当前市场上常见的容灾模式可分为同城容灾、异地容灾、双活 数据中心、两地 三中心几种。
1、 同城 容灾
同城 容灾 是在同城或相近区域内 ( ≤ 200K M )建立两个数据中心 : 一个为数据中心,负责日常生产运行 ; 另一个为灾难备份中心,负责在灾难发生后的应用系统运行。同城灾难备份的数据中心与灾难备份中心的距离比较近,通信线路质量较好,比较容易实现数据的同步 复制 ,保证高度的数据完整性和数据零丢失。同城灾难备份一般用于防范火灾、建筑物破坏、供电故障、计算机系统及人为破坏引起的灾难。
2、 异地 容灾
异地 容灾 主备中心之间的距离较远 (> 200KM ) , 因此一般采用异步镜像,会有少量的数据丢失。异地灾难备份不仅可以防范火灾、建筑物破坏等可能遇到的风险隐患,还能够防范战争、地震、水灾等风险。由于同城灾难备份和异地灾难备份各有所长,为达到最理想的防灾效果,数据中心应考虑采用同城和异地各建立一个灾难备份中心的方式解决。
本地容灾 是指在本地机房建立容灾系统,日常情况下可同时分担业务及管理系统的运行,并可切换运行;灾难情况下可在基本不丢失数据的情况下进行灾备应急切换,保持业务连续运行。与异地灾备模式相比较,本地双中心具有投资成本低、建设速度快、运维管理相对简单、可靠性更高等优点;异地灾备中心是指在异地建立一个备份的灾备中心,用于双中心的数据备份,当双中心出现自然灾害等原因而发生故障时,异地灾备中心可以用备份数据进行业务的恢复。
本地机房的容灾主要是用于防范生产服务器发生的故障,异地灾备中心用于防范大规模区域性灾难。本地机房的容灾由于其与生产中心处于同一个机房,可通过局域网进行连接,因此数据复制和应用切换比较容易实现,可实现生产与灾备服务器之间数据的实时复制和应用的快速切换。异地灾备中心由于其与生产中心不在同一机房,灾备端与生产端连接的网络线路带宽和质量存在一定的限制,应用系统的切换也需要一定的时间,因此异地灾备中心可以实现在业务限定的时间内进行恢复和可容忍丢失范围内的数据恢复。
3、 两地 三中心
结合近年国内出现的大范围自然灾害,以同城双中心加异地灾备中心的 “两地三中心”的灾备模式也随之出现,这一方案兼具高可用性和灾难备份的能力。
同城双中心 是指在同城或邻近城市建立两个可独立承担关键系统运行的数据中心,双中心具备基本等同的业务处理能力并通过高速链路实时同步数据,日常情况下可同时分担业务及管理系统的运行,并可切换运行;灾难情况下可在基本不丢失数据的情况下进行灾备应急切换,保持业务连续运行。与异地灾备模式相比较,同城双中心具有投资成本低、建设速度快、运维管理相对简单、可靠性更高等优点。
异地灾备中心 是指在异地的城市建立一个备份的灾备中心,用于双中心的数据备份,当双中心出现自然灾害等原因而发生故障时,异地灾备中心可以用备份数据进行业务的恢复。
两地三中心 : 是指 同城双中心 加 异地灾备 一种商用容灾备份解决方案;
两地 是指同城、异地;
三中心 是指生产中心、同城容灾中心、异地容灾中心。( 生产中心、同城灾备中心、异地 灾备 中心 )
4、 双活 数据中心
所谓 “ 双活 ” 或 “ 多 活 ” 数据中心,区别于 传统 数据中心 和 灾备中心的模式,前者 多个 或两个数据中心都处于运行当中, 运行相同的应用,具备同样的数据,能够提供跨中心业务负载均衡运行能力,实现持续的应用可用性和灾难备份能力, 所以称为 “双活 ” 和 “ 多 活 ” ;后者是 生产 数据中心投入运行, 灾备 数据中心处在不工作状态,只有当灾难发生时,生产数据中心瘫痪,灾备中心才启动。
