大家好,这是专栏《AI不惑境》的第七篇文章,讲述计算机视觉中的注意力(attention)机制。
进入到不惑境界,就是向高手迈进的开始了,在这个境界需要自己独立思考。如果说学习是一个从模仿,到追随,到创造的过程,那么到这个阶段,应该跃过了模仿和追随的阶段,进入了创造的阶段。从这个境界开始,讲述的问题可能不再有答案,更多的是激发大家一起来思考。
作者&编辑 | 言有三
Attention机制在近几年来在图像,自然语言处理等领域中都取得了重要的突破,被证明有益于提高模型的性能。Attention机制本身也是符合人脑和人眼的感知机制,这次我们主要以计算机视觉领域为例,讲述Attention机制的原理,应用以及模型的发展。
1 Attention机制与显著图
1.1 何为Attention机制
所谓Attention机制,便是聚焦于局部信息的机制,比如图像中的某一个图像区域。随着任务的变化,注意力区域往往会发生变化。

面对上面这样的一张图,如果你只是从整体来看,只看到了很多人头,但是你拉近一个一个仔细看就了不得了,都是天才科学家。
图中除了人脸之外的信息其实都是无用的,也做不了什么任务,Attention机制便是要找到这些最有用的信息,可以想见最简单的场景就是从照片中检测人脸了。
1.2 基于Attention的显著目标检测
和注意力机制相伴而生的一个任务便是显著目标检测,即salient object detection。它的输入是一张图,输出是一张概率图,概率越大的地方,代表是图像中重要目标的概率越大,即人眼关注的重点,一个典型的显著图如下:

右图就是左图的显著图,在头部位置概率最大,另外腿部,尾巴也有较大概率,这就是图中真正有用的信息。
显著目标检测需要一个数据集,而这样的数据集的收集便是通过追踪多个实验者的眼球在一定时间内的注意力方向进行平均得到,典型的步骤如下:
(1) 让被测试者观察图。
(2) 用eye tracker记录眼睛的注意力位置。
(3) 对所有测试者的注意力位置使用高斯滤波进行综合。
(4) 结果以0~1的概率进行记录。
于是就能得到下面这样的图,第二行是眼球追踪结果,第三行就是显著目标概率图。

上面讲述的都是空间上的注意力机制,即关注的是不同空间位置,而在CNN结构中,还有不同的特征通道,因此不同特征通道也有类似的原理,下面一起讲述。
2 Attention模型架构
