
作者介绍:chaningwang,2008年毕业于中国科学院研究生院,主攻FPGA高性能计算、FPGA图像处理等方向。
先后在华为、怡化公司从事FPGA开发、智能传感器数据处理等相关工作,工作期间设计开发了多款传感器以及传感器数据处理平台,成功应用于银行ATM机器纸币鉴伪。
2013年加入腾讯TEG\平台开发中心\基础研发组,一直致力于图像处理算法的FPGA加速工作,先后参与了基于硬件FPGA的JPEG编解码、WEBP编码、自适应量化、HEVC编码等项目。目前在基础研发组负责图片HEVC编码项目的落地推广。

作者介绍:andybzhang,2007年毕业于哈尔滨工业大学深圳研究生院 通信与信息系统专业,主要研究H264视频编码中运动估计的VLSI实现。
毕业后在华为海思半导体有限公司从事芯片设计工作,主要负责H264/H265等视频编码器的架构设计以及项目交付;工作期间,前后共参与10枚以上视频编码芯片的交付项目并成功量产。
2016年1月加入腾讯TEG\平台开发中心\基础研发组,从事图像/视频的FPGA开发工作。
(作者排名不分先后)
本文重点介绍1、各种处理器的特点:简要对比各种处理器的特点
2、图片处理算法的特点:介绍图片处理算法的特点3、FPGA加速性能的主要因素:分析FPGA能够加速图片处理的原因4、HEVC算法之FPGA和CPU实现差异:介绍HEVC FPGA实现和CPU实现差异5、图片业务在互联网中的实际应用:介绍当前图片业务中使用的性能对比6、HEVC图片编码算法介绍
一各种处理器的特点
通用处理器(CPU)可提供高度的灵活性和易用性,可以低廉的价格生产,并且适用于多种用途和重复使用。但性能相对缺乏效率。
专用集成电路(ASIC)可提供高性能,但代价是不够灵活且生产难度更大。这些电路专用于某特定的应用程序,并且生产起来价格昂贵且耗时。
从灵活性而言,介于CPU和ASIC两者之间的处理器,使用比较多的异构处理器目前有两个,一个是GPU,一个是FPGA。
FPGA属于一类更通用的可编程逻辑设备(PLD), FPGA既能提供集成电路的性能优势,又具备CPU可重新配置的灵活性。简单来说,FPGA是一种可重新配置的“通用集成电路”。
GPU的灵活性是介于FPGA与CPU之间。GPU的核心数量一般是CPU的成百上千倍,计算能力要比CPU多出几个数量级,也更适合进行并行计算。但是如果计算里面有大量的分支,或者算法的数据前后存在依赖关系,使得算法无法并行运行,则GPU的性能优势会被大大减弱。
相比GPU,FPGA的可操控粒度更小,具备更高的灵活度和算法适应性。FPGA能够简单地通过使用触发器(FF)来实现顺序逻辑,并通过使用查找表(LUT)来实现组合逻辑。当算法需要并行计算能力时,可以将大部分的逻辑资源都用来做计算,达到更高的计算效率; 当算法需要更多的控制流程时,可以将大部分的逻辑资源都用来做控制。(实际的FPGA内部也存在大量的硬核来完成固定的功能)。正是基于FPGA资源的高可控度,可以带来算法实现时的灵活度。
二图片处理算法的特点
目前图片的存储格式有很多种,大多数是经过编码压缩的,例如:JPEG、WEBP、SharpP等,YUV格式图片则是原始的图片数据,针对Y分量而言,每个点都由一个byte的数据大小来表示该点的亮度信息。
YUV图片和其它几种经过编码的图片相比较,实际中使用的非常少,主要原因是其未经压缩,占用比较大的存储空间和带宽,因此一般只存在于图片处理算法的中间过程。
既然大多数图片都是经过编码压缩的,我们来看看图片的编码过程,一般包含:数据预测、频域变换、熵编码等几个主要的过程。
