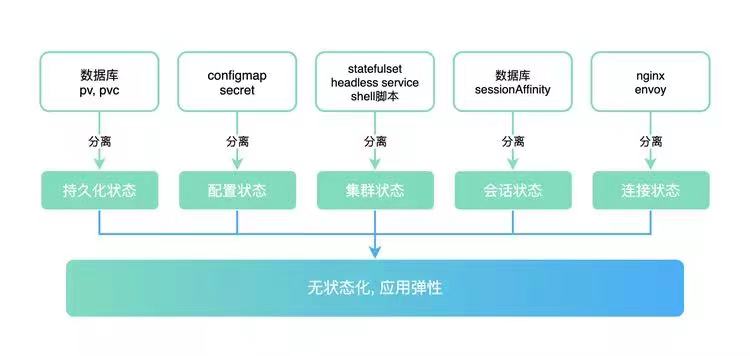
数智洞见 | 云原生中有状态应用容器化实践,如何去状态化?
应用状态简单理解就是一个程序运行所需要的数据。比如一个程序的运行需要一些配置,可以通过修改配置来改变程序的运行结果,这个配置就是该程序的一个状态。再比如一个程序需要持久化一些数据到数据库,文件或者其他形式的存储中,这个持久化就是该程序的一个状态。从这点来说,基本上所有应用都是有状态。程序的运行离不开数据,数据不对或缺失容易造成程序运行的崩溃。
腾讯云消息队列TDMQ RabbitMQ 版开启公测,文末有惊喜!
导语 1月6日,TDMQ RabbitMQ 版正式公测!TDMQ RabbitMQ 版是TDMQ系列产品中的一款子产品,是一款分布式高可用的消息队列服务,支持AMQP 0-9-1 协议,完全兼容开源 RabbitMQ 的各个组件与概念。欢迎大家扫描文末二维码使用体验! TDMQ RabbitMQ 版的背景 众所周知,RabbitMQ是一个历史比较悠久的消息队列中间件,它是使用Erlang语言开发的实现AMQP(Advanced Message Queue Protocol 高级消息队列协议)的
腾讯云CKafka重磅上线DataHub,让数据流转更简便
导语 随着大数据时代的到来,各大互联网公司对于数据的重视程度前所未有,各种业务对数据的依赖也越来越重。有一种观点认为大数据存在 “3V” 特性:Volume, Velocity, Variety。这三个 “V” 表明大数据的三方面特征:量大,实时和多样。这三个主要特征对数据采集系统的影响尤为突出。多种多样的数据源,海量的数据以及实时高效的采集是数据采集系统主要面对的几个问题。 我们想要在数据上创造价值,首先要解决数据获取的问题。因为在互联网发展中,企业内或不同企业之间建立了各种不同的业务系统,这些
云原生中间件RocketMQ-核心原理之高可用机制
RocketMQ分布式集群是通过Master和Slave的配合达到高可用性的。
Master和Slave的区别:

云原生中间件RocketMQ-核心原理之高可用机制
RocketMQ分布式集群是通过Master和Slave的配合达到高可用性的。
Master和Slave的区别:

云原生中间件RocketMQ-核心原理之高可用机制
RocketMQ分布式集群是通过Master和Slave的配合达到高可用性的。
Master和Slave的区别:

来自专有云的时钟守护者-NTP管理系统
在早期版本的 NTP 服务部署中,直接使用 NTPD 单源提供 NTP 服务,且 NTP 客户端侧直接使用 crontab 定时执行 ntpdate 命令同步时间,这样既简单又能满足所有机器时间一致性的需求。

云存储硬核技术内幕——(14) 命令与征服
在上期说到,虽然Ceph作为分布式存储系统,应用于生产环境会出现很多问题,但其他开源分布式存储系统更不适用于云计算的生产环境。

