R语言的爬虫生态虽然与Python相比要弱小很多,but,如果你真的想要用R干一些有趣的事情,那么R语言目前所具有的的网络爬取工具也能给你带来很多方便。
今天借着中秋节的兴致,用网易云课堂
全部课程>编程开发>人工智能与大数据>数据分析
模块的课程作为实战对象,来给大家演练一下如何使用R语言httr包实现异步加载和POST 表单提交以及cookies登入。
直接使用json或者其他格式的表单返回值,避免苦逼的的书写大量正则表达式以及让人眼花缭乱的 CSS表达式、Xath路径表达式。这应该是每一个爬虫练习者都应该谨记的事情。
没错,异步加载的网页大多通过返回json字符串的形式来获取数据,它的难点在于请求的提交以及表单体构建、json字符串处理和最烦人的null空值剔除与替换。
本文使用到的技术是哈德利.威科姆大神的又一新作——网络数据爬取利器:httr。
library("httr")
library("dplyr")
library("jsonlite")
library("curl")
library("magrittr")
library("rlist")
library("pipeR")
library("plyr")网易云课堂的网页使用POST请求提交的异步加载,在不久前我曾用Python演示过一次,今天换成R重塑一遍流程,你也可以参照这个代码自己照葫芦画瓢。
网易云课堂Excel课程爬虫思路
首先我们需要做的事情是确认它的网页构架:
打开F12键,定位到XHR,寻找以.josn结尾的请求文件。当你在它的右侧打开对应Preview菜单,可以看到它的json数据源并且,有大量很整齐的课程信息的时候,差不多就找对了。
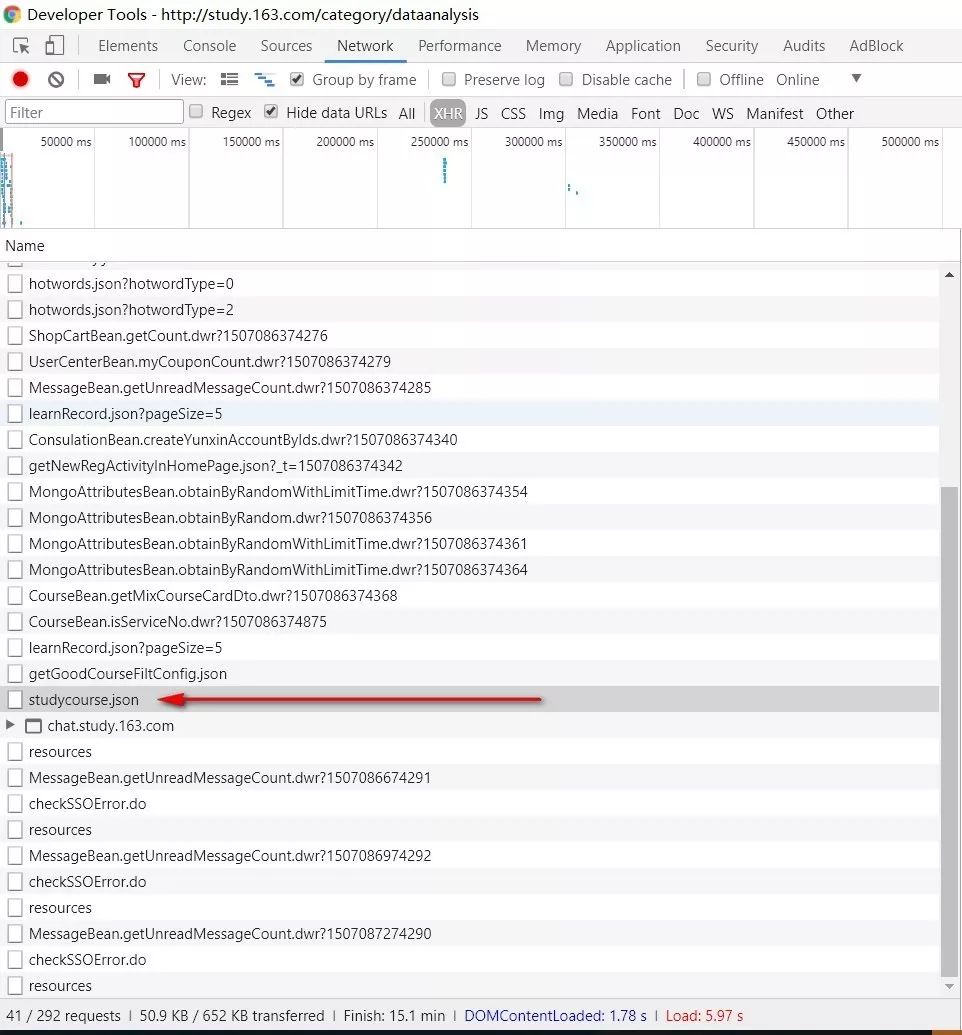
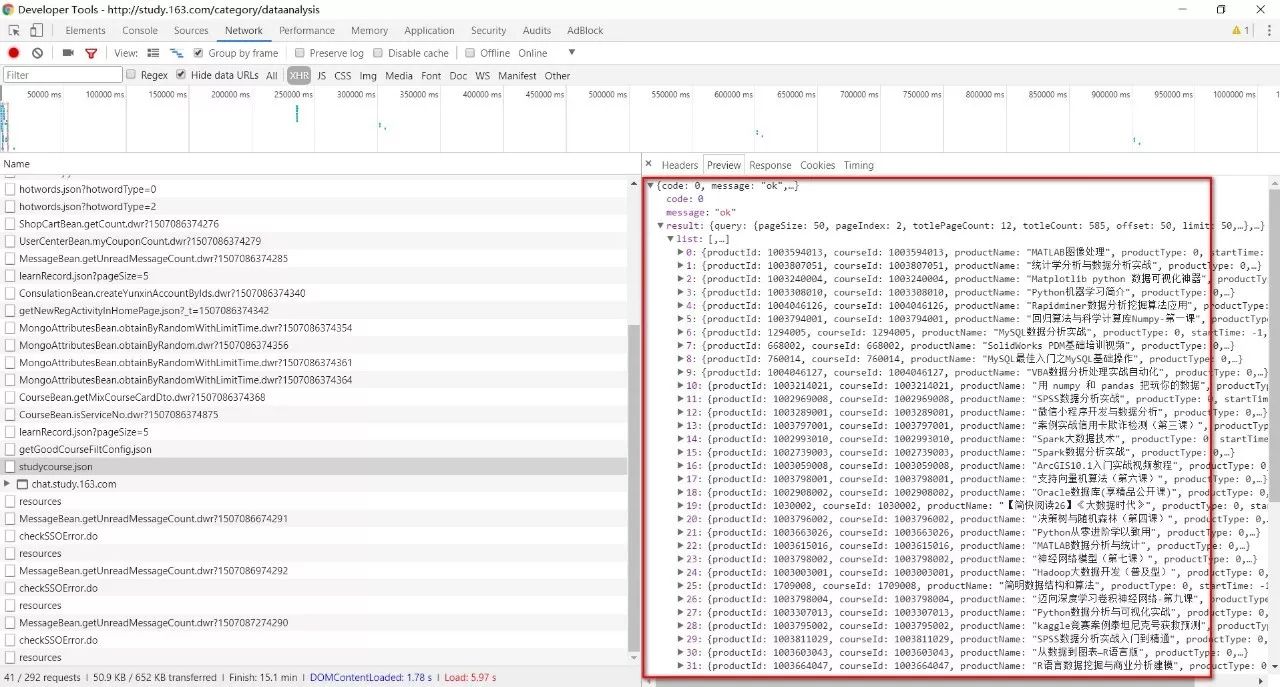
第二步:获取请求信息:
定位到Headers,主要关注四大模块:
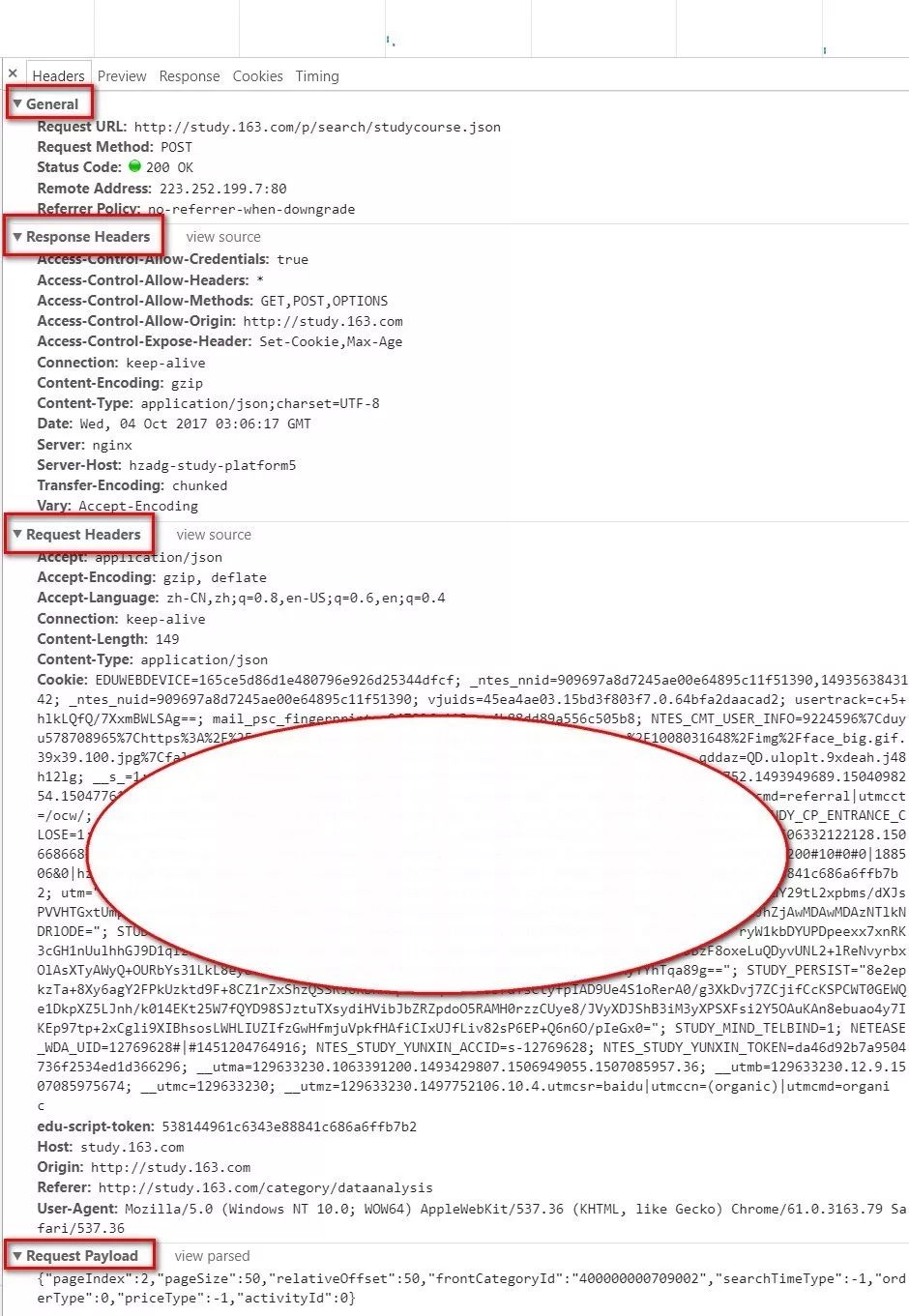
General里面的Request URL、Request Method、Status Code