注意力机制的本质就是定位到感兴趣的信息,抑制无用信息,结果通常都是以概率图或者概率特征向量的形式展示,从原理上来说,主要分为空间注意力模型,通道注意力模型,空间和通道混合注意力模型三种,这里不区分soft和hard attention。
2.1 空间注意力模型(spatial attention)
不是图像中所有的区域对任务的贡献都是同样重要的,只有任务相关的区域才是需要关心的,比如分类任务的主体,空间注意力模型就是寻找网络中最重要的部位进行处理。
我们在这里给大家介绍两个具有代表性的模型,第一个就是Google DeepMind提出的STN网络(Spatial Transformer Network[1])。它通过学习输入的形变,从而完成适合任务的预处理操作,是一种基于空间的Attention模型,网络结构如下:
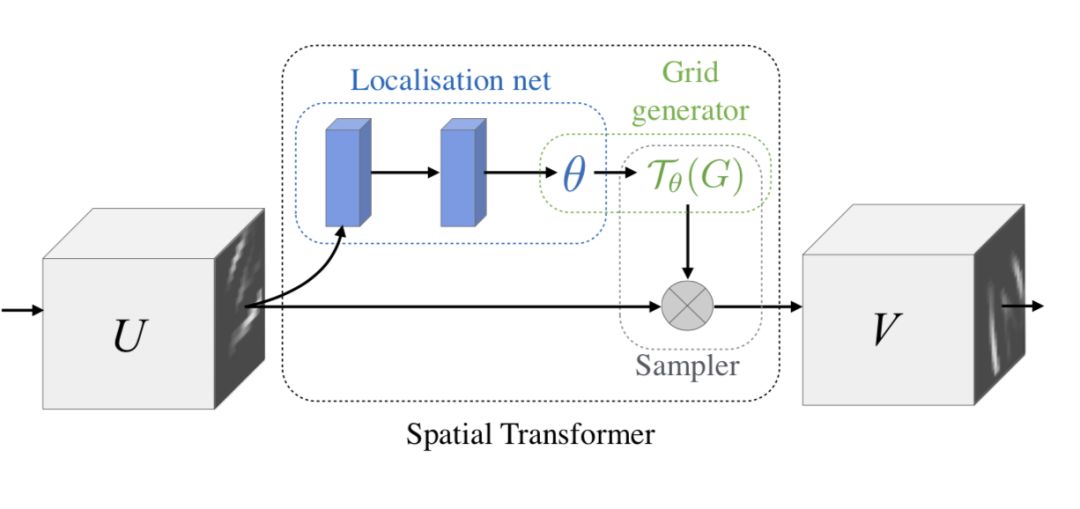
这里的Localization Net用于生成仿射变换系数,输入是C×H×W维的图像,输出是一个空间变换系数,它的大小根据要学习的变换类型而定,如果是仿射变换,则是一个6维向量。
这样的一个网络要完成的效果如下图:

即定位到目标的位置,然后进行旋转等操作,使得输入样本更加容易学习。这是一种一步调整的解决方案,当然还有很多迭代调整的方案,感兴趣可以去有三知识星球星球中阅读。
相比于Spatial Transformer Networks 一步完成目标的定位和仿射变换调整,Dynamic Capacity Networks[2]则采用了两个子网络,分别是低性能的子网络(coarse model)和高性能的子网络(fine model)。低性能的子网络(coarse model)用于对全图进行处理,定位感兴趣区域,如下图中的操作fc。高性能的子网络(fine model)则对感兴趣区域进行精细化处理,如下图的操作ff。两者共同使用,可以获得更低的计算代价和更高的精度。
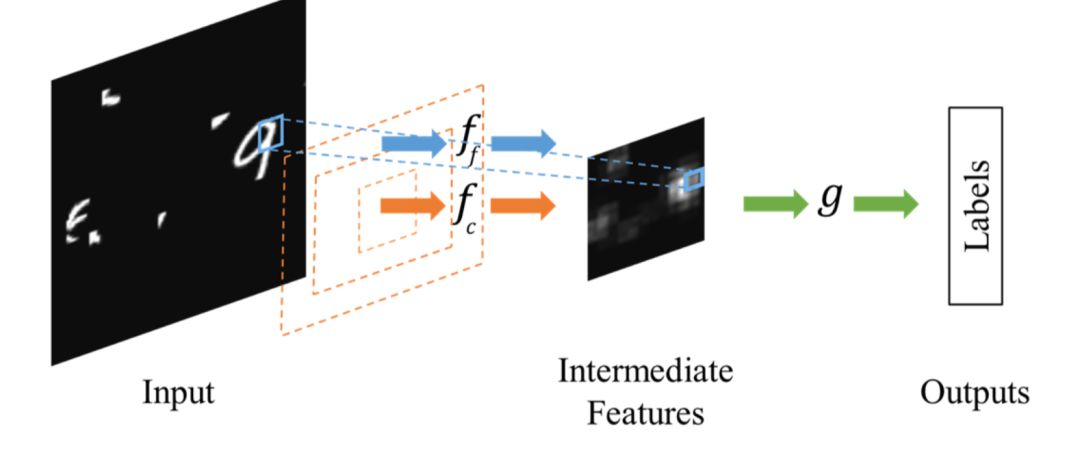
由于在大部分情况下我们感兴趣的区域只是图像中的一小部分,因此空间注意力的本质就是定位目标并进行一些变换或者获取权重。
2.2 通道注意力机制
对于输入2维图像的CNN来说,一个维度是图像的尺度空间,即长宽,另一个维度就是通道,因此基于通道的Attention也是很常用的机制。
SENet(Sequeeze and Excitation Net)[3]是2017届ImageNet分类比赛的冠军网络,本质上是一个基于通道的Attention模型,它通过建模各个特征通道的重要程度,然后针对不同的任务增强或者抑制不同的通道,原理图如下。
