射函数(即残差学习要学习的东西,当学习到0时,那么

=

,从而实现恒等映射),它可以有许多层组成(下标

来表示指定层)。例如,一个bottleneck ResBlock有三层,那么

但从图1(a)和公式可以看出,在主传播路径上存在ReLU激活函数。通过负信号则将归零,这个ReLU可能会对信息的传播产生潜在的负面影响,尤其在训练开始时,会存在很多负权值(虽然一段时间后,网络会开始调整权值,以输出不受影响的正信号来通过ReLU)。关于上述问题在[2]中有研究(见图1(b)),他们提出了一个种新的ResBlock,称为pre-activation,即将最后的BN和ReLU移动到最前面。主传播路径上没有如ReLU非线性激活函数,导致了许多Block之间缺少非线性,又限制了学习能力。其实,就是从一个极端走向了另一个极端,原始的ResNet在主路径上用很多门(例如ReLU)来阻碍信息的传播,而pre-act则让信号直接通过没有加以控制的主路径。此外,原始ResNet和pre-act的主路径上没有BN进行标准化,因此,使得全信号(即+完后的信号,full signal)的一部分没有进行标准化,进而加大了学习的难度。
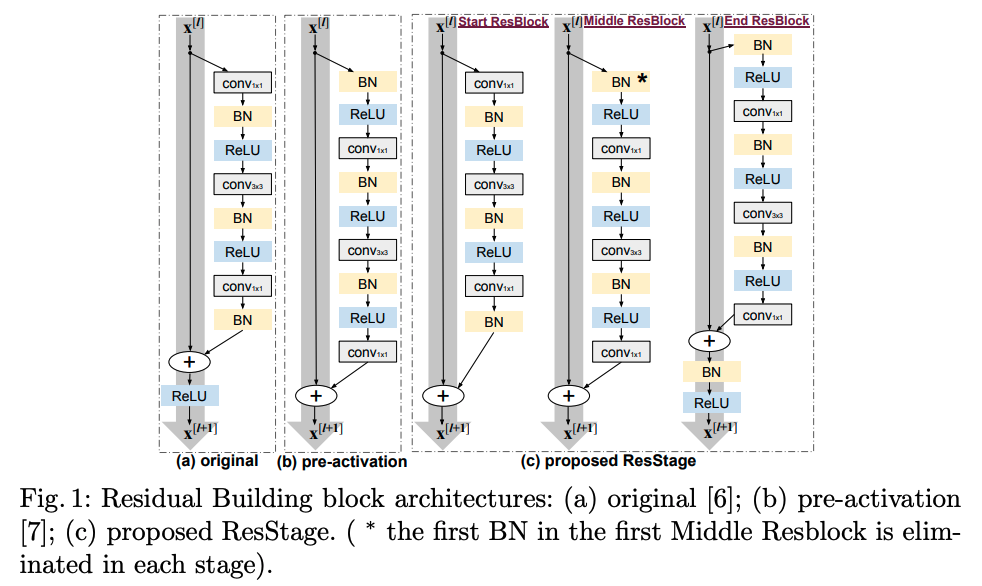
作者认为原始的ResNet网络模块中的ReLU在将负信号置0时影响了信息的传播,这种情形在刚开始训练时尤其严重,因而,本文提出了一种分网络阶段(stage)的三种不同残差构建模块。每个stage都包含有上图中的start ResBlock、Middle ResBlock、End ResBlock三种残差模块,每个stage有一个start ResBlock 、一个End ResBlock 和数个Middle ResBlock。
以50层的残差网络为例,首先把ResNet-50网络结构分为三个阶段,分别是1个starting stage、4个main stages、1个ending stage。4个main stages中的每个main stage都包含若干Blocks: main stage1有3个ResBlock, main stage2有4个,main stage3有6个,main stage4有3个。每个main stage中的ResBlock共有三种,如图1中(c)所示,一个main stage内部组成方式依次为:一个Start ResBlock、若干个Middle ResBlock(可任意数量,如在ResNet-50中main stage1有一个,main stage3有四个)、一个End ResBlock。如下图为改进后的ResNet-50网络结构图。每一个ResBlock有三层卷积(两个

