一、服务器配置
我这里是领取的腾讯云体验服务器 (GPU计算型GN8 - 6核 56G)
CPU: 6核
内存:56GB
硬盘:100GB
显卡驱动:CUDA10.2
二、购买服务器
腾讯云GPU服务购买地址:https://cloud.tencent.com/product/gpu ,选择安装系统时推荐安装市场镜像里的公共镜像,里面有已经安装好的 CUDA 驱动, 推荐选择 ”CentOS 7.6 NVIDIA GPU基础镜像(预装驱动和CUDA 10.2)“ 这个镜像,因为安装使用 PaddlePaddle 需要 显卡驱动 10.1 及以上。另外服务器需要一个完整的显卡,不能是共享的显卡,因为系统会识别不到。
如果你要自己安装显卡驱动,腾讯云也提供了教程文档: https://cloud.tencent.com/document/product/560/8064
三、教程正式开始
1.安装 Anaconda
Anaconda是1个常用的python包管理程序,里面可以设置好多个python环境。
先下载 Anaconda 安装脚本
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2021.05-Linux-x86_64.sh --no-check-certificate
下载 Anaconda
下载完成后,执行安装,会提示你阅读授权,一直按回车就可以了
sh Anaconda3-2021.05-Linux-x86_64.sh
然后提示你是否同意,输入yes

最后会询问你安装的位置,一般不用更改,输入回车就行,它会自动解压缩
安装好了之后,把Anaconda配置到环境变量,就可以用快捷 conda 命令了
vim ~/.bashrc #编辑环境配置文件
export PATH="~/anaconda3/bin:$PATH" # 在第一行加入这个vim 输入 i 可以编辑,编辑好了之后按 Esc, 然后输入 :wq 保存修改

保存好了之后更新环境变量,在命令行输入:
source ~/.bash_profile最后验证一下是否配置成功,没有保存的话就是配置成功了!
安装好了之后,创建一个 python3.8的环境,执行一下命令,会有一个确认,输入 y ,然后回车就可以了
conda create --name paddle_env python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/激活 paddle_env 环境
conda activate paddle_env2.开始安装 PaddlePaddle
PaddlePaddle 是百度开源的深度学习框架
PaddlePaddle官网:https://www.paddlepaddle.org.cn
安装时根据自己的服务器配置选择对应的安装脚本
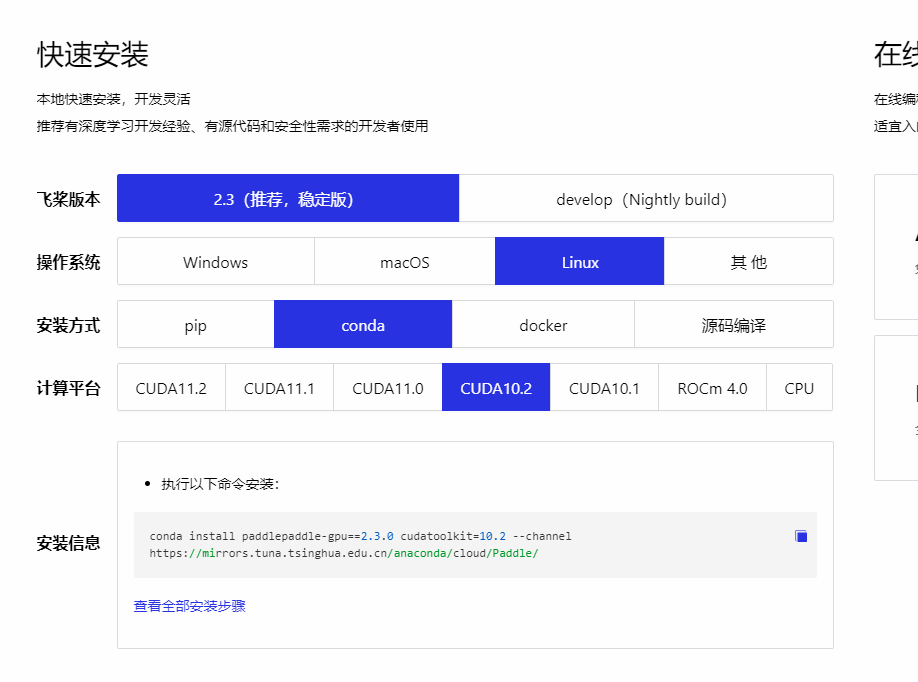
由于国内服务器访问Anaconda官方源可能会很慢,所以这里可以设置一下清华的镜像源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes
开始安装GPU版Paddle, 也会有一个输入确认,输入y回车就好了,这里安装会有点久哦
conda install paddlepaddle-gpu==2.3.0 cudatoolkit=10.2 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/
安装好PaddlePaddle 之后就可以开始安装PaddleOCR
3.安装PaddleOCR
PaddleOCR是百度基于PaddlePaddle开源的OCR文字识别服务
Github地址:https://github.com/PaddlePaddle/PaddleOCR/
安装,输入以下命令,安装好了之后就可以在命令行体验OCR识别服务了
pip install "paddleocr>=2.0." -i https://mirror.baidu.com/pypi/simple
下载一个测试图片体验包:地址
