思维导图

1.1 Wireshark是什么
- 网卡的默认模式是只接收发往本机的数据包,忽略其他。
- 在混杂模式下,网卡会接收并传递所有经过的数据包,无论它们的目的地如何。
- 这种模式对于使用Wireshark这样的网络分析工具来捕获和分析网络数据是非常重要的。
1.3 一次完整的Wireshark使用过程
- 启动Wireshark时,用户需要决定使用哪个网卡来捕获数据包,这是一个重要的初步决策。
- 许多计算机,尤其是笔记本电脑,通常装有多个网卡,包括无线和有线网卡。
- 如果安装了虚拟机软件,还会增加一些虚拟网卡,这些都是可供选择的捕获选项。
如果希望查看网卡的IP地址信息,就可以在工具栏上选择“捕获选项”,这样就可以打开如图1-3所示的Wireshark捕获窗口。
图1-3 Wireshark的工具栏 在这个窗口中每个网卡左侧都有一个
三角形按钮,单击这个按钮就可以显示详细信息,这些信息中最有用的就是IP地址

- 在Wireshark的菜单栏上,依次单击
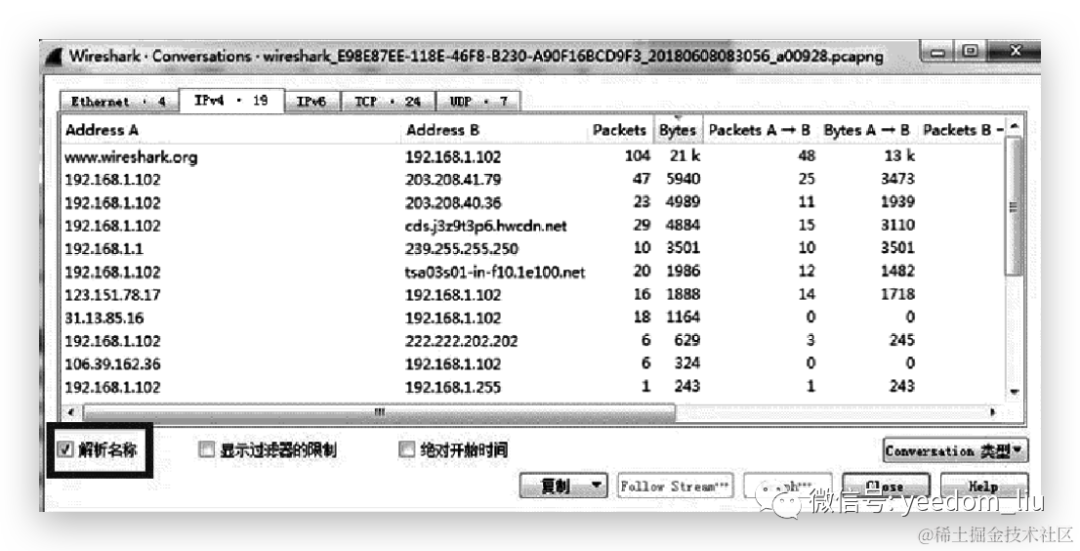
“统计”→“对话”,然后在打开的“对话”窗口中选中“IPv4”选项卡。如图1-9所示,这个选项卡以一个表格的形式显示 - 这些“标题”不仅有提示作用,还可以实现排序的功能,例如我们想要知道哪个会话中产生最多的流量,就可以在“Bytes”标题上单击,这样这些会话就会按照流量从大到小的顺序重新排列。图1-10中就是按照流量进行排序后的对话列表。
图1-10 Wireshark中的对话列表

- 从图1-10中可以看出来,104.25.219.21与192.168.1.102之间对话产生的流量最多为21k。再看这一行的“Bytes A→B”列的值为13k,这说明大部分网络流量是从104.25.219.21发往192.168.1.102的
- Wireshark中提供了一种“名字解析”的功能,如果启用了这个功能的话,那么你以后看到的就不再是那些难以理解的IP地址,而是很容易理解的域名了。
- 可以在数据包捕获过程结束之后,再启用“名字解析”的功能。
- 在菜单栏上单击“视图”→“解析名称”→“解析网络地址”,然后Wireshark就会尝试将捕获到数据包中的IP地址转换为域名,你可以观察一下现在Wireshark的数据包列表面板,如图1-11所示。
图1-11 启用了“解析网络地址”之后的数据包细节面板

