
导语
机器学习领域最重要的两个问题是机器学习模型的生产(模型训练)和机器学习模型的部署(模型推理)。其中,模型的部署关注两个方面:
- 模型推理的性能问题:目标是通过计算图层面的优化,算子层面的优化等方式,在保证模型效果的前提之下,提升模型计算(模型推理)的性能。
- 模型部署的工程问题:主要着眼于对模型部署过程中的整个模型的生命周期进行管理,降低模型部署的工程量。
目前常见的推理优化框架有侧重于推理性能提升的 TensorRT、NVIDIA 基于 TensorRT 的 Triton、Tensorflow 社区的 tensorflow serving、微软的 ONNX Runtime 等;有侧重于降低模型部署的工程量的 Seldon、KFServing 等。
前者通常需要将模型转化为某一特定格式,但通常需要围绕模型服务自行实现模型自动发布,模型灰度发布,模型版本管理,服务监控,线上流量复制等一系列功能,工程量较大。后者提供了模型部署过程中的一整套功能,可有效降低模型部署落地时的工程量,但是性能一般不如前者。
腾讯云自研的 TACO Infer 可以大幅提升推理性能 1.4~5.2 倍,并解决模型部署的问题,无侵入业务代码,仅数行代码改动即可实现业务升级。
什么是 TACO Infer
TACO Infer 是一款轻量易用、无缝集成已有深度学习框架的 AI 推理加速软件,帮助客户简洁、无侵入业务代码地一键式提升推理性能,无缝适配多种服务框架。
TACO Infer 有什么厉害之处
市面上已经有各种各样的推理优化框架,腾讯云为什么还要推出自研推理加速软件呢?其实 TACO Infer 要解决的,主要就是模型前端框架、硬件后端设备、软件版本的组合爆炸带来的工程调优复杂度问题。
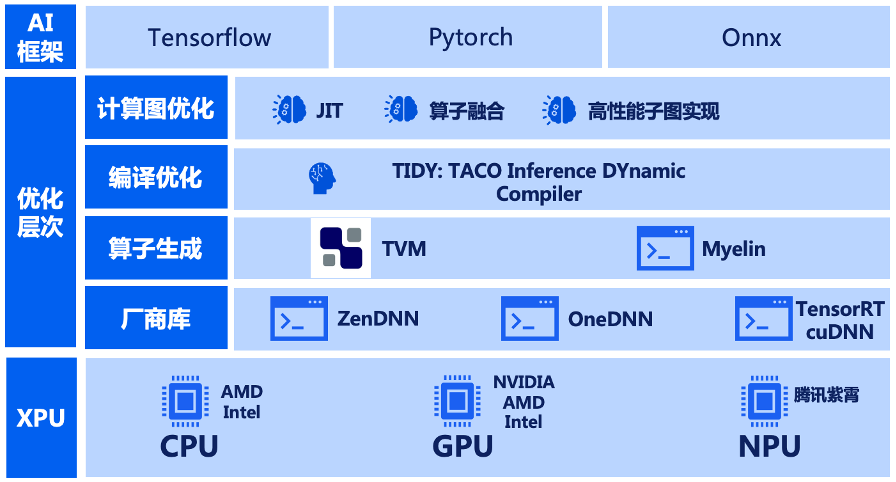
首先,在软硬件兼容性上,TACO Infer 支持 TensorFlow、PyTorch 等多种模型前端框架, 兼容 CPU、GPU、NPU 等多种加速芯片,且可无缝嵌入 TF Serving、TensorRT、Triton 等多种服务框架。
其次,在使用体验上,TACO Infer 提供统一的优化接口,无论用户使用 CPU、GPU、NPU 哪种后端设备,也无论 TensorFlow、PyTorch 或者 ONNX 哪种模型框架及版本,接口均保持一致。该接口接受未优化模型输入,输出优化后的模型。优化前后模型格式保持不变,对用户透明无感,不改变业务部署方式。
