
2022年5月20日,Wave Summit 2022深度学习开发者峰会线上成功举办,飞桨深度学习开源框架2.3版本正式发布。
新版本框架在深度定制开发能力、全流程的自动化水平等方面有大幅升级,涉及开发、训练、推理部署和云上飞桨各环节。API体系更加丰富,更便捷支持包括AI科学计算在内各领域模型开发;针对高阶开发者深度定制开发需求,飞桨框架2.3版本推出高复用性算子库、高扩展性参数服务器架构,进一步降低框架深度定制开发的成本;推出业内首个全流程自动调优方案,大幅提升性能调优的自动化水平;降低模型压缩技术的应用门槛,推出业内首个开源的自动化压缩功能;深度优化端边云全场景推理引擎,支持开发者取得最佳的部署性能。同时,针对大模型技术发展和产业应用需求,飞桨框架2.3版本的大模型训练和推理能力实现全面升级。此外,为了更好地跟云计算对接,本次升级正式推出“云上飞桨”的能力,包括业内首个异构多云自适应分布式训练架构以及云上部署编排工具PaddleCloud。

飞桨框架2.3版本共包含3200+个commits,共有210+个贡献者参与开发,下面让我们看看该版本的重点更新:
- 更加丰富的API体系
- 高复用性算子库PHI
- 高扩展性参数服务器
- 全流程硬件感知的性能自动调优
- 自动化压缩和推理引擎性能优化
- 大模型训练和推理能力全面升级
- 异构多云自适应分布式训练架构
1 更加丰富的API体系
支持各领域模型开发
相比2.2版本,2.3版本新增100多个API,覆盖概率分布、自动微分、稀疏张量、线性代数、视觉计算、框架性能分析、硬件设备管理等方面。
- 概率分布类API扩充到2.3版本的25个,新增6个基础分布、13个分布变换及2个KL散度API。
- 新增4个自动微分API:Jacobian、Hessian、jvp、vjp并应用到赛桨PaddleScience中,同时支持lazy模式的计算,能够在复杂偏微分方程组中避免计算无用导数项,提升计算性能。
- 新增11个稀疏张量API,支持创建 COO、CRS格式的Sparse Tensor,并能与Tensor互相转换,已经应用到3D检测(支持自动驾驶),图神经网络和NLP模型中。
- 新增2个拟牛顿法二阶优化API:minimize_bfgs和minimize_lbfgs,已应用到赛桨PaddleScience中,加快了模型收敛速度。
2 高复用性算子库PHI
降低算子开发门槛
算子库是深度学习框架极为重要的基础组成部分,也是硬件和框架适配的重要桥梁,但算子开发对很多开发者而言挑战比较大。飞桨框架2.3版本打造了高复用性的算子库PHI,通过函数式接口为高阶开发者提供了更简单的算子开发方式,有效降低算子开发门槛,提升开发效率,并且能够大幅降低芯片对飞桨框架的算子适配成本。下面具体看一下PHI算子库的三个特点:
- 函数式算子接口,可以通过函数调用的方式复用基础算子来进行更复杂的组合算子开发。例如,通过对矩阵乘、加减乘除法等基础算子函数式接口的调用,很容易实现一个FC或者SGD算子,高效支撑自定义算子开发需求。以非常复杂的Einsum算子为例,通过利用PHI算子库,这类复杂算子的开发有低成本的显著优势。
- 插件式算子管理机制,避免和框架代码耦合,支持低成本地复用硬件加速库的能力。
- 提供Primitive的算子内核开发接口,实现不同芯片之间的算子内核开发代码的复用,提升算子内核的开发效率。例如,飞桨在GPU和XPU上,已实现了大量基于Primitive接口的算子内核的复用,大幅降低了硬件算子适配的成本。

