文档编写目的
Cloudera Replication Manager(以下简称为 RM,旧版本的CM中简称为BDR)为数据迁移提供了一个集成式的易用管理解决方案,通过界面化的方式可以非常便捷的定义不同集群之间的数据复制操作 ,本文主要介绍如何配置及使用RM进行HDFS和Hive 复制
测试环境
源集群版本:CDH7.1.7、CM 7.4.4、已启用Kerberos, Realm为CLOUDERA.BDR.COM
目标集群版本:CDH7.1.7、CM7.4.4、已启用Kerberos, Realm为CLOUDERA. COM
前置条件
- 源集群和目标集群节点之间必须网络互通
- 源集群和目标集群都有企业版 License
- 源 CDH 集群版本要求分成三种情况:
- 不需要做 Sentry to Ranger acl 迁移 – CDH5.13.0+ – CM5.14.0+
- 需要做 Sentry to Ranger acl 迁移 – CDH5.13.0+ – CM6.3.1+
- 需要使用 HDFS snapshot diff 功能 – CDH5.13.3+,5.14.2+,5.15.0+ – CM5.15.0+,CM6.1.0+
RM简介
Cloudera Manager 提供了一个集成的、易于使用的管理解决方案,以在 Hadoop 平台上启用数据保护。Replication Manager 使您能够跨数据中心复制数据以实现灾难恢复方案。
复制可以包括存储在 HDFS 中的数据、存储在 Hive 表中的数据、Hive 元存储数据以及与在 Hive 元存储中注册的 Impala 表关联的 Impala 元数据(目录服务器元数据)。当关键数据存储在 HDFS 上时,Cloudera Manager 有助于确保数据始终可用,即使在数据中心完全关闭的情况下也是如此。
您还可以使用 HBase shell 复制 HBase 数据。(Cloudera Manager 不管理 HBase 复制。)
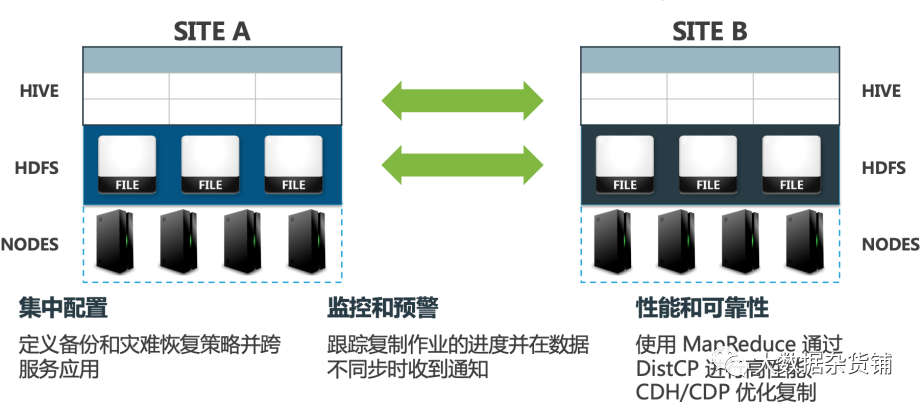
RM 属于 Cloudera Manager 上的一个功能模块,提供以下关键功能:
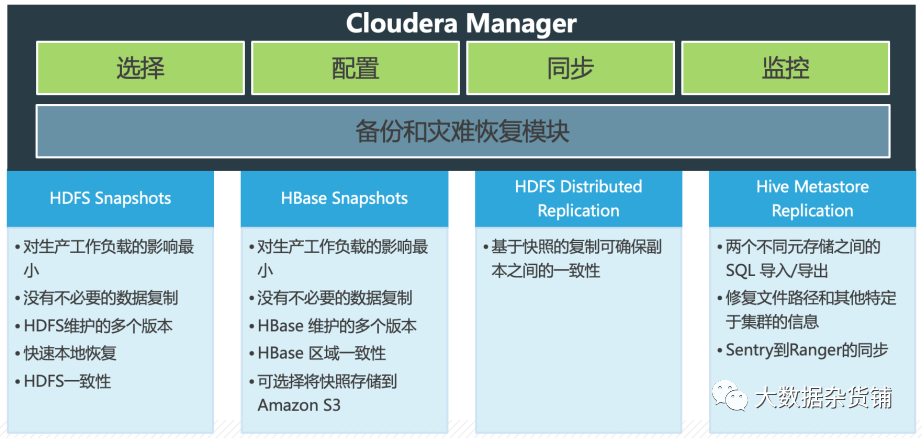
- 选择- 选择对您的业务运营至关重要的数据集。
- 计划- 为数据复制和快照创建适当的计划。根据您的业务需求触发复制和快照。
- 监控- 通过中央控制台跟踪快照和复制作业的进度,并轻松识别传输失败的问题或文件。
- 警报- 当快照或复制作业失败或中止时发出警报,以便可以快速诊断问题。
RM 可以使用定时任务或者其他的调度方式将数据从一个集群复制到另一个集群。
- 对于 HDFS,RM 可以直接同步文件或者文件夹。
- 对于 Hive/Impala,RM 可以直接进行数据库级别或者表级别数据同步,也支持数据增量同步,同时能够支持元数据同步和 Sentry 到 Ranger acl 迁移。
- RM 可以基于 HDFS 自动生成的历史快照进行复制。由于快照内的文件处于不可变状态,因此支持异步复制,即使源端数据出现持续更改也不会产生任何影响。
- RM 支持复制 HDFS 静态加密之后的数据。
- RM 可以简化安全认证,特别是针对两个集群的 kerberos 域名不一致,或者 TLS 认证不一致的情况。
RM的支持矩阵
Replication Manager 复制 HDFS、Hive 和 Impala 数据,并支持从 CDH(5.10 版及更高版本)集群到 CDP PvC Base(7.0.3 版及更高版本)集群的 Sentry 到 Ranger 复制。