“ 双活 ” 数据中心最大的特点是 : 一、充分利用资源,避免了一个数据中心常年处于闲置状态而造成浪费 , 通过资源整合, “ 双活 ” 数据中心的服务能力是 翻 倍的 ; 二 、 “ 双活 ” 数据中心如果断了一个数据中心, 其 业务可以 迅速 切换到另外一个 正在 运行的数据中心, 切换 过程对用户来说是不可感知的。
在 “ 双活 ” 的模式中,两地数据中心同时接纳交易,技术难度很大,需要更改众多底层程序 , 因而在现实中,国内还没有 真正 “ 双活 ” 数据中心 的成功 应用 案例。
数据容灾技术选择度量标准
在构建 容灾 系统时,首先考虑的是结合实际情况选择合理的数据复制技术。 在 选择合理的数据复制技术时主要考虑以下因素:
Ø 灾难承受程度 :明确计算机系统需要承受的灾难类型,系统故障、通信故障、长时间断电、火灾及地震等各种意外情况所采取的备份、保护方案不尽相同。
Ø 业务影响程度 :必须明确当计算机系统发生意外无法工作时,导致业务停顿所造成的损失程度,也就是定义用户对于计算机系统发生故障的最大容忍时间。这是设计备份方案的重要技术指标。
Ø 数据保护程度 :是否要求数据库恢复所有提交的交易 , 并且要求实时同步 ,保证 数据的连续性和一致性, 这是 备份方案复杂程度的重要依据。
对IT企业来说,传统的单数据中心,已不足以保护企业数据的安全。当单数据中心存储故障后,可能会导致业务长时间中断,甚至数据丢失。只做本地的数据冗余保护或容灾建设,已不能规避区域性灾难对企业数据的破坏。远程容灾保护数据及保障企业业务连续性成为了企业亟待解决的问题。另外,企业在远程容灾建设中,也面临网络链路租赁费用高昂和网络带宽不够的问题。
2.“两地三中心”的架构实践
(1)华为的“基于华为统一存储多级跳复制技术的两地三中心方案”
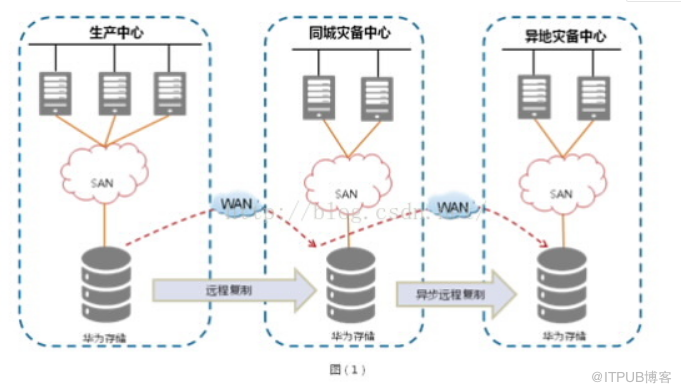
基于华为统一存储多级跳复制技术,并结合专业的容灾管理软件实现数据的两地三中心保护。该方案在生产中心、同城灾备中心和异地灾备中心分别部署华为OceanStor统一存储设备,通过异步远程复制技术,将生产中的数据复制到同城灾备中心,再到异地灾备中心,实现数据的保护,方案原理组网如图(1)所示。若生产中心发生灾难,可在同城灾备中心实现业务切换,并保持与异地灾备中心的容灾关系;若生产中心和同城灾备中心均发生灾难,可在异地灾备中心实现业务切换。
(2)中兴通讯的“基于云计算IaaS和PaaS层面的云计算技术,推出分布式双活数据中心”
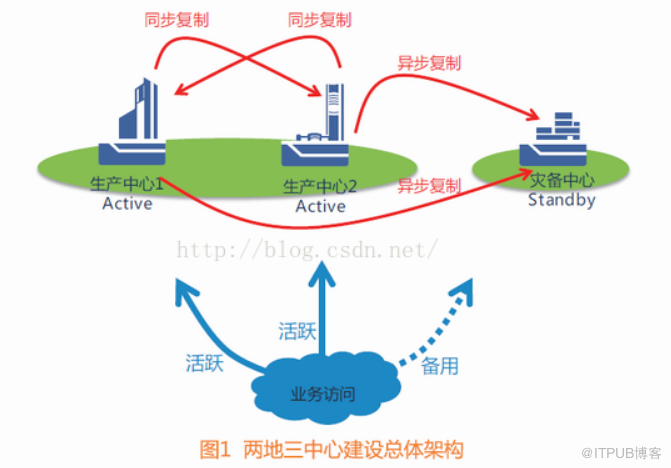
中兴的分布式双活数据中心的建设和部署架构如下图所示,在同城建设两个数据中心,同时为外提供业务服务,同时在异地建设灾备中心,用于数据的备份。中兴通讯分布式双活数据中心方案可以帮助客户找到优化投资利用率、保证业务连续性的新思路。
数据库容灾-没有最好,只有最适合
继911之后,四川大地震又一次给数据中心工作者上了一堂鲜活的安全教育课,眼睁睁看着一些企业由于关键业务数据遭到破坏导致整个企业的破产,也许这个时候那些平日一直认为IT是只花钱不赚钱的CXO们才能深刻感觉到数据是企业生命的真谛所在。“容灾”-这几年一直是IT厂商在炒作的热门概念,似乎每个人都想在这块大蛋糕上分享一块。随之而来的是花样繁多的容灾解决方案,存储厂商、主机厂商、虚拟带库厂商、数据库复制厂商、数据库厂商纷纷踏入这片热门地带。软件容灾、硬件容灾、数据级容灾、应用级容灾、低成本、异构性、高可扩展性。。。,看起来似乎每个方案都有自己独有的优势,每个厂商都可以找出充分的论据来证明为什么自己的解决方案是最适合的,用户的大脑也很容易在扑面而来的洗脑风暴中失去判断力,最能忽悠的往往成为最终的胜利者。