3 高扩展性通用异构参数服务器
提升二次开发体验
参数服务器架构在搜索推荐系统应用非常广泛。飞桨框架在2.0版本推出了业内首个通用异构参数服务器架构,在2.3版本中我们进一步提升其扩展性,主要是将其中的基础模块通用化,提升二次开发体验,高效支持产业应用中广泛的定制开发需求。
以新增支持昆仑芯XPU的参数服务器为例,在复用通用模块的基础上,只需增加三个硬件相关的定制模块,使得开发量从原来的万行减少至千行。再比如,扩展业务场景至GPU图神经网络训练,仅需要在存储模块中添加图采样策略即可开发完成GPU三级存储图检索引擎,支持GPU图分布式训练。
持平专家级手工优化
目前各个框架都在性能方面做了很多优化,但对开发者而言,要想充分发挥框架的极致性能,往往需要对框架以及硬件特性非常熟悉,通过调整各种配置才能实现,这对开发者的要求非常高,所以性能调优也常常成为开发者苦恼的问题。针对这一痛点,飞桨框架2.3版本大幅提升性能调优的自动化水平,推出的业内首个全流程自动调优方案,使得开发者更便捷获得框架最优性能体验。
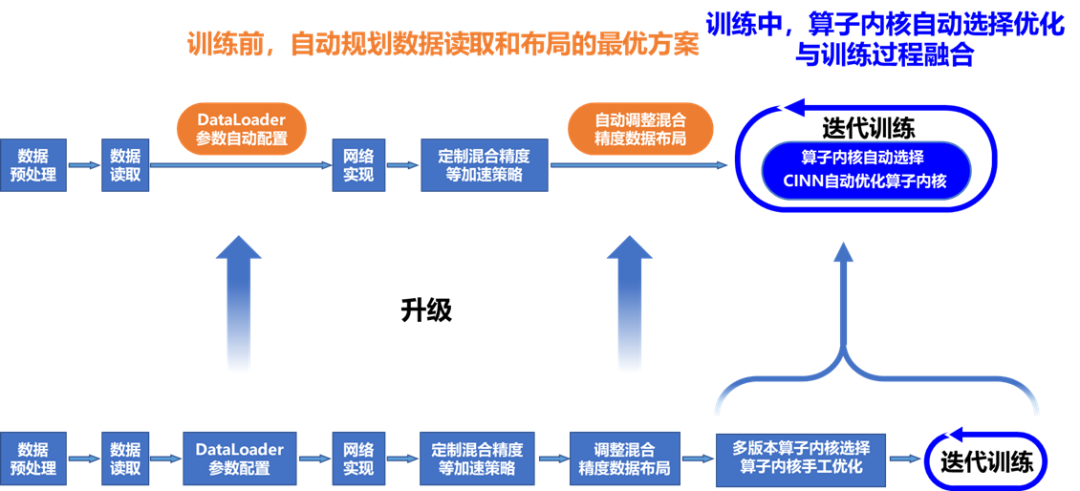
训练前
- 针对不同硬件环境下默认的DataLoader参数配置无法发挥硬件最优性能的问题,飞桨实现了DataLoader参数自动搜索功能,结合硬件特性达到最优性能配置;
- 混合精度训练等硬件相关的加速策略,往往与模型代码耦合。飞桨本次升级后,开发者无需修改模型代码,框架自动调整数据布局等设置,即可充分发挥硬件加速效果。
训练中
- 不同算子内核版本,针对不同的硬件加速库各有优势,飞桨利用CostModel预估与硬件实测相结合的方法,在运行时自动选择不同条件下的最优算子内核,无需手工配置;
- 同时借助飞桨神经网络编译器CINN的auto tune功能,实现在训练迭代过程进行子图、算子编译优化,自适应硬件特性,减少调优等待时间,更快达到最优性能。
- 通过实验对比分析,飞桨框架自动调优后的训练性能,可以达到与专家级手工配置优化持平或超越的效果,而且在不少模型上相对飞桨或其他框架的默认配置都有较大幅度的性能提升。

5 自动化压缩和推理引擎深度性能优化
高效支撑全场景部署落地
在产业落地的过程中,由于实际场景在硬件设备、推理性能等方面的约束,常常需要模型压缩的技术。然而模型压缩要想做到模型精度和推理性能的平衡,非常有挑战。以往开发者需要考虑模型训练、硬件环境等复杂因素,凭借实验从大量的压缩策略中选择适合的策略。
为了降低模型压缩技术的应用门槛,飞桨推出了业内首个开源的自动化压缩功能,采用自动硬件感知技术,匹配最优压缩方案,并通过蒸馏微调解除对模型原训练代码的依赖,大大简化了开发工作。经测试,自动化压缩方案的代码量可减少50%以上,大幅降低了开发成本,并且压缩精度与推理速度仍能与手工压缩水平持平。