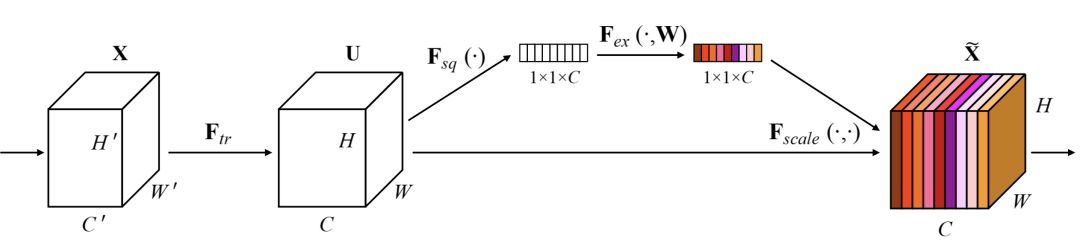
在正常的卷积操作后分出了一个旁路分支,首先进行Squeeze操作(即图中Fsq(·)),它将空间维度进行特征压缩,即每个二维的特征图变成一个实数,相当于具有全局感受野的池化操作,特征通道数不变。
然后是Excitation操作(即图中的Fex(·)),它通过参数w为每个特征通道生成权重,w被学习用来显式地建模特征通道间的相关性。在文章中,使用了一个2层bottleneck结构(先降维再升维)的全连接层+Sigmoid函数来实现。
得到了每一个特征通道的权重之后,就将该权重应用于原来的每个特征通道,基于特定的任务,就可以学习到不同通道的重要性。
将其机制应用于若干基准模型,在增加少量计算量的情况下,获得了更明显的性能提升。作为一种通用的设计思想,它可以被用于任何现有网络,具有较强的实践意义。而后SKNet[4]等方法将这样的通道加权的思想和Inception中的多分支网络结构进行结合,也实现了性能的提升。
通道注意力机制的本质,在于建模了各个特征之间的重要性,对于不同的任务可以根据输入进行特征分配,简单而有效。
2.3 空间和通道注意力机制的融合
前述的Dynamic Capacity Network是从空间维度进行Attention,SENet是从通道维度进行Attention,自然也可以同时使用空间Attention和通道Attention机制。
CBAM(Convolutional Block Attention Module)[5]是其中的代表性网络,结构如下:
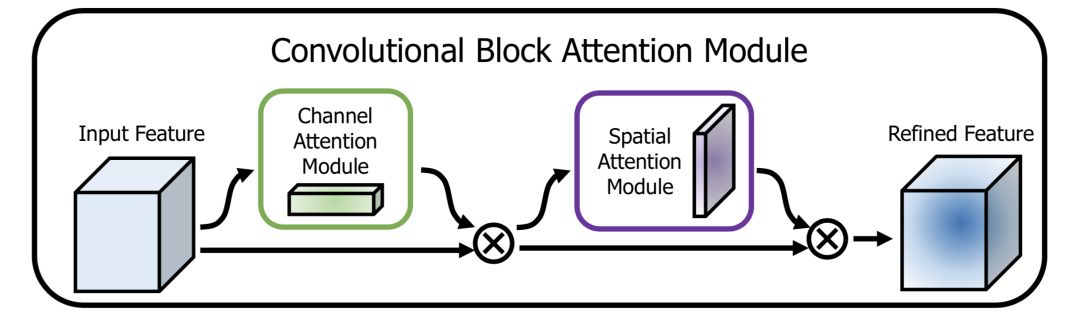
通道方向的Attention建模的是特征的重要性,结构如下:
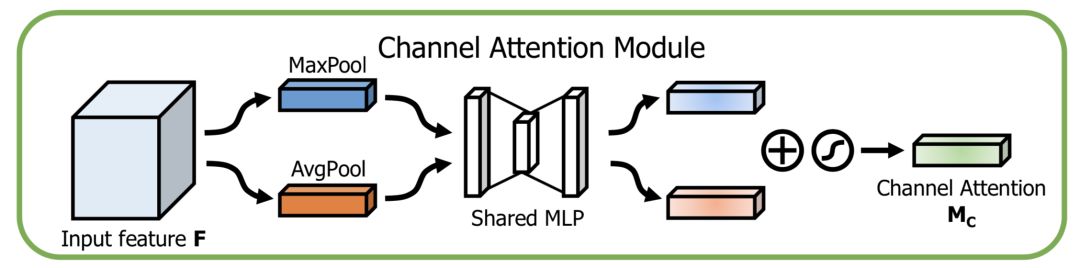
同时使用最大pooling和均值pooling算法,然后经过几个MLP层获得变换结果,最后分别应用于两个通道,使用sigmoid函数得到通道的attention结果。
空间方向的Attention建模的是空间位置的重要性,结构如下:
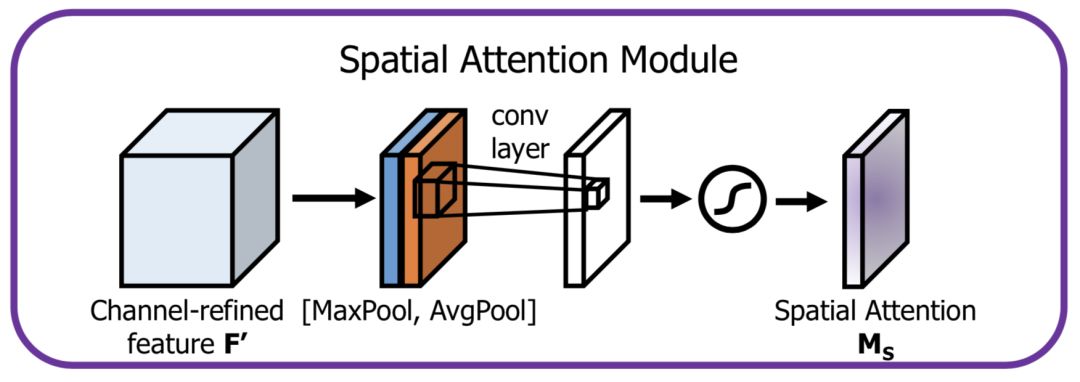
首先将通道本身进行降维,分别获取最大池化和均值池化结果,然后拼接成一个特征图,再使用一个卷积层进行学习。
