前言
应用状态简单理解就是一个程序运行所需要的数据。比如一个程序的运行需要一些配置,可以通过修改配置来改变程序的运行结果,这个配置就是该程序的一个状态。再比如一个程序需要持久化一些数据到数据库,文件或者其他形式的存储中,这个持久化就是该程序的一个状态。从这点来说,基本上所有应用都是有状态。程序的运行离不开数据,数据不对或缺失容易造成程序运行的崩溃。
在现代微服务架构中,要确保服务的弹性,要将服务设计成无状态化的,这里的无状态化并不是说这个服务没有状态了,只是说该服务的实例可以从某些地方取回执行所需要的应用状态。换句话说,我们把一个应用上到k8s上的过程其实就是一个去状态化的过程,在这个过程中的解决手段就是将应用的执行和执行所需的数据进行分离,让应用无状态化。
一个应用常见的状态大致上有5大类:
- 持久化状态
- 配置状态
- 集群状态(拓扑状态)
- 会话状态
- 连接状态
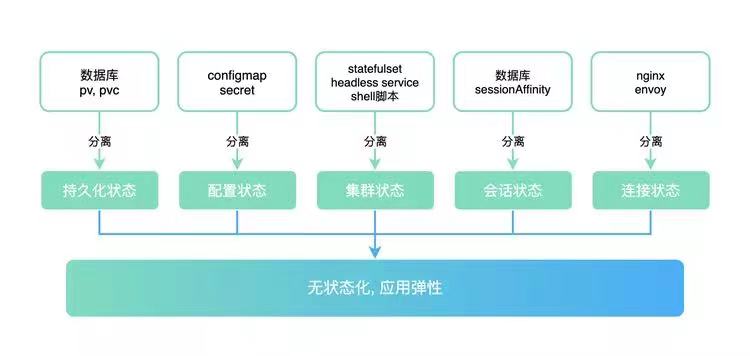
接下来先给大家介绍下在k8s中解决以上状态的一些手段。
1.持久化状态
就像上文提到的,将需要持久化的数据存到数据库中,是分离持久化状态的一个最常见的方式。大部分的简单应用通过这个方式就可以做到无状态化。那数据库呢?数据库需要将数据文件存在磁盘上,如果pod发生了漂移,数据库执行程序和数据文件之间的关系就丢失了。
所以数据库的分离持久化状态需要做到两件事情:
(1)数据文件可以存下来
(2)数据文件和执行程序之间关系可以维持住
第一件事情可以通过将数据文件直接存在某几个固定的node节点上,声明localpv。
第二件事则是需要pod和pv进行绑定,在pod上声明pvc,使用storageclass绑定pv和pvc。这里还需要保证的是当pod发生漂移了还能找到对应的pvc,可以使用statefulset,这样pod-0绑定的就是pvc-0。
数据文件持久化了,执行程序和数据文件的关系也维持住了。要弹性增加副本,只要增加pod和localpv就行, 创建pv也可以交给provisioner来自动创建。当然数据库要能在k8s上弹性扩缩容还要分离集群状态。
2.配置状态
我们可以通过修改配置来改变程序的运行状态,但是如果配置文件在容器中,pod一旦发生了漂移,之前修改的配置都不再生效,程序的执行数据有问题就可能造成程序的崩溃,比如数据库的连接配置。要分离配置状态则需要配置文件独立定义,并在容器启动后覆盖容器内的配置文件。
在k8s中分离配置状态的常用方式就是使用configmap,如果存在需要加密的数据则使用secret。
3.集群状态(拓扑状态)
很多分布式应用,多个实例之间是存在依赖关系的,比如主从关系,主备关系。要分离集群状态,比如mysql:
(1)启动的pod可以知道自己是master还是slave
(2)pod可以有唯一访问标识,可以通过这个唯一访问标识访问特定的pod
第一件事被statefulset管理的pod都会有一个顺序编号,那就可以通过脚本来根据编号规定这个pod是master还是slave。
第二件事通过headless service,会产生和pod名相关的dns,这样也就有了唯一访问标识。
这就给我们提供了充分的条件,去编写初始化脚本初始化集群。
4.会话状态
某些应用需要会话数据维持用户登录状态。如果会话数据过期或者丢失需要再次登录。要分离会话状态有两种方式:
(1)将会话数据保存到分布式缓存中或者数据库中。
(2)通过粘滞会话,根据客户端ip做会话保持,将请求路由到固定pod上。
第一种方式其实就是通过编写程序将会话状态变成了持久化状态,通过分离持久化状态来做到去状态化,这也是现在大多数流行的应用中的做法。
第二种方式如果会话只需要保持一小段时间,并且不是什么大并发的应用,那可以通过service的sessionAffinity将某个客户端的请求路由到固定的pod上,这种方式会有一个会话保持时间,超时则需要用户再次登录。当然在超时期间pod就发生了漂移也会需要用户再次登录。
5.连接状态
一些服务需要通过长链接与其他服务进行交互,比如通过grpc协议。如果仅仅只是通过service负载后端的pods,那就会存在一个问题,客户端和其中一个pod建立连接后,只要这个连接没有断开,客户端就不会再和其他pod建立连接,那么其实后端pod的横向扩展也就失去了意义。要分离连接状态,就需要对长链接进行负载均衡,基本有两种方式:
(1)利用nginx的长连接负载均衡能力来维持这些长连接。
(2)利用envoy实现客户端的长连接负载均衡。
第一种方式可以通过ingress, ingress对grpc直接有支持,声明backend-protocol为grpc,会利用nginx的长连接负载均衡能力来达到分离连接状态的目的;
第二种方式则是将发出请求拦截到sidecar envoy,利用envoy的能力在客户端做L7层负载均衡。
小结
大部分的应用都有状态,我们将应用上k8s的过程就是在对应用去状态化的过程,只是有的应用可以通过简单的将数据持久化到数据库中做到无状态化。而有的应用则要考虑分离更多更复杂的状态,来使应用做到弹性。上述的5种状态是日常中比较常见的,不管怎么样,就是通过种种手段来将程序执行所需的数据分离出来。
看到的一些问题
通过上面的描述大家应该可以看出来,有那么一部分应用跑到k8s上其实并不是一件容易的事,需要达到以下要求:
(1)对应用要有足够的了解,可以分析出应用现有状态;
(2)熟悉k8s,根据应用现有状态找到分离状态的解决方案,如果现有对象不够满足,要有开发扩展k8s的能力;
(3)有脚本编写能力,比如在分离集群状态的时候;
(4)要了解例如nginx,istio,k8s网络,存储等等的机制来协助分离状态。
所以要将应用跑到k8s是需要非常综合的一个能力,是需要多种角色的人员相互配合来实现“上云”。
现在社区中有很多operator,描述一些具有复杂状态的应用。对于一些单一的应用像prometheus, mysql等确实很方便,但是在企业中,作为产品的依赖,这种应用往往很多,如果每个都用单独operator 来部署确实会带来很大的学习和维护成本,尤其在toB交付领域更是明显。