CDH5/6到CDP的支持矩阵
源集群 | 支持的最低源 CM版本 | 支持的最低源 CDH版本 | 目标集群 | RM上支持的服务 |
|---|---|---|---|---|
CDH 5CDH 6 | 6.3.0 | 5.10 | CDP私有云基础7.0.3 | HDFS、Sentry to Ranger、Hive 外部表 |
CDP PvC Base的支持矩阵
源集群 | 支持的最低源CM 版本 | 支持的最低源 CDH版本 | 目标集群 | RM上支持的服务 |
|---|---|---|---|---|
CDP私有云基础 | 7.1.1 | 7.1.1 | CDP私有云基础 | 高密度文件系统Hive 外部表 |
Kerberos支持矩阵
在集群上使用 Kerberos 身份验证时,Replication Manager 支持以下复制方案:
- 安全源到安全目的地。
- 不安全的来源到不安全的目的地。
- 不安全的来源到安全的目的地。此场景必须满足以下要求:
- 此复制方案需要额外的配置。
- 当目标集群有多个源集群时,所有源集群必须是安全的或不安全的。Replication Manager 不支持混合使用安全和不安全的源集群。
- 目标集群必须运行 Cloudera Manager 7.x 或更高版本。
- 源集群必须运行兼容的 Cloudera Manager 版本。
RM端口要求
在 Replication Manager 中创建复制策略之前,请确保以下端口在源主机和CDP Private Cloud Base主机上是开放且可访问的,以允许源和目标 Cloudera Manager 服务器与 HDFS、Hive、MapReduce 和 YARN 主机之间进行通信, 按要求。
服务 | 默认端口 | 本地源主机 | 描述 |
|---|---|---|---|
Cloudera Manager HTTP (Web UI) | 7180笔记启用 TLS 时为 7183 | 所有管理节点 (CM*) | 用于控制流。在特定的源和目标 IP 地址上打开,而不是在所有源 IP 地址上打开以与对等(源)Cloudera Manager 通信。配置源集群和目标集群后,目标 Cloudera Manager 在对等期间连接到端口 7180/7183 上的源 Cloudera Manager。 |
HDFS 名称节点 | 8020 | 所有主节点 | 用于 HDFS 和 Hive/Impala 复制的数据流,以从目标 HDFS 和 MapReduce 主机到源 HDFS NameNode 进行通信。 |
HDFS 数据节点 | 50010 / 9866 用于 DataNode HTTP 服务器端口。 | 所有辅助节点 | 用于 HDFS 和 Hive/Impala 复制的数据流,以从目标 HDFS 和 MapReduce 主机到源 HDFS DataNode 进行通信。 |
NameNode WebHDFS | 9870笔记如果启用了 TLS,则为 9871。 | 用于 Apache Hadoop HttpFS 服务的数据流,以提供对 HDFS 的 HTTP 访问。HttpFS 有一个支持所有 HDFS 文件系统操作(读取和写入)的 REST HTTP API。 | |
纱线资源管理器 | 8032 | 所有主节点 | 用于数据流访问 YARN ResourceManager。 |