Response Headers里面的Content-Type Request Headers 里面的 Accept、Content-Type、Cookie、Referer、User-Agent 以及最后Request Paylond里面的所有参数表
General里面的url和post方法即是即决定访问的资源对象和使用的技术手段。 Response Headers里面的Content-Type决定着你获得的数据以什么样的编码格式返回。 Request Headers 里面的 Accept、Content-Type、Cookie、Referer、User-Agent等是你客户端的浏览器信息,其中Cookie是你浏览器登录后缓存在本地的登录状态信息,使用Cookie登入可以避免爬虫程序被频繁拒绝。(虽然网易云课堂的课程信息没有强制要求登录才能查看)。 Request Paylond信息最为关键,是POST提交请求必备的定位信息,因为浏览器的课程页有很多页信息,但是实际上他们访问同一个地址(就是General里面的url),而真正起到切换页面的就是这个Request Paylond里面的表单信息。
以下是我从Chrome后台获取的所有信息:
请求方式:POST
url<-"http://study.163.com/p/search/studycourse.json"请求头:
Accept:application/json
Accept-Encoding:gzip, deflate
Accept-Language:zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.4
Connection:keep-alive
Content-Length:148
Content-Type:application/json
Cookie:请键入你自己的Cookies(我的账号里还有很多付费课程呢,不能随便卖~_~)
edu-script-token:538144961c6343e88841c686a6ffb7b2
Host:study.163.com
Origin:http://study.163.com
Referer:http://study.163.com/category/dataanalysis
