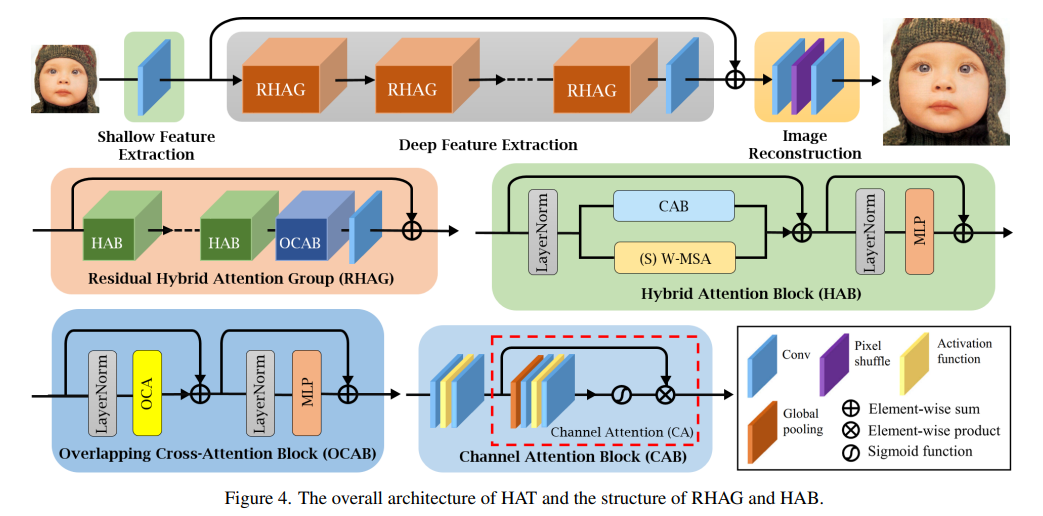
1、Activating More Pixels in Image Super-Resolution Transformer
基于Transformer的方法在低级别视觉任务中,如图像超分辨率,表现出了令人印象深刻的性能。Transformer的潜力在现有网络中仍未得到充分发挥。为了激活更多的输入像素以实现更好的重建,提出了一种新的混合注意力Transformer(HAT)。它同时结合了通道注意力和基于窗口的自注意力方案,从而充分利用了它们各自的优势,即能够利用全局统计和强大的局部拟合能力。
此外,为了更好地聚合跨窗口信息,引入了一种重叠的交叉注意力模块,以增强相邻窗口特征之间的交互作用。在训练阶段,采用同一任务预训练策略来利用模型的潜力以实现进一步的改进。大量实验证明了所提出的模块的有效性,进一步扩展了模型以显示出该任务的性能可以得到极大的提高。整体方法在PSNR比现有最先进的方法高出1dB以上。
https://github.com/XPixelGroup/HAT
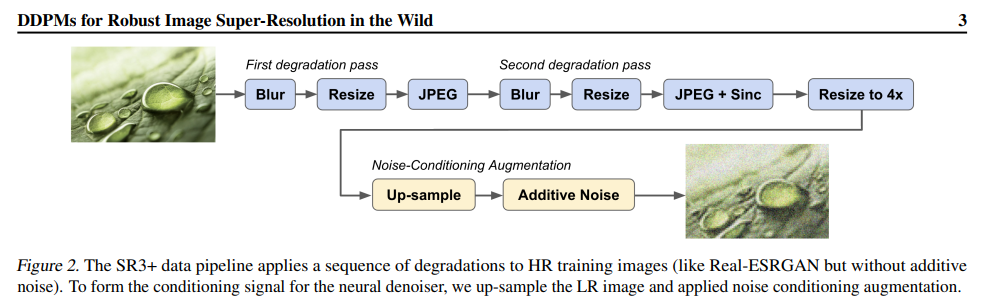
2、Denoising Diffusion Probabilistic Models for Robust Image Super-Resolution in the Wild
扩散模型在单幅图像超分辨率和其他图像-图像转换任务中显示出良好的效果。尽管取得了这样的成功,但在更具挑战性的盲超分辨率任务中,它们的表现并没有超过最先进的GAN模型,在盲超分辨率任务中,输入图像的分布不均匀,退化未知。
本文介绍了一种基于扩散的盲超分辨率模型SR3+,为此,将自监督训练与训练和测试期间的噪声调节增强相结合。SR3+的性能大大优于SR3。在相同的数据上训练时,优于RealESRGAN。
3、Implicit Diffusion Models for Continuous Super-Resolution
