编者按
通过软硬件融合的“纽带”,认识了很多汽车界的朋友。最近半年来,跟很多汽车界的大佬深入交流了汽车底层的软硬件发展。惊奇地发现,汽车软硬件的相关技术,跟数据中心大同小异,非常接近。
例如,一切皆服务,云计算是由IaaS、PaaS、SaaS等组成的分层服务体系,而车端最近几年也在推SOA。再例如,云计算的基础是虚拟化,而车端的完全集中的自动驾驶芯片,其核心也是通过虚拟化技术实现多域系统的融合。
汽车大算力平台软硬件的发展趋势,可以简单的总结为:在数据中心已经成熟多年的技术,在逐步的下沉到自动驾驶汽车终端。
1 自动驾驶汽车芯片演进简介
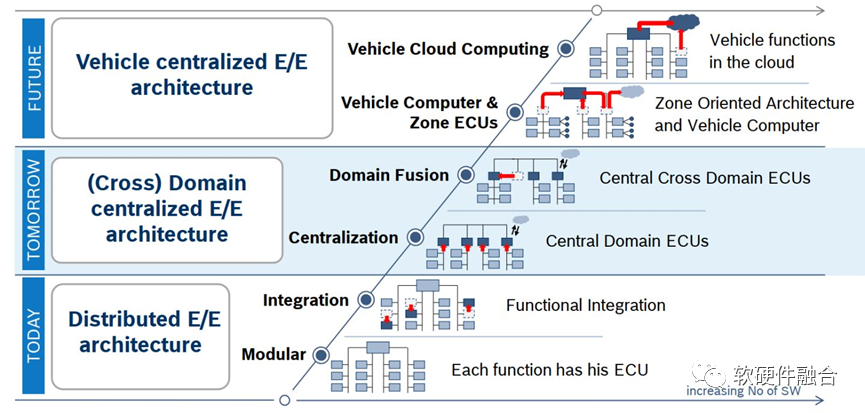
上图是BOSCH给出的汽车电气架构演进示意图。从模块级的ECU到集中相关功能的域控制器,再到完全集中的车载计算机。
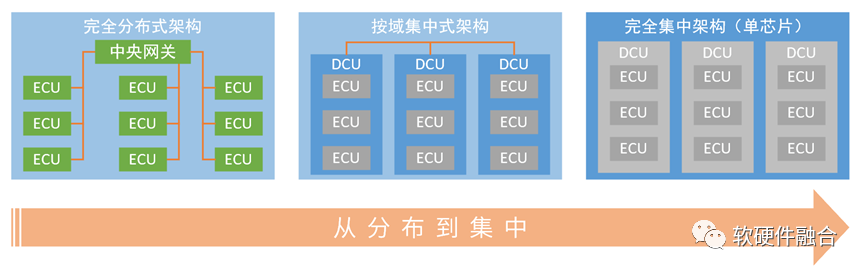
从系统架构角度分析,汽车的电气架构经过了三个发展阶段:
- 第一阶段,完全分布式架构。ECU是单个功能一个芯片,采用的芯片是传统MCU级别的芯片,一个MCU芯片负责一个具体的功能。一辆汽车需要数百颗ECU,芯片数量众多,芯片间的连接总线复杂。并且,由于不同的ECU可能来自不同的公司,这样的架构,各个ECU相互掣肘,优化和升级都很困难。
- 第二阶段,按域集中的架构。每个域控制器DCU是多个功能相近的ECU的集合,一个DCU相当于一个SOC。
- 第三阶段,终局思维,完全集中架构实现的超级终端芯片。完全集中的超级终端芯片系统,是多个单系统的集合,属于复杂的宏系统。也因此,集中的超级芯片可以看作是多个SOC的集合,Multi-SOC或Macro-SOC。
2 综合趋势:数据中心技术栈下沉到车端
汽车从机械化到电气化,再到智能化、网联化,如今的汽车越来越像一台电脑,更准确的说,是一个超级计算机。
“超级”体现在:自动驾驶汽车系统是一个非常复杂的系统,因此会把这个复杂系统按照不同的功能域划分为一个个简单小系统;相关的软硬件也需要划分成多个小系统的逻辑软硬件。反过来说,自动驾驶汽车是多个域控小系统融合的复杂大系统。
云计算是最典型的复杂系统计算场景,也因此,我们可以清晰的看到这个显著的趋势,就是已经在云计算数据中心成熟的技术,在逐步的下沉到汽车终端。
