新智元报道
编辑:拉燕 Lumina
【新智元导读】Cerebras联手G42打造了地表最强超算——Condor Galaxy 1(CG-1)。2024年,这样的超将有6个,最高可提供36 ExaFLOPs算力。
Cerebras又放大招了!
这个曾经打造出世界最大AI芯片的Cerebras,这次又为我们带来了世界最大的AI超级计算机:Condor Galaxy1(CG-1)!

CG-1以秃鹰星系命名,比我们的银河系要大上五倍。这个名字所代表的野心可谓是昭然若揭了!
那么就让我们来看看,这个叫Condar Galaxy的超级计算机究竟有哪些过人之处?
Condor Galaxy:世界最大的人工智能训练超级计算机
CG-1是现今世界上最大的超级计算机之一。
拥有64个CS-2节点、5400万核心、4 ExaFLOPs算力、并支持6000亿参数模型,第一次训练运行时间只需要10天。
CG-1旨在使大型突破性模型的训练更加轻松快速,从而加速创新。
Cerebras真的做到了......
做出更快、更强、更好的AI超级计算机!

不仅如此,Cerebas还与阿联酋技术控股集团G42达成了战略合作,准备联手打造一个由9台CG-1互联、基于云的AI超级计算全球网络:Condor Galaxy。
目前CG-1已在加利福尼亚州圣克拉拉部署成功,其余的CG2、3......将在18月内部署完成。
连Cerebras自家的CEO Andrew Feldman都表示:
「这太疯狂了!Condor Galaxy完成后,我们将拥有一个能够提供36 exaFLOPs训练能力的超级AI 计算网络。这意味着我们届时会拥有576个CS-2、近5亿个核心,内部带宽达到3,490 TB。我们将需要超过5亿个AMD Epyc来为我们提供数据。」
Condor Galaxy将显著减少AI大模型训练所需的时间,同时,Condor Galaxy 基于云的服务将允许其他人也能轻松访问业界最优秀的人工智能计算能力,从而推动全球数百个人工智能项目的发展。
这个前所未有的AI超级计算网络,可能会彻底改变全球人工智能的发展。
这格局、这能力,怪不得Cerebras被视为是威胁英伟达的强劲对手。
从Andromeda到Condor
Cerebras在官网上也是发布了Condor Galaxy1(CG-1)详细的参数信息。
- 4 exaFLOPS的AI计算能力
- 5400万个针对AI优化的计算核心
- 82 TB内存
- 64个Cerebras CS-2系统
- 基本配置支持6000亿个参数,可扩展至100万亿个
- 386 Tbps内部带宽
- 72704个AMD EPYC第3代处理器
- 本机硬件支持50000个token的训练,无需第三方库
- 具有线性性能扩展的数据并行编程模型

