
大型语言模型(LLM)已经在各种任务上展示了最先进的表现。然而,LLM的推理延迟和大量的GPU内存消耗限制了它们的部署性能。近来,一些有效尝试对LLM进行量化,但是当使用大批次大小或长序列进行推理时,仍然存在计算受限的问题。细粒度量化方法已经在为LLM实现低比特量化方面展示了其能力,但同时需要FP16数据类型进行线性层计算,这在处理大批次大小或长序列时较为耗时。在本文中,作者介绍了一种称为FlattenQuant的方法,通过展平张量中的大通道,显著降低张量的最大值,以实现比特张量量化且精度损失最小。作者的实验表明,FlattenQuant可以直接使用4比特,在LLM中实现48.29%的线性层计算,其余层使用8比特。《FlattenQuant》方法中引入的4比特矩阵乘法可以有效解决由大型矩阵计算引起的计算受限问题。作者的工作使LLM实现了高达2倍的速度提升和2.3倍的内存减少,同时精度损失几乎可以忽略不计。
1 Introduction
大型语言模型(LLM)的卓越能力近年来产生了重大影响(OpenAI, 2023; Ge等人,2023; Zhao等人,2023)。各种LLM已经被发布并在现实世界的生产环境中得到应用(Eloundou等人,2023)。因此,对于LLM的部署有着广泛的需求。
使用大型语言模型(LLMs)进行推理会导致对硬件内存资源的显著消耗,这是由于生成了大量的权重参数和激活张量缓存。此外, Transformer 层的推理需要密集的矩阵计算,这对GPU的计算能力提出了重大挑战。上述事实分别导致了LLM推理的内存受限和计算受限,从而导致了显著的推理延迟。
随着LLMs的广泛应用,高效处理同时大量涌现的推理请求的需求日益增长,这就需要使用大的批处理大小来执行推理。一种广泛采用的优化LLM推理的方法是GPTQ量化,如(Frantar等人,2022年)所述,采用4位量化权重。这有效地缓解了内存受限的问题,尤其是在小批量大小或短序列的情况下,性能令人印象深刻。然而,GPTQ并没有将量化扩展到激活,仍然依赖于FP16进行计算,而不是转换为更低的位 Level 。因此,当批量大小或序列长度增加时,它面临着计算受限的挑战。图1直观地展示了这一挑战,其中8位计算显示出优越的加速性能,特别是在序列长度为256时,与使用FP16计算的GPTQ相比尤为明显。这种现象根源于推理过程的计算受限特性,其中延迟主要受矩阵计算影响,而不是内存访问。
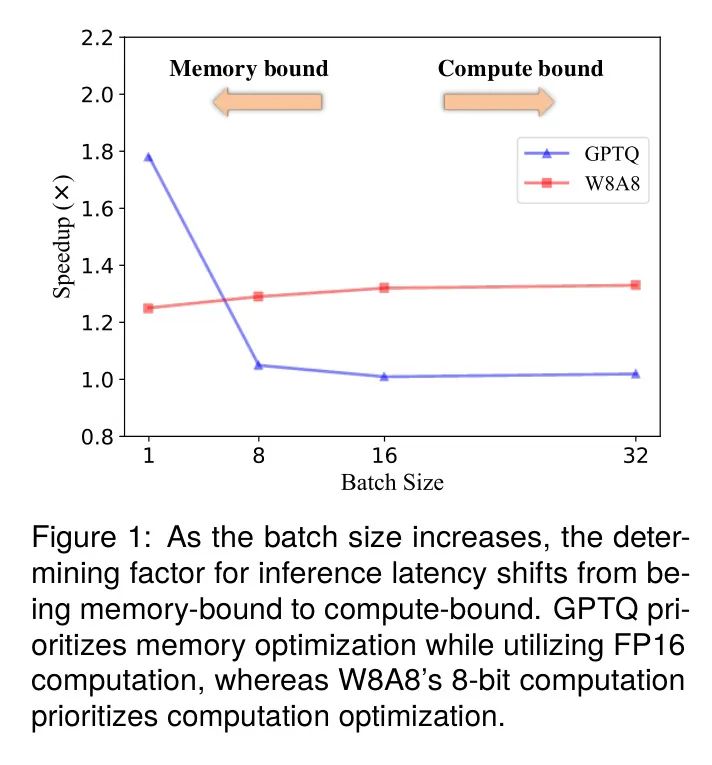
在如CNN这样的小规模模型中,8位量化可以确保精度的小幅损失,并有效减少推理延迟(Banner等人,2019年)。然而,当涉及到量化时,LLM模型呈现两个具有挑战性的方面:
在LLMs的推理过程中,在处理大批量或长序列时存在一个计算受限的问题。为了加快矩阵计算速度,有实际需求使用8位甚至4位。
