
导语 | 腾讯云MongoDB当前服务于游戏、电商、社交、教育、新闻资讯、金融、物联网、软件服务等多个行业;MongoDB团队(简称CMongo)致力于对开源MongoDB内核进行深度研究及持续性优化(如百万库表、物理备份、免密、审计等),为用户提供高性能、低成本、高可用性的安全数据库存储服务。后续持续分享MongoDB在腾讯内部及外部的典型应用场景、踩坑案例、性能优化、内核模块化分析。
引言
全民K歌作为腾讯音乐集团四大产品线之一,月活超过1.5亿,并不断推出新的音娱功能及新玩法,极大丰富了数亿用户的音乐娱乐活动。
MongoDB天然支持高可用、分布式、高性能、高压缩、schema free、完善的客户端访问均衡策略等功能。作为腾讯音乐集体核心部门,K歌Feed等业务采用腾讯云MongoDB作为主存储服务,极大的方便了K歌业务的快速迭代开发。
本文主要分享K歌技术演进过程中的一些踩坑过程、方案设计、性能优化等,主要包括以下技术点:
- 全民K歌业务特性;
- Feed业务读写选型;
- Feed数据吐出控制策略优化;
- Feed核心表设计;
- K歌业务层面踩坑及优化过程;
- K歌业务MongoDB使用踩坑及优化。
一、MongoDB业务层面优化
(一)腾讯音乐全民K歌业务特性
每一个社交产品,都离不开Feed流设计,在全民K歌的场景,需要解决以下主要问题:
- 我们有一些千万粉丝、百万粉丝的用户,存在关系链扩散的性能挑战;
- Feed业务种类繁多,有复杂的业务策略来控制保证重要的Feed曝光。
对于Feed流的数据吐出,有种类繁多的控制策略,通过这些不同的控制策略来实现不同功能:
- 大v曝光频控,避免刷流量的行为;
- 好友共同发布了一些互动玩法的Feed,进行合并,避免刷屏;
- 支持不同分类Feed的检索;
- 安全问题需要过滤掉的用户Feed;
- 推荐实时插流/混排;
- 低质量的Feed、系统自动发类型的Feed做曝光频控。
(二)读写选型
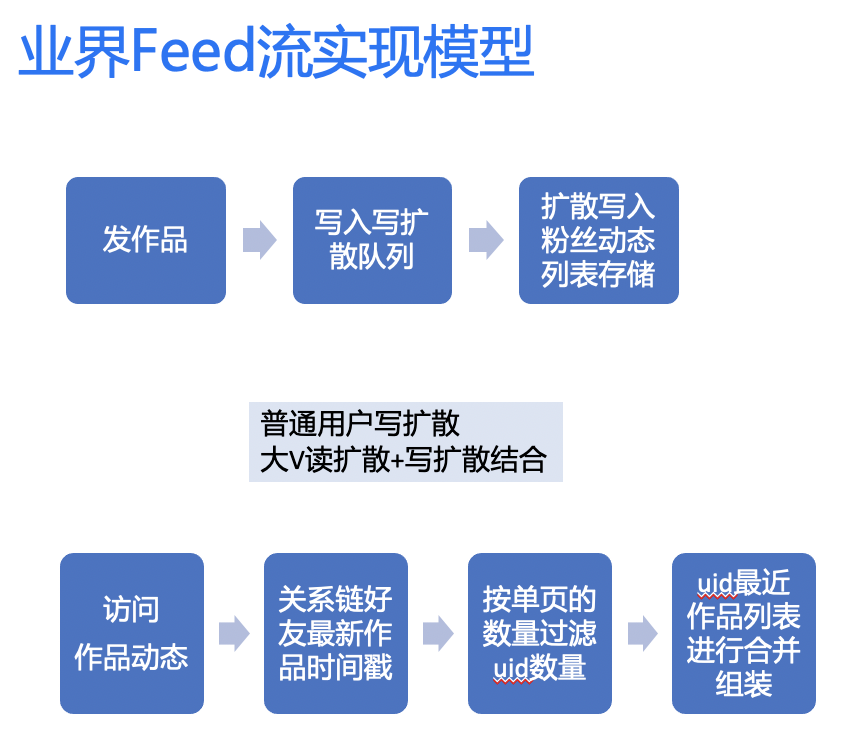
Feed主流实现模型主要分为3种,这些模型在业界都有大型产品在用:
- 读扩散 (QQ空间)
- 写扩散 (微信朋友圈)
- 大v读扩散+普通用户写扩散 (新浪微博)
没有最好的模式,只有适合的架构。选择合适的架构,需要结合业务模型、读写比例、历史包袱和实现成本等方面,权衡利弊。