图像超分辨率(SR)因其广泛的应用而受到越来越多的关注。然而,当前的SR方法通常受到过度平滑和伪影的影响,而大多数工作只能进行固定放大倍数。本文介绍了一种隐式扩散模型(IDM),用于高保真连续图像超分辨率。
IDM采用隐式神经表示和去噪扩散模型相结合的统一端到端框架,其中,在解码过程中采用了隐式神经表示来学习连续分辨率表示。此外,设计了一种比例自适应调节机制,其中包括低分辨率(LR)调节网络和一个比例因子,该比例因子调节分辨率并相应地调节最终输出中的LR信息和生成特征的比例,从而使模型适应连续分辨率要求。大量实验证实了IDM有效性,并展示其在先前艺术品中的卓越性能。代码在https://github.com/Ree1s/IDM

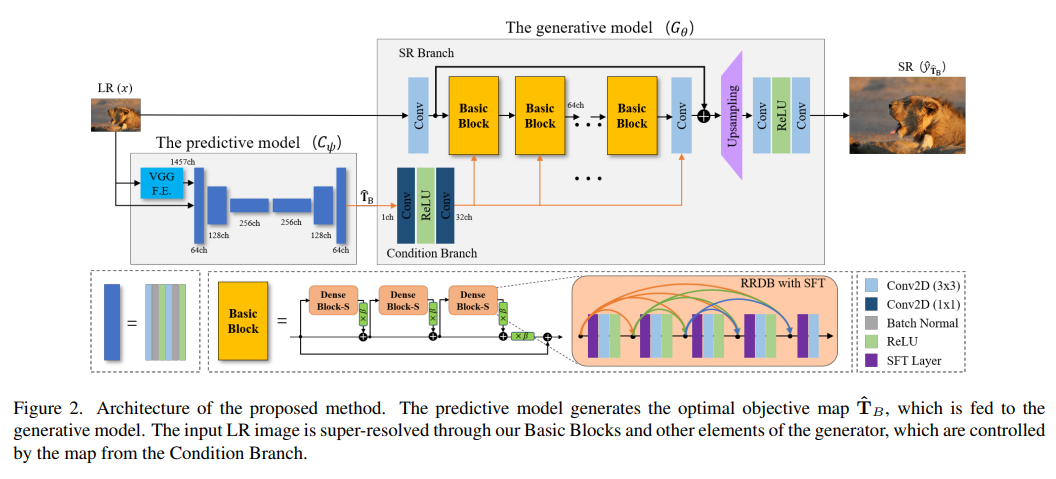
4、Perception-Oriented Single Image Super-Resolution using Optimal Objective Estimation
相对于使用失真导向损失(如L1或L2)训练的网络而言,使用感知和对抗损失训练的单图像超分辨率(SISR)网络提供了高对比度输出。但是,已经表明,使用单个感知损失无法准确恢复图片中的局部不同形状,往往会产生不良伪像或不自然的细节。因此,人们尝试了各种损失的组合,例如感知、对抗和失真损失,但往往很难找到最优的组合。
本文提出了一种新的SISR框架,应用于每个区域进行最优目标生成,以在高分辨率输出的整体区域中生成合理的结果。具体来说,该框架包括两个模型:一个预测模型,用于推断给定低分辨率(LR)输入的最佳目标图;一个生成模型,生成相应的SR输出。生成模型基于提出的目标轨迹进行训练,该轨迹表示一组基本目标,使单个网络能够学习与轨迹上组合的损失相对应的各种SR结果。
在五个基准测试中,实验结果表明,该方法在LPIPS、DISTS、PSNR和SSIM度量上优于最先进的感知驱动SR方法。视觉结果也证明了方法在感知导向重构方面的优越性。代码和模型在https://github.com/seunghosnu/SROOE
