⛳️ Python 爬虫实战场景,人
本次要采集的站点是 double 人车,目标站点如下所示:
www.renrenche.com/cn/dazhong/?plog_id=6aa04cde5309dd233f85bd47a996c423域名使用的是 base64 加密
该站点也是字体反爬经典案例,其呈现不是以乱码形式展现,而是源码差异,具体如下图所示。
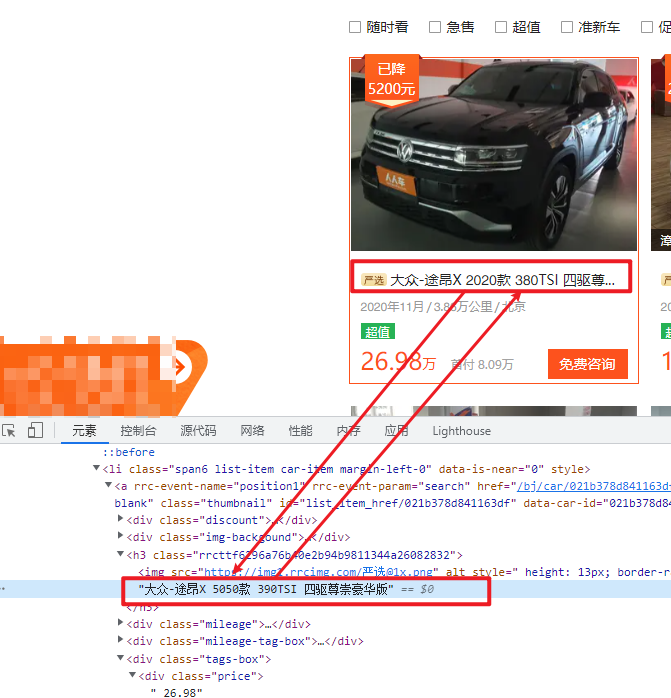
可以看到 2020 在源码中为 5050 , 380 为 390 ,非常有趣的一种字体反爬手段。
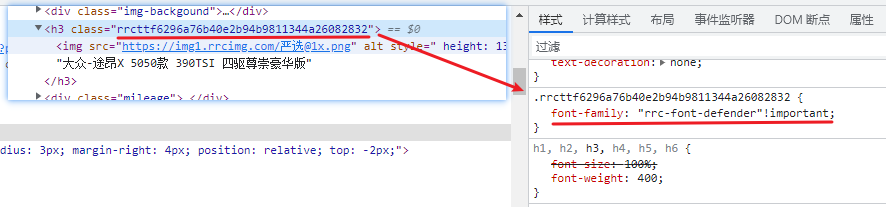
检查其 css 样式,发现下图字体设置。
切换到网络视图,抓取字体请求,得到如下内容,又是一个 woff 字体文件,在文件名上右键,然后在来源面板打开,可以预览字体内容。

可以看到最下面的数字顺序是混乱的。
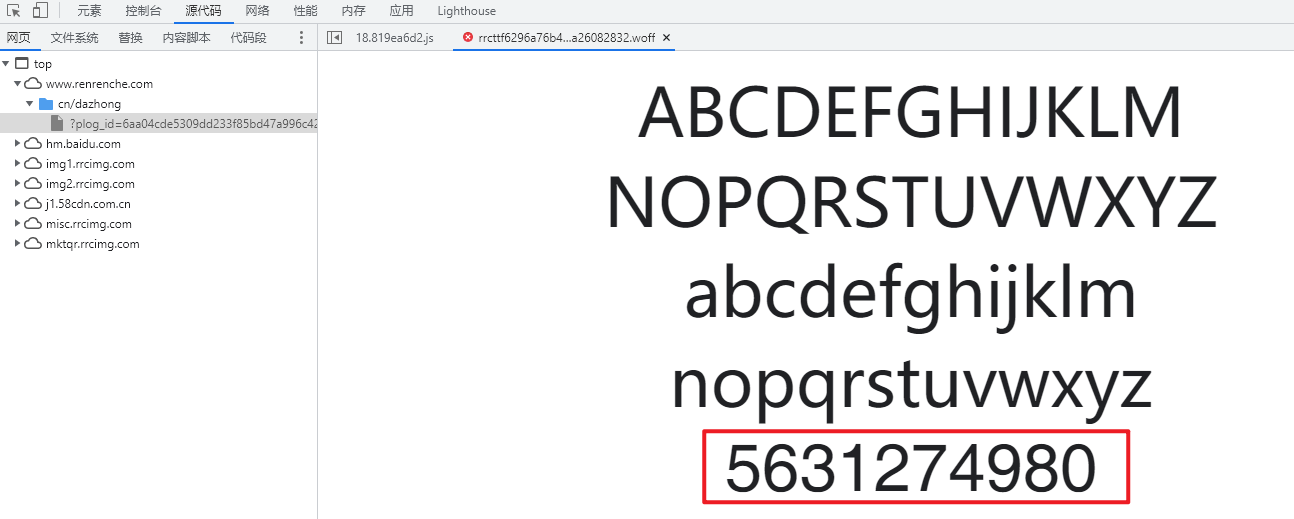
得到这个逻辑之后,就可以通过字体文件进行替换操作了。
⛳️ 实战编码,人
随机下载一个字体文件到本地,然后打开之后,查看编码,使用的工具是 FontCreator,打开之后,可以看到索引和文字的对应关系如下。