对于一线交付运维人员更是如此,提供给它们的交付物中可以修改的更应该是一个通用的配置文件,他们修改通用的配置,可以在一定程度上控制交付结果。
一些实践尝试
核心想法就是:
- 既然应用上k8s就是去状态化的过程,那分离这些状态产生的k8s对象就按照步骤一步步加入就好了。
- 在应用可以部署到k8s上后,这个yaml作为一个模版,与其他的配置文件作个映射。
以zookeeper举个例子,zookeeper要分离集群状态,存储状态。并在部署成功后可以对client提供服务。
apiVersion: dtstack.com/v1beta1kind: WorkLoadmetadata: name: dtbase-zookeeper namespace: dtstack-prospec: workloadpatrs: - baseworkload: name: leader parameters: spec: replicas: 3 serviceName: dtbase-zookeeper-leader-zk-hs template: spec: imagePullSecrets: - name: dtstack type: statefulset steps: - action: bound name: zkdata object: spec: accessModes: - ReadWriteOnce resources: requests: storage: 100G storageClassName: dtbase-prd-zk type: pvc - action: bound name: zk-sts object: command: - sh - -c - /zookeeper/bin/dtstack/start-zookeeper-k8s.sh env: - name: ZK_SERVERS value: "3" - name: ZOO_INIT_LIMIT value: "10" - name: ZOO_MAX_CLIENT_CNXNS value: "200" image: 172.16.23.54/dtstack/zookeeper:3.4.14_02 ... ports: - containerPort: 2888 name: server - containerPort: 2181 name: client - containerPort: 3888 name: leader-election ... volumeMounts: - mountPath: /data name: zkdata subPath: zk_data - mountPath: /datalog name: zkdata subPath: zk_datalog - mountPath: /logs name: zkdata subPath: zk_logs type: container - action: createorupdate name: zk-hs object: spec: clusterIP: None ports: - name: server port: 2888 - name: leader-election port: 3888 - name: jmx-prom-agent port: 9505 selector: app: dtbase-zookeeper-leader type: service - action: createorupdate name: zk-cs object: spec: ports: - name: client port: 2181 targetPort: 2181 selector: app: dtbase-zookeeper-leader type: service...上面给出了部分重要信息。
(1)分离存储状态,采用pvc来声明,而pv和storageclass其实更多应该是由k8s管理平台提供,所以这里只声明需要多少大的存储空间。
(2)分离集群状态, 这里采用了statefulset + headless 给每个zookeeper的每个pod生成唯一可访问标识,在start-zookeeper-k8s.sh 中根据这个标识将zookeeper各个节点的dns填入到zoo.cfg中,并生成myid文件。
通过service提供对客户端提供服务访问。
其实上面还有一个状态是没有分离的,就是写入zoo.cfg的配置,按照上面的配置,当要增加节点的时候,只有卸载重新安装zookeeper才行,好在存储状态已经分离,所以数据都会继续存在。
上面的定义还可以进一步抽象,将状态抽象出来,通过添加状态,来达到更容易让人理解的地步,毕竟距离应用最近的人是最了解应用的,比如mysql,zookeeper的维护人员,产品应用的开发人员。
在上面的workload可以进行部署后,剩下的就是与一个面向交付的配置文件作映射,比如:
params: - key: image ref: spec.workloadpatrs.0.steps.3.object.image - key: resourceRequest.cpu ref: spec.workloadpatrs.0.steps.3.object.resources.requests.cpu - key: resourceLimit.cpu ref: spec.workloadpatrs.0.steps.3.object.resources.limits.cpu - key: storageClass ref: spec.workloadpatrs.0.steps.1.object.spec.storageClassName交付人员面向的交付配置是一个更容易理解,也是从workload中抽象出来的比较容易出现修改的一些配置,通过修改这些配置来控制交付结果。