由于每个通道之间的值分布存在显著差异,大多数现有的方案采用逐通道量化(Frantar等人,2022)或组量化(Yao等人,2022)。然而,这些细粒度的量化方法在张量内部使用不同的缩放因子,这可能会阻止线性层的计算直接使用低比特矩阵乘法,从而降低了推理速度。
在本文中,作者提出了一种称为Flatten-Quant的方法,以实现精确的低比特每张量量化。该方法包括将具有较大值的通道展平,并添加额外的通道以容纳这些值。通过这个过程,显著降低了张量的最大值,同时保留了完整的信息。展平后的张量可以经历每张量量化,同时确保准确性的保持。总结来说,作者的贡献如下:
作者分析了LLM(大型语言模型)的量化方案与推理延迟之间的关系,尤其是量化方案需要克服计算限制的要求。
基于这些发现,作者提出了Flatten-Quant方法,该方法降低了每张量量化的难度,并使低比特计算能够克服计算限制。
作者提出了一个基于FlattenQuant的量化框架,该框架可以直接使用4位数值实现LLMs中48.29%的线性层计算,其余部分使用8位数值。与使用FP16计算的基础线相比,作者在仅有非常小的准确度损失的情况下,实现了最高2倍的速度提升和2.3倍的内存减少。
2 Related Work
Neural Network Quantization
量化是在部署过程中进行模型压缩的一种高效方法(Jacob等人,2018年)。由于LLM模型的训练对硬件要求较高,作者专注于对部署友好的后训练量化(PTQ)(Hubara等人,2021年)。启动PTQ过程需要一个校准数据集,这对于收集网络每一层的输入激活的数值分布至关重要。利用这个数据集,作者可以通过分析激活和权重的值分布来推导出每一层所需的量化参数。获取量化参数最常用的方法可以用以下方程表示:
在量化过程(如公式1所示),层的输入的浮点激活表示为
,而量化的整数值表示为
。所需的位宽由
表示,而浮点到整数的缩放因子由
表示。最终的量化精度受到缩放因子选择的影响很大,这对整个过程至关重要。
Per-Tensor and Fine-Grained Quantization
量化的张量可以通过多种方式完成,每种方式都提供不同 Level 的粒度。当缩放因子适用于整个张量时,这被称为逐张量量化。另外,作者可以采用其他方法来细化量化粒度,比如逐 Token (Yao等人,2022年)、逐通道(Frantar等人,2022年)或组量化(Yao等人,2022年;Dai等人,2021年)。在实践中,对于卷积神经网络(CNNs),逐张量量化是最常用的方法,因为它可以满足精度要求,涉及的量化参数较少,并且在推理期间计算需求较低。然而,由于大型语言模型(LLMs)的数值分布复杂,通过直接的逐张量量化来实现必要的精度可能是具有挑战性的。因此,基于数据分布特征,已经探索了许多细粒度的量化方法。
3 Bottleneck of LLMs Quantification
Outliers of Activation Tensors