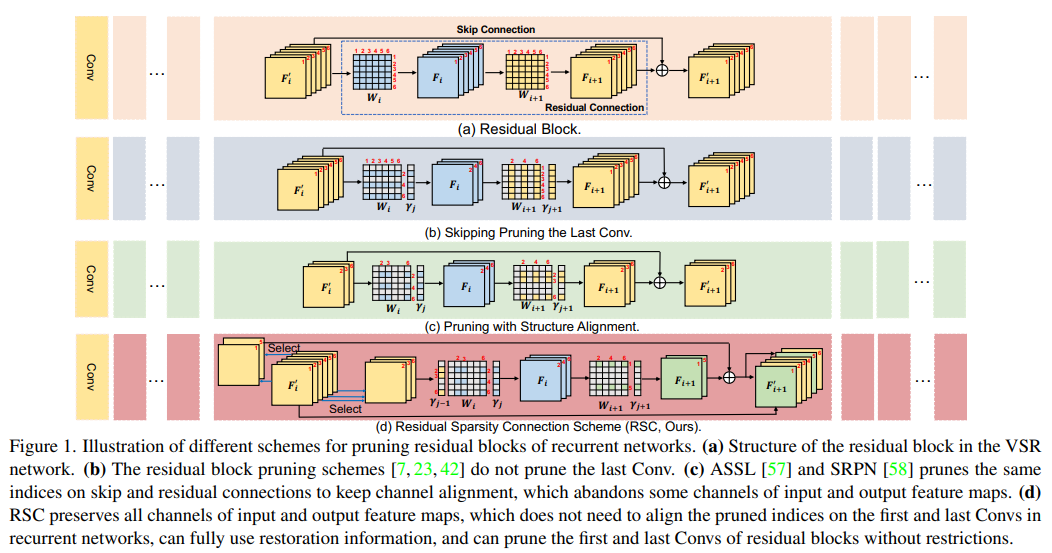
5、Structured Sparsity Learning for Efficient Video Super-Resolution
现有视频超分辨率(VSR)模型的高计算成本阻碍了它们在资源受限的设备(例如智能手机和无人机)上的部署。现有VSR模型包含相当多的冗余参数,拖慢推理效率。为了剪枝这些不重要的参数,根据VSR的特性开发了一种结构化剪枝方案,称为结构稀疏学习(SSL)。
SSL为VSR模型的多个关键组件设计了剪枝方案,包括残差块、递归网络和上采样网络。具体而言,为递归网络的残差块设计了一种残差稀疏连接(RSC)方案,以解放剪枝限制并保留恢复信息。对于上采样网络,设计了一个像素洗牌剪枝方案,以保证特征通道空间转换的准确性。此外观察到,在隐藏状态沿着递归网络传播时,剪枝误差会被放大。为缓解此问题,设计了时间微调(TF)。大量实验证明了SSL在定量和定性上都显著优于最近的方法。代码在https://github.com/Zj-BinXia/SSL
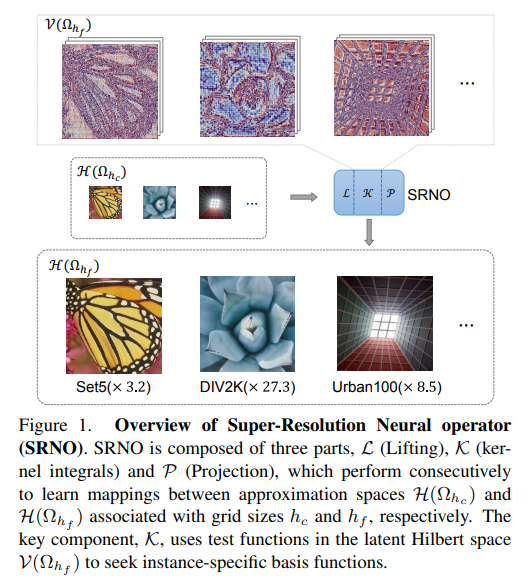
6、Super-Resolution Neural Operator
提出超分辨率神经算子(Super-resolution Neural Operator,SRNO),可以从低分辨率(LR)对应物中解决高分辨率(HR)图像的任意缩放。将LR-HR图像对视为使用不同网格大小近似的连续函数,SRNO学习了对应的函数空间之间的映射。
与先前的连续SR工作相比,SRNO的关键特征是:1)每层中的核积分通过Galerkin类型的注意力得到高效实现,在空间域中具有非局部特性,从而有利于网格自由的连续性;2)多层注意力结构允许动态潜在基础更新,这对于SR问题从LR图像“幻想”高频信息非常重要。