如何为企业选择一个最优的容灾解决方案?投资最多的方案就是最安全、最满足实际需求的吗?显然答案是否定,应该说容灾方案没有最好,只有最适合。选择方案时需要考虑多方面因素:投资、复杂度、可行性、可管理性、可扩展性、RPO、RTO。。。下面就对几种主流的数据库容灾方案进行分析,希望能在容灾方案选型阶段给大家一点思路。
基于存储的复制方案
典型代表:EMC SRDF ,HDS Truecopy,IBM PPRC,任何数据中心的建立都离不开磁盘阵列,所以这些厂商也就有机会在第一时间给客户灌输自己基于阵列的容灾方案,在市场上的声音也是最大的。但他们在设计方案的时候往往更多地考虑如何让用户多买阵列,而不是将旧阵列加以重用。
方案优势:同步异步方式可供选择,数据同步过程不占用主机资源,带宽利用率高。
方案限制:生产中心与灾备中心必须选择同品牌同级别的盘阵,也就是要绑死一家厂商,商务上很容易处于被动状态,拿不到好折扣,将来的扩容也没有其他选择。数据同步过程中灾备中心处于standby状态,不能进行任何读写操作,即使使用高端盘阵也只能在灾难发生时才能发挥体会到其优越的处理能力,造成资源浪费。需要建立光纤网作为复制链路,又是一笔不小的费用。在存储级定制复制策略,无法在操作系统级控制和分辨复制内容,不管是数据库还是普通文件统统进行全盘复制,而无法进行应用区分,即使是一些不需要复制的文件也不能进行筛选,浪费带宽、浪费存储。
基于卷的复制技术
典型代表:Veritas Volume Replicator
方案优势:IP网作为复制链路,成本低,不受距离限制,以卷作为复制对象,可以实现数据库和普通文件的容灾,支持异构存储。
方案限制:需要复制的数据库和文件必须建立在Veritas Volume Manager之上,即使是已经上线的系统也必须要进行数据的迁移,可实施性差,相信没有人可以接受一个7x24运行的生产系统进行在线存储格式转换。复制过程在主机操作系统级实现,占用操作系统资源而且是不小的比例。为保证数据一致性,需要在生产中心维护复制log,发生的每一个I/O操作都要写复制一致性需要的log,所以很容易造成I/O性能瓶颈。如果出现线路故障导致堆积的log堆积过多出现空间溢出,生产中心和灾备中心只能进行完全同步。复制过程中灾备中心的数据库处于standy状态,不能进行任何读写,造成资源浪费。
基于数据库的复制
典型代表:Oracle Data Guard。在人们印象中要提到Oracle Data Guard,首先会想到Oracle免费提供的物理备用数据库功能,通过传输和恢复Redo log实现数据库的同步,同步过程中备用数据库完全处于standby状态,不能进行任何读写访问。在这里我更想多说一下Oracle在11g企业版里推出的Active Data Guard ,为什么要强调active呢?一句话解释就是在同步复制过程中备用数据库一直处于active状态,用户可以在备用数据库上进行查询、报表等操作。同时数据同步的效率更高、对硬件的资源要求更低,这样可以更大程度地发挥物理备用数据库的硬件资源的利用率。Active Data Guard不单可以数据库的容灾目的,还可以将一些原本运行于主数据库的分析、统计、报表、备份、测试等应用迁移到备用数据库,从而降低主库的负载,变相提高了生产环境的处理能力和服务质量,