研究显示,大型语言模型(LLMs)通常具有均匀分布的权重,这使得可以通过每张量方法简化量化(Xiao等人,2023年)。然而,由于各通道值分布的不同,量化激活项则面临挑战(Xiao等人,2023年)。某些通道的值可能比大多数通道大20-100倍,这需要截断最大值以确立适当的缩放因子阈值。如果阈值设置得过小,这些较大的激活通道中的关键信息可能会丢失。相反,如果阈值过大,大多数通道的量化精度将会显著降低。在这种情况下,针对LLMs的量化通常采用更细粒度的方法。这些方法包括为不同的张量段采用不同的位宽,基于数值分布的每通道量化或分组量化。
如表1所示,已提出了各种量化方法来处理大型语言模型(LLMs)。LLM.int8()方法(Dettmers等人,2022年)利用FP16数据类型处理难以量化的张量,并使用INT8数据类型处理其余部分。GPTQ(Frantar等人,2022年)专注于权重 的4位或3位量化,采用按通道量化并基于Hessian矩阵调整未量化参数。RPTQ(Yuan等人,2023年)对激活张量的数值分布进行聚类,并根据此进行分组以实现低位量化,尽管这可能由于内存重新排列而导致潜在的推理效率降低。相比之下,SmoothQuant(Xiao等人,2023年)试图通过将激活张量中的大值转移到权重上,来平衡激活和权重量化的难度。然而,如果激活张量包含过度大的异常值,这可能效果不佳。

Aim for Compute-bound
推理延迟受到两个主要因素的影响:计算受限和内存受限。量化在很大程度上有助于缓解内存瓶颈。例如,当GPTQ将大型语言模型(LLMs)的权重量化到3位时,它能在A100 GPU上的推理中实现超过3倍的加速。然而,随着输入批处理大小和序列长度的增加,计算受限因素变得占主导地位,掩盖了内存受限的影响。在这种情况下,据LightSeq(Wang等人,2020年)报道,矩阵乘法占据了推理时间的多达80%。因此,减轻计算受限挑战的主要方法是减少矩阵乘法所需的时间。
以A100(Choquette等人,2021)GPU为例,在计算能力方面,INT4计算相较于FP16计算显示出4倍的加速,而INT8则展示了2倍的提升。上述论述强调了通过减少位宽来解决大规模矩阵乘法中的计算限制性难题的可能性。
在使用细粒度量化方法时,面临的一个挑战是量化单元与矩阵乘法计算的兼容性问题。因此,直接利用TensorCore(Markidis等人,2018年)对量化激活和权重进行矩阵乘法变得不可行。例如,在像LLM.int8()(Dettmers等人,2022年)这样的方法中,必须将矩阵乘法计算分割为基于精度的独立计算,然后对结果进行求和。采用逐通道量化(Frantar等人,2022年)的技术,在矩阵乘法计算之前,需要将张量反量化到FP16数据类型。同样,像RPTQ(Yuan等人,2023年)这样依赖于组量化方法,在单个矩阵乘法操作内执行线性层计算时也会遇到挑战。上述方法将权重的量化粒度限制在通道 Level 甚至组 Level ,表明张量中的每个数据单元对应不同的量化系数。这使得量化权重无法直接参与矩阵乘法计算,这必然需要反量化到FP16进行计算。这在大批量或长序列时会导致计算受限。因此,在预期计算受限的情况下,对于部署LLMs来说,逐张量量化仍然是更佳的选择。