这两种机制,分别学习了通道的重要性和空间的重要性,还可以很容易地嵌入到任何已知的框架中。
除此之外,还有很多的注意力机制相关的研究,比如残差注意力机制,多尺度注意力机制,递归注意力机制等。
感兴趣的同学可以去我们知识星球中阅读相关的网络结构主题。
【知识星球】超3万字的网络结构解读,学习必备


3 Attention机制典型应用场景
从原理上来说,注意力机制在所有的计算机视觉任务中都能提升模型性能,但是有两类场景尤其受益。
3.1 细粒度分类
关于细粒度分类的基础内容,可以回顾公众号的往期文章。
【图像分类】细粒度图像分类是什么,有什么方法,发展的怎么样
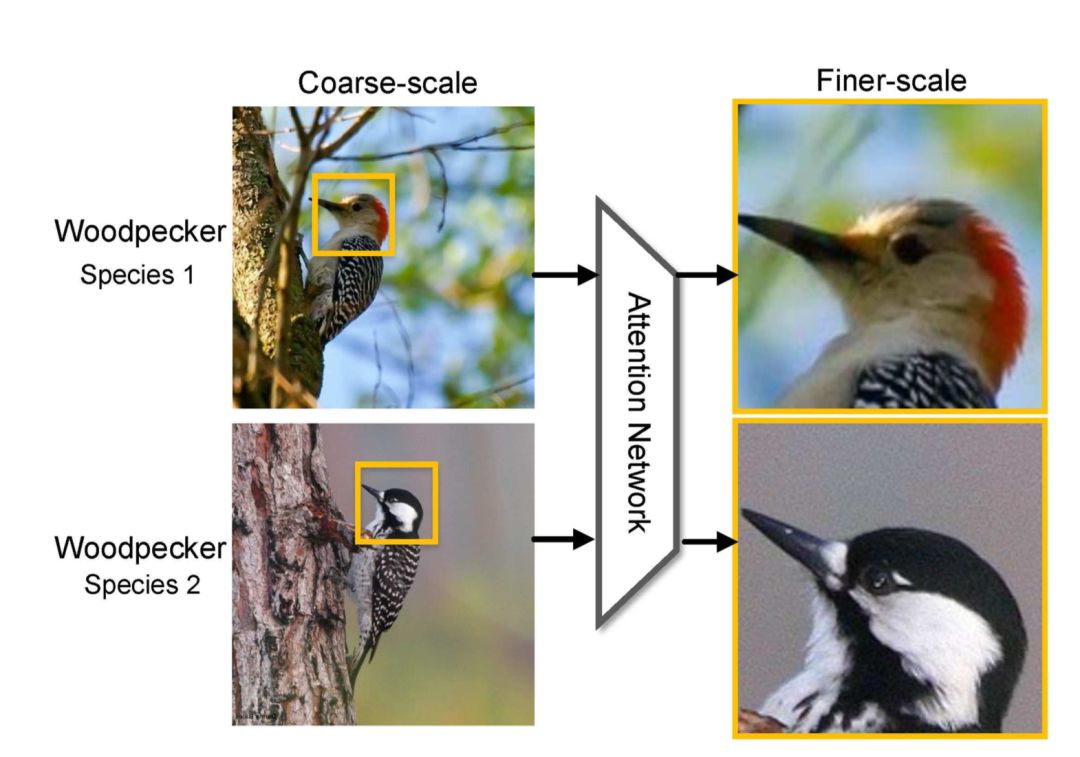
我们知道细粒度分类任务中真正的难题在于如何定位到真正对任务有用的局部区域,如上示意图中的鸟的头部。Attention机制恰巧原理上非常合适,文[1],[6]中都使用了注意力机制,对模型的提升效果很明显。
3.2 显著目标检测/缩略图生成/自动构图
我们又回到了开头,没错,Attention的本质就是重要/显著区域定位,所以在目标检测领域是非常有用的。


上图展示了几个显著目标检测的结果,可以看出对于有显著目标的图,概率图非常聚焦于目标主体,在网络中添加注意力机制模块,可以进一步提升这一类任务的模型。
除此之外,在视频分析,看图说话等任务中也比较重要,相关内容将在有三AI知识星球中每日更新。
参考文献
[1] Jaderberg M, Simonyan K, Zisserman A. Spatial transformer networks[C]//Advances in neural information processing systems. 2015: 2017-2025.
[2] Almahairi A, Ballas N, Cooijmans T, et al. Dynamic capacity networks[C]//International Conference on Machine Learning. 2016: 2549-2558.
[3] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7132-7141.
[4] Li X, Wang W, Hu X, et al. Selective Kernel Networks[J]. 2019.