wget https://paddleocr.bj.bcebos.com/dygraph_v2.1/ppocr_img.zip #下载
unzip ppocr_img.zip #解压开始体验OCR识别
cd ppocr_img #进入刚才下载解压的图片目录执行OCR识别
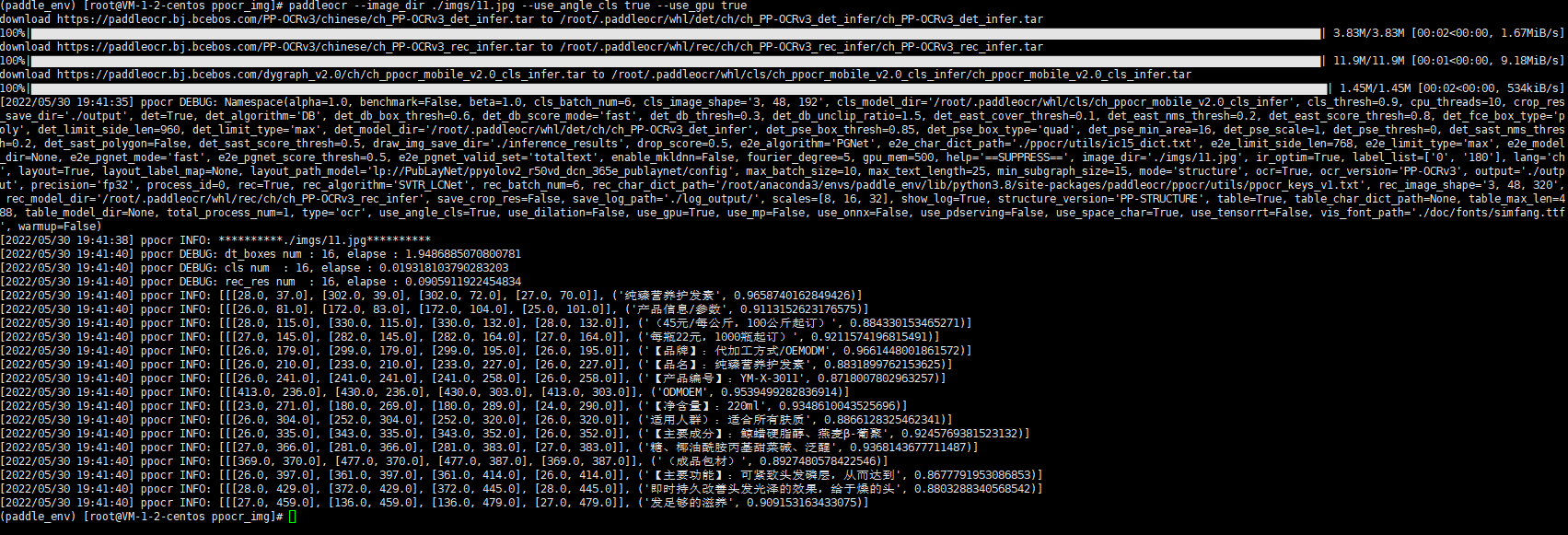
paddleocr --image_dir ./imgs/11.jpg --use_angle_cls true --use_gpu true执行可能会报错,这里需要安装 两个 lib libX11 和 libXext
yum install -y libX11
yum install -y libXext
这样就是识别出来啦,使用GPU服务器识别超快的
3.部署OCR识别API服务
部署的话,Paddle 提供了 PaddleHub 和 Paddle Serving 两个方式,使用PaddleHub是最方便的,命令行直接执行就可以了, Paddle Serving 部署的话更稳定,而且支持 c++ 编译部署。
这里讲一下 PaddleHub 和 Paddle Serving python 部署 (推荐还是 Paddle Serving 部署)
3.1 PaddleHub 部署 OCR 识别API
安装 PaddleHub
pip install --upgrade paddlehub -i https://mirror.baidu.com/pypi/simple启动 API 服务
hub serving start -m ch_pp-ocrv3 --use_gpu #会自动下载OCR模型这样就启动了一个 OCR 识别服务

接口的请求地址为:http://127.0.0.1:8866/predict/ch_pp-ocrv3
识别的时候需要把图片转为base64, 然后 json 请求去提交参数
python 测试脚本
import requests import json import cv2 import base64def cv2_to_base64(image):
data = cv2.imencode('.jpg', image)[1]
return base64.b64encode(data.tostring()).decode('utf8')发送HTTP请求
data = {'images':[cv2_to_base64(cv2.imread("你的图片地址"))]}
headers = {"Content-type": "application/json"}
url = "http://127.0.0.1/predict/ch_pp-ocrv3"
r = requests.post(url=url, headers=headers, data=json.dumps(data))打印预测结果
print(r.json())

通过 curl 去请求接口
curl --location --request POST 'http://127.0.0.1/predict/ch_pp-ocrv3'
--header 'Content-Type: application/json'
--data-raw '{"images":["图片的base64内容,不需前面的base64标识"]}'结果返回:
{"msg":[{"data":[{"confidence":0.9314630627632141,"text":"(paddle env][root@M-1-2-centos","text_box_position":[[6,10],[231,10],[231,23],[6,23]]},{"confidence":0.9092367887496948,"text":"ppocr imgl# hub serving start -m chpp-ocrv3 --use_gpu","text_box_position":[[227,10],[612,12],[612,25],[227,23]]},{"confidence":0.939938485622406,"text":"[2022-05-30 19:49:34 +0800]","text_box_position":[[5,25],[191,25],[191,38],[5,38]]},{"confidence":0.8236835598945618,"text":"[28320]","text_box_position":[[200,26],[246,26],[246,37],[200,37]]},{"confidence":0.6653339862823486,"text":"LINFO]","text_box_position":[[256,26],[295,26],[295,37],[256,37]]},{"confidence":0.842379093170166,"text":"starting gunicorn 2o.1.0","text_box_position":[[301,26],[474,26],[474,38],[301,38]]},{"confidence":0.939938485622406,"text":"[2022-05-30 19:49:34 +0800]","text_box_position":[[5,40],[191,40],[191,53],[5,53]]},{"confidence":0.8367705345153809,"text":"[28320]","text_box_position":[[200,41],[247,41],[247,52],[200,52]]},{"confidence":0.86468505859375,"text":"[INFO]","text_box_position":[[257,41],[297,41],[297,52],[257,52]]},{"confidence":0.9211856722831726,"text":"Listening at: http://0.0.0.0 (28320)","text_box_position":[[302,40],[589,40],[589,53],[302,53]]},{"confidence":0.9346868395805359,"text":"[2022-05-3019:49:34+0800]","text_box_position":[[4,55],[191,54],[191,67],[4,68]]},{"confidence":0.9421297311782837,"text":"[28320]","text_box_position":[[199,55],[247,55],[247,68],[199,68]]},{"confidence":0.9394086003303528,"text":"[INFO]","text_box_position":[[256,55],[298,55],[298,68],[256,68]]},{"confidence":0.9321832656860352,"text":"Using worker: sync","text_box_position":[[302,56],[430,56],[430,68],[302,68]]},{"confidence":0.9334865808486938,"text":"[2022-05-30 19:49:34 +0800]","text_box_position":[[4,70],[191,70],[191,83],[4,83]]},{"confidence":0.8994974493980408,"text":"[INFO] ","text_box_position":[[256,70],[305,70],[305,84],[256,84]]},{"confidence":0.8855429887771606,"text":"[28324]","text_box_position":[[200,71],[246,71],[246,82],[200,82]]},{"confidence":0.9438435435295105,"text":"Booting worker with pid: 28324","text_box_position":[[300,70],[515,69],[515,83],[300,84]]}],"save_path":""}],"results":"","status":"000"}这样就可以正常使用啦,识别速度的话大概在 100-300ms 左右,挺快的。