4 FlattenQuant
Flattening the Tensor
作者提出的方法名为FlattenQuant,它利用了每张量量化来促进在LLM推理过程中的线性层计算中的高效低比特矩阵乘法。通过使用TensorCore,作者确保了最佳性能。作者方法的核心在于识别目标张量中包含异常值的通道索引,扩展这些特定的通道以容纳异常值,并相应地重复对应的矩阵通道,以确保准确的矩阵乘法。这一策略得到了通道之间异常值的一致存在以及每个通道内方差有限的支持,如(Bondarenko等人,2021)所阐明。
在为FlattenQuant做准备时,作者使用一个校准数据集在模型上执行推理。
参照图1(a),激活通道被扩展,权重通道相应地被重复。方程3解释了激活元素
是如何被展平的,方程4解释了权重
的第j个通道是如何被重复的。
将激活最大值限制在一个更低的截断阈值,可以在每个张量量化的背景下提高准确性。此外,为了进一步增加每个张量量化的准确性,作者还对权重应用了展平操作,这有效地降低了权重的最大值,并促进了值的更均匀分布。
Achieving High-precision
通道间的平滑处理。为了实现每个张量的量化,SmoothQuant使用了一种平滑操作,将高值激活数据迁移到权重中。作者采用了类似但略有修改的操作,如图5的公式所示,其中
是迁移强度。作者定义
为
,其中
是
。与SmoothQuant相比,作者的目标是获得通道值的均匀分布。在对每个通道的最大绝对值进行归一化处理后,作者获得了张量内的相对数值大小,并在激活和权重之间应用了平滑处理。这促使通道值更加公平地分布,从而使得激活和权重更加平坦。
Selection of the truncation threshold.
截断阈值决定了在逐张量量化之前的最大值。一个较小的阈值会导致量化时精度更高,但也会使得GPU内存消耗和线性层计算增加。在选择阈值时,作者主要的目标是防止异常通道干扰量化缩放因子,并避免通道过度扁平化。作者首先使用箱线图(Frigge等人,1989年)来抑制异常通道。在方程6中,下四分位数(
)和上四分位数(
)分别将数据分为最低和最高的25%,而四分位距(
)定义为
。然后作者通过将系数
与通道最大值的平均值相乘得出截断阈值(方程7)。
Quantize some layers to INT4.
通道间的平滑对于实现张量通道上值的更均匀分布至关重要,进一步展平张量,大大降低张量的最大值,显著减少量化的难度。上述操作是4位每张量量化的关键前提。值得注意的是,INT4数据类型提供的表示范围仅是INT8的