[5] Woo S, Park J, Lee J Y, et al. Cbam: Convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 3-19.
[6] Fu J, Zheng H, Mei T. Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4438-4446.
总结
注意力机制是一个原理简单而有效的机制,符合人眼的视觉感知原理,在实现上也容易嵌入当前的主流模型架构,是值得采用和学习的技术。
下期预告:深度学习中的无监督学习。
有三AI夏季划

暑期正浓,有三AI夏季划进行中,相比春季划内容更难更全,且更加贴近工业界实战,目标是系统性成长为中级CV算法工程师。这一次的报名周期会持续到国庆,请有需要的同学持续关注,点击图片阅读详细信息。
转载文章请后台联系
侵权必究


往期修行境界
- 【完结】深度学习CV算法工程师从入门到初级面试有多远,大概是25篇文章的距离
- 【完结】优秀的深度学习从业者都有哪些优秀的习惯
- 【完结】给新手的12大深度学习开源框架快速入门项目
- 【完结】总结12大CNN主流模型架构设计思想
- 【知乎直播】千奇百怪的CNN网络架构等你来
- 【AI不惑境】数据压榨有多狠,人工智能就有多成功
- 【AI不惑境】网络深度对深度学习模型性能有什么影响?
- 【AI不惑境】网络的宽度如何影响深度学习模型的性能?
- 【AI不惑境】学习率和batchsize如何影响模型的性能?
- 【AI不惑境】残差网络的前世今生与原理
- 【AI不惑境】移动端高效网络,卷积拆分和分组的精髓
- 【AI不惑境】深度学习中的多尺度模型设计
- 【知识星球】做作业还能赢奖金,传统图像/机器学习/深度学习尽在不言
- 【知识星球】颜值,自拍,美学三大任务简介和数据集下载
- 【知识星球】数据集板块重磅发布,海量数据集介绍与下载
- 【知识星球】猫猫狗狗与深度学习那些事儿
- 【知识星球】超3万字的网络结构解读,学习必备
- 【知识星球】视频分类/行为识别网络和数据集上新
- 【知识星球】3D网络结构解读系列上新
- 【知识星球】动态推理网络结构上新,不是所有的网络都是不变的
- 【知识星球】Attention网络结构上新,聚焦才能赢
- 【知识星球】总有些骨骼轻奇,姿态妖娆的模型结构设计,不知道你知不知道,反正我知道一些