现在我们返回到“对话”窗口中,这时里面的IP地址没有任何的变化。Wireshark为了方便我们自行选择查看IP地址还是域名,在这个窗口的左下方有一个“解析名称”的复选框,只有当选中了这个复选框之后,里面的IP地址才会被解析为域名,如图1-12所示。
图1-12 启用了“解析网络地址”之后的会话列表
2.1 伯克利包过滤
伯克利包过滤中的限定符有下面3种
限定符 | 描述 | 默认值 | 示例 |
|---|---|---|---|
type | 表示指代的对象,如IP地址、子网或端口等。 | 默认为host | host 192.168.1.1 表示主机名或IP地址,net 表示子网,port 表示端口 |
dir | 表示数据包的传输方向,如源地址或目的地址。 | 默认为src or dst | src 表示源地址,dst 表示目的地址。例如,192.168.1.1 表示源或目的地址为192.168.1.1的数据包 |
proto | 表示与数据包匹配的协议类型。 | 无默认值 | 常见的协议包括ether(以太网)、ip(互联网协议)、tcp(传输控制协议)、arp(地址解析协议) |
图2-2 IP数据包头的格式
2.2 捕获过滤器
选择菜单栏上的“捕获”→“选项”按钮。
图2-3

(2)如图2-4所示,在“所选择接口的捕获过滤器”后面的文本框中填写字符串形式的过滤器。
图2-4 Wireshark中设置捕获过滤器 这个编写的过滤器如果不正确的话,文本框的颜色会变成粉红色,如果正确的话则为绿色。

图2-5给出了一个正确的过滤器。
图2-5 一个设置好的捕获过滤器

2.3 显示过滤器
在数据包列表处选中一个数据包,然后在数据包详细信息栏处查看这个数据包的详细内容,这里会以行的形式展示数据包的信息,当我们选中其中一行时(见图2-11),例如IP地址,那么在状态栏处就会显示出该数据包该行对应的过滤器表达式。
图2-11 在状态栏处显示的过滤器表达式

3.1 捕获接口的输出功能
我们以用时间分割为例,将每隔10秒捕获的数据保存为一个文件,使用的方法为勾选“自动创建新文件,经过…”,然后勾选下方的第2个复选框,在文本框中输入10,单位选择为“秒”(见图3-3)。
图3-3 “Wireshark·捕获接口”中“输出”选项 选择完毕之后,单击“开始”捕获数据包,这时Wireshark就会将每隔10秒捕获到的数据包单独的保存成文件。图3-4给出了保存文件的示例。

3.2 环状缓冲区
Wireshark中提供了类似的功能,但你选择了多文件输出的时候,如果不希望这个文件的个数一直在增加,可以选择使用环形缓冲器,这样Wireshark就不会不断地产生新的文件。具体的设置如图3-5所示。
图3-5 环形缓冲器的使用
3.5 保存显示过滤器
单击菜单栏上的“分析”→“显示过滤器”
图3-11 Wireshark中的显示过滤器

单击这个对话窗口左下方的“+”按钮,在左侧“新建显示过滤器”中输入过滤器的名称(例如baidu),在右侧输入“显示过滤器”的内容,我这里输入的是ip.addr==www.baidu.com(见图3-12),完成之后单击OK按钮。
图3-13 在Wireshark中的添加一个显示过滤器

7.2 观察远程访问HTTP的过程
步骤 | 描述 | 详细过程 |
|---|---|---|
1 | 判断服务器是否在同一局域网 | 操作系统将自己的IP地址和子网掩码用二进制表示并进行与运算,确定所在子网。例如,IP地址192.168.1.10和子网掩码255.255.255.0的与运算得到子网192.168.1.0。 |
2 | 寻找网关并转换IP地址为MAC地址 | 如果目标服务器不在同一局域网内,客户端需要找到网关(如192.168.1.1)。然后通过ARP协议将IP地址转换为MAC地址,以便局域网中的交换机能识别并转发数据包。 |
3 | 建立与服务器的TCP连接 | 使用TCP协议的三次握手建立客户端和服务器之间的连接。 |
4 | 应用程序构造HTTP请求 | 操作系统完成TCP连接后,应用程序负责构造HTTP请求数据包。这个阶段可能会有延迟,因为应用程序处理请求需要时间。 |
5 | 服务器响应及传输时间 | 客户端发送请求后,数据包传送到服务器并得到响应。这个过程包括数据传输时间和服务器应用程序的响应时间。 |
表7-1 与子网掩码IP地址对应十进制,二进制