这些技术主要包括:
- 虚拟化。虚拟化是云计算的核心,也即将是汽车超级终端的核心。通过虚拟化技术,把物理的硬件灵活地虚拟成逻辑的多个不同规格的“硬件”供软件使用。
- 弹性。通过虚拟化、资源池化等技术,可以实现对各种资源的细粒度切分以及灵活的重组,以此来实现灵活的资源供给,高效地支撑更加灵活多变的应用需求。
- 迁移。迁移实现VM或容器在不同的硬件平台自由“流动”。迁移是实现系统高可用的基础,是资源宏观调度的基础,也是实现车规级芯片系统可靠性和稳定性的基础,还是实现云网边端融合的基础。
- 高可用。完全分布式的ECU阶段,车轨芯片关注的是器件的可靠性和功能的稳定性。随着汽车芯片越来越计算机化,可以通过一些更高层的技术实现软件服务的高可用,这样就可以降低对器件可靠性和基础功能稳定性的要求。
- 服务化。我们把资源、功能服务化,这样能够实现解耦,并且不需要关注底层的技术细节和运行维护等繁杂的工作。云计算通常分为IaaS、PaaS、SaaS三层,云计算本质上是由众多服务组成的一套服务体系。自动驾驶汽车软件栈核心思想是SOA,也即通过服务化来构建整个软件体系。
当然,如果仅仅只是数据中心技术栈下沉,那问题要简单很多。更全面的趋势/挑战在于数据中心技术栈下沉的过程中,叠加了底层的计算机体系结构重构(从异构走向超异构)。具体分析看后续的分趋势介绍。
3 趋势一:虚拟化成为软硬件的核心

虚拟化是云计算的核心,可以说,没有虚拟化就没有云计算。在自动驾驶汽车上,虚拟化技术也会成为最核心的支撑技术。
汽车超级芯片的软硬件系统栈和传统SOC系统栈的最大区别在于有没有虚拟化。通过虚拟化技术实现对硬件/软件的逻辑切分,提供多个逻辑的硬件/软件供上层软件使用。
虚拟化通常分为两类(虚拟化技术有三类,计算机虚拟化、容器虚拟化、函数虚拟化,函数虚拟化在车端目前应用的可能性不大):
- 计算机虚拟化:无虚拟化系统的系统软件只有OS,而计算机虚拟化的系统软件通常是Host OS(层1)、Hypervisor(层2)、Guest OS(层3),然后才是VM内的库和应用等更上层的软件。
- 容器虚拟化:通过容器相关的技术实现地虚拟化技术。流行的容器引擎有Docker、containerd、CRI-O等,而Kubernetes则是流行的容器集群管理系统。