K歌使用的是读扩散模型,使用读扩散模型的考虑如下:
- 存在不少千万/百万粉丝的大V,写扩散严重,推送延迟高,同时存储成本会高;
- 低活用户、流失用户推送浪费计算资源和存储资源;
- 安全合规相关的审核会引发大量写扩散;
- 写扩散qps=3*读扩散qps;
- K歌关系链导入的历史原因,早期写扩散成本高,同时后期改成读写扩散混合的模式改造成本大。
但是读扩散模式存在以下比较明显的缺点:
- 翻页把时间线前面的所有数据拉出来,性能开销越来越大,性能越来越差;
- 关注+好友数量可达万级别,实现全局的过滤、插流、合并、频控策略复杂,性能不足。
(三)读扩散优化
- 优化背景
读扩散模型的存储数据主要分为3大块:
- 关系链
- Feed数据
- 最新更新时间戳
未优化前的关系链读扩散模型,每次拉取Feed数据的时候,都需要通过关系链、时间戳,以及Feed索引数据来读扩散构建候选结果集。最后根据具体的Feedid拉取Feed详情来构建结果进行返回。
对于首屏,如果一页为10条,通过关系链+最新时间戳过滤出最新的20个uid(预拉取多一些,避免各种业务过滤合并策略把数据全部过滤),然后拉取每个uid最新的60条Feed的简单的索引信息来构建候选集合,通过各种业务合并过滤策略来构建最多10条最新Feedid,再拉取Feed详细信息构建响应结果。
翻页时把上一次返回的数据的最小时间戳basetime带过来,然后把basetime之前的有发布Feed的uid以及basetime之后有发布的最近20个uid过滤出来,重复上面步骤构建候选集合的过程来输出这一页的数据。这种实现逻辑翻页会越来越慢,延迟不稳定。
- 优化过程
针对以上问题,我们在读扩散模型上进行了一些优化,优化架构图如下:
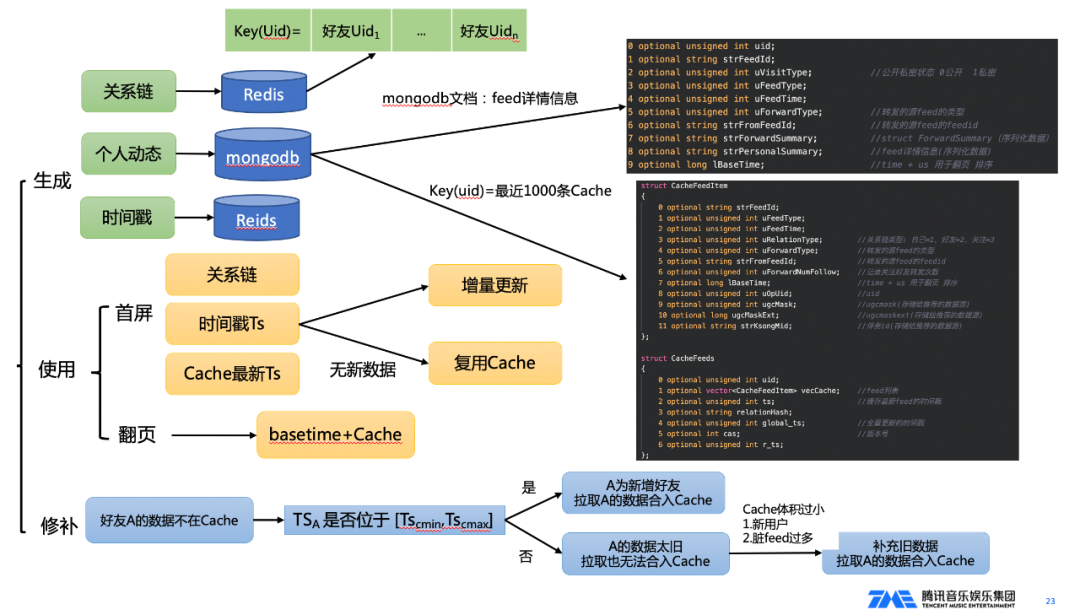
我们通过读扩散结果的Cache模式,解决翻页越来越慢、复杂的全局过滤逻辑的问题。
Cache优势:
- 灵活过滤,实现复杂的过滤合并逻辑;
- 翻页读Cache性能高,首页使用Cache避免重复计算。
时间线Cache需要解决的问题和弊端:
- 关系链变更Cache有延迟;
- 脏Feed导致Cache体积减小。
此外,我们把Cache主要分为全量生成过程,增量更新过程,以及修补逻辑三部分来解决这些问题:
- 全量是在首次拉取,和每24小时定时更新;
- 增量则是在首页刷新,无最新数据则复用Cache;
- 通过缓存关系链,如果关系链变更,活脏Feed太多导致过滤后的Cache体积过小,则触发修补逻辑。
最终,通过这些策略,我们的Feed流系统也具备了写扩散的一些优势,主要优势如下:
- 减少重复计算;
- 有全局的Feed视图,方便实现全局策略。
(四)主要表设计
- Feed表设计
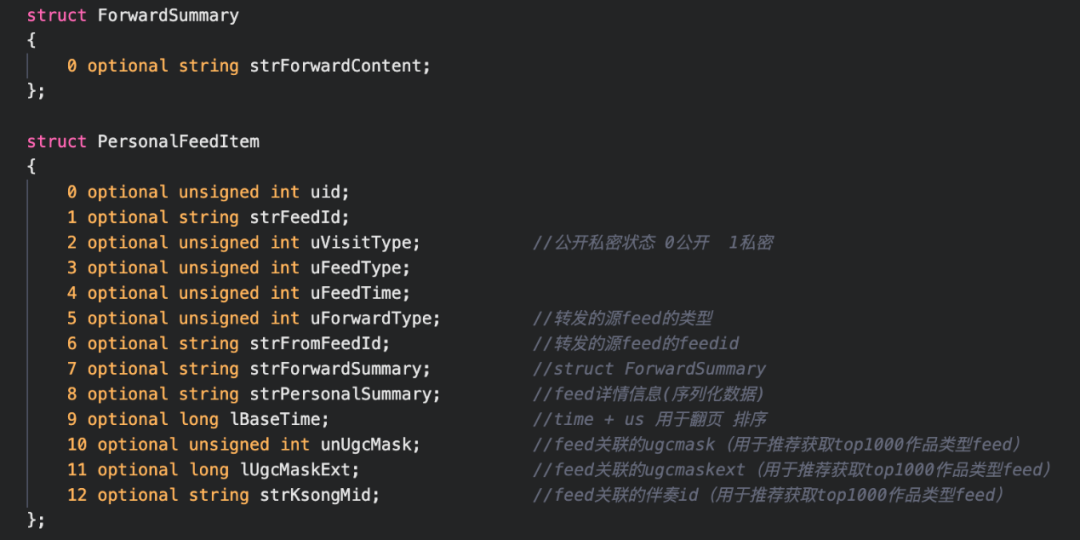
Feed这里的设计建立了2个表:Feed详情表和Feed Cache表。
Feed详情表:
该表使用用户userid做片键,Feedid做唯一键,表核心字段如下:
Feed Cache表:
该表使用uid做片键和唯一键,并且做ttl,表核心字段如下:
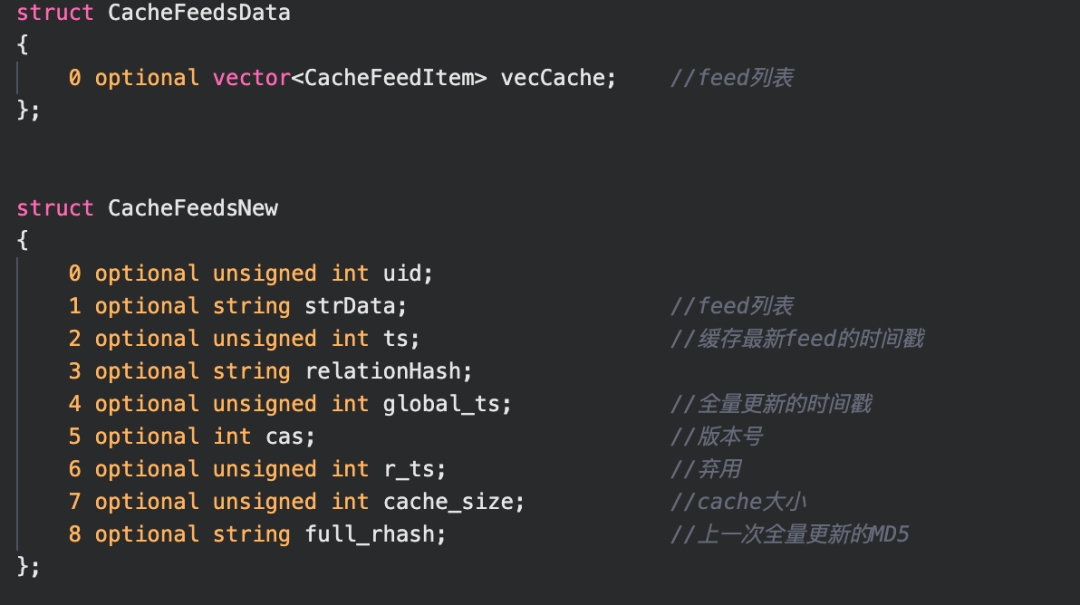
FeedCache是一个kv存储的文档,key是uid,value是CacheFeedData jce序列化后的结果。为了避免TTL删除数据消耗线上业务性能,可以在写入数据时指定过期时间。过期时间直接配置成业务低峰期时段。
- 账号关系表设计
关注关系链常规涉及两个维度的数据,一是关注,二是粉丝 (一个关注动作会产生两个维度数据)。
关注列表:
关注一般不是很多,最多只有几千,经常会被全部拉出来,这个可以存储为kv的形式(高性能可以考虑内存型数据库或cache)。
关注是用Redis存储的,一个key对应的value是上面RightCache这个结构的jce序列化后的结果。


粉丝列表:
粉丝是一个长列表(几百万甚至上千万),一般会以列表展示,存储于MongoDB中,以用户id为片键, 每个粉丝作为一个单独的doc,使用内存型的存储内存碎片的损耗比较高,内存成本大。关注和粉丝数据可以使用消息队列来实现最终一致性。
粉丝数据按照MongoDB文档存储,主要包含以下字段:opuid、fuid、realtiontype、time。
二、MongoDB使用层面优化
该业务MongoDB部署架构图如下:
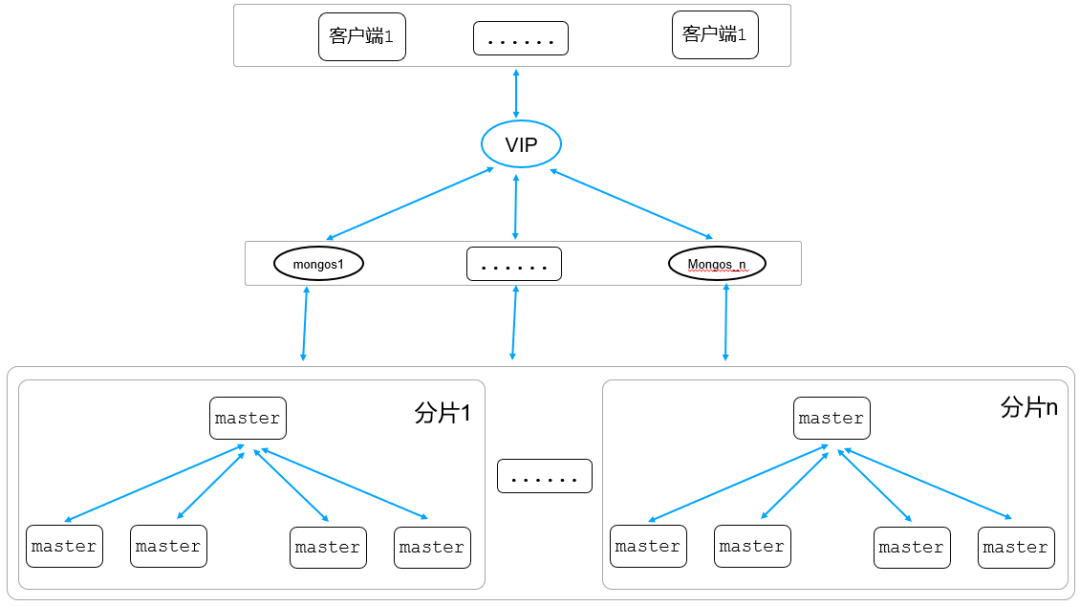