方案优势:灾备端处于Active状态,可进程正常的查询操作,提高硬件利用率。通过IP网实现数据复制,成本低,传输数据量小,带宽占用低。与数据库集成在一起,管理简单,数据库一致性得到很好保证,支持异构存储,距离不受限制。如果数据中心完全为Oracle环境,本人力推Active Data Guard作为数据库容灾方案的首选!低成本、易管理、高效率,其他方案只能望其项背。
方案限制:只能进行Oracle的复制,对于其他数据库无能为力,对Oracle数据库的版本有要求。
第三方数据库复制技术:
典型代表:Quest Shareplex
方案优势:IP网作为复制链路,成本低,支持异构存储,生产中心和灾备中心双活,资源利用率高,针对不同数据库类型有相应复制方案。
方案限制:以Shareplex基于Oracle的数据复制为例,Shareplex通过Oracle Redo log复制技术实现数据同步,但是Quest用到的Redo log解析方法不在Oracle官方认证和支持范围内,可以说是一种后门技术,随时可能出现安全隐患,另外Redo log的解析和恢复算法效率较低,会导致数据复制过程中主库的资源占用过高,备库也一直处于繁忙的运算状态。如果主库的增删改操作频繁,一旦出现数据链路中断等问题,备用数据库与主库的时间差会越来越大,最终导致复制失败。
上面简单分析了一下市场上常见的几种类型数据库容灾解决方案,当然还有一些其他的方案提供商,如Falcon、GoldenGate、Netapp等。到底选择哪一方案,依然那句话:没有最好、只有最适合,把握数据库容灾的基本原则:省钱、实用、简单、高效!
1. 容灾 的核心技术及选择
容灾系统是指在相隔较远的异地,建立两套或多套功能相同的 IT 系统,互相之间可以进行健康状态监视和功能切换,当一处系统因意外 ( 如火灾、地震等 ) 停止工作时,整个应用系统可以切换到另一处,使得该系统功能可以继续正常工作。容灾技术是系统的高可用性技术的一个组成部分,容灾系统更加强调处理外界环境对系统的影响,特别是灾难性事件对整个 IT 节点的影响,提供节点级别的系统恢复功能。
1.1. 容灾系统 衡量指标
衡量容灾系统的主要指标有 RPO ( Recovery Point Object ,灾难发生时允许丢失的数据量)、 RTO ( Recovery Time Objective ,系统恢复的时间)、容灾半径(生产系统和容灾系统之间的距离)以及 ROI(Return of Investment ,容灾系统的投入产出比 ) 。
RPO 是指业务系统所允许的灾难过程中的最大数据丢失量(以时间来度量),这是一个灾备系统所选用的数据复制技术有密切关系的指标,用以衡量灾备方案的数据冗余备份能力。
RTO 是指“将信息系统从灾难造成的故障或瘫痪状态恢复到可正常运行状态,并将其支持的业务功能从灾难造成的不正常状态恢复到可接受状态”所需时间,其中包括备份数据恢复到可用状态所需时间、应用系统切换时间、以及备用网络切换时间等,该指标用以衡量容灾方案的业务恢复能力。例如,灾难发生后半天内便需要恢复,则 RTO 值就是十二小时。
容灾半径是指生产中心和灾备中心之间的直线距离,用以衡量容灾方案所能防御的灾难影响范围。
容灾方案的 ROI 也是用户需要重点关注的,它用以衡量用户投入到容灾系统的资金与从中所获得的收益的比率。
显然,具有零 RTO 、零 RPO 和大容灾半径的灾难恢复方案是用户最期望的,但受系统性能要求、适用技术及成本等方面的约束,这种方案实际上是不大可行的。所以,用户在选择容灾方案时应该综合考虑灾难的发生概率、灾难对数据的破坏力、数据所支撑业务的重要性、适用的技术措施及自身所能承受的成本等多种因素,理性地作出选择。