图片的处理算法也可以粗略分为两大类,空域图片处理算法和频域图片处理算法。
基于图片的YUV原始数据的图片处理算法属于空域图片处理算法。基于图片频域变换后的数据完成图片处理的算法属于频域图片处理算法。
但是,无论是频域还是空域图片处理算法,一般都需要将图片首先进行熵解码之后才能处理,等处理完成之后,再经过熵编码,压缩为目标图片格式。
熵编解码算法有多种,但是各种算法的实现都具有“存在数据依赖”的特点,无法实现大规模的并行改造。这个特点影响了GPU在图片处理、编解码算法中性能的发挥。
而FPGA基于更小的控制粒度和多核并行的特性,在熵编解码算法的处理上优于GPU。
三FPGA加速性能的主要因素:并行度FPGA算法一般运行频率在几百MHz的级别,CPU的频率已达到GHz。我们一定会想FPGA的算法为什么比通用CPU的算法可以获得更高性能?(高吞吐量、低延时)
这里我们做一个理想的算法假设来说明这个问题。
假设:算法ALG0,一共需要A、B两步完成。CPU频率1GHz,FPGA频率100MHz。其中A的计算量10000次、B的计算量20000次。CPU需要10000个时钟周期输出A的计算结果。 耗时10us,吞吐量:10万;
FPGA可由1000个计算单元(计算单元既可以由多个逻辑单元构成,也可以由硬核来构成)并行计算,30个时钟周期来输出A的计算结果,延时0.3us:吞吐量333万;
步骤A并行度:1000;FPGA吞吐量 vs CPU吞吐量:33.3倍;FPGA延时vs CPU延时:3%;步骤B:CPU需要20000个时钟周期输出B的计算结果。 耗时20us,吞吐量:5万;FPGA可由2000个计算单元并行计算,30个时钟周期来输出A的计算结果。耗时0.3us:吞吐量333万;步骤B并行度:2000;FPGA吞吐量 vs CPU吞吐量:66.6倍;FPGA延时vs CPU延时:1.5%;步骤A、B联合起来看整个算法:CPU需要30000个时钟周期输出A、B的计算结果。 耗时30us,吞吐量:3.3万;FPGA总共有3000个计算单元在并行完成算法ALG0的计算, A、B步骤流水执行,算法ALG0 30个周期可以输出一个计算结果,吞吐量仍然333万,延时60个时钟周期,0.6us;算法ALG0的并行度:3000;(同一个时钟周期,有3000个计算单元在并行完成计算)FPGA吞吐量 vs CPU吞吐量:100倍;FPGA延时vs CPU延时:2%;如果只考虑单核性能:FPGA是CPU吞吐量的100倍,延时是CPU的2%;
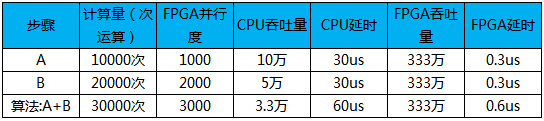
从上面的结果来看,一个算法在FPGA中的实现,优化性能的过程本质就是在提升并行度的过程。
如何提升算法的并行度?
我们的项目中,常用的方法有:流水线设计 + 多核并行;还是以上面的算法ALG0来分析流水线设计给并行度带来的提升。
上面的例子中提到 假设 步骤A可由1000个逻辑单元并行完成计算,数据存在前后依赖,那么1000个计算单元如何获得更高的并行度?
下面给出一种流水线的假设:步骤A可分为10级流水,每级流水100个计算单元可以并行在一个时钟周期内完成100次计算,每级流水需要耗时3个时钟周期(锁存输入数据+并行计算+输出锁存),因此,步骤A的延时一共是30个时钟周期。理想情况下,流水线被压满(step_n的输出作为step_n+1的输入),1000个计算单元分为10组,都在并行工作,并行度达到最高。