K歌业务MongoDB架构图:客户端通过腾讯云VIP转发到代理mongos层,代理mongos接受到请求后,从config server(存储路由信息,架构图中未体现)获取路由信息,然后根据这条路由信息获取转发规则,最终转发该请求到对应的存储层分片。在业务上线开发过程中,发现MongoDB的一些不合理使用的使用方式。通过对这些不合理的使用方式优化,提升了访问MongoDB的性能,最终提升了整个Feed流系统用户体验。
(一)K歌业务mongodb访问主要优化点如下
- 最优片建及分片方式选择
前面提到信息流业务Feed详情表、粉丝列表存储在MongoDB中,两个表都采用用户userId来做分片片建,分片方式采用hashed分片,并且提前进行预分片:
sh.shardCollection("xx.follower", {userId:"hashed"}, false, { numInitialChunks: 8192*分片数} )sh.shardCollection("xx.FeedInfo", {FeedId:"hashed"}, false, { numInitialChunks: 8192*分片数} )两个表分别选择FeedId和userId做片键,并且采用hashed分片方式,同时提前对表做预分片操作,主要是基于以下方面考虑:
- 数据写
通过提前预分片并且采用hashed分片方式,可以保证数据均衡的写入到不同分片,避免数据不均引起的moveChunk操作,充分利用了每个分片的存储能力,实现写入性能的最大化。
- 数据读
通过FeedId查询某条Feed详情和通过userId查询该用户的粉丝列表信息,由于采用hashed分片方式,同一个Id值对应的hash计算值会落在同一个shard分片,这样可以保证整个查询的效率最高。
说明:由于查询都是指定id类型查询,因此可以保证从同一个shard读取数据,实现了读取性能的最大化。但是,如果查询是例如userId类的范围查询,例如 db.FeedInfo.find({FeedId:{$gt: 1000,$lt:2000}}),这种场景就不适合用hashed分片方式,因为满足 {$gt: 1000}条件的数据可能很多条,通过hash计算后,这些数据会散列到多个分片。这种场景范围分片会更好,一个范围内的数据可能落到同一个分片。所以,分片集群片键选择、分片方式对整个集群读写性能起着非常重要的核心作用,需要根据业务的实际情况进行选择。