User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36请求头参数:(JSON)
pageIndex 1
pageSize 50
relativeOffset 0
frontCategoryId 400000000709002
searchTimeType -1
orderType 0
priceType -1
activityId 0前五页和最后一页的Request Paylond信息(可以看到其中前四个参数最为关键,剩余的可以不要)
{"pageIndex":1,"pageSize":50,"relativeOffset":0,"frontCategoryId":"400000000709002","searchTimeType":-1,"orderType":0,"priceType":-1,"activityId":0}
{"pageIndex":2,"pageSize":50,"relativeOffset":50,"frontCategoryId":"400000000709002","searchTimeType":-1,"orderType":0,"priceType":-1,"activityId":0}
{"pageIndex":3,"pageSize":50,"relativeOffset":100,"frontCategoryId":"400000000709002","searchTimeType":-1,"orderType":0,"priceType":-1,"activityId":0}
{"pageIndex":4,"pageSize":50,"relativeOffset":150,"frontCategoryId":"400000000709002","searchTimeType":-1,"orderType":0,"priceType":-1,"activityId":0}
{"pageIndex":5,"pageSize":50,"relativeOffset":200,"frontCategoryId":"400000000709002","searchTimeType":-1,"orderType":0,"priceType":-1,"activityId":0}
……
{"pageIndex":12,"pageSize":50,"relativeOffset":550,"frontCategoryId":"400000000709002","searchTimeType":-1,"orderType":0,"priceType":-1,"activityId":0}第四步:构造请求提交信息:
Cookie='请键入个人的网易云课堂Cookies'构造浏览器报头信息:
#构造浏览器报头信息: headers <- c('Accept'='application/json', 'Content-Type'='application/json', 'User-Agent'='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36', 'edu-script-token'= '3e44b18e2cea46b6890d1cf92c1ad606', 'Referer'='http://study.163.com/category/dataanalysis', 'Connection'='keep-alive', 'Cookie'=Cookie )
构造请求头参数信息:(这里只接受list)
payload<-list(
'pageIndex'=1,
'pageSize'=50,
'relativeOffset'=0,
'frontCategoryId'='400000000709002'
)
构造url:
第五步:单步执行:
r <- POST(url,add_headers(.headers =headers),body =payload, encode="json",verbose())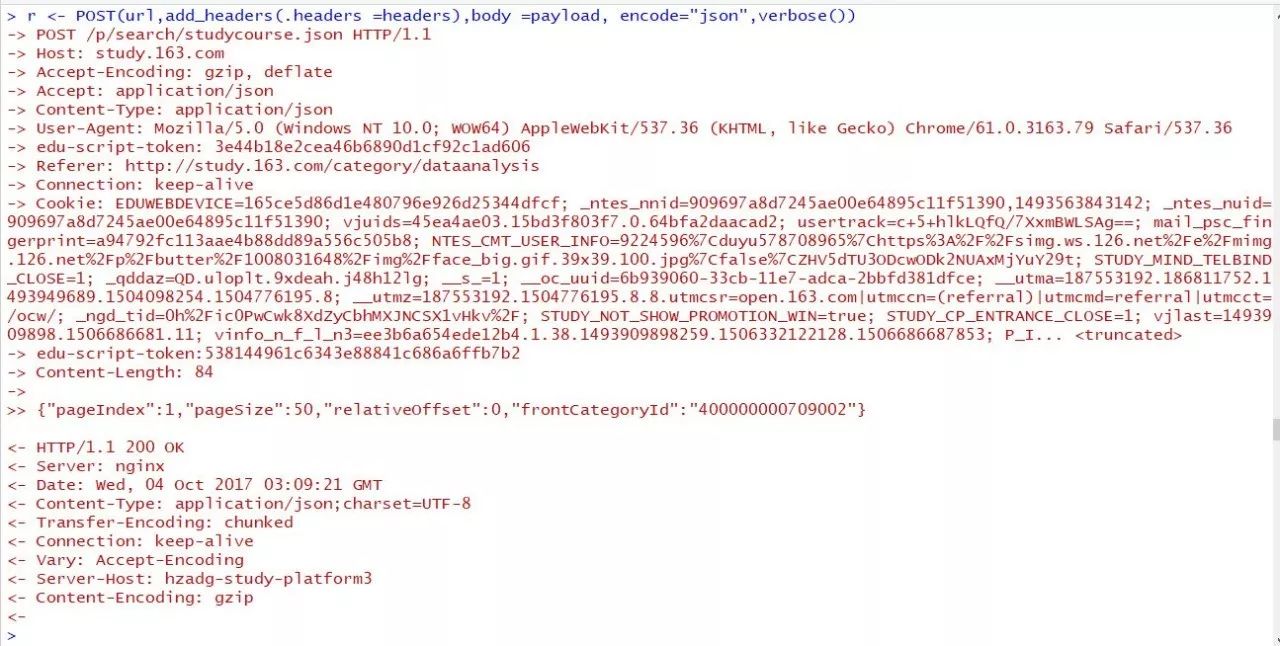
从返回信息上我们可以看到提交成功,毕竟已经成功返回有效内容。
myresult1 <-r %>% content() %>%[[(3) %>% [[(2) %>% toJSON() %>% fromJSON(simplifyDataFrame=TRUE)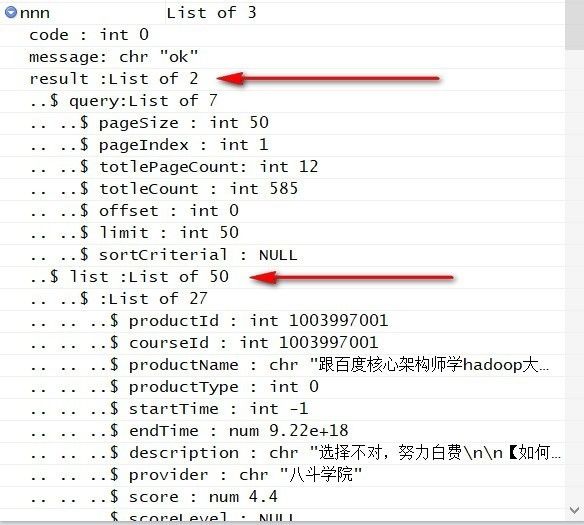