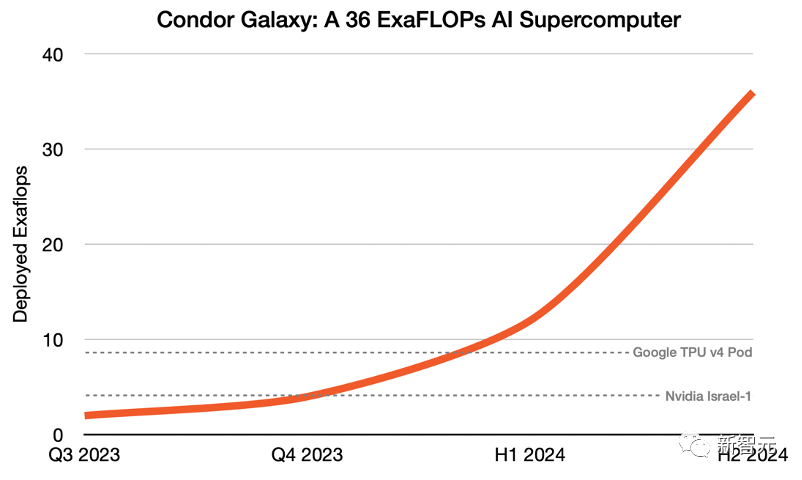
而且像这么能打的超算总共有9个,2024年完工。总计36 ExaFLOPS的AI算力,说一句世界最强不为过吧。
Cerebras将在7月24日的ICML 2023大会上分享在CG-1上训练新模型的结果。
2022年,Cerebras已经是世界上最大、最强大的AI处理器芯片了。
要想做得更大,唯一的办法就是让晶圆级引擎在集群规模上运行。
为了实现这一目标,Cerebras发明了两项技术:
- Cerebras Wafer-Scale集群
这是一种全新的系统架构,可连接多达192个Cerebras的CS-2系统,并作为单个逻辑加速器运行。这种设计将内存与计算解耦,能够为AI模型部署TB级内存,而仅使用GPU只能部署GB级的内存。
- 权重流(Weight streaming)
在晶圆级集群上仅使用数据并行性训练大型模型的新方法。Cerebras表示,他们发现客户在训练大型GPU模型时遇到了些困难。Cerebras的解决方案利用了硬件的大规模计算和内存的特性,以纯数据并行的方式,通过逐层流式传输模型来分配工作。
2022年11月,Cerebras将这两项技术推向市场,推出了Andromeda——这是一台1 exaFLOP、16 CS-2 AI的超算。
Andromeda有这么三个意义:
首先,它为Cerebras的晶圆级集群提供了设计参考,使他们能够更快速、轻松地为客户构建新的AI超算。
第二,它提供了一个训练大型生成模型的世界级平台,使Cerebras能够在短短几周内训练出7个Cerebras-GPT模型,并与全世界共享这些开源模型。
第三,它成为了Cerebras云的旗舰产品,为客户使用Cerebras的系统打开了大门,而无需采购和管理硬件。
而今天宣布的CG-1则是所有这些努力的结晶——它是Cerebras部署过的最大的AI超算,得益于Andromeda,Condor可以在短短两周内就完成部署。
目前,它已经训练了多个大型语言模型,涵盖阿拉伯语等全新数据集。它通过Cerebras云和G42云给全球的客户提供服务。
Condor Galaxy四步走
官网中,Cerebras也是披露了Condor Galaxy未来发展的四步计划。
- 第一阶段:
CG-1目前由32个CS-2系统组成,已在圣克拉拉的Colovore数据中心启动并运行。
- 第二阶段:
Cerebras将把CG-1的规模扩大一倍,将其扩展到64个CS-2系统,速度为4 exaFLOPS。一个64节点系统代表一个完整的超算实例。
- 第三阶段:
Cerebras们将在全美再建立两个完整的超算,使部署的计算中心总数达到3个,计算能力达到12 exaFLOPS。
- 第四阶段:
再建设6个超算中心,全部安装达到9个,人工智能计算能力达到36 exaFLOPS。