从上面可以看出,在上例中合理的流水线设计是FPGA算法性能提升的关键点。
基于多核的并行度提升:针对GPU来说,GPU内部的核心数量是一定的,功能也是固定的。如果算法的并行度可以很好地map到GPU的多核上进行计算,那么GPU的性能可以充分发挥。但是当算法计算、分支、查表等操作都比较多时,GPU的性能比较难以得到充分发挥。
FPGA具有更小的控制颗粒度,在算法的设计上,具备更高的灵活性。代价是更高的设计复杂度以及较长的开发周期。
当分支和控制比较多时,FPGA的逻辑资源可以被用来做控制,当计算比较多时,逻辑资源可以被用来做计算。
计算简单时,可以使用较少FPGA逻辑资源搭建出简单的计算单元。因为FPGA的逻辑资源数量是一定的,每个计算单元消耗的逻辑资源少时,则可以搭建出更多的计算单元,多个计算单元可以作为多核并行工作。
计算复杂时,可以使用较多FPGA逻辑资源搭建出复杂的计算单元。此时,可搭建出较少数量的计算单元。
因为FPGA具有更小的控制粒度,FPGA可以搭建出计算、控制并存的处理单元。这样FPGA可以更灵活地匹配算法,因此,比GPU有更大的应用场景。
当然,缺点:较高的编程复杂度以及较长的开发周期是目前还是短板。
基于以上这些原因,不难理解为什么在FPGA中实现图像编解码算法时,往往使用图片的原始数据作预测,而不是使用重构数据做预测,其目的正是优化算法流水线的设计,提升并行度。(图像编解码算法见“图片处理算法介绍”)
当然,实际项目使用中,图片处理算法是CPU和FPGA配合完成诸多图片处理算法的。这样的好处是,既可以发挥CPU的通用性,又可以发挥FPGA的加速性能,做到合理的软硬件布局也非常重要。 对于CPU和FPGA协同工作实现性能加速的文章,可参见OA上《基于异构计算平台的算法性能优化方法分享》一文。
四HEVC图像压缩算法之FPGA和CPU实现差异理论上说,如果不考虑FPGA资源、硬件实现架构和处理性能,CPU图像压缩算法可以完全在FPGA进行“复制”实现,FPGA算法压缩性能可以完全等同CPU。但是现实没那么理想,FPGA算法实现要统一考虑FPGA性能,资源,算法实现复杂度等要素,只有联合设计才能设计出最优秀的方案。FPGA的硬件可以实现并发性,流水线设计正是利用了并发性,大大提高了硬件处理性能,但是流水线设计,对算法的前后依赖关系有一定要求,不同流水线的算法处理要解耦才能保证并发的最大效率。为了发挥FPGA硬件实现的速度优势,算法进行优化是必须要做的,综合考虑各方面,我们在实际应用中,往往FPGA的算法实现要做一些“让步”。另外,某种型号的FPGA一旦被选定,它的运算以及布线资源往往有个理论值,算法的实现同时要考虑FPGA资源的利用情况,如何能在相同的FPGA资源上实现最好的压缩算法成为设计的难点。我们用FPGA进行算法实现的目标-----实现算法性能尽量接近CPU,图片处理吞吐量,以及处理延迟让CPU望其项背。
FPGA和CPU的主要算法差异点如表所示:

五图片业务在互联网中的实际应用目前,我们已经使用FPGA实现了多种图片的编解码算法,还在进一步丰富当中。
下面给出一些实际的性能参数效果对比。

注:纵坐标单位ms

注:纵坐标单位 张/秒
现网中主流的图片还是以JPEG图片为主。JPEG图片比HEVC算法压缩的HEVC格式图片size大50%左右,如果客户终端采用HEVC格式图片,相比JPEG也可以节省50%的带宽,降低成本的同时,提升客户体验。(HEVC的解码和JPEG解码性能接近)
当前相册平台的图片存储量已经接近250P,如果全部采用HEVC格式存储,则可以节省125P的存储,效果还是非常可观的。
六HEVC图片编码算法介绍
HEVC图片编码算法主要包括去除图像空域冗余的帧内预测,以及消除图像能量冗余的变换编码,还有基于信息论的熵编码。
Ø 帧内预测编码是利用周边已编码图像对当前图像块进行预测的一种技术,在空间上,当前块通常和周边图像块有很大的相似性,编码当前图像和预测图像的差值可以降低图片空间域的相关性;
Ø 变换编码不是直接对空域图像信号进行编码,而是首先将空域图像信号通过变换算法映射到频域,产生一批变换系数,然后对这些变换系数进行编码处理。变换编码是一种间接编码方法,其中关键问题是在空域描述时,数据相关性大,数据冗余度大,经过变换在频域描述,数据相关性大大减少,数据冗余量减少,这样再进行量化,编码就能得到较大的压缩比。JPEG/H264/HEVC常用的变换算法有DCT(离散余弦变换)、DST(离散正弦变换) 其中,最常用的是离散余弦变换;
Ø 根据信息论的原理,可以找到最佳数据压缩编码的方法,数据压缩的理论极限是信息熵。熵编码是一种无损压缩算法,H264/HEVC的熵编码算法主要有三部分组成,二值化,概率模型建模,regular/bypass编码引擎,二值化完成语法以及残差元素的二进制表示,概率模型建模通过对已经编码语法元素以及残差的概率统计选择每个bin的概率模型,编码引擎完成每个bin的编码,输出编码之后的bit流
七HEVC图像编码之单点介绍
CU分割CU(Coding Uint),编码单元。
通常,一副编码图像被划分成很多个CTU(coding tree unit),CTU可以最大为64,最小为8x8,CTU内部又按照树形划分成多个CU(编码单元),如图所示,其中a~m是CU,CTU内部是以CU为单位进行的编码。