K歌feed业务都是根据feedId、userId进行查询,不存在范围查询,因此选用hash预分片方式进行片键设置,这样可以最大化提升查询、写入功能。
- 不带片键查询优化
上一节提到,查询如果带上片键,可以保证数据落在同一个shard,这样可以实现读性能的最大化。但是,实际业务场景中,一个业务访问同一个表,有些请求可以带上片键字段,有些查询则没有片键字段,这部分不带片键的查询需要广播到多个shard,然后mongos聚合后返回客户端。这类不带片键的查询相比从同一个shard获取数据,性能会差很多。
如果集群分片数比较多,某个不带片键的查询SQL频率很高,为了提升查询性能,可以通过建立辅助索引表来解决该问题。以Feed详情表为例,该表片建为用户userId,如果用户想看自己发表过的所有Feed,查询条件只要带上userId即可。
但是,如果需要FeedId获取指定某条Feed则需要进行查询的广播操作,因为Feed详情表片键为userId。此时查询性能会受影响。不带片键的查询不仅仅影响查询性能,还会加重每个分片的系统负载,因此可以通过增加辅助索引表(假设表名:FeedId_userId_relationship)的方式来解决该问题。辅助表中每个doc文档主要包含2个字段:
- FeedId字段
该字段和详情表的FeedId一致,代表具体的一条Feed详情。
- UserId
该字段和详情表userId一致,代表该FeedId对应的这条Feed详情信息由该user发起。
FeedId_userId_relationship辅助表采用FeedId做为片建,同样采用前面提到的预分片功能,该表和Feed详情表的映射关系如下:
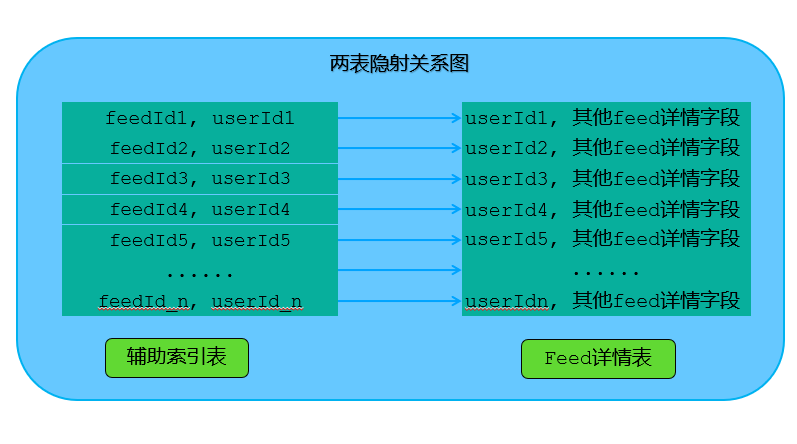
如上图,通过某个FeedId查询具体Feed时,首先根据FeedId从辅助索引表中查找该FeedId对应的userId,然后根据查询到的userId+FeedId的组合获取对应的详情信息。整个查询过程需要查两个表。查询语句如下:
如上,通过引入辅助索引表,最终解决跨分片广播问题。由于引入辅助表会增加一定的存储成本,同时会增加一次辅助查询,一般只有在分片shard比较多,并且不带片键的查询比较频繁的情况下使用。
- count慢操作的优化