腾讯云服务器安装JDK与tomcat(ubuntu)
sudo add-apt-repository ppa:webupd8team/java
腾讯云服务器安装JDK与tomcat(ubuntu)
sudo add-apt-repository ppa:webupd8team/java
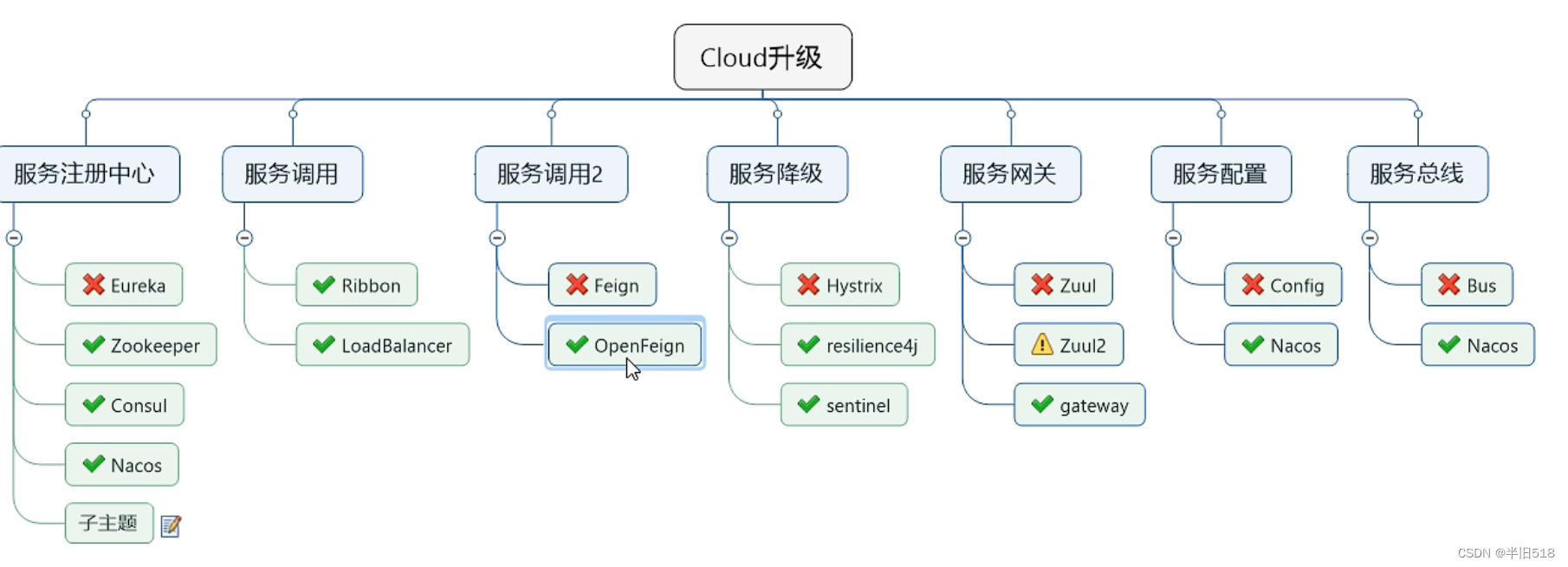
【云原生】springcloud10——人生苦短,我用OpenFeign
前面我们已经讲了服务注册的Eureka,Zookeeper,Consult,以及调用部分的的Ribbon和LoadBalancer,现在我们将学习服务调用的第二部分组件,Feign和OpenFeign,由于Feign已经停更了,我们直接进入OpenFeign的学习。
腾讯云服务器Linux系统--安装Kafka
我用华为的镜像,下载比较快, 并且是而二进制文件,不用编译了,解压配置后,直接使用。
蘑菇街千亿级消息Kafka上云实践
导语:Apache Kafka凭借其高吞吐、高可靠等特性在实时数据或流式数据架构中扮演着重要角色,受到了众多企业用户的青睐。但是随着云时代来临,公有云厂商纷纷推出消息队列服务,很多用户也逐渐从自建消息集群过渡到使用云上消息队列服务。本文将以蘑菇街Kafka服务迁移上云为例,阐述腾讯云消息队列CKafka如何对用户产生价值。 (编辑:中间件小Q妹)

【云原生】springcloud06——订单服务注册zookeeper
上一讲我们已经讲将支付服务进zookeeper完成,结合下图,可以发现我们还需要将订单服务注册进zookeeper。

腾讯云Dubbo-zookeeper实战
2) 上传zookeeper-3.4.6.tar.gz文件到/usr/local/src/zookeeper下

实时流计算框架——Storm
官方下载地址http://storm.apache.org/downloads.html
Kafka组成&使用场景---Kafka从入门到精通(四)
上篇文章介绍了kafka的设计概要,有点对点的队列模式,和消费生产的topic模式,kafka有着高吞吐,低延迟,伸缩性,消息持久化,负载均衡故障转移特性,kafka跟其他处理内存方式不同,内存高命中率来保证发送消息直接在内存操作,而持久化直接交给系统去处理,并且持久化采用的是顺序IO,sendFile零拷贝来保证高吞吐。Kafka的负载均衡则是采用broken和topic每个都有一个master和flower,每个topic的matser和flower不在同一个broken,这样保证一个服务器宕机,其他的flower也会存储数据,不会丢失,故障转移则是 会通过会话心跳的机制跟zookeeper来实现,通过服务注册入zookeeper中,一旦服务器停止,则会选举新的服务。伸缩性也是由zookeeper来配合的,因为有多个服务,这时候则需要考虑多个服务的一致性,服务的无状态 或者 轻量级状态可以保证效率更高,所以他们统一吧状态写入zookeeper保存。

linux系统安装zookeeper 服务的方法
5、进入到 /usr/local/services/zookeeper/zookeeper-3.4.9/conf 目录中:
Nginx/ZooKeeper 负载均衡的差异
Nginx是著名的反向代理服务器,也被广泛的作为负载均衡服务器
ZooKeeper是分布式协调服务框架,有时也被用来做负载均衡
那么他们的区别是什么?如何选择呢?
下面从实际场景看下他们的关系

大数据技术周报第 002 期
最近试了下在百度和 Google 搜索自己的id,结果真的差距不小。百度给 CSDN 的权重太高了。。(让人喷饭!)