Hive 元存储 | 9083 | 所有管理节点 (CM*) | 用于 Hive/Impala 复制以查询或访问 Hive Metastore 的数据流。 |
Impala 目录服务器 | 26000 | 所有管理节点 (CM*) | 仅用于 Hive/Impala 复制期间的数据流内部使用。目录服务使用此端口与 Impala 守护程序进行通信。 |
密钥管理服务器 (KMS) | 16000 | 所有主节点 | 用于加密数据复制期间的数据流。适用于 Java KeyStore KMS 和 Key Trustee KMS。 |
Kerberos KDC 服务器和 KRB5 服务 | 88 | 全部 | 在集群上启用 Kerberos 身份验证时,用于 Replication Manager 的身份验证流。打开目标集群上所有主机的端口。 |
RM配置
配置同行
在目标CDP7.1.7 集群CM界面>备份>同行中
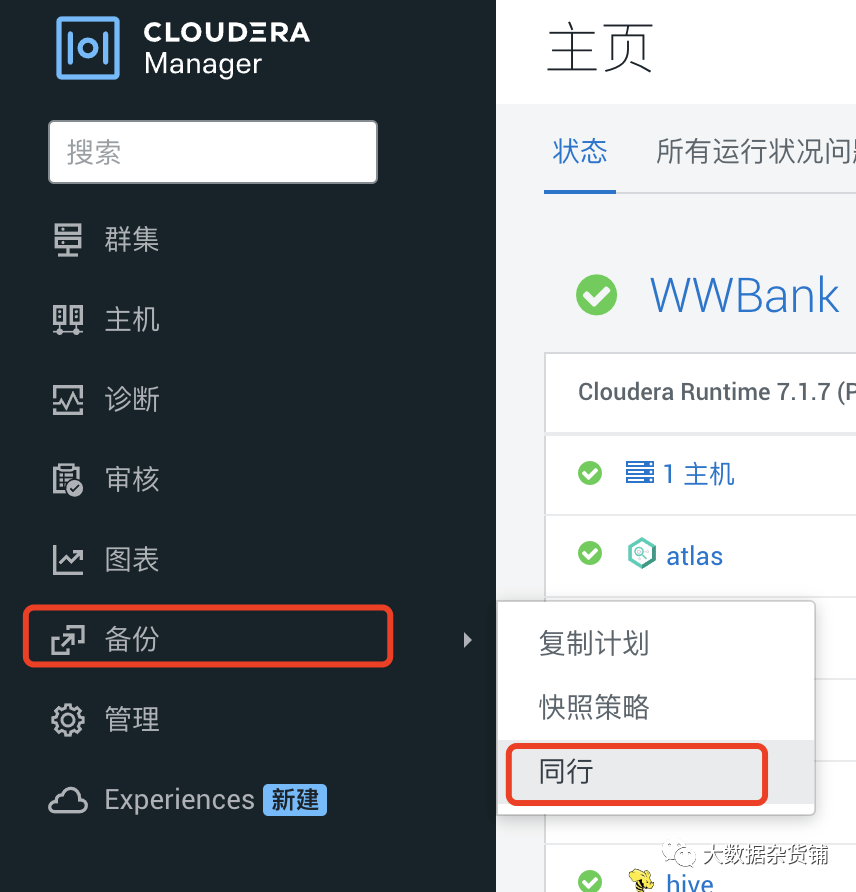
配置同行的管理员账号信息
点击添加同行,填写源CDP7.1.7集群的地址和CM页面的管理员用户和密码
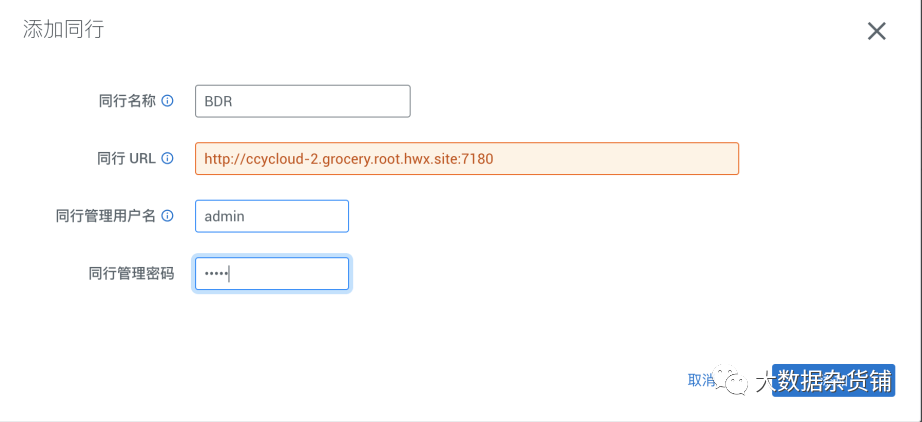
添加之后,系统会自动进行连接性测试:

如测试连接中出现如下异常,表明两个集群的Kerberos域互相存在问题,建议在部署时考虑使用相同的KDC,用于减少配置互信的工作量

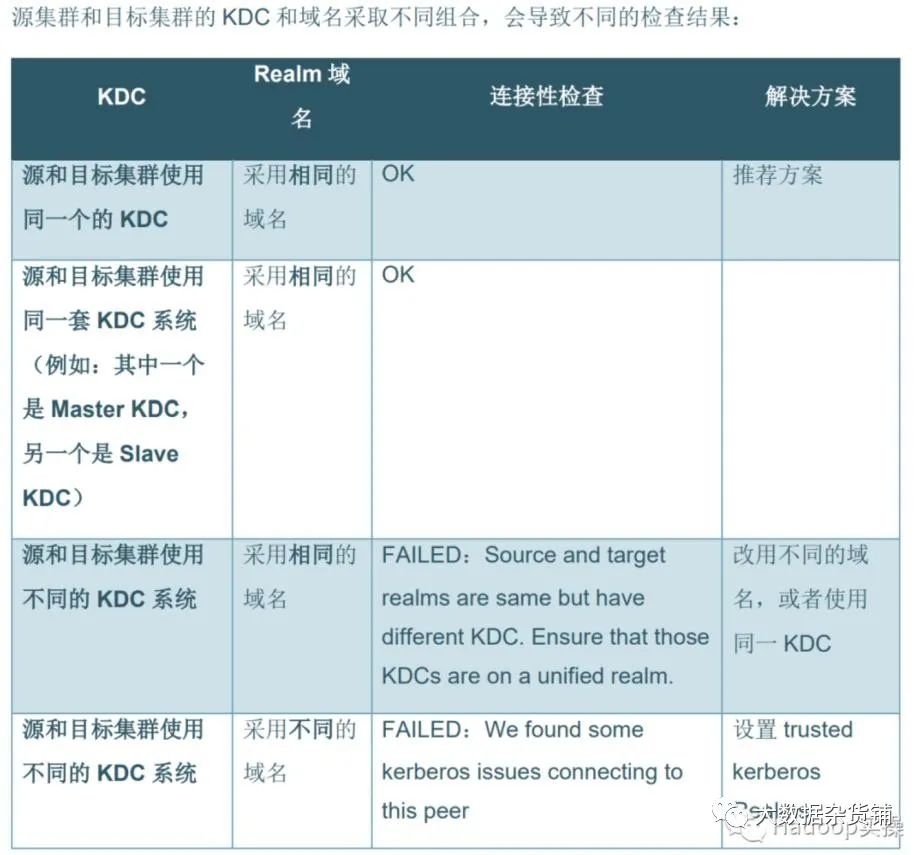
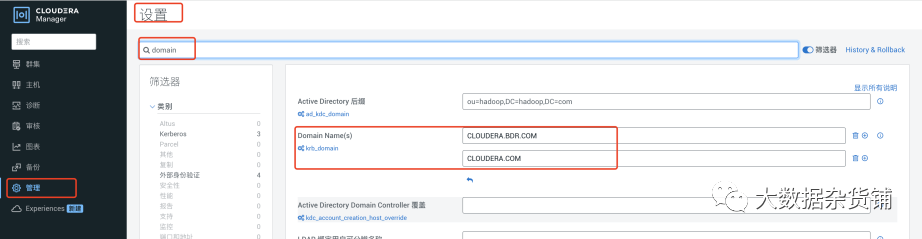
由于测试环境使用的源集群和目标集群使用的不同的KDC系统,因此需要进行集群互信配置,在目标CDP7.1.7集群中 CM页面>管理>设置>搜索DOMAIN,添加源CDP 7.1.7集群的Kerberos域,比如:CLOUDERA.BDR.COM,然后保存重启生效
然后重新测试连接性,注:该步骤只表明源集群和目标集群的CM域互信可以连接,并不代表可以进行数据复制,如两个集群使用的不同的域和KDC服务器,还需如下配置互信
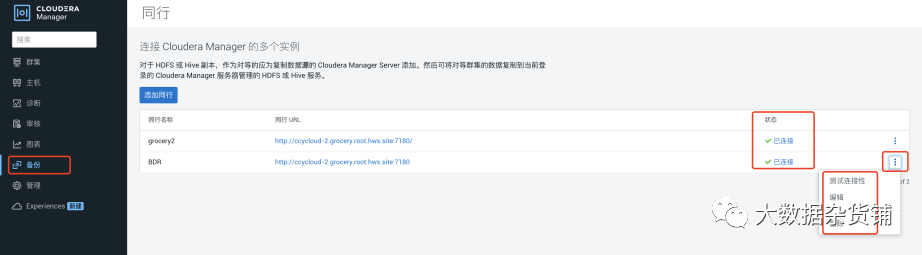
如果配置信息有问题,则可以点击编辑进行修改,然后再重新测试连接性。
集群互信配置
如已配置互信,此步骤可跳过,否则HDFS复制和Hive 复制将时会提示认证失败,配置步骤如下(以下操作均为在目标CDP7.1.7集群上操作):
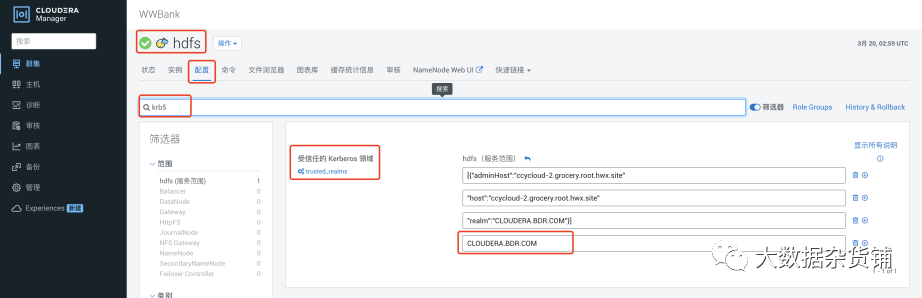
在CM界面>HDFS>配置>搜索krb5 > 添加受信任的Kerberos 域,如CLOUDERA.BDR.COM。这里也可以使用前面连接性测试提供的推荐配置。
在HDFS 配置中hdfs-site.xml的HDFS 服务高级配置(安全阈)中添加如下配置,该配置用于客户端的匹配规则用于控制允许的认证realms,如果该参数不配置,拷贝源集群数据时会出现无效的凭证异常,* 表示不限制 ,并保存重启生效
<property>
<name>dfs.namenode.kerberos.principal.pattern</name>
<value>*</value>
</property>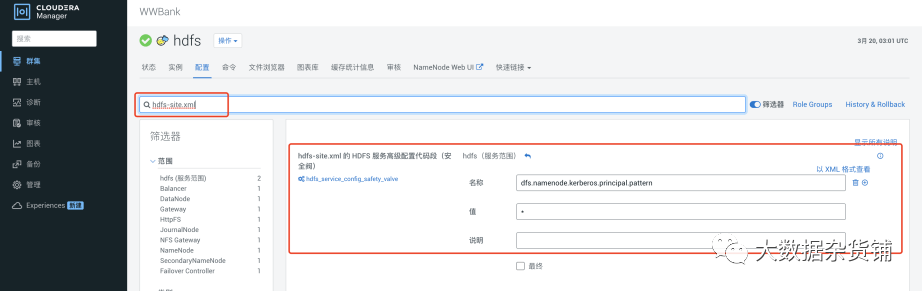
添加互信请求互信凭证