同时,飞桨推理引擎也在持续进行深度的性能优化,支持开发者取得最佳的部署性能。本次升级,飞桨在数据处理、计算图优化、执行调度、软硬件融合的内核调优等方面进一步进行深度优化,推理性能进一步提升。以端侧为例,在ARM CPU上,我们支持了稀疏计算功能,在高通865手机,FP32精度单线程下,稀疏度75%,相对稠密模型性能有高达30%提升,并且精度损失<1%。在边缘、云也都实现了深度优化,实现了端、边、云多平台推理性能的全面提升。
6 大模型训练和推理能力全面升级
提供训推一体全流程方案
针对MoE模型的海量稀疏参数,飞桨采用了包括HBM显存/MEM内存/AEP/SSD等在内的通用多级存储模式,实现36机即可训练十万亿模型,并采用2D预取调度和参数融合提高异构存储效率。同时针对All-to-All通信压力,研发了硬件拓扑感知层次通信,通信效率提升20%。针对MoE训练中的负载不均衡情况,提出弹性训练通过增删节点平衡负载,整体效率提升18%。此外,针对MoE大模型推理,飞桨提出Ring Memory Offloading策略,有效解决单节点大模型训练推理存储问题,减少显存碎片。
更多详情请见:
SE-MoE: A Scalable and Efficient Mixture-of-Experts Distributed Training and Inference System(https://arxiv.org/abs/2205.10034).
针对生物计算蛋白质结构分析模型存在多分支特征计算、中间计算结果较大、参数量小、参数个数较多、小算子较多等特点,飞桨提出了分支并行分布式策略提高并行效率,数千个参数、梯度、优化器变量使用张量融合策略和BF16通信策略以提高通信及参数更新效率,小算子使用算子融合策略提高计算效率等;此外,进一步支持了GPU/DCU等多种硬件环境下端到端的高扩展分布式训练。
飞桨整体推出了针对大模型的压缩、推理、服务化全流程部署方案。该方案通过面向大模型的精度无损模型压缩技术、自适应分布式推理技术,可自动感知硬件特性,完成模型压缩、自动切分和混合并行推理计算,可比模型测试达到领先性能。并且,整体方案通用且可扩展,能广泛支持不同种类的模型结构高速推理,目前已支撑了如自然语言理解、对话、跨模态生成等大模型的实时在线应用。
7 异构多云自适应分布式训练
实现算力和模型共享
针对多算力中心数据、算力共享面临的安全、效率挑战,飞桨推出了业内首个异构多云自适应分布式训练架构,支持云际环境下的异构硬件联合训练,实现算力共享(多个算力中心互联训练)或知识共享(云化方式利用各自的大模型)。该架构融合了混合并行训练、通信压缩、异构通信、安全加密等技术,并已在“鹏城云脑II+百度百舸”下完成多个模型的验证。
通过算力共享方式成功训练了多语言知识融合的ERNIE模型,可以做到精度无损和性能基本无损。在该场景下,各算力中心会收到全量训练数据和自适应切分的不同模型网络层,并采用集合通信、模型并行等技术训练各网络层,参数服务器架构将中间层输出与梯度信息进行通信压缩和安全加密后,传递至其它算力中心,完成联合训练。多算力中心算力联合训练,将是一种更灵活的大模型训练方式。
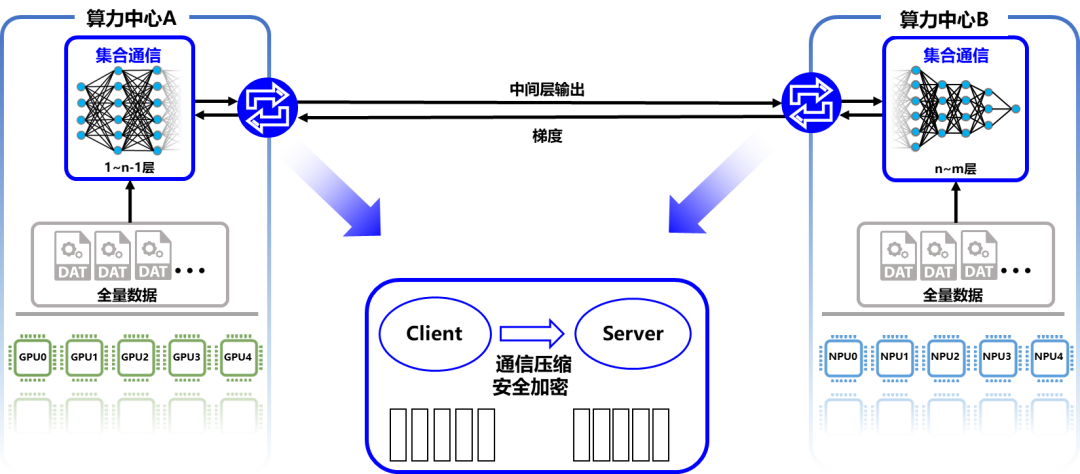
在知识共享场景下,以翻译模型为例,算力中心C会向A和B发送模型请求。A和B上的单语言模型依据请求上的数据计算出中间层输出结果,并同样利用参数服务器架构发送给算力中心C。C使用中间层输出结果完成训练,这可看成是知识共享的训练。鹏城云脑II和百度百舸以这种知识共享方式成功训练了英语-西班牙语翻译模型。预训练大模型也可用于其它模型高质量生产。

更多详情请见:
Nebula-I: A General Framework for Collaboratively Training Deep Learning Models on Low-Bandwidth Cloud Clusters(https://arxiv.org/abs/2205.09470).
7 云上飞桨编排部署工具PaddleCloud
支持极简安装与多模型编排
为了让开发者更便捷地使用云上飞桨的功能,飞桨推出了云上部署编排工具PaddleCloud。仅需简单的两行配置,就可以在各个云环境上定制专属的完整的飞桨开发部署环境。PaddleCloud完成与主流云上存储与网络的适配,并通过在环境内部自适应的对接各类异构硬件。云上环境会随飞桨版本自动更新,用户能使用PaddleCloud快速体验飞桨新版功能。
此外,PaddleCloud基于飞桨K8s Operator和DAG实现多开发套件、多模型之间的灵活快速编排。内置经典行业案例模板,可轻松完成云上一键安装,及多模型系统串联,实现复杂AI应用高效落地。

欢迎大家下载体验飞桨深度学习开源框架2.3.0版本!
相关阅读
- 百度CTO王海峰:飞桨助力普惠AI,赋能千行百业,惠及千家万户
- 百度吴甜提出大模型落地关键路径 业内首发行业大模型