0 对应的是 zero ,其余的字体对应关系都发生了变化,这也是后续我们解决该字体加密的核心逻辑。
而且在实测中发现字体文件只有第一次网页加载时,才会重新下载,后续都是直接从缓存读取,这就给了我们偷懒的机会。

接下来我们重点解决一下字体加密部分代码。
获取网页字体类名
import requests
from lxml import etree
res = requests.get('https://www.renrenche.com/cn/dazhong/?plog_id=6aa04cde5309dd233f85bd47a996c423')
els = etree.HTML(res.text)
class_name = els.xpath('//h3/@class')[0]通过 class_name 获取字体文件的二进制流。
在获取字体文件的时候,先判断一下本地文件夹中是否存在该文件,如果有,直接使用即可。
import requests from lxml import etreefrom fontTools.ttLib import TTFont
import io
import osres = requests.get('https://www.renrenche.com/cn/dazhong/?plog_id=6aa04cde5309dd233f85bd47a996c423')
els = etree.HTML(res.text)
class_name = els.xpath('//h3/@class')[0]本地保存文件
file_woff = './tmp/renPython脱敏处理_font/{0}.woff'.format(class_name)
if not os.path.exists(os.path.dirname(file_woff)):
os.makedirs(os.path.dirname(file_woff))url = 'https://misc.rrcimg.com/ttf/{0}.woff'.format(class_name)
resp = requests.get(url)判断文件是否存在,不存在创建
if not os.path.exists(file_woff):
print("创建文件")
with open(file_woff, 'wb') as f:
f.write(resp.content)读取文件
with open(file_woff, 'rb') as font_file:
font = TTFont(io.BytesIO(font_file.read())) # 转换成字体对象print(font)
获取 cmap
font_obj = font['cmap']
获取 cmap table
font_tables = font['cmap'].tables
uni_list = font['cmap'].tables[0].ttFont.getGlyphOrder()
print(uni_list)
此时得到如下内容:
['.notdef', 'zero', 'four', 'five', 'three', 'seven', 'one', 'two', 'six', 'nine', 'eight']找到字体文件的对应关系,编写对应的转换,这里我们直接复制一段网站文本进行测试。
替换前:本田-凌派 5048款 490Turbo CVT豪华版
替换后:本田-凌派 2019款 180Turbo CVT豪华版接下来核心逻辑会写在代码中,可以边看边学习。
# 将英文替换为数字
cn_num_list = [eng_list[_] for _ in uni_list]
print(cn_num_list) # 转换后的正确数字顺序将数字对应关系生成
zip_num_list = dict(zip(cn_num_list, num_list))
print(zip_num_list)假设读取到的文本是 本田-凌派 5048款 490Turbo CVT豪华版
input_txt = '本田-凌派 5048款 490Turbo CVT豪华版'
print("转换前",input_txt)文本进行转换,当字符是数字时
transfor_str = [_ if not .isdigit() else zip_num_list[] for _ in input_txt]
print("转换后",''.join(transfor_str))