前面提到,粉丝关系表存在mongodb中,每条数据主要包含几个字段,用户的每个粉丝对应一条mongodb文档数据,对应数据内容如下:
{ "_id" : ObjectId("6176647d2b18266890bb7c63"), "userid" : “345”, "follow_userid" : “3333”, "realtiontype" : 3, "follow_time" : ISODate("2017-06-12T11:26:26Z") }一个用户的每个粉丝对应一条数据,如果需要查找某个用户下面拥有多少个粉丝,则通过下面的查询获取(例如查找用户id为“345”的用户的粉丝总数):
db.fans.count({"userid" : “345”})该查询对应执行计划如下:
{ "executionSuccess" : true, "nReturned" : 0, "executionTimeMillis" : 0, "totalKeysExamined" : 156783, "totalDocsExamined" : 0, "executionStages" : { "stage" : "COUNT", "nReturned" : 0, ...... "nSkipped" : 0, "inputStage" : { "stage" : "COUNT_SCAN", ...... } }, "allPlansExecution" : [ ] }和其他关系型数据库(例如mysql)类似,从上面的执行计划可以看出,对某个表按照某个条件求count,走最优索引情况下,其快慢主要和满足条件的数据量的多少成正比关系。例如该用户如果粉丝数量越多,则其扫描的keys(也就是索引表)会越多,因此其查询也会越慢。
从上面的分析可以看出,如果某个用户粉丝很多,则其count操作会很慢。因此,我们可以使用一个幂等性计算的计数来存储粉丝总数和关注总数,这个数据访问量比较高,可以使用高性能的存储,例如Redis的来存储。幂等性的计算可以使用Redis的lua脚本来保证。
优化办法:粉丝数量是一个Redis的key,用 lua脚本执行(计数key incrby操作与opuid_touid_op做key的setnx expire)来完成幂等性计算。
- 写大多数的优化
