简介
MySQL 5.6引入了基于schema的并行复制,即如果binlog events操作的是不同schema的对象,不是DDL,且操作的对象没有对其他schema的foreign key关联,则这些binlog events在slave上做重放的时候可以并行。slave上依然还是有一条IO线程负责从master拉取binlog并写入relay log,之前负责重放relay log的SQL线程现在作为coordinator线程,根据读取到的relay log里的binlog event,决定是否需要下发到worker线程做并行重放。worker线程的数量由slave_parallel_workers决定,对于不能下发到worker的events,coordinator会等到所有worker线程执行结束后自己重放当前日志。
基于schema的并行复制MTS(Multi-Threaded Slave)能一定程度上解决之前由于单线程重放relay log造成的备库延迟问题,但当用户的实例只有一个schema时备库延迟的问题还是不能解决,而单库多表是比较常见的情形。
MySQL 5.7先是实现了基于commit-parent的并行复制,打破了之前schema的限制,很大程度提升了备库重放日志效率。在最新代码中,并行复制进一步被优化为基于lock-interval的方式,在重放日志时相较于commit-parent方式有更大的并行度。搜索关注“腾讯云数据库”官方微信立得10元腾讯云无门槛代金券,体验移动端一键管理数据库,学习更多数据库技术实战教程。
2. 基于commit-parent的并行复制
commit-parent方式的原理很简单,如果两个事务能在master节点同时prepare成功,说明他们之间不存在冲突,那么这两个事务可以在slave节点做并行重放。
为了能让slave知道两个事务是否同时prepare成功,master节点需要将事务prepare的时间戳记录在binlog中以供slave读取。MySQL以事务提交的时间点为分界将时间轴划分为很多小的时间片,每个事务的提交意味着当前时间片的结束,以及下一个时间片的开始;每个事务在prepare时获取当前时间片的起始时间点,作为该事务的prepare时间戳。
MySQL将时间戳实现为逻辑时间戳,是一个全局单调递增的计数器,所以每个事务在prepare时获取一个计数值,这个计数值被称作该事务的commit-parent,每个事务在commit时将这个全局计数器加1。如果两个事务拥有相同的commit-parent,则意味着这两个事务在同一个时间片里prepare成功,于是他们可以被并行地重放。所以slave端逻辑很简单,只需要判断当前事务和正在执行的事务是否拥有相同的commit-parent,然后决定能否和正在执行的事务一起执行。
一个例子如下:
Trx1 ------------P----------C-------------------------------->
|
Trx2 ----------------P------+---C---------------------------->
| |
Trx3 -------------------P---+---+-----C---------------------->
| | |
Trx4 -----------------------+-P-+-----+----C----------------->
| | | |
Trx5 -----------------------+---+-P---+----+---C------------->
| | | | |
Trx6 -----------------------+---+---P-+----+---+---C---------->
| | | | | |
Trx7 -----------------------+---+-----+----+---+-P-+--C------->
| | | | | | |横轴为每个事务的时间线,P为prepare时间点,C为commit时间点;竖线表示因为事务提交所导致的时间片划分。在这个例子中,Trx1, Trx2和Trx3可以并行重放,Trx5和Trx6可以并行重放。
3. 基于lock-interval的并行复制
上面例子中,在slave端重放时,Trx4不能和Trx5, Trx6做并行重放,但是这三个事务同时prepare成功了,他们之间并不存在锁冲突,所以是可以并行重放的。为了解决这类问题,MySQL实现了基于lock-interval的并行复制。这种方式的原理是,如果两个事务同时获得了其所需的所有锁,则表明这两个事务不冲突,可以同时重放。所以MySQL定义了lock-interval的概念:表示事务从获得所需所有锁开始,到释放第一个锁为止,这中间的时间段。为了简单地描述这个时间段,lock-interval的起始点被定义为事务中最后一个DML语句prepare的时间戳,终止点被定义为事务在引擎层commit前的时间戳。如果两个事务的lock-interval有重叠,说明它们不存在锁冲突,可以并行重放。图例如下:
- 可并行重放:
Trx1 -----L---------C------------>
Trx2 ----------L---------C------->
不能并行重放:
Trx1 -----L----C----------------->