最后,在性能提升上,TACO Infer 强大的可扩展性设计使得无论是开源社区的前沿加速方案还是硬件厂商的定制加速算子,都可集成在 TACO Infer 中,一站式整合多种开源优化方案,获得 1.4~5.2 倍的推理加速。
技术上如何实现
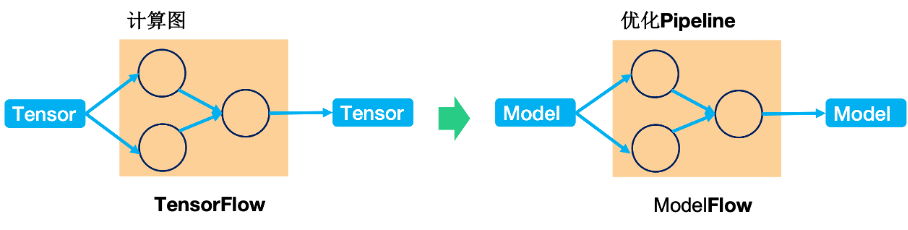
独创的 ModelFlow 设计理念
目前,主流深度学习框架采用“TensorFlow”的设计理念,即以 Tensor 作为核心数据在计算图中流动(Flow)的方式完成计算过程。受此启发,我们独创了“ModelFlow”的设计理念,即以 Model 作为核心数据,在优化 Pipeline 中流动(Flow)的方式完成模型优化过程。
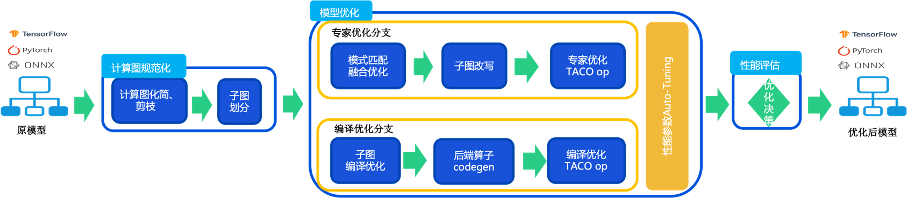
丰富的模型优化策略
TACO-Infer 支持以专家优化和编译优化两条优化路径对深度学习模型分别进行优化。
在专家优化路径,模型经过精心设计的跨框架复用的计算图优化组件进行计算图匹配,算子融合之后,被匹配的算子会被替换为基于专家优化库进行加速的算子实现。
而在编译优化路径,模型经过编译优化后端进行子图编译优化,高性能算子代码生成之后,被匹配的算子会被替换为经过编译技术加速的算子实现。同时,在模型优化过程中,TACO-Infer 会对相关性能参数进行自动搜索调优。最后,在性能评估阶段,TACO-Infer 会实测模型,自动选择最佳优化路径,保证获得最佳的模型优化性能。
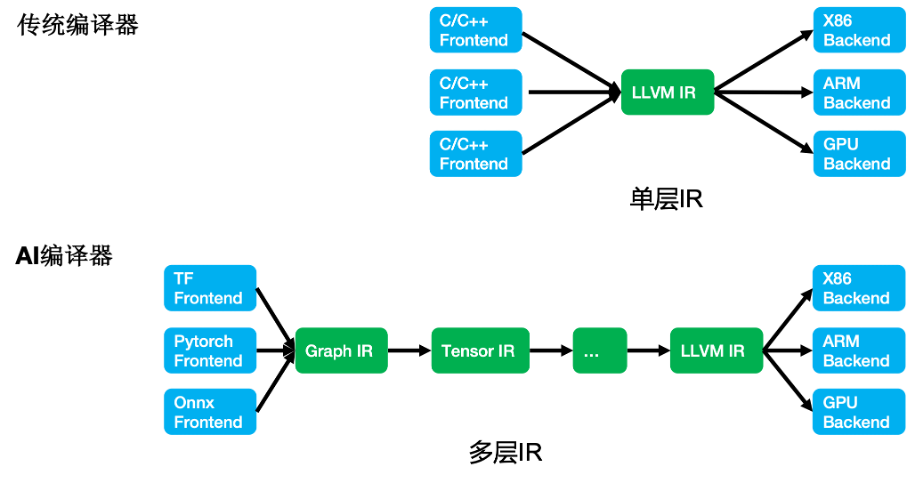
自研的 AI 编译优化后端
在传统编译器实现中,通常采用单层 IR 设计,如 LLVM。而 AI 模型具有更丰富的语义,更复杂的优化层次。单层 IR 设计不足以支撑。因此,AI 编译器通常采用多层 IR(MLIR) 设计,以支持不同层次的优化。
TIDY(TACO Inference DYnamic shape compiler) 是我们自研的基于 MLIR 实现的 AI 编译优化后端。TIDY 可以支持多种深度学习框架(TF/Pytorch),支持多种异构硬件(GPU/CPU),支持动态 shape。同时还可以灵活集成第三方专家优化库,提升计算密集型算子的性能,与编译优化技术一起提升模型整体性能。