写入数据可以根据业务的数据可靠性来选择不同的writeConcern策略:
- {w: 0} :对客户端的写入不需要发送任何确认。场景:性能要求高;不关注数据完整性
- {w: 1}:默认的writeConcern,数据写入到Primary就向客户端发送确认。场景:兼顾性能与一定层度得数据可靠性。
- {w: “majority”}:数据写入到副本集大多数成员后向客户端发送确认。场景:数据完整性要求比较高、避免数据回滚场景,该选项会降低写入性能。
对于数据可靠性要求比较高的场景往往还会使用{j: true}选项来保证写入时journal日志持久化之后才返回给客户端确认。数据可靠性高的场景会降低写的性能,在K歌Feed业务使用初期的场景中,我们会发现写大多数的场景都写延迟不太稳定,核心业务都出现了这种情况,从5ms到1s抖动。通过分析定位,我们发现是写时候到链式复制到策略导致的。
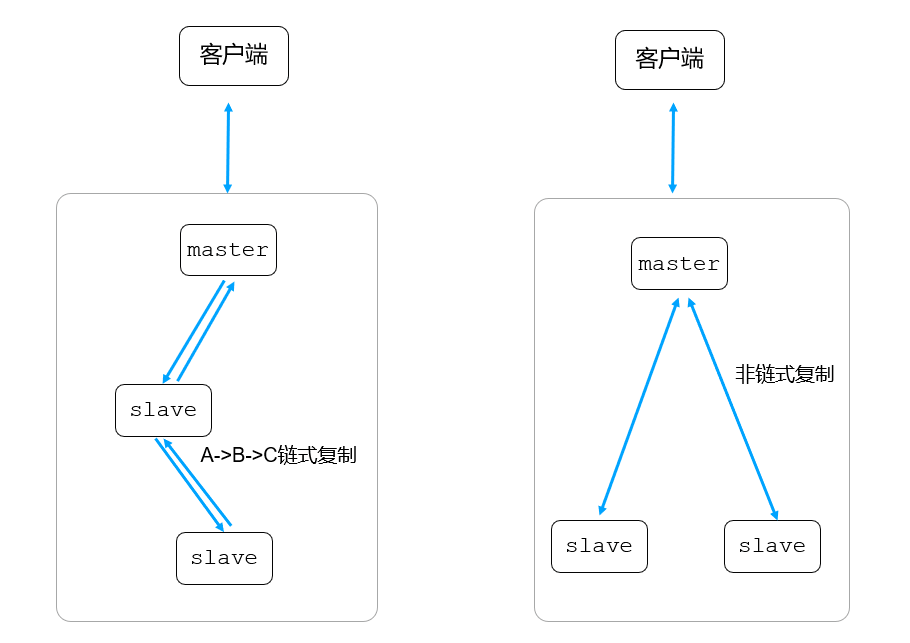
链式复制的概念:
假设节点A(primary)、B节点(secondary)、C节点(secondary),如果B节点从A节点同步数据,C节点从B节点同步数据,这样A->B->C之间就形成了一个链式的同步结构,如下图所示:
MongoDB多节点副本集可以支持链式复制,可以通过如下命令获取当前副本集是否支持链式复制:
cmgo-xx:SECONDARY> rs.conf().settings.chainingAllowed true cmgo-xx:SECONDARY>此外,可以通过查看副本集中每个节点的同步源来判断当前副本集节点中是否存在有链式复制情况,如果同步源为secondary从节点,则说明副本集中存在链式复制,具体查看如下副本集参数:
cmgo-xx:SECONDARY> rs.status().syncSourceHost xx.xx.xx.xx:7021 cmgo-xx:SECONDARY>由于业务配置为写多数派,鉴于性能考虑可以关闭链式复制功能,MongoDB可以通过如下命令操作进行关闭:
cfg = rs.config() cfg.settings.chainingAllowed = falsers.reconfig(cfg)- 链式复制好处:可以大大减轻主节点同步oplog的压力。