Trx2 ---------------L----C------->
同commit-parent方式一样,master端需要将每个事务的lock-interval记录在binlog中,slave端读取到之后和正在执行的事务的lock-interval比较,如果当前事务的起始点晚于正在执行事务中最早的终止点,则当前事务必须等到所有正在执行事务结束后才能执行;否则可以和正在执行事务并行执行。lock-interval也是用逻辑时间戳来表示的,起始点和终止点分别记录在binlog中的last_committed和sequence_number中,生成这两个值的过程会在后面介绍。搜索关注“腾讯云数据库”官方微信立得10元腾讯云无门槛代金券,体验移动端一键管理数据库,学习更多数据库技术实战教程。生成两个值的过程和binlog组提交耦合地很紧,所以先介绍下binlog组提交原理。
4. binlog组提交
为了提供事务的D(Durability)属性,对于涉及数据写的事务,在返回commit成功之前需要先将WAL fsync到磁盘(出于平衡性能和crash safe的考虑,MySQL提供了两个参数控制这种行为: sync_binlog和innodb_flush_log_at_trx_commit,后面的讨论都假设这两个值设置为1)。如果每个事务提交都执行一次fsync会导致性能不高,所以MySQL实现了在fsync时将多个事务的WAL同时写到磁盘上,即组提交,包括binlog组提交和innodb redo log组提交。
对于单个事务提交,为了保证redo log和binlog的一致性,MySQL实现了2PC,流程如下(图片来源:http://mysqlmusings.blogspot.com/2012/06/binary-log-group-commit-in-mysql-56.html):
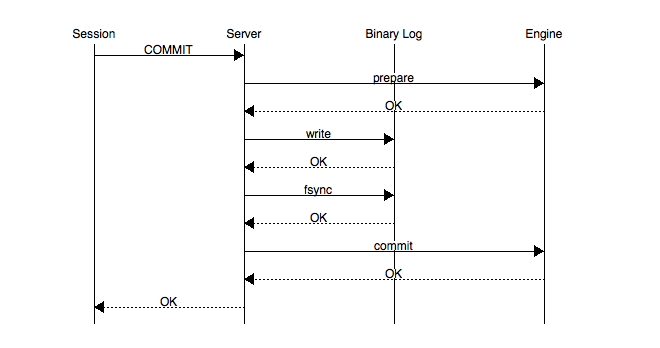
recovery的逻辑是,先读取redo log,对于redo log里prepare成功但是没有提交或回滚的事务,检查它是否在binlog中,如果binlog中有记录,则提交该事务;如果没有记录,则回滚该事务。在早版本MySQL中,prepare和commit会分别将redo log落盘,binlog提交也需要落盘,所以一次事务提交包括三次fsync调用。在5.7中,这部分代码做了优化,后面会介绍。
对于多个事务的组提交,一个关键是保证事务在redo log和binlog中的顺序一致。这个顺序一致要求来源于xtrabackup和ibbackup这类物理备份工具的实现,他们依赖这个假设来保证主备数据的一致。
上述的2PC并不能保证这一点,所以在5.6之前,为了保证事务顺序一致引入了一个prepare_commit_mutex,事务在prepare阶段获取它,在commit成功后释放。这样做的坏处是限制了吞吐,同一时间只能有一个事务在提交,所以group commit变得没有意义,不能做到真正批量fsync。
5.6真正解决了这个问题,去掉了prepare_commit_mutex,通过如下机制保证顺序的一致:
- 整个commit分为三个阶段:flush阶段,sync阶段和commit阶段,入口函数为MYSQL_BIN_LOG::ordered_commit;
- flush阶段将binlog从thd的cache中写到binlog文件,sync阶段调用fsync,commit阶段做引擎层的按序提交;
- 每个阶段有一个队列,第一个进入队列的事务(即队列为空时)会作为当前阶段的leader,其他的作为follower,leader确认自己身份后把当前队列中的followers摘出来,并代表他们和自己做当前阶段需要做的工作,再进入到下一个阶段的队列中,如果下一个队列为空,它会继续作为leader,如果不为空,则它和它的followers会变为新阶段的follower,一旦成为follower,就只需要等待别的线程通知事务提交完成;函数实现在MYSQL_BIN_LOG::change_stage,返回值为true时表示是follower,调用DBUG_RETURN(finish_commit())等待结束,否则做当前阶段工作;
- 顺序的一致通过队列顺序得到保证;
前面提到5.7中的2pc实现做了一些优化,主要在两点:
- commit阶段redo log不落盘。根据recovery逻辑,事务的提交成功与否由binlog决定,只要将binlog落盘了commit阶段是不需要fsync的,所以一次事务提交只需要两次fsync调用;
- prepare日志只需要保证在写入binlog之前fsync到磁盘即可,所以可以在binlog组提交里flush阶段开始时将prepare日志落盘。这样做的好处是可以批量fsync多个事务的prepare日志,即redo log组提交。这部分代码实现在:
MYSQL_BIN_LOG::ordered_commit --> process_flush_stage_queue --> ha_flush_logs // fscyn prepare redo log
|__ flush_thread_caches // write binlog caches和binlog组提交相关的几个参数:
- binlog_max_flush_queue_time:这个参数只在5.7.9之前生效,当事务发现自己是flush阶段leader之后,并不马上进入下一阶段,而是等待binlog_max_flush_queue_time再继续。这样做好处是一次可以fsync更多事务,坏处是可能导致单个事务响应变慢;
- binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count:等待binlog_group_commit_sync_delay毫秒直到收集到binlog_group_commit_sync_no_delay_count个事务时,进行一次组提交;
5. Master端MTS支持
前面提到,在binlog中,lock-interval通过两个值表征,last_committed值和sequence_number,每一条Gtid_event都包含这两个值,在日志中体现为:
[gpadmin@~/workspace/install/data]$ mysqlbinlog master-bin.000002 | grep last_committed
#170814 11:48:16 server id 1 end_log_pos 259 CRC32 0xb7cf2899 GTID last_committed=0 sequence_number=1
#170814 11:48:22 server id 1 end_log_pos 513 CRC32 0x8bfdd3a0 GTID last_committed=0 sequence_number=2
#170814 11:48:35 server id 1 end_log_pos 767 CRC32 0x56e7f3f7 GTID last_committed=2 sequence_number=3
#170814 11:48:49 server id 1 end_log_pos 1021 CRC32 0xb601ea8f GTID last_committed=3 sequence_number=4在代码中有三个类包含这两个数值信息:
class Gtid_event: public Binary_log_event
{
long long int last_committed; //当前binlog文件中,lock-interval起始点
long long int sequence_number; //当前binlog文件中,lock-interval终止点
}class Transaction_ctx
{
int64 last_committed;
int64 sequence_number;
}class MYSQL_BIN_LOG: public TC_LOG
{
Logical_clock max_committed_transaction; //最后一次组提交的事务中最大sequence_number
Logical_clock transaction_counter; //全局递增数值,表征每一个事务
}
class Logical_clock
{
int64 state;
int64 offset; //每次rotate时记录当前state值
}
数值的产生以及流动如下:
- 所有数值都来源于MYSQL_BIN_LOG,每个事务在prepare时获取MYSQL_BIN_LOG.max_committed_transactions.state,记录在Transaction_ctx.last_committed中,表示当前事务lock-interval起始时间戳(绝对值),代码实现为:
binlog_prepare --> store_commit_parent;每个事务在组提交的flush阶段获取MYSQL_BIN_LOG.transaction_counter,记录在Transaction_ctx.sequence_number中,表示当前事务lock-interval终止时间戳(绝对值);注意,上面提到起始时间戳是事务中最后一条DML语句prepare时的时间戳,在代码实现中,为了方便,事务中每条DML语句prepare时都会更新last_committed,所以最后一条DML会覆盖之前的值; - 在组提交的flush阶段,获取Transaction_ctx.last_committed和Transaction_ctx.sequence_number后,计算该事务日志在当前binlog文件中的“相对”lock-interval,计算方式为
Transaction_ctx.last_committed - MYSQL_BIN_LOG.max_committed_transactions.offset,记录在Gtid_event的last_committed中;Transaction_ctx.sequence_number - MYSQL_BIN_LOG.max_committed_transactions.offset,记录在Gtid_event的sequence_number中;Gtid_event会被写入到binlog中;代码实现在binlog_cache_data::flush中; - 当一次组提交结束时,在commit阶段中,找出这一组事务中的最大Transaction_ctx.sequence_number,写入到MYSQL_BIN_LOG.max_committed_transactions.state中;每次binlog rotate时将当前MYSQL_BIN_LOG.max_committed_transactions.state记录到MYSQL_BIN_LOG.max_committed_transactions.offset中;代码实现在