。由于矩阵乘法是在激活和权重都量化到INT4之后进行的,即使是轻微的量化错误也可能产生重大影响。因此,在使用INT4时,必须达到高水平的量化精度。
作者的主要目标是使特定的线性层能够实现4位量化,这需要评估每个层分配给4位精度的适宜性。为了实现这一点,作者采用了类似于TensorRT(Vanholder,2016)中使用的方法来评估量化引起的误差,利用KL散度作为评估的关键指标。在按照方程8对每张量进行4位和8位量化后,作者获得了量化张量分布
与原始数据分布
之间的KL散度。然后,将得到的比率与预定义的阈值
进行比较。如果比率低于这个阈值,该层将被分配到4位量化;否则,它将被分配到8位量化。需要注意的是,要对一个层进行4位量化,激活值和权重必须同时进行4位量化。
一旦确定了截断阈值和量化位宽,线性层将受到图3所示量化框架的约束。作者的框架特别融入了平坦张量,这对实现每张量高精度量化有着重要贡献。
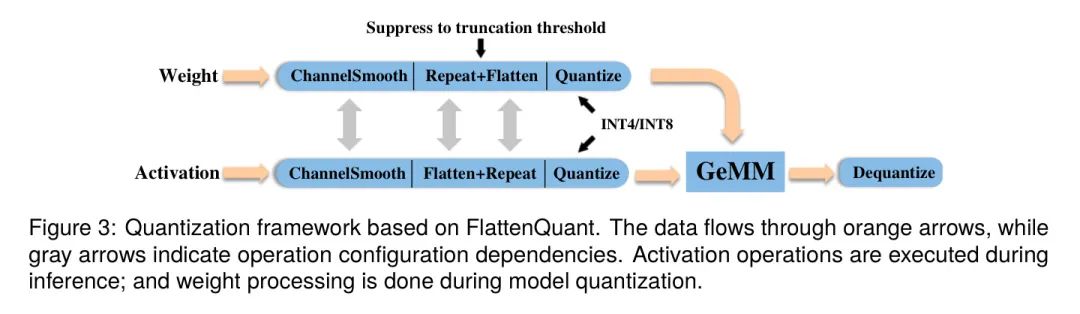
Settings
Baseline 方法。作者的算法旨在特别提高在逐张量量化具有优势的场景下的推理效率,尤其是在计算受限的情况下。为了全面评估其性能,作者将其与两种 Baseline 方法进行了比较:W8A8 的简单量化和 SmoothQuant 方法。FlattenQuant 方法引入了一系列量化 Level ,即 O1、O2 和 O3,这些 Level 在侵略性和效率上逐步增强。关于 Baseline 和 FlattenQuant 使用的具体量化方案的更详细见解,请参考表2。

模型与数据集。作者评估了所提出的FlattenQuant在OPT模型(Zhang等人,2022年)上的表现,使用了五个零样本评估任务:OpenBookQA(Mihaylov等人,2018年)、LAMBADA(OpenAI)(Paperno等人,2016年)、PIQA(Bisk等人,2019年)、HellaSwag(Zellers等人,2019年)、WinoGrande(Sakaguchi等人,2021年),以及一个语言建模数据集WikiText(Merity等人,2017年),以验证算法设置。作者使用了lm-eval-harness(Gao等人,2021年)来评估各个模型。
实现。作者在PyTorch(Paszke等人,2019)中实现了FlattenQuant,并与HuggingFace(Wolf等人,2019)整合了OPT模型家族。作者的实验是在配备有四个A100 GPU(每个带有80GB内存)的服务器上进行的。作者基于CUTLASS INT8和INT4 GEMM Kernel 实现了量化线性层和批量矩阵乘法(BMM)函数,用于INT8和INT4。作者简单地用作者的INT8或INT4量化线性层替换原始的浮点(FP16)线性层,作为量化模型。
为了平滑通道,将
设置为0.5。此外,为了建立一个合适的截断阈值,将
设置为1.3。更进一步,为了确定每一层的量化位宽,作者分配给