可以看到我们想要的内容存放在r %>% content()返回值的第三个list(result)内的第二个list中,长度为50,宽度为27,刚好就是我们在后台看到的课程信息。如果你不记得<code>[[(3)的用法,记得看前几篇的推送,它与extract函数相同,用于提取指定list对象。
如何使用管道操作符优雅的书写R语言代码
这是所有课程信息字段名称,我们无需要这么多,仅挑选其中必要到的即可。
[1] "productId" "courseId" "productName" "productType" "startTime" "endTime"
[7] "description" "provider" "score" "scoreLevel" "learnerCount" "imgUrl"
[13] "bigImgUrl" "lectorName" "originalPrice" "discountPrice" "discountRate" "forumTagLector"
[19] "tagLectorTime" "schoolShortName" "tagIap" "gmtModified" "displayType" "courseCardProps"
[25] "published" "activityIds" "isPromStatus"
usefulname<-c("productId","courseId","productName","lectorName","provider","score","scoreLevel","learnerCount","originalPrice","discountPrice","discountRate","description")
myresult1<-myresult1 %>% select(usefulname)第六步:书写完整的循环获取全部课程数据:
myfullresult<-list()
for (i in 1:12){
payload[["pageIndex"]]=i
payload[["relativeOffset"]]=payload[["relativeOffset"]] %>% +(50*(i-1))