7.3 时间显示设置
我们平时使用的时间格式有两种,一种是常用的某年某月某日,称为绝对格式。另一种就是形如秒表上的显示,这个示数表示的是经过了多久,例如2分21秒,称为相对格式。 默认情况下,Wireshark中提供了一个显示捕获数据包时刻的“Time”列(见图7-13)。这个列中显示的是相对值,捕获到第一个数据包的时间定义为零点,之后捕获到数据包的时间值都是距离这个零点的时间间隔,单位为微秒。
图7-13 Wireshark中的Time列
Wireshark为了能够更好地对数据包进行分析,还提供了多种时间的显示方式。如果要修改这些显示方式的话,可以在菜单栏上依次单击“视图”→“时间显示格式”,Wireshark中提供的包括如图7-14所示的选项。
图7-14 Wireshark中的“时间

只使用某一种时间格式的话不太容易看出数据包之间的关联,但是来回切换时间格式又过于烦琐。这时我们就可以选择在原有时间列的基础上再添加新的列,这个列用来显示当前包与前面包的时间间隔,具体的步骤如下。
- 首先单击菜单栏上的“编辑”→“首选项”,或者直接单击工具栏上的“首选项”按钮。
- 然后在图7-15所示的首选项窗口左侧选择“外观”→“列”。
- 这时首选项窗口的右侧就会显示出当前数据包列表中的全部列,点击左下方的“+”号就可以添加新的一列。
- 这时在首选项窗口的右侧就会添加新的一行,这一行分成两个标题和类型两个部分,我们单击标题处为新添加的列起一个名字,这里我们为其起名为tcp.time_delta。
- 在类型下面的Number下拉列表框处,选中我们需要的列内容。其中和时间有关的选项如图7-16所示。
图7-15 Wireshark中的首选项

图7-16 在Wireshark中添加新的一列

如图7-17所示,我们在类型里选择使用Custom类型,在字段处输入“tcp.time_delta”,最后在字段发生处添加一个“0”。
图7-17 添加列的内容

在数据包列表面板中已经多了一个名为“tcp.time_delta”的列,但是现在该列还不能正常工作。我们还需要完成如下的步骤。
- 在Wireshark首选项窗口中依次选择“Protocols”→“TCP”。
- 勾选“Calculate conversation timestamps”,默认这个选项是不被选中的(见图7-18)。选中之后Wireshark会为TCP会话中的数据包再加上一个新的时间戳,用来表示该数据包在当前会话的产生时间。
图7-18 勾选“Calculate

(3)单击“OK”按钮。这时再查看数据包列表面板就可以看到新的一列已经起作用了。
在默认情况下,Wireshark会以捕获第一个数据包的时间作为原点。但是我们也可以自行将某一个数据包定义为原点,具体的方法是在一个数据包上单击鼠标右键,在弹出的菜单上选中“设置/取消设置时间参考”,此时这个数据包的时间列就会显示为“REF”。如果我们使用了相对时间格式的话,它之后的所有数据包都会将这个数据包的捕获时间作为原点。
7.4 各位置延迟时间的计算
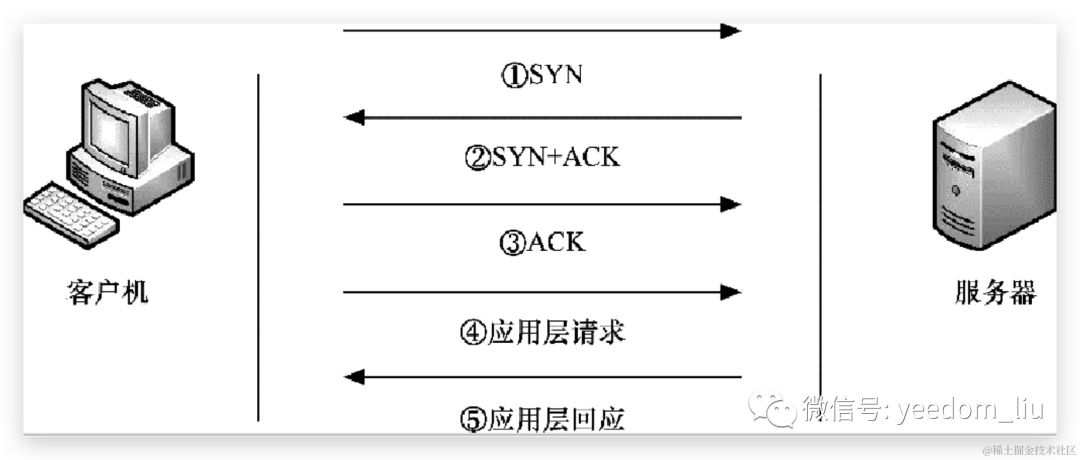
在整个上网过程中,一共可以分成4个阶段,但是由于其中的ARP阶段位于内网,而且速度非常快,因此通常不会引起网络延迟,这里只考虑后面的3个阶段,分别是网络传输延迟、客户端应用程序引起的延迟和服务器应用程序引起的延迟。需要注意的一点是,这种延迟分类的方法是基于Wireshark捕获数据包得出的。图7-19中显示了上网过程中捕获到的数据包。
图7-19 上网过程中产生的数据包