1.2. 容灾 级别
按照容灾系统对应用系统的保护程度可以分为数据级容灾 、 应用级容灾 和 业务级容灾。
数据级容灾 仅 将生产中心的数据复制到容灾中心,在生产中心出现故障时,仅能实现 存储 系统的接管或是数据的恢复 。容灾 中心的数据可以是本地生产数据的完全复制( 一般 在同城实现) , 也可以比生产数据略微落后,但必定是可用的 (一般 在异地实现) , 而差异的数据 通常 可以通过一些工具( 如 操作记录、日志等) 可以 手工补回。基于数据容灾 实现 业务恢复的速度 较慢 ,通常情况下 RTO 超过 24 小时, 但是这种 级别 的容灾系统运行维护成本较低。
应用级容灾是 在数据级容灾的基础上,进一步实现应用 可用性 ,确保业务的快速恢复。这就 要求 容灾系统 的 应用不能改变原有业务处理逻辑,是对生产中心系统的基本复制 。因此 ,容灾中心需要建立起一套和本地生产相当的备份环境,包括主机、网络、应用、 IP 等 资源均有配套,当 生产 系统发生灾难时,异地系统可以 提供 完全可用的生产环境。 应用级 容灾的 RTO 通常 在 12 个 小时 以内 ,技术复杂度较高,运行维护的成本也比较高。
业务级 容灾 是生产中心 与容灾中心对业务请求同时进行 处理 的容灾方式,能够确保 业务 持续可用。这种 方式 业务 恢复 过程的自动化程度高, RTO 可以 做到 30 分钟 以内 。 但是 这种容灾级别 的 项目 实施难度大, 需要从 应用层对系统进行改造,比较适合流程固定 的 简单业务系统 。 这种 容灾系统 的运行维护成本最高。
1.3. 常见 容灾建设模式
当前 ,市场上常见的 容灾 模式可分为同城容灾、异地容灾、 双活 数据中心、 两地 三中心几种。
1.3.1. 同城 容灾
同城 容灾 是在同城或相近区域内 ( ≤ 200K M )建立两个数据中心 : 一个为数据中心,负责日常生产运行 ; 另一个为灾难备份中心,负责在灾难发生后的应用系统运行。同城灾难备份的数据中心与灾难备份中心的距离比较近,通信线路质量较好,比较容易实现数据的同步 复制 ,保证高度的数据完整性和数据零丢失。同城灾难备份一般用于防范火灾、建筑物破坏、供电故障、计算机系统及人为破坏引起的灾难。
1.3.2. 异地 容灾
异地 容灾 主备中心之间的距离较远 (> 200KM ) , 因此一般采用异步镜像,会有少量的数据丢失。异地灾难备份不仅可以防范火灾、建筑物破坏等可能遇到的风险隐患,还能够防范战争、地震、水灾等风险。由于同城灾难备份和异地灾难备份各有所长,为达到最理想的防灾效果,数据中心应考虑采用同城和异地各建立一个灾难备份中心的方式解决。
1.3.3. 两地 三中心
结合近年国内出现的大范围自然灾害,以同城双中心加异地灾备中心的 “两地三中心”的灾备模式也随之出现,这一方案兼具高可用性和灾难备份的能力。
同城双中心是指在同城或邻近城市建立两个可独立承担关键系统运行的数据中心,双中心具备基本等同的业务处理能力并通过高速链路实时同步数据,日常情况下可同时分担业务及管理系统的运行,并可切换运行;灾难情况下可在基本不丢失数据的情况下进行灾备应急切换,保持业务连续运行。
异地灾备中心是指在异地的城市建立一个备份的灾备中心,用于双中心的数据备份,当双中心出现自然灾害等原因而发生故障时,异地灾备中心可以用备份数据进行业务的恢复。
1.3.4. 双活 数据中心