官方的部署教程:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/deploy/hubserving/readme.md
3.2 通过Paddle Serving 部署OCR识别服务
相比较于hubserving部署,PaddleServing具备以下优点:
- 支持客户端和服务端之间高并发和高效通信
- 支持 工业级的服务能力 例如模型管理,在线加载,在线A/B测试等
- 支持 多种编程语言 开发客户端,例如C++, Python和Java
- 先准备PaddleOCR 环境,这里拉去github代码的话会好慢,可以自己先科学下载,然后上传到服务器git clone https://github.com/PaddlePaddle/PaddleOCR --depth=1
进入到工作目录
cd PaddleOCR/deploy/pdserving/准备PaddleServing的运行环境,步骤如下
# 安装serving,用于启动服务 wget https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_server_gpu-0.8.3.post102-py3-none-any.whl pip3 install paddle_serving_server_gpu-0.8.3.post102-py3-none-any.whl安装client,用于向服务发送请求
wget https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_client-0.8.3-cp38-none-any.whl
pip3 install paddle_serving_client-0.8.3-cp38-none-any.whl安装serving-app
wget https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_app-0.8.3-py3-none-any.whl
pip3 install paddle_serving_app-0.8.3-py3-none-any.whl
模型转换
使用PaddleServing做服务化部署时,需要将保存的inference模型转换为serving易于部署的模型。
首先,下载PP-OCR的inference模型
# 下载并解压 OCR 文本检测模型
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar -O ch_PP-OCRv3_det_infer.tar && tar -xf ch_PP-OCRv3_det_infer.tar下载并解压 OCR 文本识别模型
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar -O ch_PP-OCRv3_rec_infer.tar && tar -xf ch_PP-OCRv3_rec_infer.tar
接下来,用安装的paddle_serving_client把下载的inference模型转换成易于server部署的模型格式。
# 转换检测模型
python3 -m paddle_serving_client.convert --dirname ./ch_PP-OCRv3_det_infer/
--model_filename inference.pdmodel
--params_filename inference.pdiparams
--serving_server ./ppocr_det_v3_serving/
--serving_client ./ppocr_det_v3_client/转换识别模型
python3 -m paddle_serving_client.convert --dirname ./ch_PP-OCRv3_rec_infer/
--model_filename inference.pdmodel