在源CDP7.1.7集群和CDP7.1.7集群中添加互相凭证,为了使跨域信任正常运行,两个KDC必须具有相同的krbtgt 主体和密码,并且两个KDC必须配置为使用相同的加密类型。
CLOUDERA.COM 为CDP7.1.7 集群的Kerberos域,CLOUDERA.BDR.COM为CDP7.1.7集群的域。
需要在KDC中设置跨领域信任,请在 kadmin.local 或者 kadmin shell KDC主机上的Shell创建完全相同的krbtgt主体和密码,执行如下语句,并将密码都设置为BadPass#1
addprinc -e "aes256-cts:normal aes128-cts:normal des3-hmac-sha1:normal arcfour-hmac:normal des-hmac-sha1:normal des-cbc-md5:normal des-cbc-crc:normal" krbtgt/CLOUDERA.BDR.COM@CLOUDERA.COM
addprinc -e "aes256-cts:normal aes128-cts:normal des3-hmac-sha1:normal arcfour-hmac:normal des-hmac-sha1:normal des-cbc-md5:normal des-cbc-crc:normal" krbtgt/CLOUDERA. COM@CLOUDERA.BDR.COM
目标CDP7.1.7集群 /etc/hosts 解析添加源CDP7.1.7集群的/etc/hosts 解析
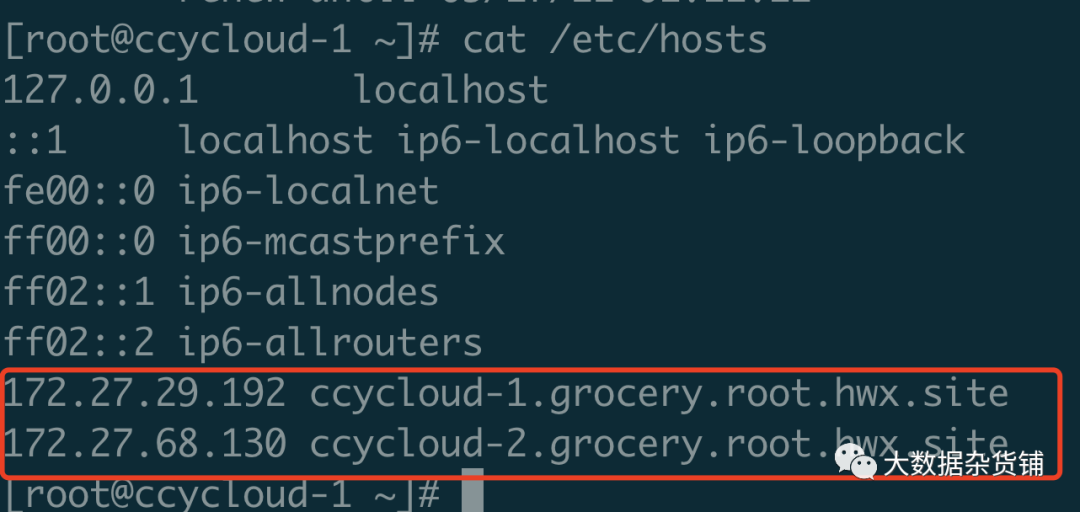
因为我这里都是单节点集群,且都在同一个内网中且使用DNS进行IP和主机管理,因此可以不配置该步骤。跨网络或者使用hosts文件进行的主机管理,则需要配置该hosts文件,并将/etc/hosts文件分发给集群中所有的主机。
并修改/etc/krb5.conf 配置复制到集群所有节点,添加如下标红字体配置
includedir /etc/krb5.conf.d/[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log[libdefaults]
dns_lookup_realm = false
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
rdns = false
pkinit_anchors = /etc/pki/tls/certs/ca-bundle.crt
default_realm = CLOUDERA.COMdefault_ccache_name = KEYRING:persistent:%
[realms]
CLOUDERA.COM = {
kdc = ccycloud-1.grocery.root.hwx.site
admin_server = ccycloud-1.grocery.root.hwx.site
}
CLOUDERA.BDR.COM = {
kdc = ccycloud-2.grocery.root.hwx.site
admin_server = ccycloud-2.grocery.root.hwx.site
default_domain=CLOUDERA.BDR.COM
}
[domain_realm]
.ccycloud-1.grocery.root.hwx.site = CLOUDERA.COM
ccycloud-1.grocery.root.hwx.site = CLOUDERA.COM