这5个数据包的含义如图7-20所示,其中①②③④⑤分别对应着图7-19中的第9、10、11、12、13这几个数据包。
图7-20 客户机与服务器的通信过程
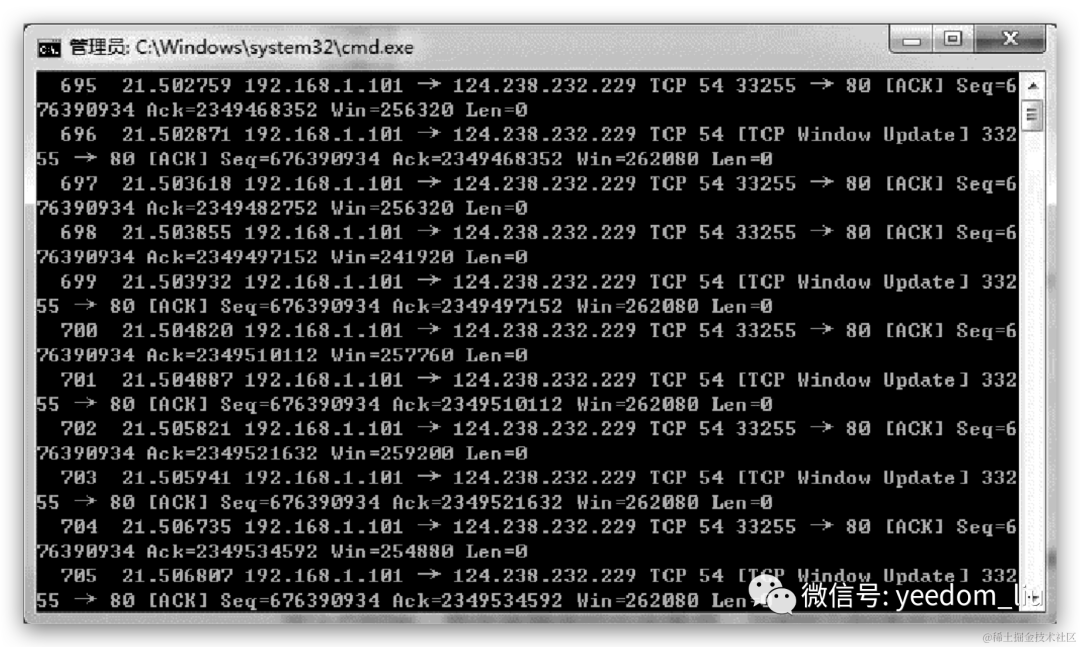
当发生网络延迟时,我们首先需要考虑的就是传输线路导致的延迟。如图7-21所示,我们首先来查看捕获到的TCP 3次握手中的第2个数据包,它的tcp.time_delta值为0.062,这个值是由3个时间共同组成的:
图7-21 TCP 3次握手中的第2个数据包

从客户端到服务端的时间; 服务端操作系统接收TCP 3次握手的syn请求,并回应一个(syn,ack)回应; 从服务端到客户端的时间。 考虑操作系统在处理TCP 握手时的时间很短,这个值可以看作是由第一个和第 3 个时间组成的,也就是数据包在线路上传输所花费的时间。如果这个值较大的话,则说明线路传输时出现了延时,这个原因可能是由服务端和客户端之间的设备造成的。
16.1 Wireshark编程开发的基础
菜单栏上的“帮助”→“关于Wireshark”,打开“关于Wireshark”对话框。如图16-1所示,在这个对话框中显示了当前版本所支持的所有工具,如果在这个对话框中显示了“with Lua 5.x”的话,表示已经内嵌了Lua的解释环境。
图16-1 Wireshark中的Lua版本