--params_filename inference.pdiparams
--serving_server ./ppocr_rec_v3_serving/
--serving_client ./ppocr_rec_v3_client/
检测模型转换完成后,会在当前文件夹多出ppocr_det_v3_serving 和ppocr_det_v3_client的文件夹,具备如下格式:
|- ppocr_det_v3_serving/
|- model
|- params
|- serving_server_conf.prototxt
|- serving_server_conf.stream.prototxt
|- ppocr_det_v3_client
|- serving_client_conf.prototxt
|- serving_client_conf.stream.prototxt
Paddle Serving pipeline部署
# 启动服务,运行日志保存在log.txt
python3 web_service.py &>log.txt &
运行日志,没有报错的话就是启动成功啦
然后可以使用他提供的client代码去请求测试一下
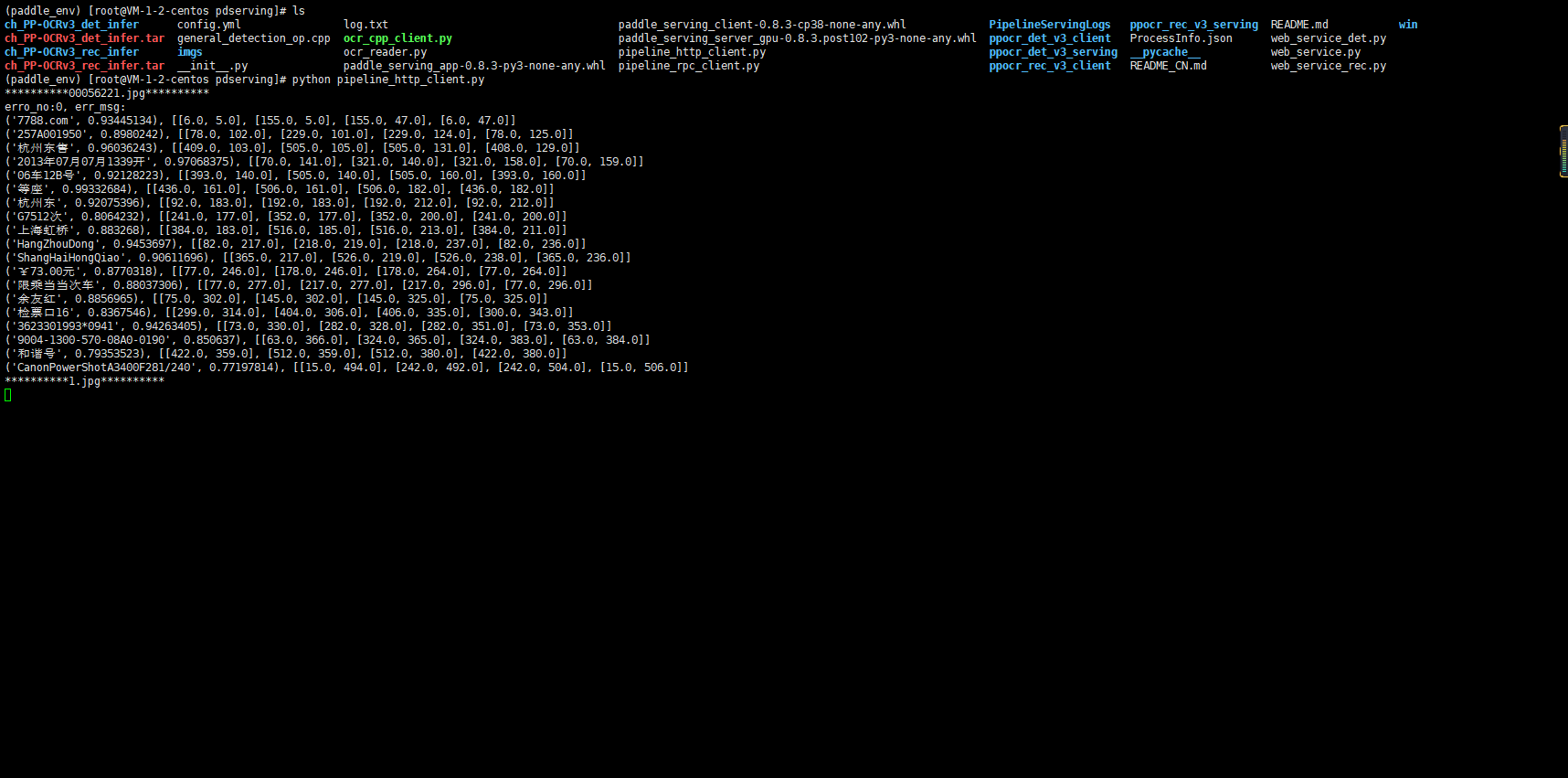
提供 HTTP API 去请求测试
请求地址:http://127.0.0.1/ocr/prediction
请求方式: json
请求参数:{“key”: “image”, “value”: “图片的base64”}
curl --location --request POST 'http://127.0.0.1/ocr/prediction' \--header 'Content-Type: application/json' \
--data-raw '{"key":"image","value":"图片的base64"}'
返回的数据格式:
{
"err_no": 0,
"err_msg": "",
"key": [
"result"
],
"value": [
"[[('(padde env)[root@M-1-2-centoppocrimghub servingstart -m chpp-ocrv3--usegpu', 0.84638405), [[5.0, 10.0], [611.0, 12.0], [611.0, 24.0], [5.0, 22.0]]], [('[2022-05-3019:49:34+0800][28320】[INF0]Startingqunicorm20.1.', 0.81580645), [[5.0, 25.0], [472.0, 25.0], [472.0, 38.0], [5.0, 37.0]]], [('[2022-05-3019:49:34+0800][28320][INF0]Listeningat:http://0.0.0.0(28320)', 0.84695405), [[5.0, 40.0], [589.0, 40.0], [589.0, 54.0], [5.0, 54.0]]], [('[2022-05-319:49:34+0800][28320】[INF0]Usingworker:sync', 0.7949861), [[5.0, 54.0], [430.0, 56.0], [430.0, 68.0], [5.0, 66.0]]], [('[2022-05-319:49:34+080】[28324】[INFO】Bootingworkerwith pid:28324', 0.85473406), [[4.0, 70.0], [515.0, 70.0], [515.0, 84.0], [4.0, 84.0]]]]"
],
"tensors": []
}这样就完成啦,可以正常使用啦,如果提供其他语言调用的话可以查看他们的官方文档
结语
部署这个相对还是挺简单的,Paddle 官方的文档也挺齐全,不过一些特殊文字识别的话还是需要自己去定制训练的,这里腾讯的GPU服务器还是挺不错的,这个还是免费体验的,哈哈哈。自己部署了一个OCR 识别服务,还是很有成就感的!