走完这四步,Cerebras就会是全球公共AI计算基础设施排名前三的公司了。

2024年全面部署Condor Galaxy后,其将成为世界上最大的云AI超算之一。运算能力达到36 exaflops,是英伟达以色列一号超算的9倍,是谷歌已发布的最大TPU v4 pod的4倍。
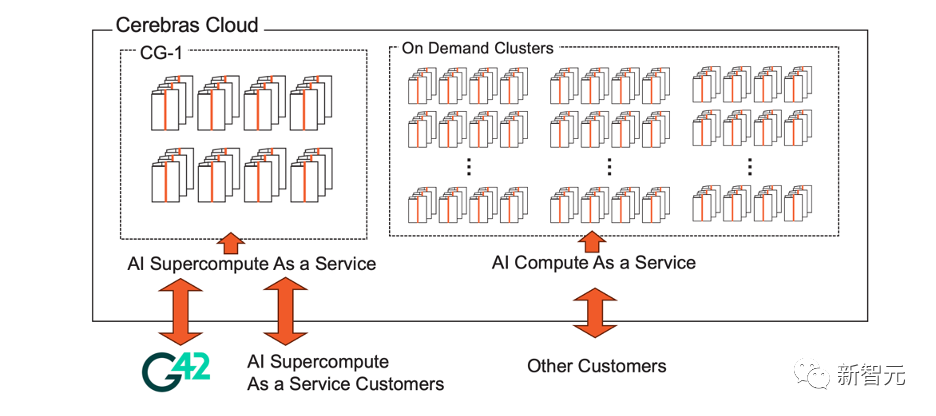
Cerebras云
Cerebras为G42管理和运营CG-1,并通过Cerebras云提供,用于人工智能训练的专用超级计算实例对模型开发至关重要。
要知道,OpenAI的ChatGPT得益于微软Azure建立的专用集群,DeepMind和Google Brain的突破则得益于GCP的预配置TPU pod。
自Andromeda发布以来,Cerebras一直在提供基于云的访问Cerebras系统的服务,最多可连接16个CS-2系统。
随着CG-1的推出,Cerebras现在正在扩大Cerebras的云服务,包括最多64个系统的全配置人工智能超级计算机,为客户提供一键访问4 exaFLOPs人工智能性能的服务。
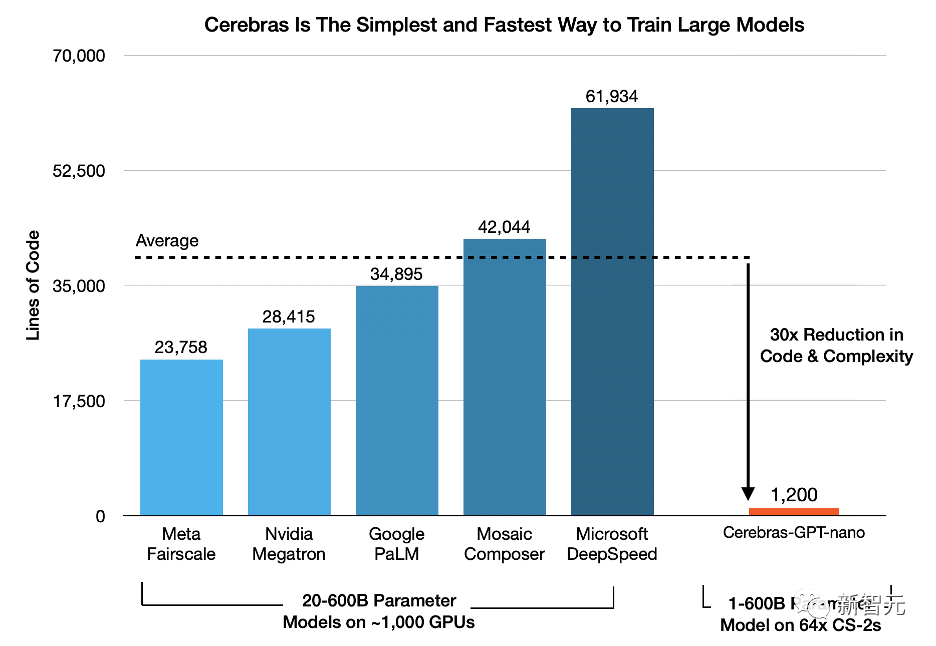
不光如此,Cerebras还解决了GPU扩展的难题。
虽然GPU是强大的通用加速器,但人们普遍认为,对大型GPU集群进行编程是ML开发人员面临的巨大技术障碍。
几乎所有公司都被迫要发明一种编程框架来管理这种复杂性,例如微软的DeepSpeed、英伟达的Megatron、Meta的Fairscale和Mosaic的Foundry。
Cerebras对这些库进行了深入分析,发现在GPU集群上训练一个模型平均需要约38000行代码。
对于大多数软件团队来说,复杂性实在太高,根本无法管理。
Cerebras晶圆级的集群,无论是1个节点还是64个节点,从根本上说都是作为一个单一的逻辑加速器来设计的。
由于CG-1具有82 TB的统一内存,Cerebras的团队甚至可以将最大的模型直接放入内存中,而无需任何分区或额外的代码。
在Cerebras上,100B参数模型使用的代码与1B模型相同,不需要任何流水线或模型并行性。
Cerebras本机支持多达50000个token的长序列训练。
效果就是,在Cerebras上实现标准的GPT仅需1200行代码,比行业领先框架的平均代码简洁30倍。
参考资料:
https://www.cerebras.net/press-release/cerebras-and-g42-unveil-worlds-largest-supercomputer-for-ai-training-with-4-exaflops-to-fuel-a-new-era-of-innovation