4 趋势二:多域融合,多个单系统融合成复杂宏系统
BOSCH依据功能,把汽车划分为5个功能域:动力域(Power Train)、底盘域(Chassis)、车身域(Body/Comfort)、座舱域(Cockpit/Infotainment)、自动驾驶域(ADAS)。通常情况下,一个域需要一颗或多颗DCU-SOC芯片;而发展趋势,则是完全集中的超级计算机模式,也即把五个功能域融合到一个超大算力的单芯片解决方案。
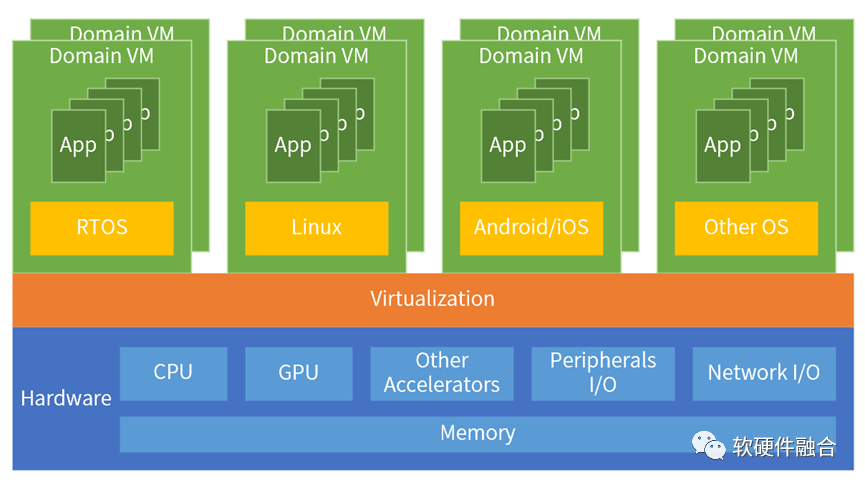
通过虚拟化技术,实现在单个硬件平台上支撑多个独立域工作的架构。也因此,在DCU域控制器所积累的各种软件生态,可以无缝地迁移到新架构上。
5 趋势三:未来五年,单芯片算力突破20000 TOPS
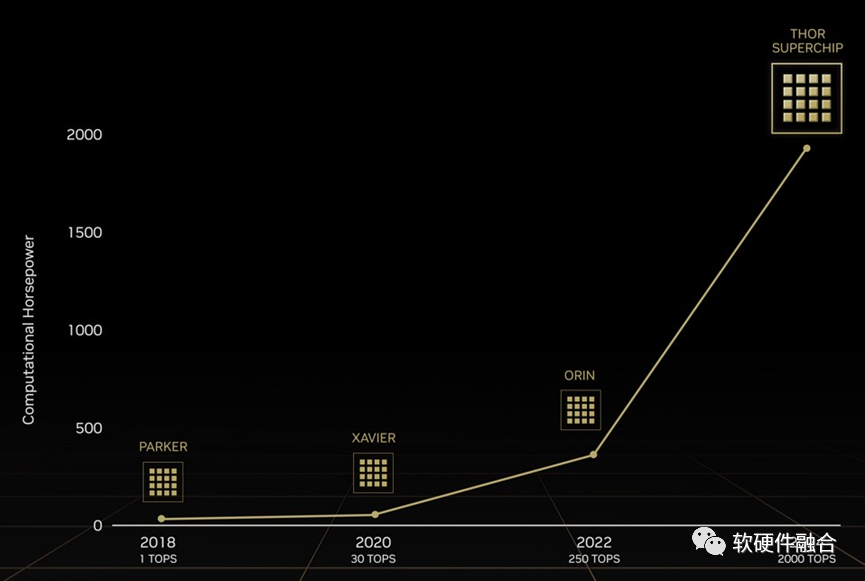
上图是NVIDIA自动驾驶芯片的发展Roadmap,我们可以看到,每隔两年升级一代,算力基本上提升8倍:
- 2018年,第一代,Parker,算力1 TOPS。
- 2020年,第二代,XAVIER,算力30 TOPS。Parker是NVIDIA汽车芯片的第一代产品,主要是试水,因此算力并不是很高,给了第二代直接增长30倍的空间。
- 2022年,第三代,ORIN,算力250 TOPS。比第二代提升8倍多。
- 2024年,第四代,THOR,算力2000 TOPS。比第三代提升8倍。
根据这个路线图的发展节奏,到2028年第六代芯片,算力将达到12.8万TOPS(128 POPS)。这个算力有点恐怖,实际上Thor已经基本上达到了目前工艺和封装的上限,未来的算力发展会受工艺和封装极限的约束。因此,我们给出相对保守的预测:
- 2026年,第五代自动驾驶芯片,算力再提升4倍以上,算力10000 TOPS(10 POPS)左右。
- 2028年,第六代自动驾驶芯片,算力再提升2倍以上,算力突破20000 (20POPS)TOPS。
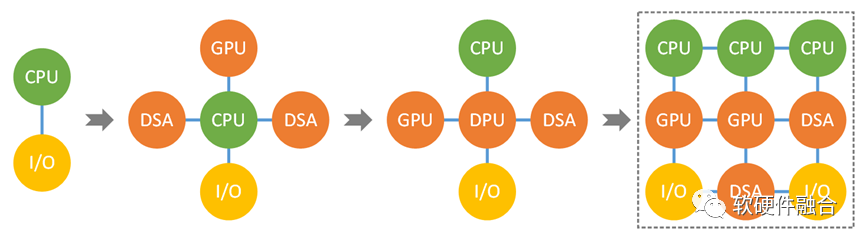
6 趋势四:体系结构逐步从异构走向超异构
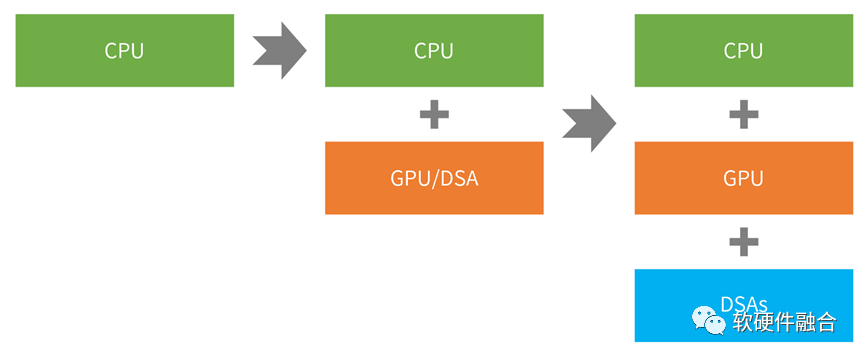