一个值为1.86。另外,展平操作后的最终通道数被填充为32的倍数,以对齐矩阵乘法块。
Accuracy Results on LLMs
正如表3中加粗数据所示,明显可以看出在O3配置下,FlattenQuant达到的准确度与SmoothQuant相当。采用展平操作有效地降低了最大值,从而减轻了量化挑战。此外,集成GPTQ可以有效地补偿权重量化过程中产生的误差。值得注意的是,要强调的是GPTQ优化是在每一层的展平权重上进行的。表4展示了作者实验中LLMs相应的设置。在OPT的6.7b、13b、30b和66b模型上,作者的方法一致地实现了近50%的层量化,使用了INT4。另外,展平的比例主要保持在25%的范围内。这大大方便了GPU内存优化并提升了推理速度。


Memory Consumption and Speedup
作者应用了INT4量化到大约50%的层中,与SmoothQuant相比,这进一步减少了推理过程中的GPU内存消耗。表6展示了GPU内存消耗的情况。值得注意的是,尽管对于大批量大小和长序列的推理过程可能会因为键值缓存而消耗大量内存,但这一特定组件并未包含在作者的实验中。作出这一决定的主要原因是,即使在使用INT8量化的情况下,键值对的计算也需要16位表示,而在工业场景中,8位缓存更适合,因为这些场景常常需要额外的量化操作。然而,确保准确性将需要每个组的量化操作,这超出了本文主要关注点的范围。
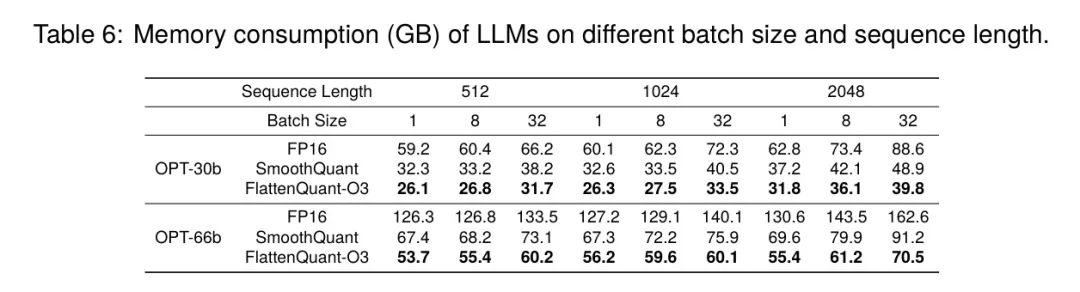
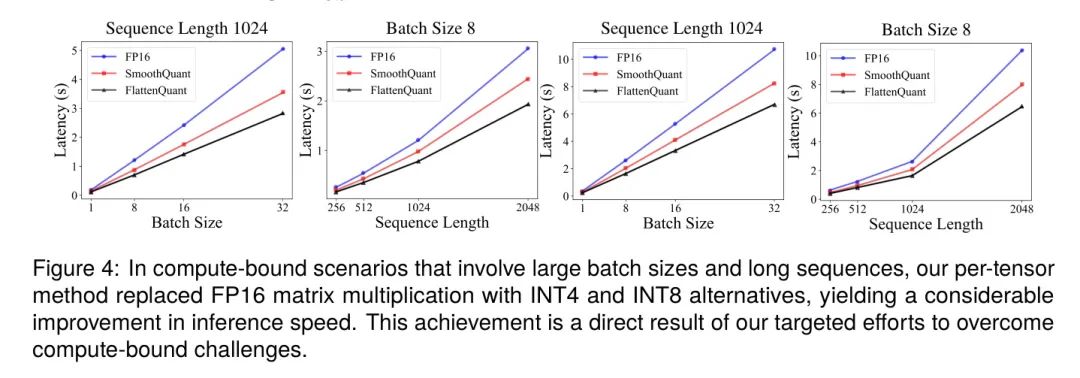
图4展示了在不同批处理大小和序列长度下,OPT-13b和OPT-30b上的推理速度。结果表明,FlattenQuant的速度几乎是FP16的两倍,并且在计算受限的场景中,其性能显著快于SmoothQuant。当序列长度保持恒定时,推理延迟与批处理大小之间存在线性相关性。这种相关性是由于一旦达到计算限制,推理延迟就由矩阵计算的数据维度决定。当批处理大小保持恒定时,随着序列长度的平方 Level 增长,理论计算量也会增加,这一点在推理延迟中也得到了体现。
作者比较了展平操作和矩阵乘法的延迟,如表5所示,可以看出,与矩阵乘法相比,张量展平操作的延迟非常小。因此,通过FlattenQuant引入低比特计算,可以带来显著的加速,这与图4所示的结果是一致的。

Ablation Study
在FlattenQuant方法中,截断阈值的选取、每一层的量化位数(INT4或INT8)以及通道平滑算子的存在与否都共同决定了最终的量化结果。为了确定最佳的量化过程,作者在WikiText-2数据集上进行了全面的消融研究。
通道平滑表7显示了通道平滑操作在三款OPT模型上带来了显著的准确度提升。作者断言这个操作使得激活和权重张量通道上的值分布更加均匀。

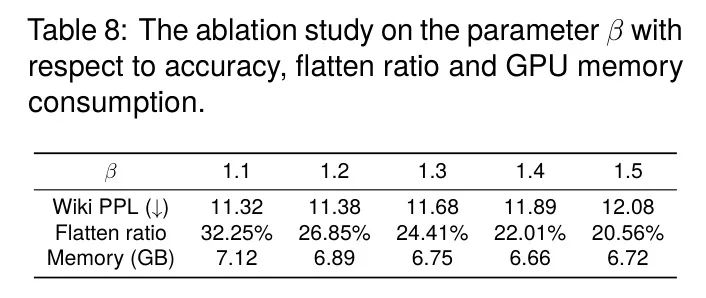