.ccycloud-2.grocery.root.hwx.site = CLOUDERA.BDR.COM
ccycloud-2.grocery.root.hwx.site = CLOUDERA.BDR.COM
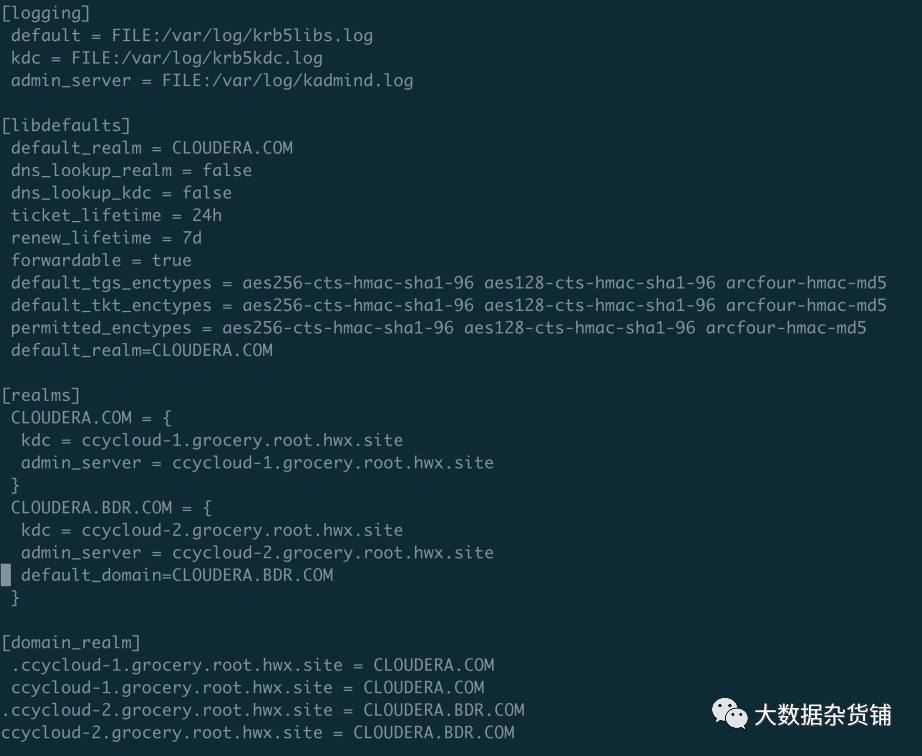
执行互信配置成功后的验证
使用源集群也就是CDH7集群的凭证在目标CDP7集群中认证,然后执行HDFS命令查看如CLOUDERA.COM 为CDP7.1.7 集群的Kerberos域,CLOUDERA.BDR.COM为源CDH7.1.7集群的域
#需确认在源CDP7集群中有etl_user的用户凭证,并且有相关权限
kinit etl_user@CLOUDERA.BDR.COM
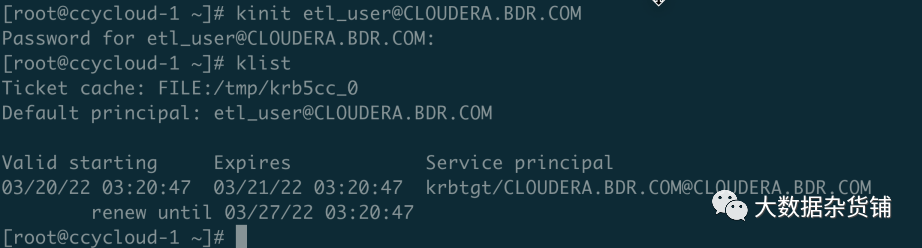
两个集群都能正常访问表示互相配置成功,

添加RM 执行用户
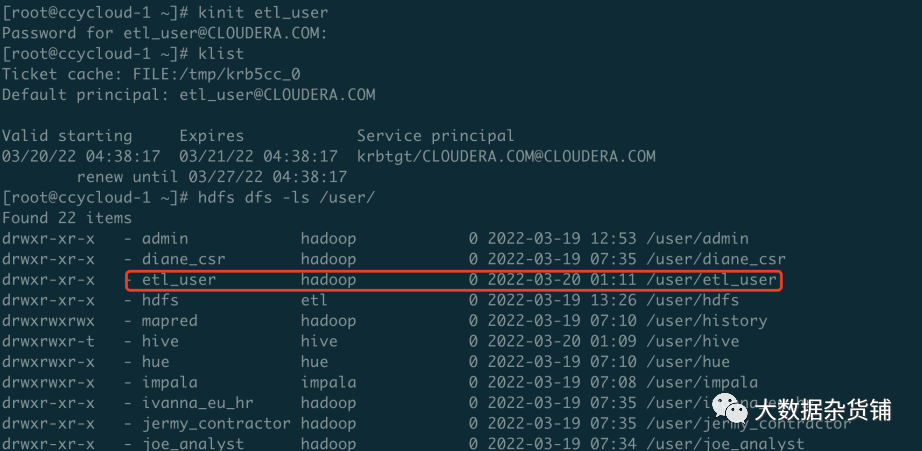
由于RM执行时需要较大的权限,因此建议添加一个专用于执行复制计划的用户,如etl_user,并且添加到hadoop组。在目标CDP7.17集群中,添加用户,命令如下
useradd etl_user
id etl_user
usermod -G hadoop etl_user
echo BadPass#1|passwd --stdin etl_user需要在目标集群和源集群的所有机器上添加该用户,推荐使用批量程序进行。创建etl_user的HDFS 目录,用户属组为etl_user:hadoop
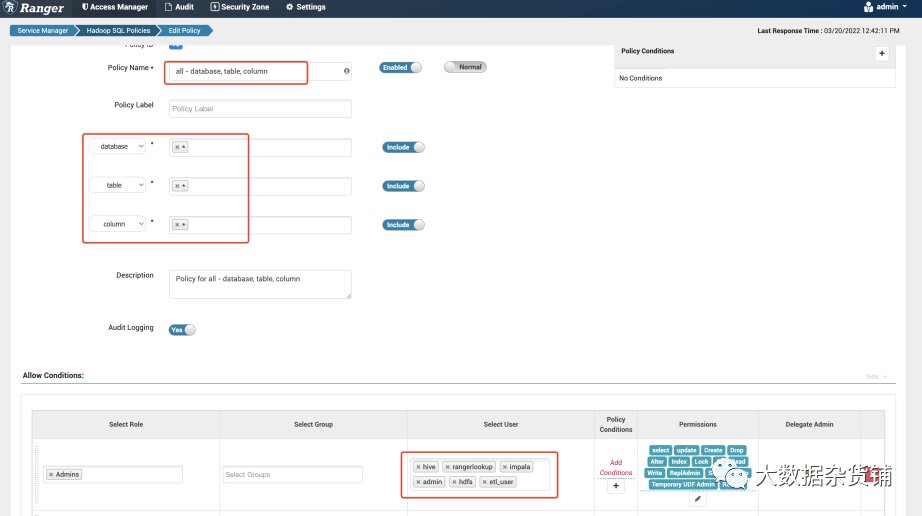
目标集群中在Ranger 中授权,HDFS 的权限策略如下,跟hdfs 用户权限一致,在所有hdfs的路径上都有所有权限。

Hive 中权限策略如下:注:hdfs与etl_user两用户都需要有all - database, table, column的权限,否则Hive 的复制计划执行到hive metastore 检查这一步将报错。
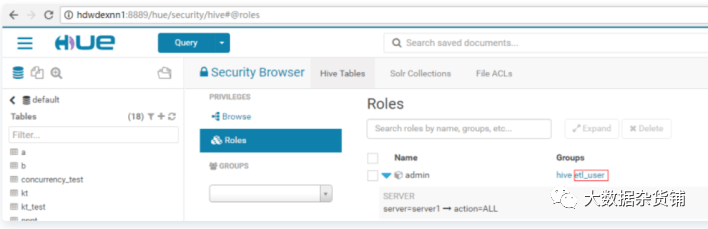
源集群中也需要添加etl_user,如果是CDP集群,则和目标集群设置相同权限(在Ranger中赋权),如果是CDH集群,则通过sentry给etl_user所有Hive表的权限,etl_user为我们执行Hive 复制计划中所使用的用户,所以在目标和源集群中都需要有对应的权限
HDFS、Hive 复制
HDFS复制验证
配置HDFS 的复制计划,在目标集群的CM界面>备份>复制计划 中点创建计划

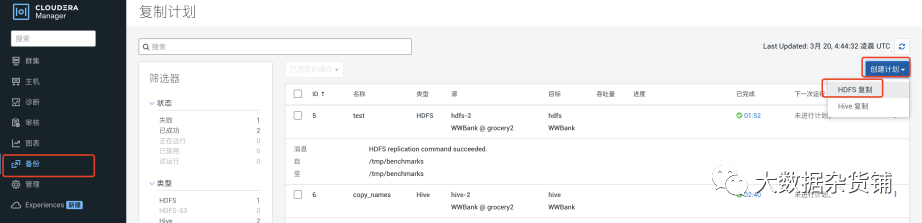
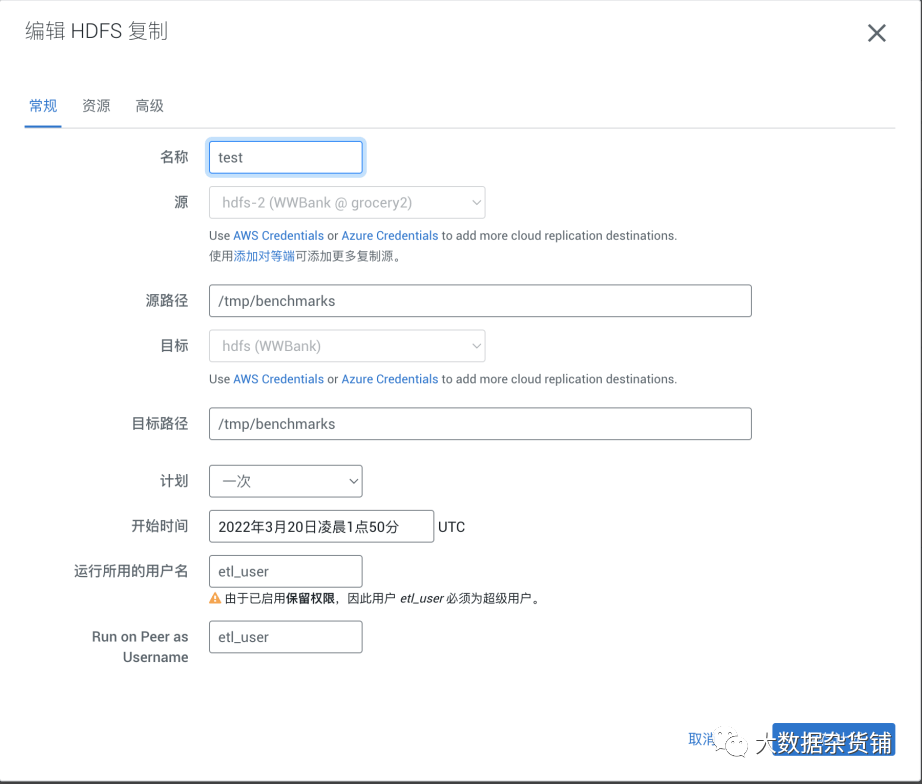
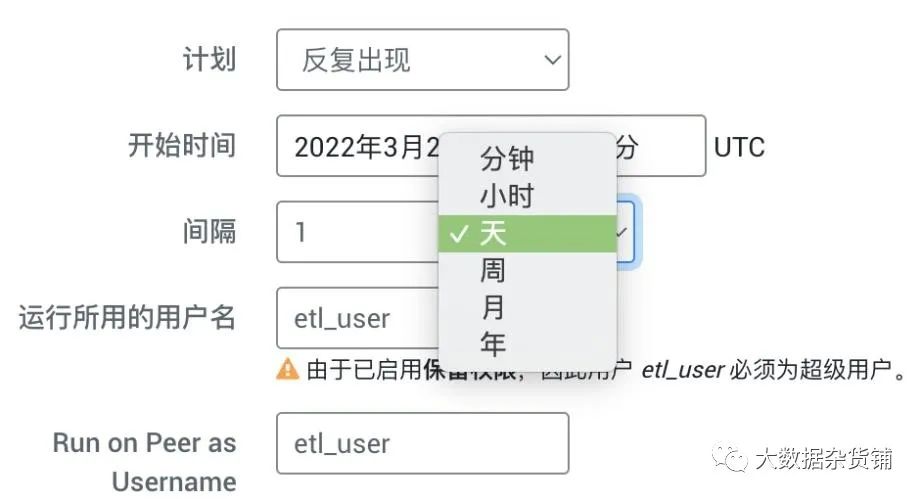
计划中可以选择时间周期,本次测试设置为手动执行1次。周期性的数据同步可选择不同粒度的间隔周期进行数据复制。
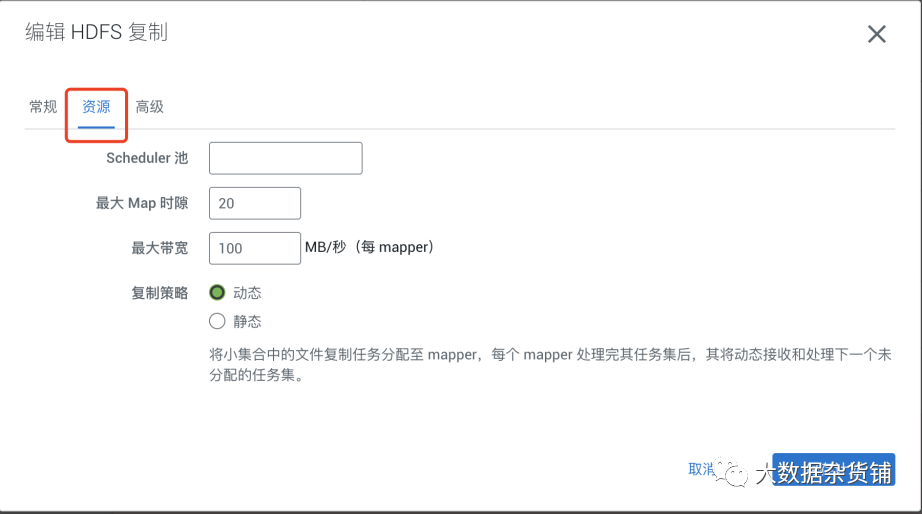
也可以配置HDFS复制的资源和高级设置,这样可以更好的控制资源使用和配置。
资源页面主要控制使用的资源池、最大的Map数及允许使用的最大带宽,复制策略也可以根据需求选择静态和动态。
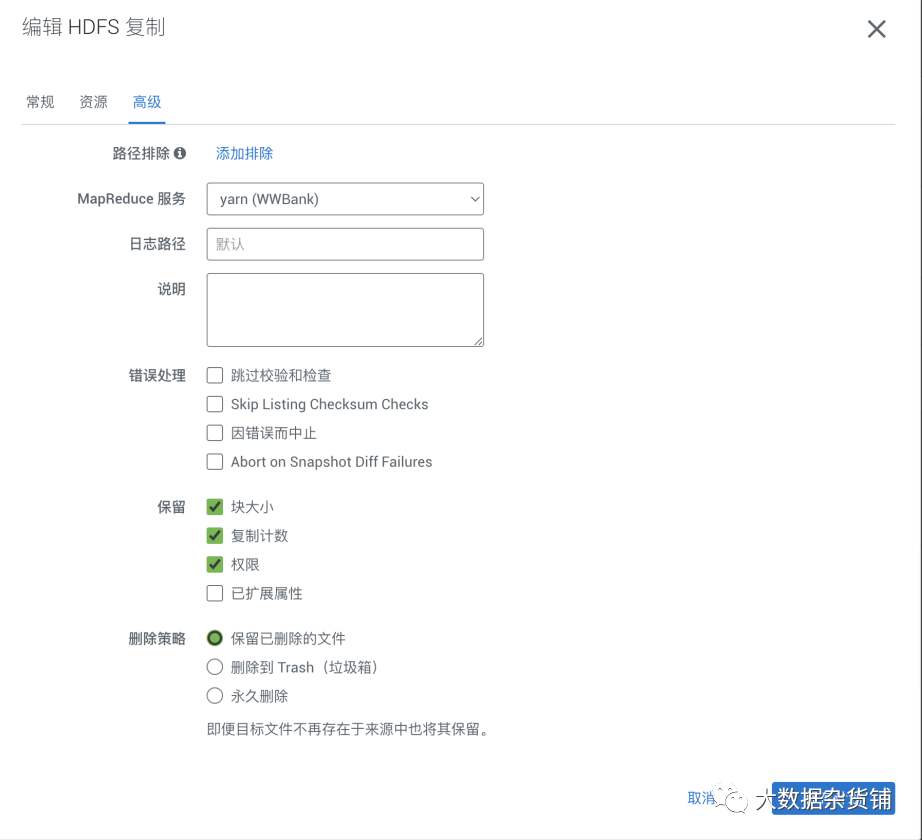