,一个

),共有16个ResBlock,则层数共有

。每个Main Stage中的ResBlock有不同的设计。我们把这种分段组织结构的ResNet叫ResStage network。
2. Improved projection shortcut
projection shortcut 被用于残差网络特征维度改变的时候,用于将不同特征维度的特征相加之前的处理。原始的残差网络使用stride为2的1x1卷积进行通道的改变。如下图中的(a)。
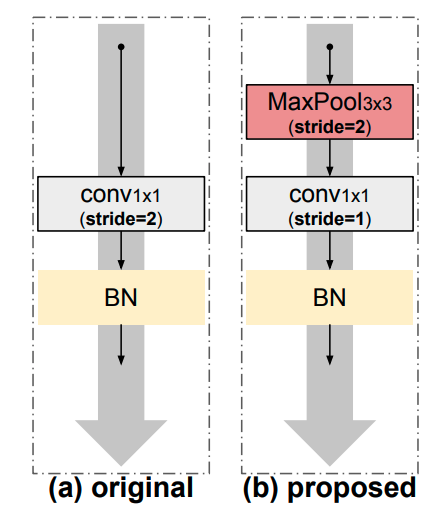
作者认为1x1卷积丢弃了大量信息,如图中(b)所示。对于spacial projection,作者使用stride=2的3×3max pooling层,然后,对于channel projection使用stride=1的1×1 conv,然后再跟BN。
这样做的优点在于:
spacial projection将考虑来自特征映射的所有信息,并在下一步中选择激活度最高的元素,减少了信息的损失,后面的实验结果也证明了这点。这样改进后的projection shortcut,在通道流程上可以看作是“软下采样(conv3*3)”和“硬下采样(3*3max pooling)”两种方式的结合,是两种方式优势的互补。“硬采样”有助于分类(选择激活程度最高的元素),而“软采样”也有助于不丢失所有空间背景(因此,有助于更好的定位,因为元素之间可以进行过渡比较平滑)。同样这个改进并不增加模型复杂度和模型参数量,非常实惠。
作者将ResStage和改进后的projection shortcut用在了ResNet上,并把这个网络成为IResNet。
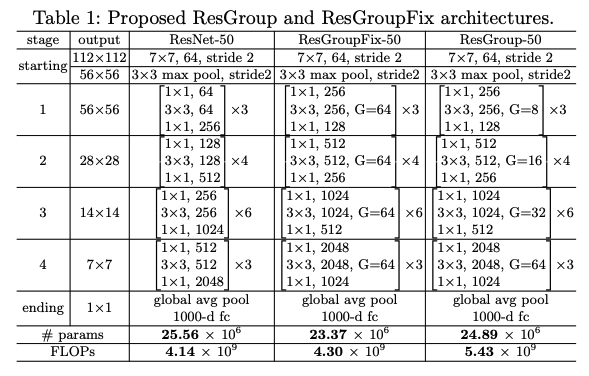
3. Grouped building block
作者认为原始的残差网络中瓶颈模块(bottleneck block)不够好,这种上下粗中间细的结构中,前面的1x1卷积是为了降通道数进而减少计算量,后面的1x1卷积是为了特征对齐,3x3卷积部分被限制了,只有它在“认真的”学习特征模式,将其通道数减少虽然提高了计算速度,却降低了网络表达能力。(算是一种不得已而为之的设计吧)
而新的组卷积(Group conv)技术方案恰好可以解决这个问题。所以作者提出使用组卷积构建模块替换瓶颈模块。
如下图:
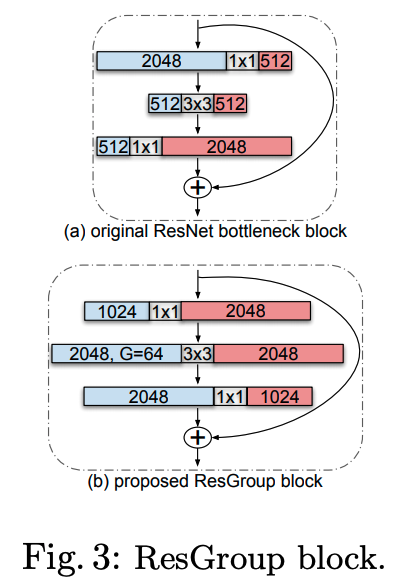
ResGroup在不增加计算量的前提下可更好的让3x3卷积发挥作用。
实验结果
我们在6个数据集上进行了实验,使用IResNet模块,可以训练更深层的网络模型,而且相对原始方案,在相同深度时,iResNet的精度也更高。
下图为在ImageNet上训练50、101、152、200层网络时的结果比较:
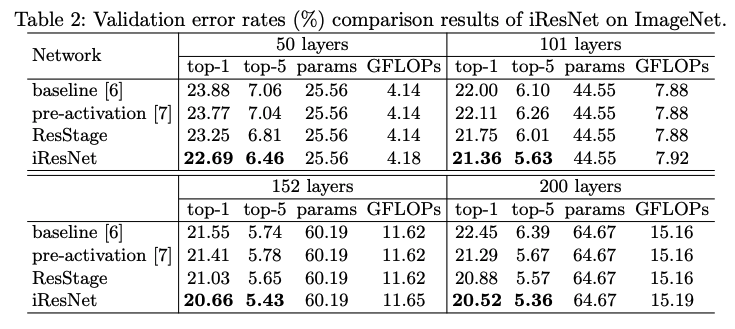
可见原始残差网络在超过152层时精度开始下降,iResNet精度一直在上升,且比其他方案的精度更好。
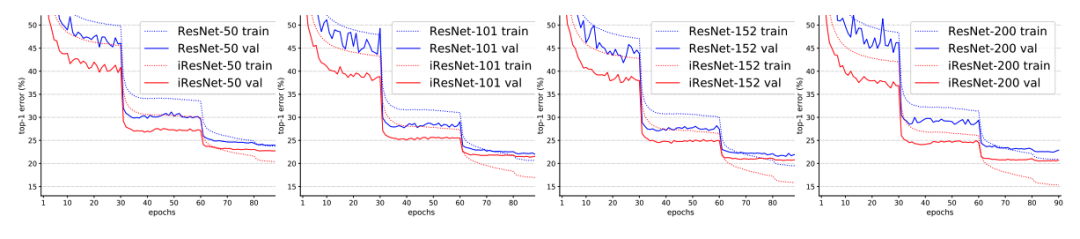
下图为训练时的验证集精度曲线,从趋势上看,iResNet具有持续精度提升的表现。
下图为训练404层iResNet网络和152、200层ResNet网络的比较:

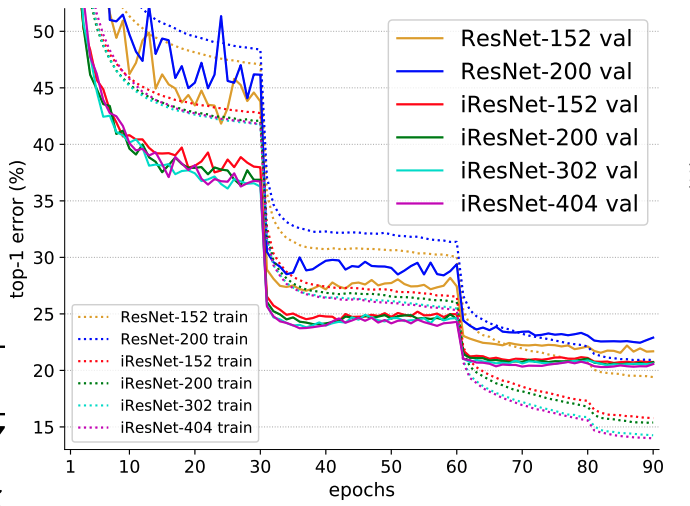
随着层数增多,iResNet网络的精度持续提高。
在视频动作识别人中中使用iResNet也明显改进了结果:

在CIFAR-10和CIFAR-100数据集上,不同深度网络的表现:
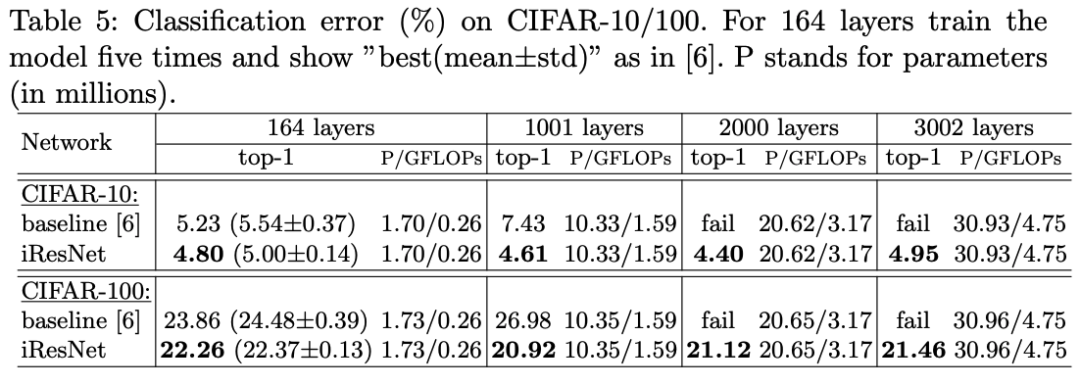
iResNet的精度随着层数增加到2000层时精度还在提升,达到3002层时精度下降,而ResNet无法在2000层收敛。
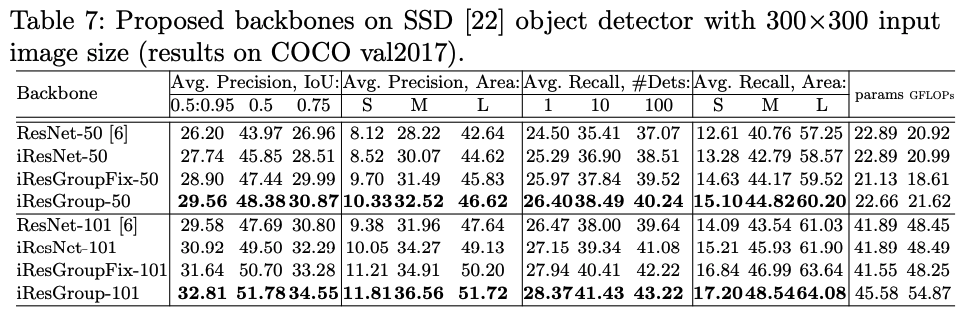
在COCO目标检测数据集利用SSD检测方法,将iResNet作为backbone训练结果显示,同样取得了精度提升。
iResNet与其他知名图像分类算法在ImageNet数据集上的比较:
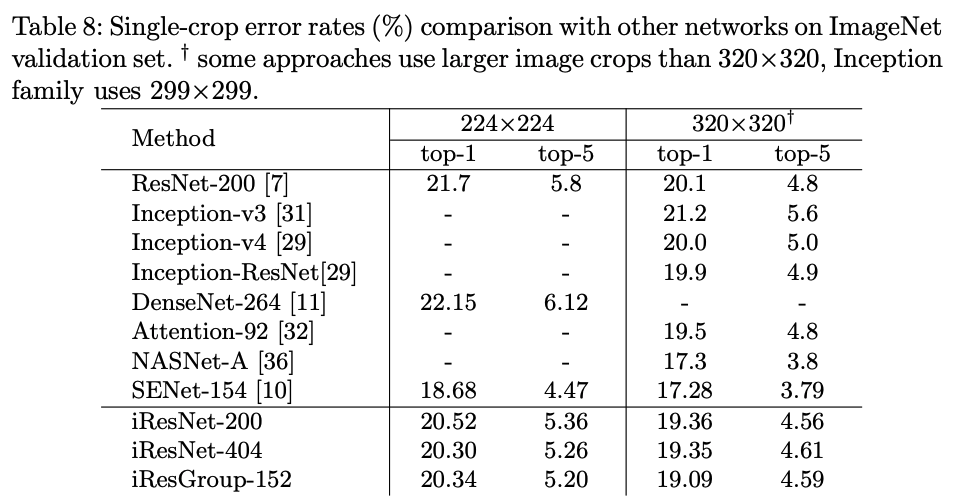
iResNet 比大部分方法好,但使用了其他技巧的顶尖选手NASNet-A和SENet-154的精度更高,而 iResNet 可以用来构建这些网络。
Conclusion
这项工作提出了一个ResNet的改进版本。IResNet主要改进了ResNet的三个主要组成部分:通过网络层的信息流、the residual building block 和 the projection shortcut。IResNet能够在准确性和学习收敛性方面上都超过ResNet,例如,在ImageNet数据集上,使用具有50层的ResNet,对于,在不同配置下的,top-1精度提升范围在1.19%到2.33%之间。这些改进是在不增加模型复杂性的情况下获得的。我们提出的方法允许我们训练极深的网络,当训练超过400层(ImageNet上)和超过3000层(CIFAR-10/100上)的网络时,没有出现难以优化的问题。本文提出的方法可成为训练超深网络的工具,或可启发其他算法的出现,iResNet 可完美替换ResNet,精度提高计算量不增加,所以在实际应用中也不失为一个好的选择。