截断阈值为了在量化精度和资源使用之间取得平衡,有必要选择一个合适的参数
值,如公式7所示。从OPT-6.7模型获得的研究结果展示在表8中。当
的值小于1.2时,平均通道展平比率超过30%,导致GPU内存使用增加。然而,相应的准确度提升却很微小。当
的值超过1.4时,平均通道平坦度和GPU内存占用没有实质性变化。但是,准确度明显下降。因此,为了获得平衡的性能,需要在1.2到1.4的范围内确定
的值。
在获取截断阈值的过程中,作者验证了抑制异常通道的影响。表9显示了此操作对三种OPT模型带来了显著的准确性提升。作者认为这个操作防止了一些异常通道过度影响每个通道最大值的平均值。

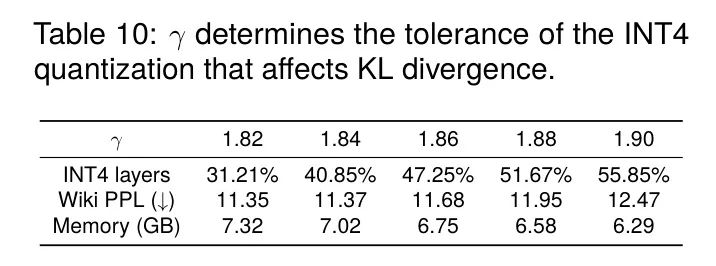
精度选择 作者需要选择一个合适的
(如公式8中定义的)来平衡量化精度和资源消耗。表10展示了在OPT-6.7模型上的结果。当
低于1.86时,精度提升变得微乎其微,而GPU内存占用却增加了。当
超过1.88时,会出现明显的精度下降。因此,通过将
设置在1.86到1.88之间,可以实现最佳性能。
6 Conclusion and Future Work
作者提出了FlattenQuant,这是一种针对大型语言模型在计算受限场景下的逐张量后训练量化目标,它可以在多达48.29%的线性层量化为INT4的情况下实现精度无损。与SmoothQuant相比,FlattenQuant可以进一步减少推理延迟和内存使用。FlattenQuant采用的逐张量INT4量化显著提高了推理性能,尤其是在由于巨大批量大小或长序列推理导致的计算受限问题出现的场景中。
此外,强调一些值得注意的限制条件是很重要的:作者提出的方法对于倾向于计算密集型的场景更具优势。它还对硬件提出了一定的先决条件,包括能够处理INT4数据类型的Tensor Core的可用性,从而提高了推理效率。另外,对于工业部署来说,深度运算符融合变得至关重要。通过将张量展平、通道重复以及后续的矩阵乘法运算符融合为一个单一 Kernel ,可以进一步减轻与展平操作相关的资源消耗。最后,可以推理出,随着模型规模的扩大,作者的方法的影响持续存在。因此,可以假设对于超过1000亿个参数的模型,通过实施作者提出的策略,作者预计在计算效率和内存消耗方面会观察到类似的改进。
Acknowledgement
这项工作得到了中国国家自然科学基金会(编号:U22A6001)、浙江实验室关键研究项目(编号:2022PGOAC02,编号:K2023NB0AC11)、浙江省关键研发项目(编号:2022C04006)以及浙江省自然科学基金(编号:LG21F020004)的支持。
参考
[1].FlattenQuant: Breaking Through the Inference Compute-bound for Large Language Models with Per-tensor Quantization.