TShark -v来查看。如图16-2所示,我们可以看到这个Tshark和Wireshark一样都支持Lua5.2.4。
图16-2 TShark -v来查看Lua版本
17.2 Tshark.exe的使用方法
Tshark中,可以使用如下的命令查看每个网卡的编号: tshark -D
使用第4块网卡来捕获数据,为了加快捕获的速度,这里使用-s参数来表示只捕获数据包的前512个字节数据: tshark -s 512 -i 4
和Wireshark一样,Tshark还支持捕获过滤器和显示过滤器的使用,这两种过滤器的语法也和Wireshark中规定的一样,例如下面就使用了目标端口为80的过滤器: tshark -s 512 -i 4 -f 'tcp dst port 80' 捕获到的数据包如图17-3所示。
图17-3 tshark捕获到的数据包
Tshark中还提供了强大的统计功能,这个功能通过参数-z来实现,这个参数后面需要使用Tshark所指定的值,可以使用如下命令: tshark -z -h Tshark所有可以使用的值如图17-4所示。
图17-4 tshark的统计功能

使用“io,phs”作为-z参数的值,这里面我们添加了-q来指定不显示捕获的数据包信息: tshark -i 4 -f“port 80” -q -z io,phs 执行该命令的结果如图17-5所示。
图17-5 tshark的统计结果

如果你希望深入地了解Tshark的功能,可以访问https://www.wireshark.org/docs/man-pages/tshark.html来学习。
17.3 Dumpcap的用法
Dumpcap也是Wireshark中自带的一个命令行工具,这种工具的优势就在于对资源的消耗较小。你可以使用dumpcap.exe -h来查看它的帮助文件。
图17-6 Dumpcap的帮助文件

17.4 Editcap的使用方法
使用Wireshark在捕获数据包时得到的文件可能会很大,Editcap就可以将这种大文件分割成较小的文件。另外,Editcap也可以通过开始时间和停止时间来获取捕获数据包文件的子集,删除捕获数据包文件中重复数据等。 同样我们了解这个工具最好的办法还是查看它的帮助文件,使用Editcap -h可以看到(见图17-7)。
图17-7 Editcap的帮助文件

参数 | 描述 | 使用示例 | 功能 |
|---|---|---|---|
-r | 保留原始文件 | editcap -r Traces.pcapng packetrange.pcapng 1-2000 | 保留输入文件Traces.pcapng,并将其中的前2000个数据包保存到packetrange.pcapng |
-c | 按数量拆分文件 | editcap -c 2000 Traces.pcapng SplitTrace.pcapng | 将文件Traces.pcapng按每2000个数据包拆分成多个文件,保存为SplitTrace.pcapng |
-d | 去除重复数据包(比较当前数据包和前5个) | editcap -d Traces.pcapng nodupes.pcapng | 检测并去除文件Traces.pcapng中的重复数据包,保存为nodupes.pcapng |
-D | 去除重复数据包(指定范围) | editcap -D 10000 Traces.pcapng nodupes.pcapng | 可以指定范围(0~100000)来检测并去除Traces.pcapng中的重复数据包,保存为nodupes.pcapng |
17.5 Mergecap的使用方法
Mergecap的功能比较单一,它主要的功能就是将多个文件合并成一个文件,最基本的语法为: mergecap –w infile1.pcapng infile2.pcapng … 也就是mergecap后面跟多个文件名,其中的第一个是其他文件合并生成的。
17.6 capinfos的使用方法
参数 | 描述 | 输出单位 |
|---|---|---|
-t | 输出包文件的类型 | - |
-E | 输出包文件的封装类型 | - |
-c | 输出包的个数 | - |
-s | 输出包文件的大小 | byte |
-d | 输出所有包的总字节长度 | byte |
-u | 输出包文件中包的时间周期 | second |
-a | 输出包文件中包的起始时间 | - |
-e | 输出包文件中包的结束时间 | - |
-y | 输出包文件中包的平均速率 | byte/s |
-i | 输出包文件中包的平均速率 | bit/s |
-z | 输出包文件中包的平均字节长度 | byte |
-x | 输出包文件中包的平均速率 | packet/s |
图17-8 使用Capinfos查看数据包的信息