在高级设置中会配置使用的MR服务,日志路径,错误处理、数据保留策略、删除策略、预警等内容。
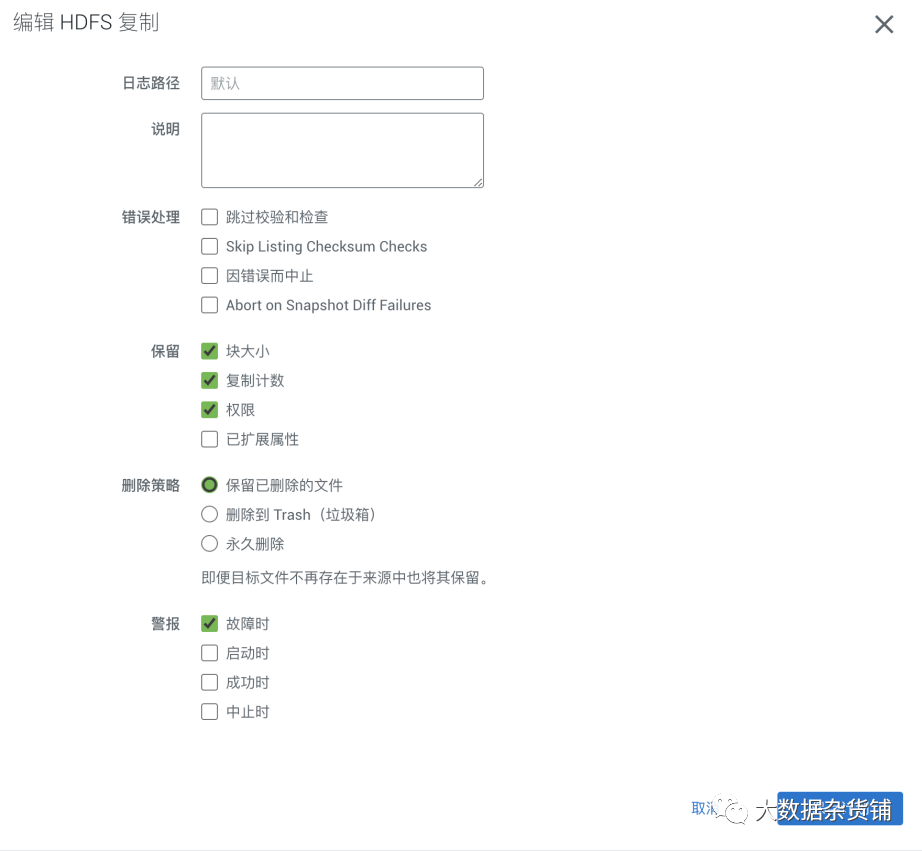
保存计划后点击运行

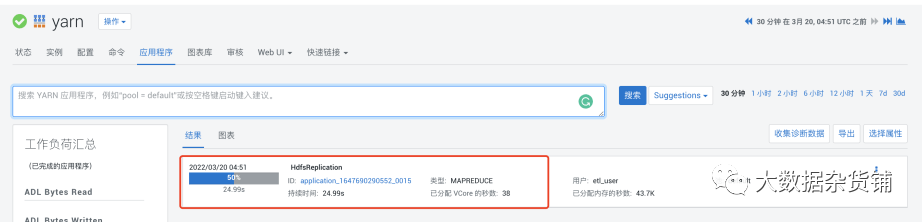
在CM 的YARN 应用程序中可以看到生成了一个MR作业,如官网解释其本质是一个distcp 作业,完成后的CDP集群
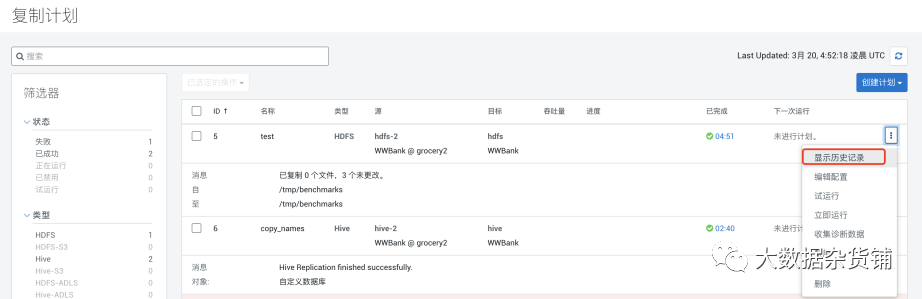
在复制任务右侧提供了一些功能,例如查看历史记录、修改配置、禁用等。
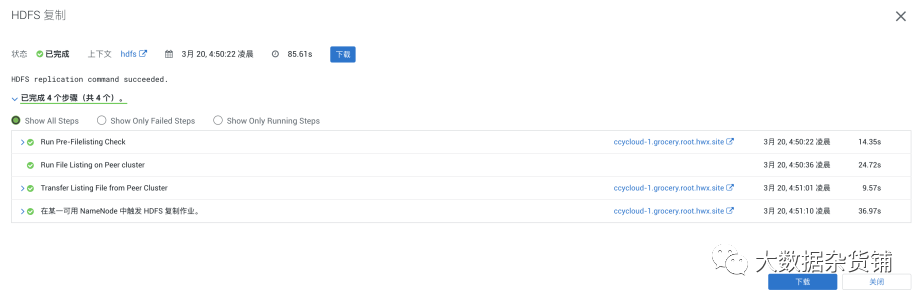
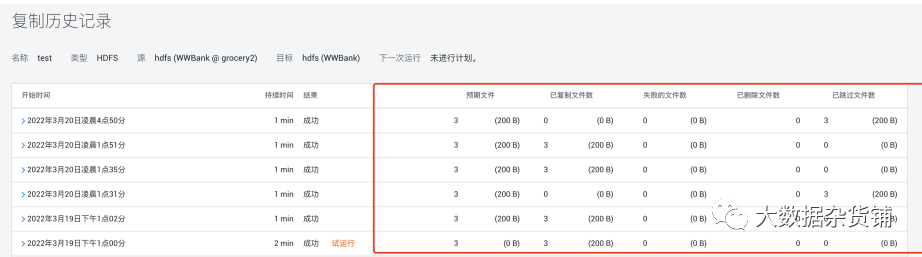
任务执行完成后可以查看历史记录
包含每次执行的信息统计
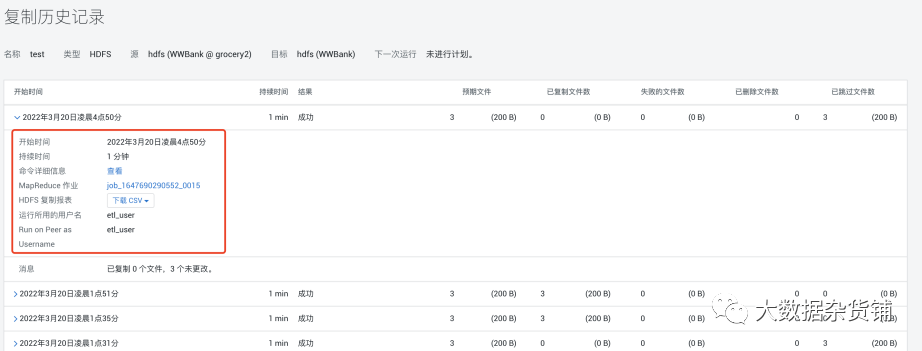
可以展开一次执行记录,查看详情
Hive复制验证
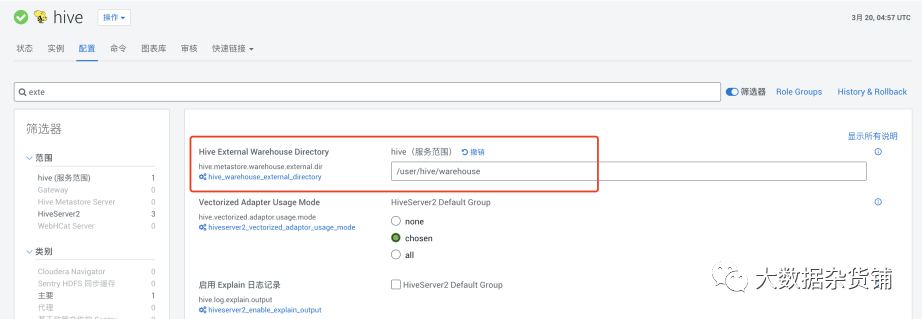
首先在CDP中将Hive 中的外部表的默认路径修改为/user/hive/warehouse,这也是官网建议的做法,这样原有 CDH5 应用代码可以做到无感知运行。
如果是CDP到CDP的同步,则不需要进行调整。
如果希望将相同的数据库从 Hive1 复制到 Hive3(设计上使用不同的 Hive 仓库 目录),则需要针对每个策略使用“强制覆盖”选项,以避免出现不匹配问题。对于CDP到CDP集群,则不需要使用“强制覆盖”选项。
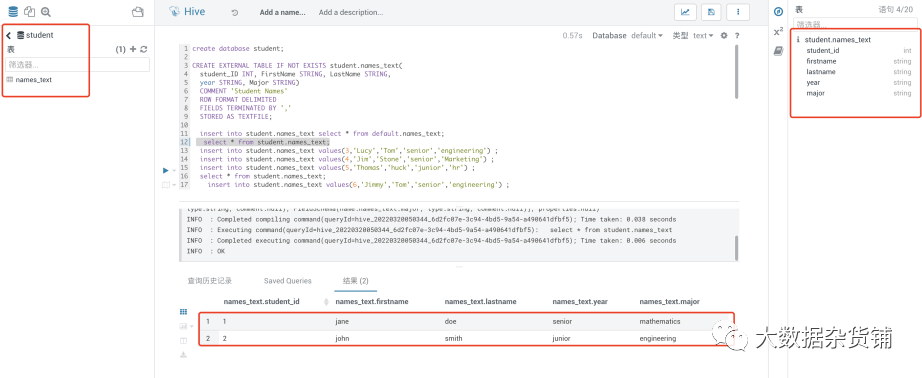
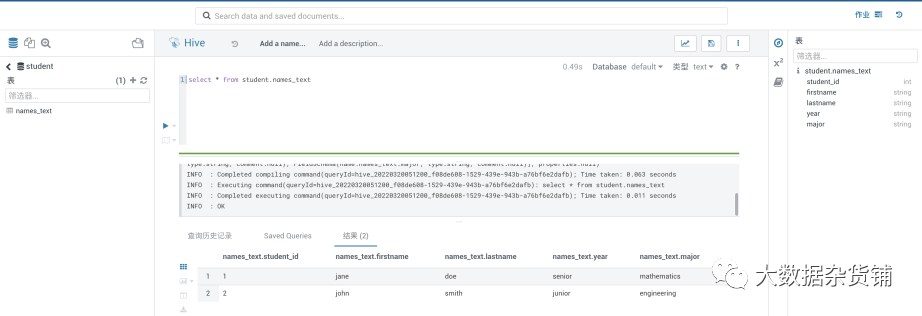
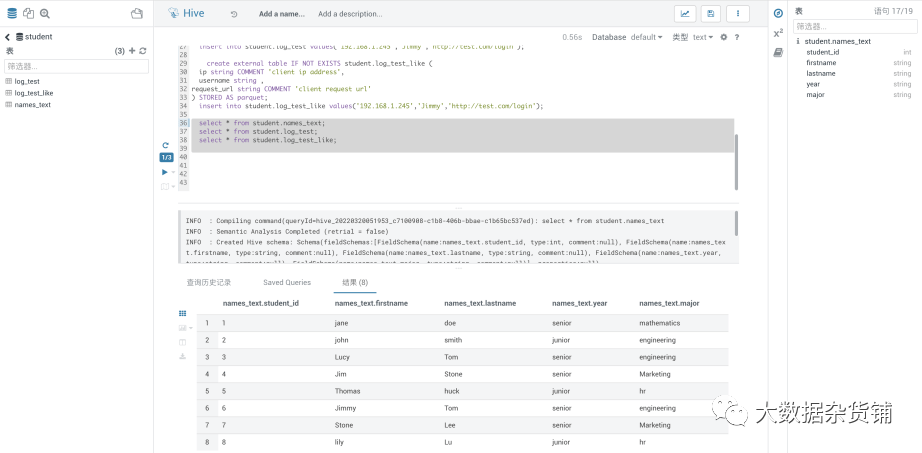
在源CDP7.1.7集群中创建一个测试库student和表student.names_text,并在表中准备了两条记录
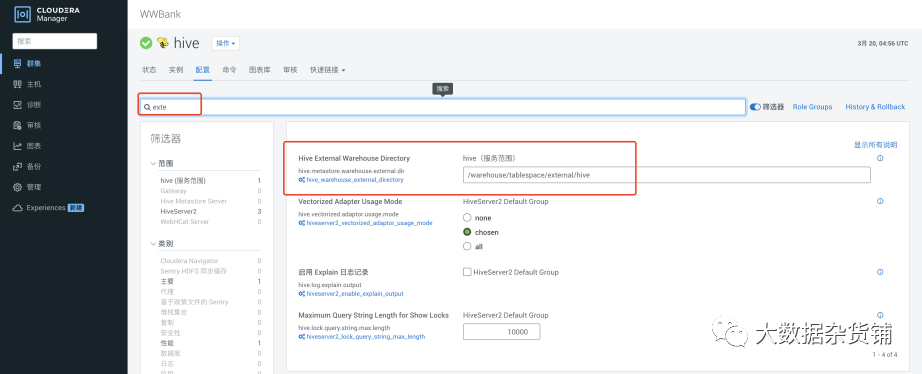
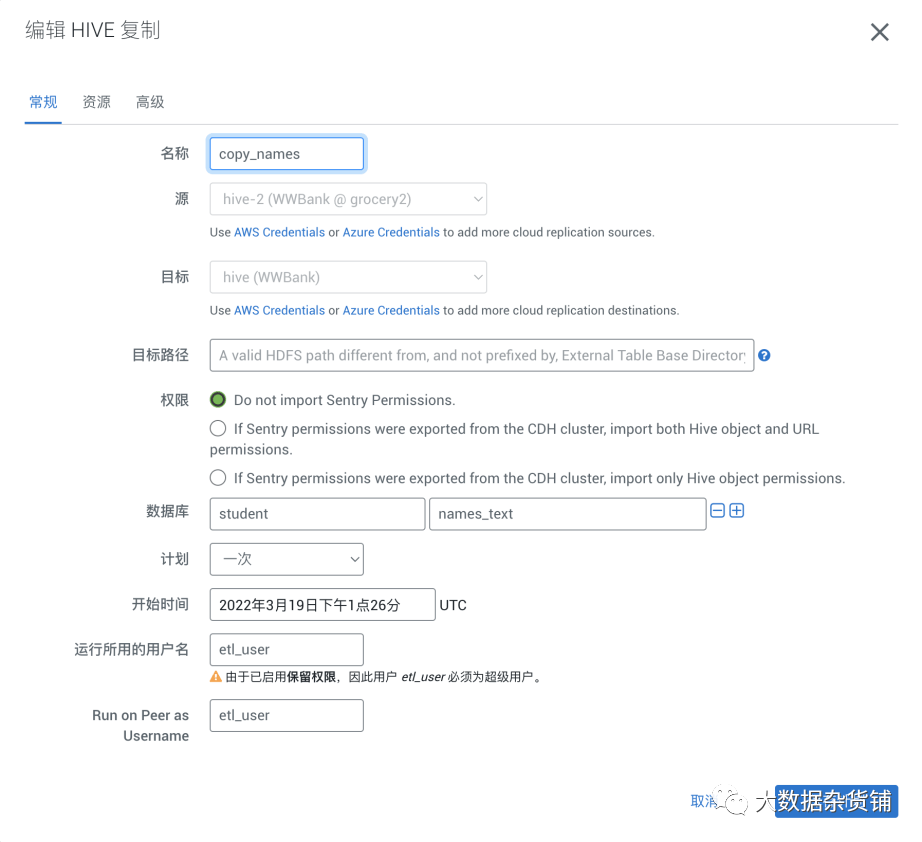
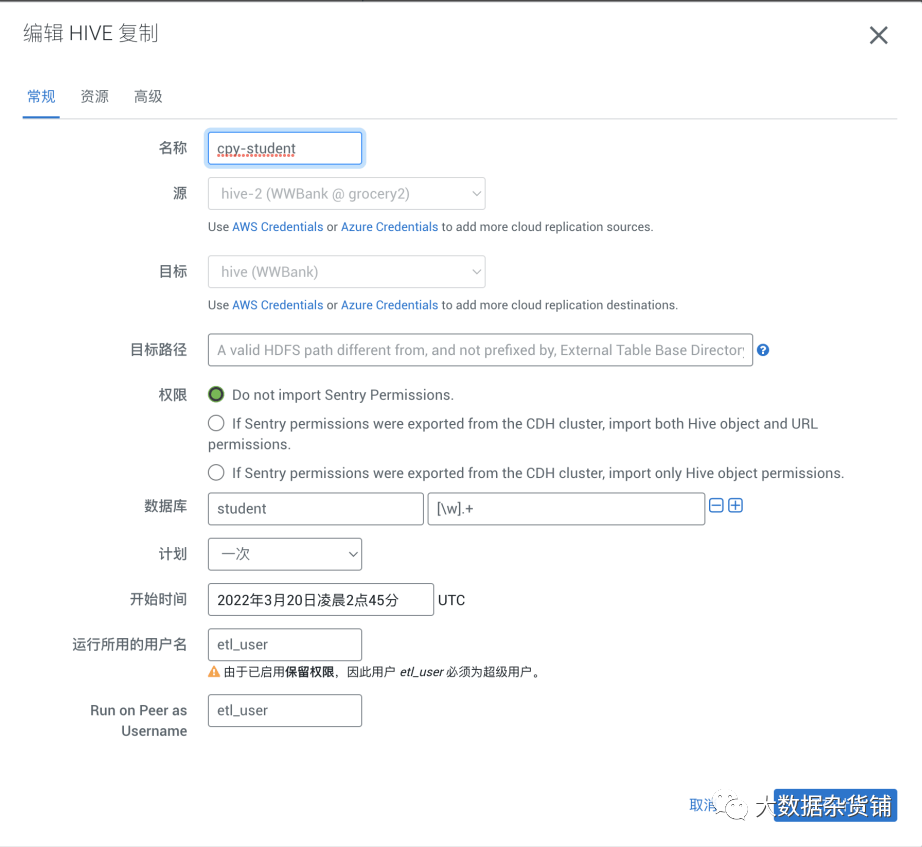
在目标CDP集群创建复制计划,目标路径不填默认为Hive 中指定的外部表路径,hive.metastore.warehouse.external.dir ,对于源是CDH的集群,建议修改为/user/hive/warehouse与CDH的内部表路径保持一致。对于源是CDP的集群,不需要做任何调整。
在资源中可选择运行的资源池以及带宽和MAP数量
在高级配置中可配置部分参数由于更快的运行,详细可参考官网文档
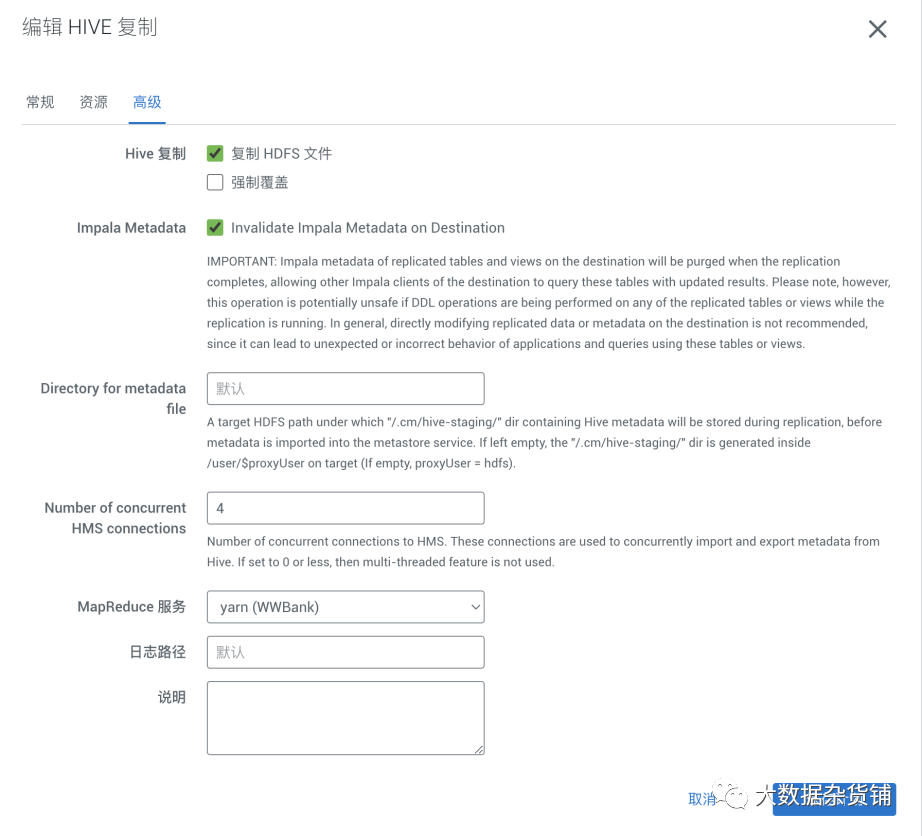
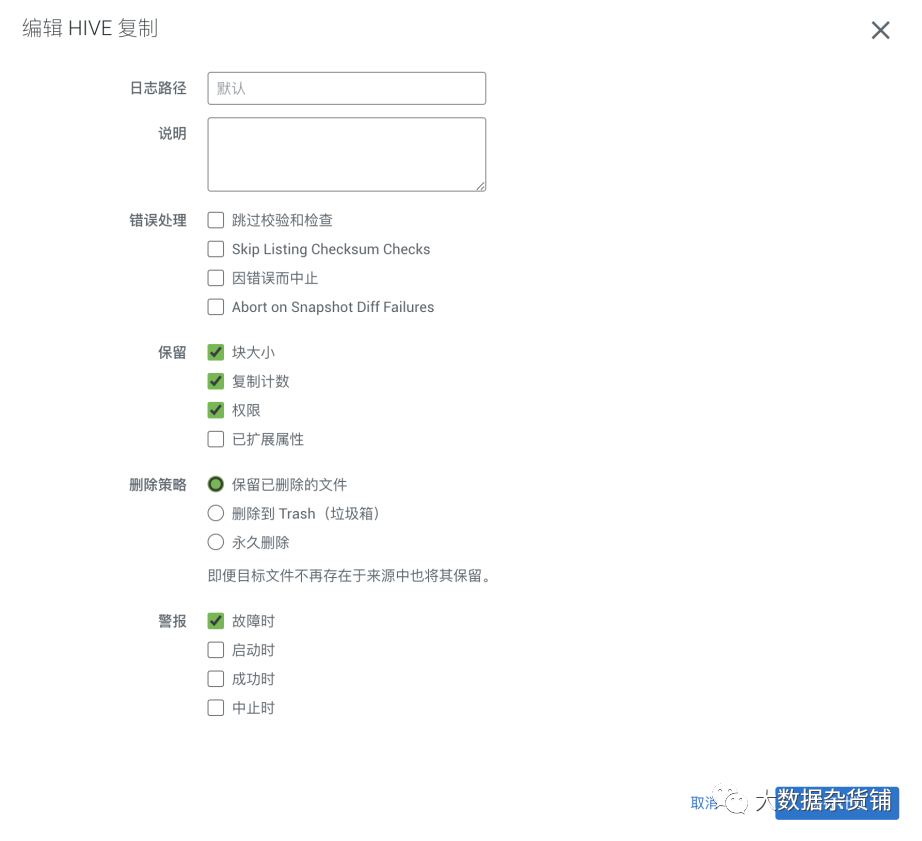
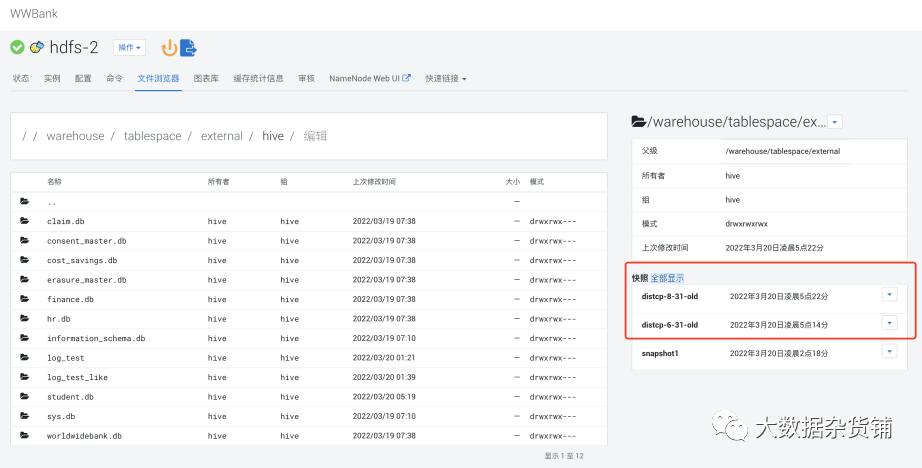
建议启用快照 ,启用快照也是后续做增量同步的前提条件。
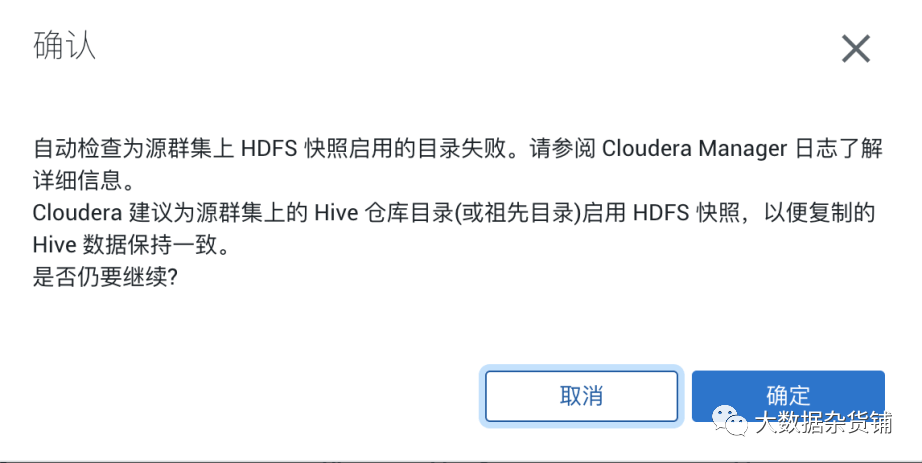
在源集群中通过hdfs的文件浏览器启用快照
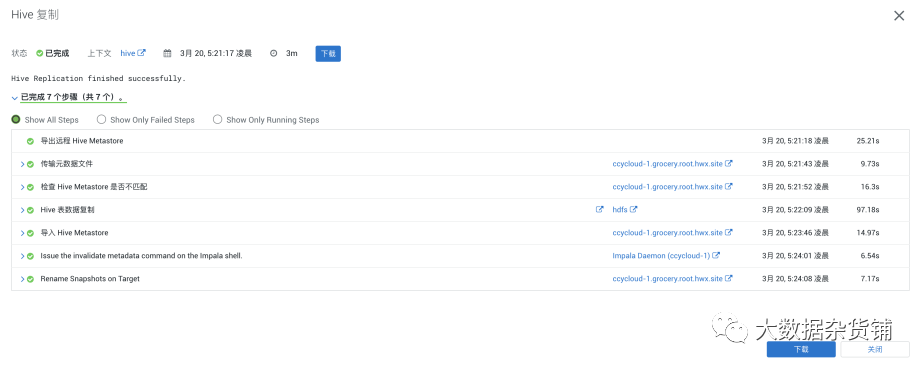
点运行查看日志

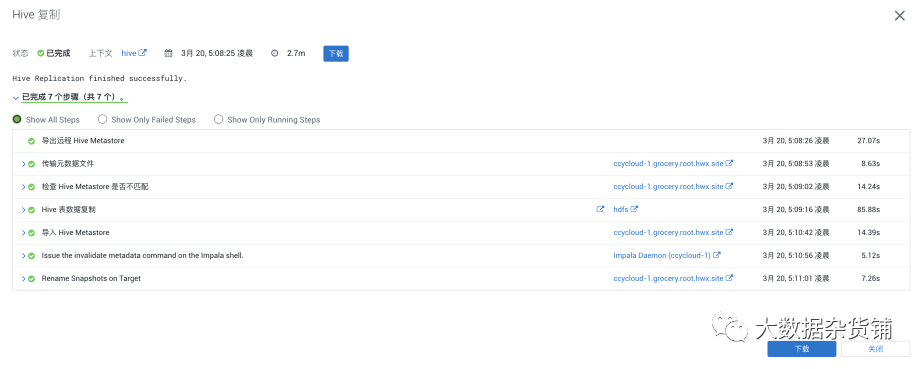