web <- POST(url,add_headers(.headers =headers),body =payload,encode="json",verbose())
myresult<-web %>% content() %>% [[(3) %>% [[(2)
myfullresult<-c(myfullresult,myresult)
}以上获取的是个巨大的列表,我们需要将其转换为数据框,并提取出我们需要的列。
mydata<-do.call(rbind,myfullresult) %>% as.data.frame() %>% select(usefulname)还有一个问题,因为mydata整体是数据框,但是单个变量仍然是lsit(原因是原始信息中出现大量的NULL值),我们需要将所有NULL替换为NA,方可对mydata的个列进行向量化。
替换NULL值
for (j in 1:length(mydata)){
for (i in 1:nrow(mydata)){
if(is.null(mydata[i,j][[1]])){
mydata[i,j][[1]]=NA
}
}
}将所有list列转为向量:
for (i in usefulname){
mydata[[i]]<-mydata[[i]] %>% unlist()
}去重:
mydata<-unique(mydata)保存:
write.csv(mydata, file ="D:/R/File/yunketang_datafenxi.csv")预览:
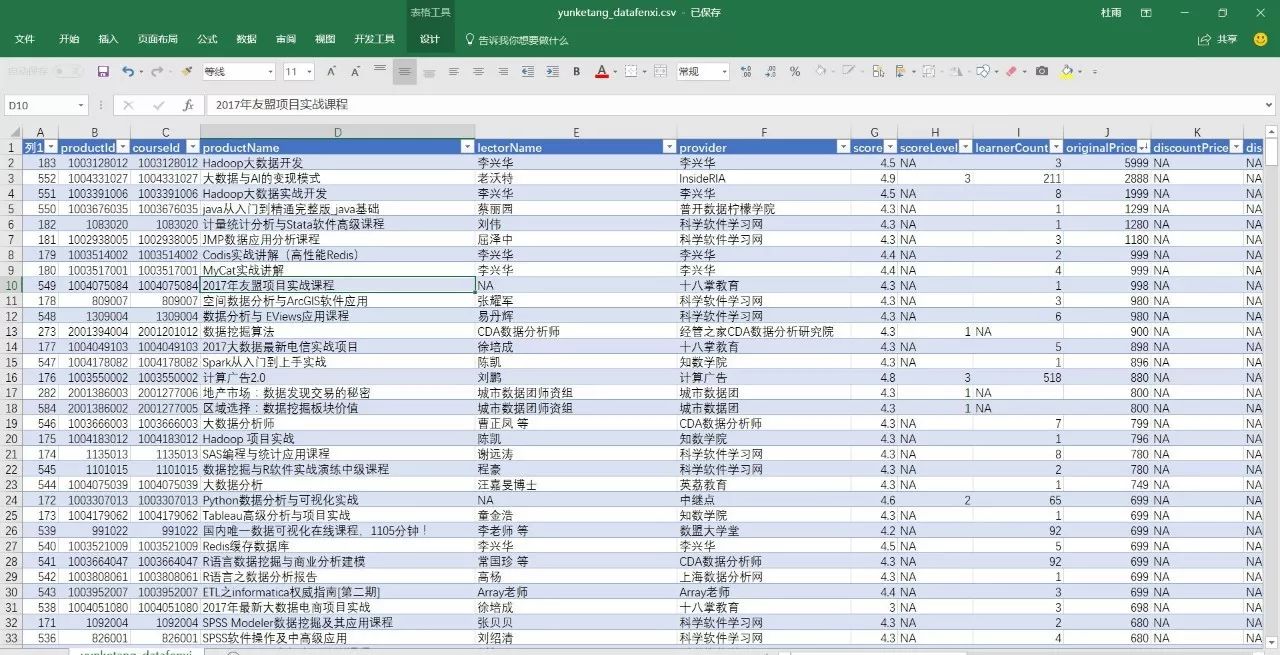
其实多了解一些方法,在很多时候避免走弯路,CSS表达式和Xpath路径表达式甚至正则表达式的门槛都很高,单是搞明白一种就已经很不容易,融会贯通就更难了。
但是多了解一些捷径和方法,你完全可以规避掉这些,我们的目标是获取数据,没有人关心你用的什么方法,学会灵活运用才是关键。
往期案例数据请移步本人GitHub:
https://github.com/ljtyduyu/DataWarehouse/tree/master/File