为什么需要异构计算?一方面,CPU的性能效率是最低的,并且已经性能瓶颈。随着业务对性能的要求越来越高,CPU已经不堪重负;另一方面,系统中大量的性能敏感型计算任务需要放到硬件加速器中进行加速处理,以此来提高性能。
但异构计算也有一些问题。
第一个问题是,异构计算中的加速处理器,其性能和灵活性特征无法兼顾:
- GPU灵活性较好,但性能效率不够极致;
- DSA性能好,但灵活性差,难以适应复杂计算场景对灵活性的要求;
- FPGA功耗和成本高,需要一些定制开发,落地案例不多;
- ASIC功能完全固定,难以适应灵活多变的复杂计算场景。
另一个严重的问题是计算孤岛问题。我们提供芯片A帮助客户解决问题a,提供芯片B帮助客户解决问题b,依此类推。但这样会产生有很多问题:
- 只考虑一个问题会顾此失彼,并且不同的芯片间没有协同。而且即使有协同,从架构上也决定了很难高效协同。
- 多个个体解决方案无法组织成用户需要的“有机”整体。如同“瞎子摸象”一般,当不同供应商给客户提供扇子、绳子、柱子、墙壁的时候,客户是无法组织成“大象”的。
- 服务器物理空间和功耗有限。无法容纳这么多张单领域或场景解决方案的加速卡,客户需要综合性解决方案。
合适的做法则是,进一步的从异构走向超异构。
一方面,把硬件分层从异构的两层再细分为超异构的三层:
- 层次一,DSA层。系统中的非常确定的任务沉淀到基础设施层,而DSA层则定位基础设施层加速,既高效又能够满足基础设施层工作任务的灵活性特定。
- 层次二,GPU层。定位性能敏感业务应用的加速。既有一定的性能加速效率,又能够兼顾业务应用场景的弹性需求。
- 层次三,最上层的CPU层。负责不适合加速的工作任务处理,CPU也负责兜底。
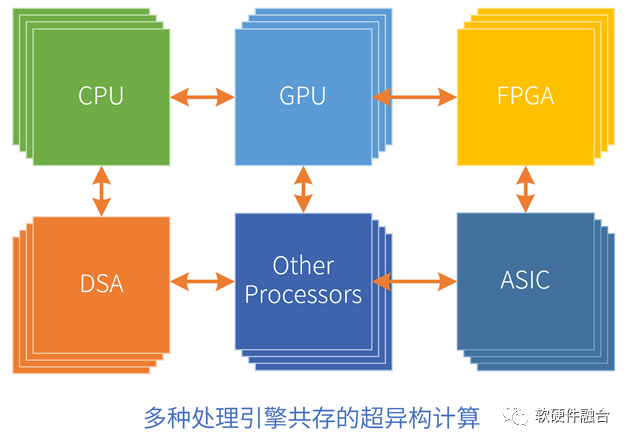
另一方面,最终承载这一切的必然是三个层次的、多种不同类型处理引擎协同工作的超异构计算架构。
7 趋势五:一切皆服务
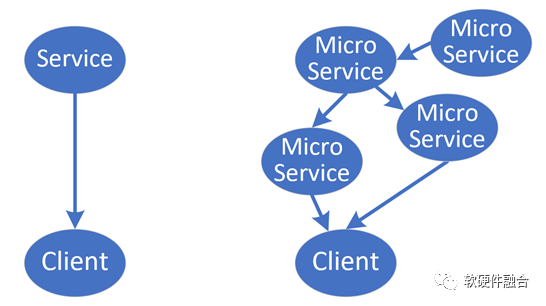
经典的C/S架构,一边是客户端的Client程序,另一端是服务器端的Service程序。如果我们进一步把这个架构细化,再考虑微服务化的影响,这样会形成一个微服务依赖网络。