ordered_commit --> process_commit_stage_queue --> update_max_committed中;
搜索关注“腾讯云数据库”官方微信立得10元腾讯云无门槛代金券,体验移动端一键管理数据库,学习更多数据库技术实战教程。整个过程代码调用关系如下:
ordered_commit --> process_flush_stage_queue --> ha_flush_logs(fsync innodb prepare logs)
| |__ assign_automatic_gtids_to_flush_group
| |__ flush_thread_caches --> binlog_cache_mngr::flush --> stmt_cache->flush
| |__ trx_cache->flush
|__ flush_cache_to_file --> flush_io_cache
|__ sync and commit stages
binlog_cache_data::flush --> set Transaction_ctx->sequence_number
|__ MYSQL_BIN_LOG::write_gtid, generate Gtid_log_event, relative sequence_number/last_committed
|__ MYSQL_BIN_LOG::write_cache --> do_write_cache
6. Slave端MTS实现
当调用START SLAVE命令时,slave实例上会启动IO线程和SQL线程(coordinator线程),coordinator线程入口函数及顶层调用关系为:
handle_slave_sql --> slave_start_workers //fork worker线程,数量由参数slave_parallel_workers决定
|__ exec_relay_log_event //while循环调用,每次调用处理一个日志event
|__ slave_stop_workers //STOP SLAVE整体的逻辑为,coordinator线程通过调用next_event从relay log读取一个日志event,再调用apply_event确定当前event应当下发到workers做并行重放,还是必须由coordinator自己做串行重放,如果确定应当下发到workers,则调用append_item_to_jobs将当前event添加到相应worker的工作队列中。相关函数调用关系为:
exec_relay_log_event --> next_event --> read_log_event
| |__ mts_checkpoint_routine //检查是否需要做checkpoint,后面介绍
|__ apply_event_and_update_pos --> apply_event
|__ append_item_to_jobs (pass the job to worker, da first)
apply_event --> wait_for_workers_to_finish --> mts_checkpoint_routine //等待之前的并行workers执行结束
|__ apply_gtid_event
|__ do_apply_event
|....................(上下不同分支,下为可下发到worker,上为需coordinator做重放)
|__ get_slave_worker --> schedule_next_event --> wait_for_last_committed_trx
|__ get_lease_occupied_worker
一个事务的所有日志event(在slave上称为一个group)会被下发到同一个worker执行,多个事务可能在多条worker线程上并行执行。如果一个事务被判断为应当下发到worker执行,在将其指派给相应worker前,需要判断该事务是否可以和所有workers上正在执行的事务同时执行。这部分逻辑实现在函数schedule_next_event --> wait_for_last_committed_trx中,简单地说就是检查当前事务lock-interval起始点(last_committed)是否大于所有正在执行事务的lock-interval终止点中最小的那个,如果是则需要等待,否则则可以并行执行。
worker线程的调用关系为:
slave_worker_exec_job_group --> slave_worker_exec_event(while loop to pop job) --> update vars like CGEP
| |__ do_apply_event_worker --> do_apply_event
|__ slave_worker_ends_group(after breaking loop) --> commit_positions(update Slave_job_group in gaq)
|__ update CGEP related调用关系中有提到gaq和CGEP等,这是coordinator和workers之间通信的变量,主要相关的一些类包括:
class Relay_log_info: public Rpl_info //记录coordinator线程状态
{
Slave_worker_array workers; //workers线程数组
Slave_committed_queue gaq; //G(lobal)A(ssigned)Q(queue),记录各事务在各worker上的分发状态,每个事务一个entry,entry类型为Slave_job_group
Preallocated_array<Slave_job_item, 8, true> curr_group_da; //d(efferred) a(rray),当前事务的一些日志event不能确定是否能下发到worker时,放进这个数组里,比如Gtid_log_event, Begin Query event
}class Slave_worker: public Relay_log_info //记录每条worker线程状态
{
Slave_jobs_queue jobs; //工作队列,每个元素类型为Slave_job_item
Relay_log_info *c_rli; //coordinator指针
ulong id;
ulong gaq_index; //当前执行事务在coordinator线程gaq中的下标
}typedef struct Slave_job_item //每条日志封装成一个job
{
Log_event *data; //日志event
uint relay_number;
my_off_it relay_pos;
} Slave_job_item;
typedef struct st_slave_job_group //每个事务一个group,记录当前事务状态
{
ulong worker_id;
Slave_worker *worker; //被下发到的worker
int32 done; //当前事务是否回放完成
} Slave_job_group;
coordinator和worker的交互流程为:
- 当读取到一个表示事务开始的日志event,包括BEGIN和Gtid_log_event,函数get_slave_worker会构建一个Slave_job_group用来表示当前事务,并加入到Relay_log_info中gaq的队尾;
- 同样在get_slave_worker中,对于暂时不能确定能否下发到worker的事务,如刚读取到BEGIN或Gtid_log_event,将它们加入到Relay_log_info.curr_group_da中;
- 读取后续的日志event,如果在get_slave_worker中判断为当前事务可以下发,并且返回相应的worker指针后(从apply_event返回后),coordinator会调用append_job_items先将之前存放在Relay_log_info.curr_group_da中的Slave_job_item添加到相应的worker的Slave_worker.jobs队列中,然后再将当前日志event添加到该jobs队列中,worker线程会从jobs队列读取并回放日志;
- 当worker执行完当前事务后,会把Relay_log_info.gaq中该事务对应的Slave_job_group里的done标记为真;
- coordinator会调用函数mts_checkpoint_routune定期做“checkpoint”操作,将Relay_log_info.gaq中已经执行结束的事务移出队列,移除方式为从队列头开始检查,如果done为真则移出,否则停止扫描,并标记Low Water Mark为移出的事务中最大的sequence_number(lock-interval终止点);函数调用为:
mts_checkpoint_routine --> check if needed //检查距离上次checkpoint是否足够时间和执行了足够多事务
|__ gaq->move_queue_head(remove done Slave_job_group and update lwm)额外说明的一点是,5.7同时支持基于schema和基于lock-interval的并行复制,由参数slave_parallel_type控制,当为DATABASE时,启用基于schema的机制,当为LOGICAL_CLOCK时启用基于lock-interval的机制。
基于schema的并行复制实现和上述介绍的代码是耦合在一起的,不过在get_slave_worker中是通过日志event涉及的schema对象获取worker(函数实现为map_db_to_worker),并将db到worker的映射关系保存在coordinator的一个hash表中(Relay_log_info.mapping_db_to_worker),hash entry的结构为:
typedef struct st_db_worker_hash_entry
{
const char *db;
Slave_worker *worker;
long usage; //使用这个分发映射关系的事务数量
} db_worker_hash_entry7. 总结
本文介绍了binlog组提交,以及并行复制的三种方式:基于schema的方式,基于commit-parent的方式,以及基于lock-interval的方式。