实验结果表明,SRNO在准确性和运行时间方面优于现有的连续SR方法。代码在https://github.com/2y7c3/Super-Resolution-Neural-Operator
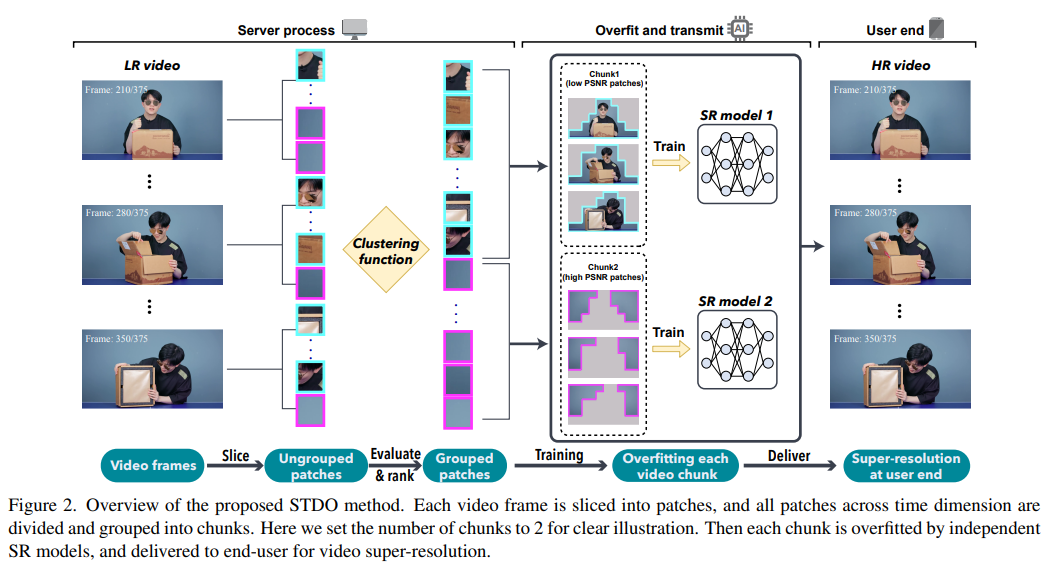
7、Towards High-Quality and Efficient Video Super-Resolution via Spatial-Temporal Data Overfitting
提出一种新的高质量、高效的视频分辨率提高方法,利用时空信息将视频准确地分成块,从而将块的数量和模型大小保持在最小。在现成的移动电话上部署模型,实验结果表明,方法实现了具有高视频质量的实时视频超分辨率。与最先进的方法相比,在实时视频分辨率提高任务中实现了28 fps的流媒体速度,41.6 PSNR,速度提高了14倍,质量提高了2.29 dB。代码将发布:https://github.com/coulsonlee/STDO-CVPR2023
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!
经典GAN不得不读:StyleGAN
一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!
最新最全100篇汇总!生成扩散模型Diffusion Models
ECCV2022 | 生成对抗网络GAN部分论文汇总
CVPR 2022 | 25+方向、最新50篇GAN论文
ICCV 2021 | 35个主题GAN论文汇总
超110篇!CVPR 2021最全GAN论文梳理
超100篇!CVPR 2020最全GAN论文梳理
拆解组新的GAN:解耦表征MixNMatch
StarGAN第2版:多域多样性图像生成
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 |《计算机视觉中的数学方法》分享
《基于深度学习的表面缺陷检测方法综述》
《零样本图像分类综述: 十年进展》
《基于深度神经网络的少样本学习综述》