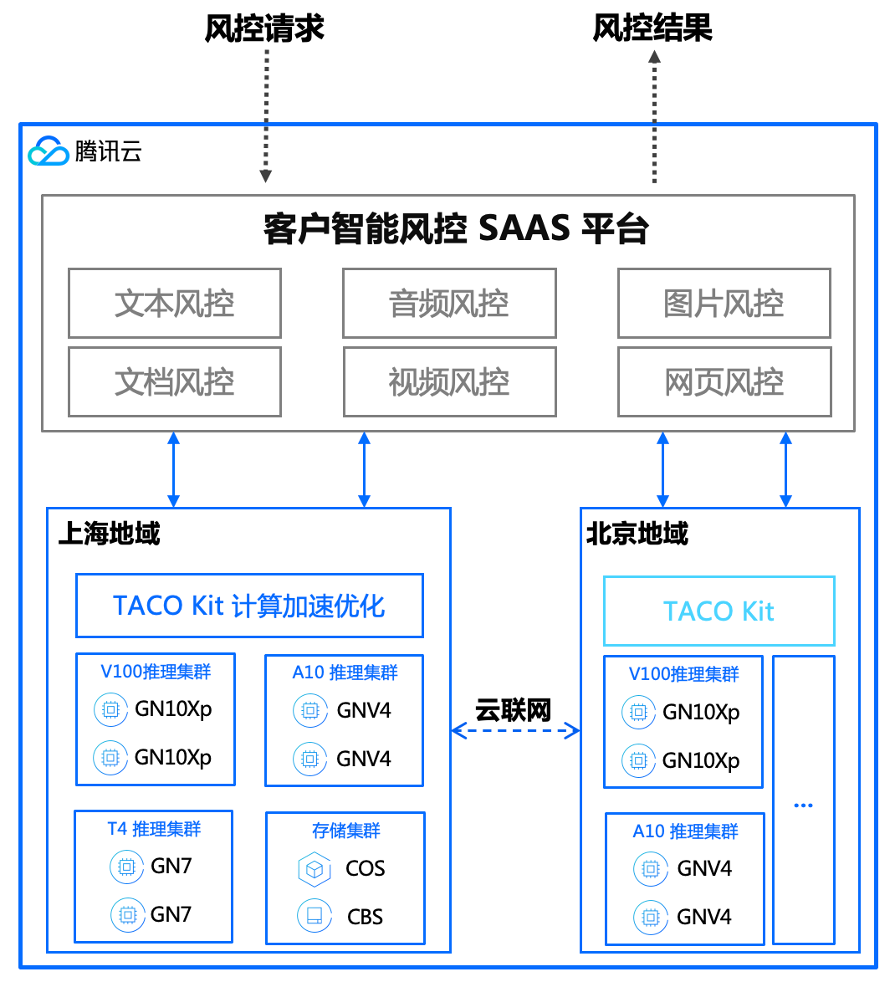
TACO Infer 助力数美自动语音识别 QPS 3倍提升
在实际业务中,TACO Infer 也助力了多个客户推理业务效能提升,在提高推理性能同时,节省算力成本。
作为腾讯云的战略合作伙伴,数美科技是一家在线业务风控解决方案提供商,提供支持文本、图片、音频、视频等多种形式风险内容过滤的内容安全产品和解决营销欺诈、交易风控、数据盗爬、欺诈广告等业务风险问题的业务安全产品。产品形态主要是 SaaS 服务,注重性能延迟和业务并发能力。

数美在进行自动语音识别推理吞吐优化中发现,由于音频数据特征预处理负载较重,带来的 IO、特征计算耗时增加等问题尤为突出,此外未算子化的特征计算需要额外的工程代码实现,增加了运维和适配不同硬件的难度。
针对这样的业务痛点,腾讯云专家团队与数美科技业务伙伴进行了深入交流和沟通,协同制定了优化方案,针对业务场景,在计算图、AI 编译优化、算子生成做了深度优化。
由于客户性能主要受特征前处理效率和模型前向推理性能影响,TACO 通过将音频特征计算算子化,从而将原先 CPU 亲和的特征计算合并到 ASR 模型里,并且基于自研 AI 编译器进一步实现子图编译优化增强和计算图预处理,消除不必要分支,精简推理模型。
数美使用 TACO Infer 优化后模型推理时延缩短70%,QPS 优化三倍,降低了业务部署成本,在同类竞品中获得了更大的性能和成本优势。且 TACO Infer 适配了多种框架,不改变用户模型格式,从而实现了客户业务的无感迁移。
总结
腾讯云秉承为客户解决实际业务难题,创造增量价值的初衷,不仅要让客户在云上业务可靠运行,还要辅助客户真正发挥出云服务器的算力性价比优势。我们希望通过 TACO Train、TACO Infer、qGPU 共享技术等软件附加值产品,助力客户提升算力效率,降低业务成本,形成可持续发展的长期合作模式。
未来,TACO Infer 会不断在软硬件兼容性和性能提升上有提升,包括融合硬件厂商优化算子、自研 AI 编译技术升级等。相信随着 TACO Infer 的不断发展,在保持易用性的基础上,使用 TACO Infer 的性能收益将会越来越高,欢迎加入 TACO Infer 交流群,更多新特性敬请期待。