编码器可以根据视频内容自适应的选择CU划分方式,达到编码效率最优。
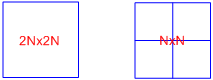
PU分割PU(Prediction Uint),预测单元。PU是在CU的基础上,再向下划分,帧内编码按照4叉树形式划分,
如图:PU大小可以为2Nx2N,NxN
TU分割TU(Transform Uint),变换单元,也是在CU基础,每次以4叉树形式划分。与PU之间没有关系。以LCU取值64为例,TU取值范围32x32、16x16、8x8、4x4。编码器可以根据视频内容自适应的选择划分方式。例如,在平坦区域和内容缓慢变化区域可以使用较大的TU,在纹理细节区域可选择较小的TU,灵活的TU大小可以达到图像质量和压缩率的统一

变换HEVC沿用了H264所采用的整数DCT技术。H264最大只支持4x4、8x8尺寸DCT,HEVC用到了4种不同尺寸的整数DCT,分别为4x4、8x8、16x16和32x32。大的CU使用更大的变换DCT使得变换的效率更高,进一步提高了图像压缩率。
DCT公式为:

X为原始输入信号,C为系数矩阵。
量化量化是指将信号的连续取值映射为有限多个离散幅值的过程,实现信号取值多对一的映射、在图像编码中,残差信号经过离散余弦变换后,变换系数往往具有较大的动态范围。因此对变换系数进行量化可以有效地减少信号取值空间,进而获得更好的压缩效果。协议只规定了反量化过程的实现,而将量化的选择留给了编码器自行决定。
传统的标量量化方法,公式表示如下:
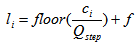
其中,表示DCT系数,表示量化步长,为量化后的值。表示向下取整函数,为控制舍入关系。
HEVC中,规定了52个量化步长,对应于52个量化参数,(qp取值0~51),二者关系如下:
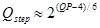
考虑到色度信号若使用较大的量化步长会出现颜色漂移现象,因此色度信号的量化参数限制在0~45。
反量化
反量化的公式:
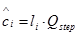
其中,表示量化后的值,为量化步长,表示量化后得到的重构DCT系数。由于量化是个有损过程,因此与不相同。
反变换公式为:

系数矩阵与变换的系数矩阵相同。
熵编码HEVC采用CABAC(基于内容自适应的二进制算数编码)编码。
码过程主要包括了3个基本步骤:
(1)二值化(2)上下文建模
(3)二进制算术编码
如下图所示为单个语法或残差进行CABAC编码时候的示意图,在编码中,如果输入的语法元素是非二进制的语法元素则进行二进制化,否则跳过这一过程。二进制字符串进入编码器后有两种选择:一种是进行快速编码,直接进入Bypass旁路编码器,以固定的概率模型进行编码;还有一种是根据语法元素的类型,通过上下文从概率模型建模器中选择待编码语法元素得概率模型,然后二进制值和选择的上下文模型一起进入编码器,输出编码码流。最后根据编码的输出更新概率模型,为下一次的迭代编码做好准备。