在目标集群中通过hue进行查询验证:
原表中增加3条数据,进行增量更新验证
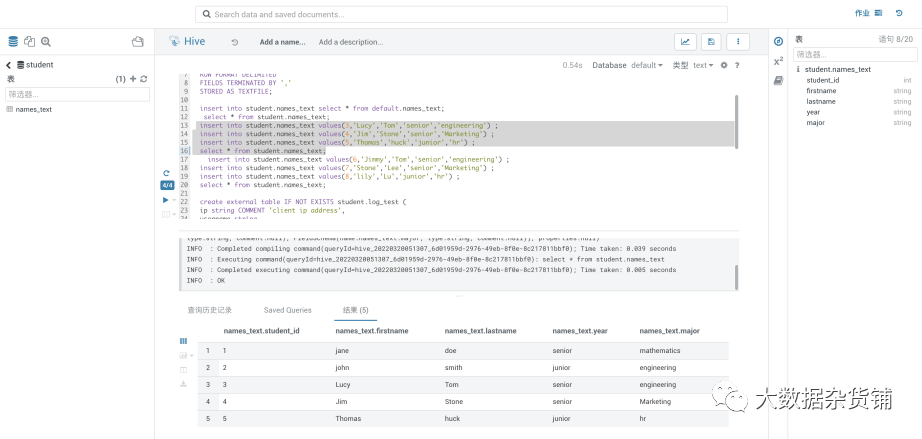
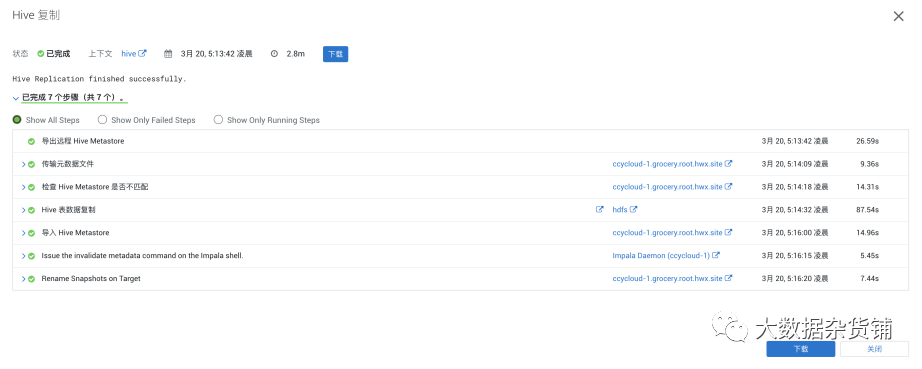
再次执行同一个复制计划
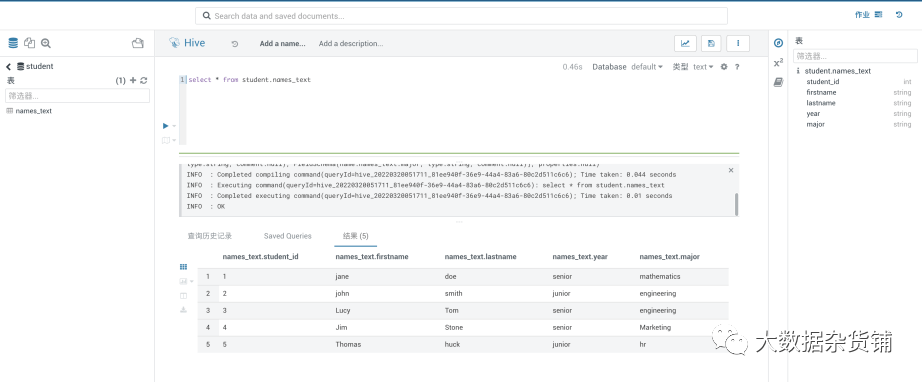
在目标CDP集群中通过hue查看,发现增量数据已更新
添加两个空表并分别添加一条记录,并在name_text中追加三条数据做全库增量更新验证。分别添加了一个ORC和Parquet表。
RM中支持正则表达式匹配。例如:[\w].+ 表示匹配任何对象
(?!myname\b).+ 表示匹配除了 myname 以外的对象
db1|db2 表示匹配 db1 或者 db2
通过hue查看验证已全部同步
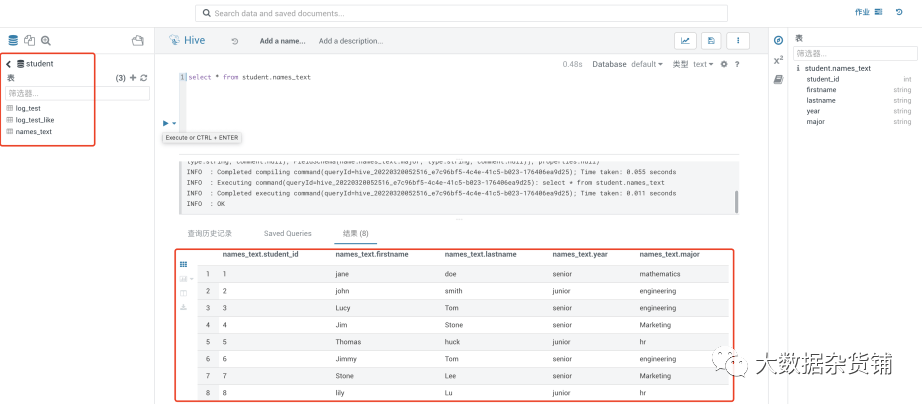
还可以查看历史记录,例如从历史记录中可以看到Hive全量和增量同步信息:

在源集群启用快照后,RM任务会自己拍摄快照,并将比较老的快照进行清理,在数据同步时通过快照比较找出增量,进行增量同步。
异常处理
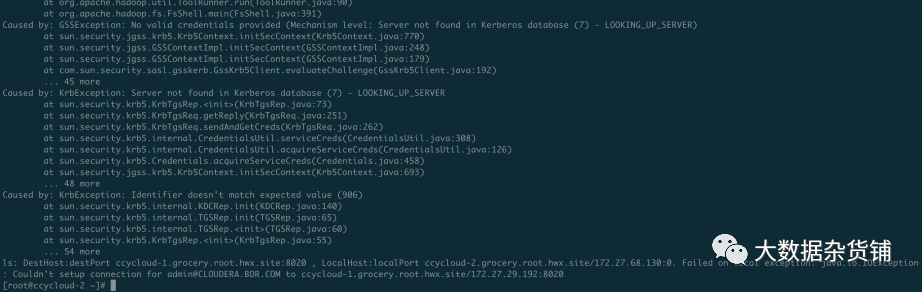
kinit 认证成功,但是访问源集群HDFS失败的问题。
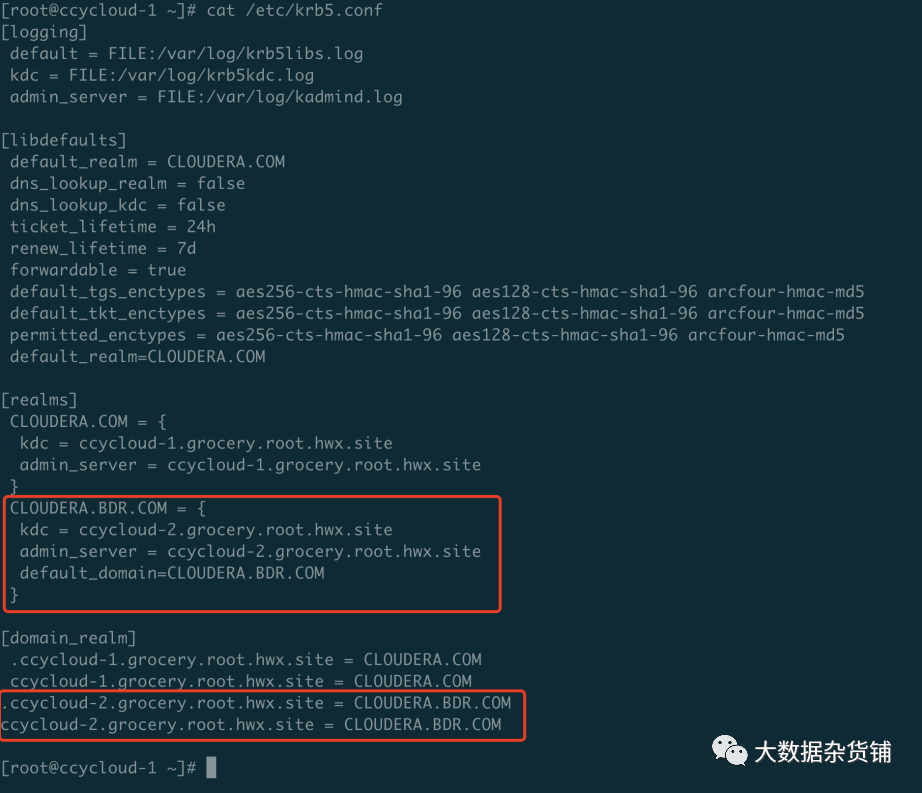
在配置/etc/hosts 的时候hostsname 使用的是非FQDN格式,导致在只添加了源集群KDC 主机在/etc/krb5.conf 中,并且kdc的主机与NameNode是不同的机器,解决的方式是将NameNode 的域配置添加到/etc/krb5.conf 中,如下图所示的ccycloud-2.grocery.root.hwx.site = CLOUDERA.BDR.COM
异常如下:

Hive 复制出现Database 和Table not found 问题
在目标集群上 CM > HDFS > Configuration > HDFS Client Advanced Configuration Snippet (Safety Valve) for hdfs-site.xml 添加下面的参数,并重启生效:
<property>
<name>replication.hive.ignoreDatabaseNotFound</name>
<value>true</value>
</property>
<property>
<name>replication.hive.ignoreTableNotFound</name>
<value>true</value>
</property>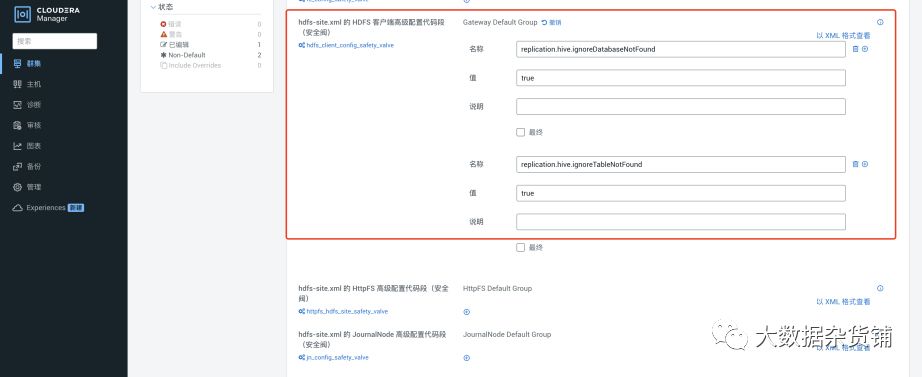
结尾
Replication Manager是Cloudera Manager提供的一个集成的、易于使用的管理解决方案,用于在Hadoop平台上实现数据保护。Replication Manager使您可以跨数据中心复制数据以进行灾难恢复方案。复制可以包括存储在HDFS中的数据,存储在Hive表中的数据,Hive Metastore数据以及与在Hive Metastore中注册的Impala表关联的Impala元数据(目录服务器元数据)。当关键数据存储在HDFS上时,Cloudera Manager可以帮助确保即使在数据中心完全关闭的情况下,数据也始终可用。