一切皆服务,云计算是由IaaS、PaaS、SaaS等组成的分层服务体系,车端也在推SOA。软件服务化,甚至进一步地微服务化。不考虑SOA和微服务具体实施技术细节的不同,他们共同的特点在于:
- 通过服务实现不同软件实体间的解耦,以及资源和功能复用。
- 服务提供者保证服务的高可用,包括服务的性能和延迟等指标、服务所需的资源多寡以及服务的稳定性等,还需要考虑服务的弹性;而服务使用方不用关心这些具体细节。
- 服务不仅仅可以在本地部署和交互,也可以跨平台部署和交互。部署和交互:可以跨不同的虚拟环境(VM/容器等),也可以跨本地集群的不同硬件实体,甚至跨云网边端不同地理位置的设备。
8 趋势六:云网边端从协同走向融合
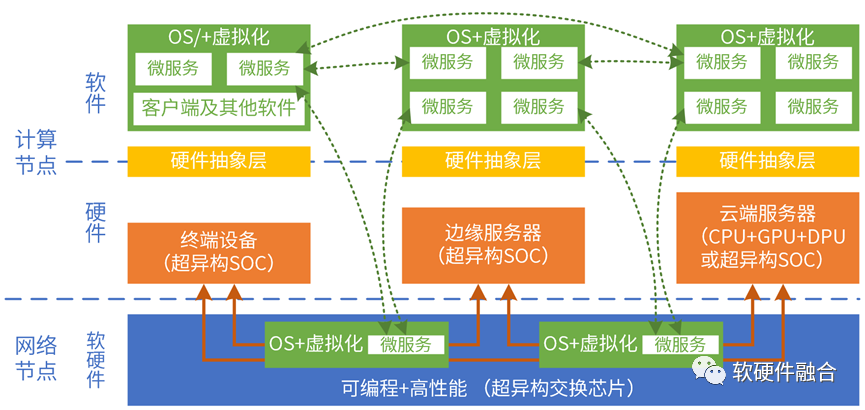
协同和融合有什么区别?协同的双方,依然“你是你,我是我”;而融合,则是双方组成了一个新的整体,不分彼此。
协同阶段,通常的系统功能划分是固定的,你做什么,我做什么,大家分工明确,协作完成整个工作。而挑战在于,系统不是静态的,宏观系统复杂而又多变,系统任务的准确分工,几乎不可能。
充分考虑到系统的复杂度和持续变化,充分意识到在设计初期很难把系统分工考虑清楚。并且,即使分工清楚,随着时间推移,系统变化,分工很可能还会发生改变。因此,需要动态的功能划分。
通过计算平台的融合,把云网边端形成一个统一的算力平台,把分工的事情交给上层的软件完成。软件自适应的寻找合适的运行平台,实现算力资源充分而又灵活的使用,实现云网边端的真正融合。
9(目前唯一的)案例:NVIDIA Thor

在NVIDIA GTC Sept 2022上,NVIDIA发布了2000TFLOPS算力的自动驾驶芯片Thor。

Thor SoC能够实现多域计算,它可以为自动驾驶和车载娱乐划分任务。通常,这些各种类型的功能由分布在车辆各处的数十个控制单元控制。制造商可以利用Thor实现所有功能的融合,来整合整个车辆,而不是依赖分布式的ECU/DCU。

多域计算隔离使得并发的时间敏感的进程可以不间断地运行。通过虚拟化机制,在一台计算机上,可以同时运行Linux、QNX和Android等。
多域计算隔离,可以实现应用、数据、资源、服务、性能和安全域等能力的物理上完全隔离。
NVIDIA Thor,是第一个实现多域融合的、集中式的、超大算力的超级终端大芯片。
(全文完)