- 链式复制不足:当写策略为majority时,写请求的耗时变大。
当业务采用“写大多数”策略时,应相应地关闭链式复制,避免写请求耗时变大。我们关闭了链式复制后整体写延迟稳定在10ms以内。
- 海量qps业务抖动的优化
在一些核心集群,我们发现在高峰期偶尔会慢查询变多,服务抖动,抖动看起来是因为个别CPU飙升导致的。通过分析具体高CPU的线程,以及perf性能分析具体的函数,我们发现主要是两个问题:
- 高峰期连接数量陡涨,连接认证开销过大,导致CPU飙升;
- WT存储引擎cache使用率及脏数据比例太高,MongoDB的用户线程阻塞进行脏数据清理,最终业务侧抖动。
为了优化这两个问题,我们通过优化MongoDB的配置参数来解决:
- MongoDB连接池上下限一致,减少建立连接的开销;
- 提前触发内存清理eviction_target=60 ,用户线程参与内存清理的触发值提高到97%:eviction_trigger=97,增加更多的清理线程:evict.threads_max:20,从而减少高峰期慢查询150k/min=>20k/min,服务稳定性也的到了提升。
优化后效果如图:

- 数据备份过程业务抖动的优化
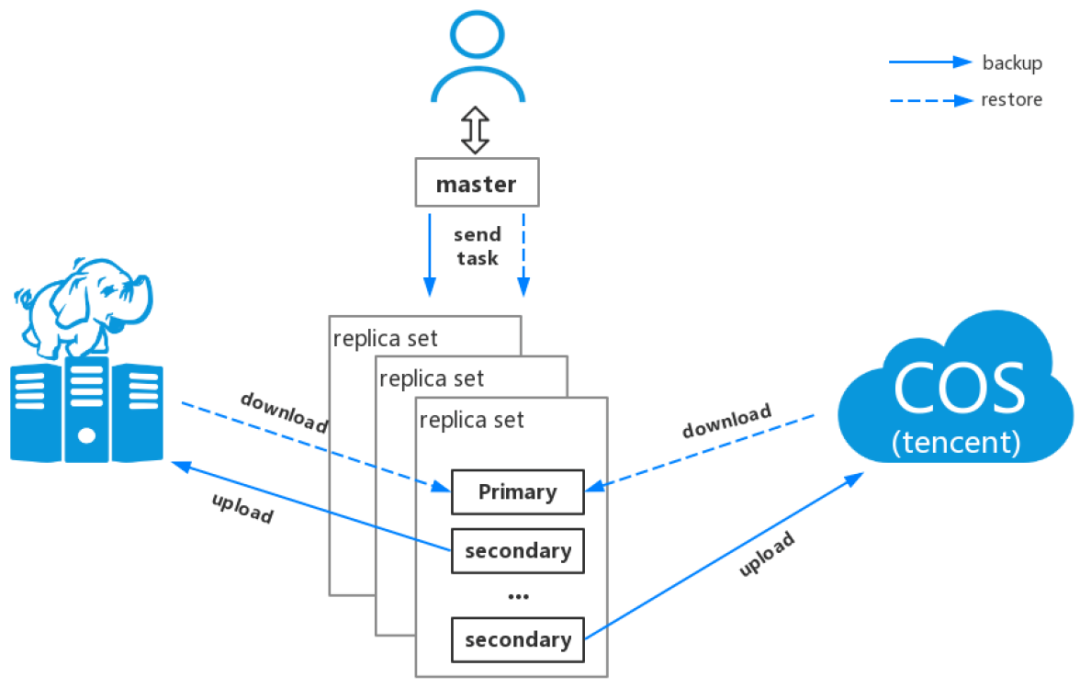
腾讯云MongoDB默认凌晨会定期对集群数据做全量备份和增量备份,并支持默认7天内的任意时间点回档。但是,随着集群数据量逐渐的增加,当前该集群数据量已经比较大,开始出现凌晨集群定期抖动,主要现象如下:
- 访问时延增加
- 慢日志增加
- CPU使用率增加
通过分析,发现问题和数据备份时间点一致,由于物理备份和逻辑备份期间需要对整实例进行数据备份,系统资源负载增加,最终影响业务查询服务。
优化方式:数据备份期间隐藏节点,确保该节点对客户端不可见。
关于腾讯云MongoDB
腾讯云MongoDB当前服务于游戏、电商、社交、教育、新闻资讯、金融、物联网、软件服务等多个行业;MongoDB团队(简称CMongo)致力于对开源MongoDB内核进行深度研究及持续性优化(如百万库表、物理备份、免密、审计等),为用户提供高性能、低成本、高可用性的安全数据库存储服务。后续持续分享MongoDB在腾讯内部及外部的典型应用场景、踩坑案例、性能优化、内核模块化分析。陈文武&熊润煌&腾讯云Mongodb团队