附录
Hue中运行的SQL代码:
create database student;CREATE EXTERNAL TABLE IF NOT EXISTS student.names_text(
student_ID INT, FirstName STRING, LastName STRING,
year STRING, Major STRING)
COMMENT 'Student Names'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;insert into student.names_text select * from default.names_text;
select * from student.names_text;
insert into student.names_text values(3,'Lucy','Tom','senior','engineering') ;
insert into student.names_text values(4,'Jim','Stone','senior','Marketing') ;
insert into student.names_text values(5,'Thomas','huck','junior','hr') ;
select * from student.names_text;
insert into student.names_text values(6,'Jimmy','Tom','senior','engineering') ;
insert into student.names_text values(7,'Stone','Lee','senior','Marketing') ;
insert into student.names_text values(8,'lily','Lu','junior','hr') ;
select * from student.names_text;create external table IF NOT EXISTS student.log_test (
ip string COMMENT 'client ip address',
username string ,
request_url string COMMENT 'client request url'
) STORED AS ORC;
insert into student.log_test values('192.168.1.245','Jimmy','http://test.com/login');create external table IF NOT EXISTS student.log_test_like (
ip string COMMENT 'client ip address',
username string ,
request_url string COMMENT 'client request url'
) STORED AS parquet;
insert into student.log_test_like values('192.168.1.245','Jimmy','http://test.com/login');
select * from student.names_text;
select * from student.log_test;
select * from student.log_test_like;