所谓 “ 双活 ” 或 “ 多 活 ” 数据中心,区别于 传统 数据中心 和 灾备中心的模式,前者 多个 或两个数据中心都处于运行当中, 运行相同的应用,具备同样的数据,能够提供跨中心业务负载均衡运行能力,实现持续的应用可用性和灾难备份能力, 所以称为 “双活 ” 和 “ 多 活 ” ;后者是 生产 数据中心投入运行, 灾备 数据中心处在不工作状态,只有当灾难发生时,生产数据中心瘫痪,灾备中心才启动。
“ 双活 ” 数据中心最大的特点是 : 一、充分利用资源,避免了一个数据中心常年处于闲置状态而造成浪费 , 通过资源整合, “ 双活 ” 数据中心的服务能力是 翻 倍的 ; 二 、 “ 双活 ” 数据中心如果断了一个数据中心, 其 业务可以 迅速 切换到另外一个 正在 运行的数据中心, 切换 过程对用户来说是不可感知的。
在 “ 双活 ” 的模式中,两地数据中心同时接纳交易,技术难度很大,需要更改众多底层程序 , 因而在现实中,国内还没有 真正 “ 双活 ” 数据中心 的成功 应用 案例。
1.4. 常用 的数据复制技术
在构建容灾系统所涉及的诸多要素中,数据复制 技术 是基础,只有保证了数据的安全可用,应用 或是 业务的恢复才有可能。 正常情况下系统的各种应用在数据中心运行,数据存放在数据中心和灾难备份中心两地保存。当灾难发生时,使用备份数据对工作系统进行恢复或将应用切换到备份中心。
数据 复制技术的选择决定灾备系统的 RPO 指标 ,灾难备份系统中数据备份技术的选择应符合数据恢复时间或系统切换时间满足业务连续性的要求。
数据复制( Replication )是指利用复制软件把数据从一个磁盘复制到另一个磁盘,生成一个数据副本。这个数据副本是数据处理系统直接可以访问的,不需要进行任何的数据恢复操作,这一点是复制与 D2D 备份的最大区别。
根据不同容灾方案所采用数据复制技术位于企业 IT 架构不同层面,数据复制可分为基于存储层的复制、基于主机层复制和 基于应用的复制 。
具体 到一个 I/O 从 磁盘到应用的流程上,可能经由 磁盘阵列 、存储网络、卷管理软件、文件系统、 数据 库系统和应用系统 全部 流程或是其中的几个流程, 那么 数据复制就可以在这些 流程 的任一层次上实现,如下图所示:
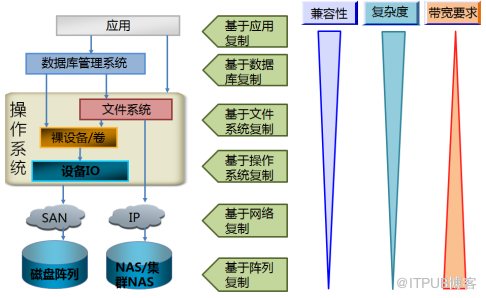
基于存储层的复制可以是由存储设备的控制器执行,也可以是由网络 层的 虚拟化存储管理平台来执行,基于存储层的复制基于 主机和应用的无关性,兼容性要求最低, 实施 难度最小,但是由于是卷级别的数据拷贝,对网络带宽要求最高; 基于主机的复制可以 由安装在主机上的卷管理软件或是文件系统来实现,在实际的应用场景中,以基于卷管理软件的数据复制技术居多, 这种 方式通常要求主机平台相关,实施难度 升高 ,但是带宽要求降低; 基于数据 层的复制通过 数据库 的容灾功能模块来实现, 对 网络带宽要求最低,但是 只能 实现数据库数据 的 容灾;基于应用层的数据复制 需要 对应用程序进行定制开发,现实场景中很难见到。
下面就重点 介绍一下 几种 常见的数据复制技术。
1.4.1. 基于存储层的容灾复制方案
1.4.1.1. 基于存储 设备的数据复制
基于存储设备的数据 复制 技术的核心是利用存储阵列自身的盘阵对盘阵的数据块复制技术实现对生产数据的远程拷贝,从而实现生产数据的灾难保护。在主数据中心发生灾难时,可以直接利用灾备中心的数据建立运营支撑环境,为业务继续运营提供 IT 支持。同时,也可以利用灾备中心的数据恢复主数据中心的业务系统,从而能够让企业的业务运营快速回复到灾难发生前的正常运营状态。
基于存储设备 的数据复制技术 示意图如下:
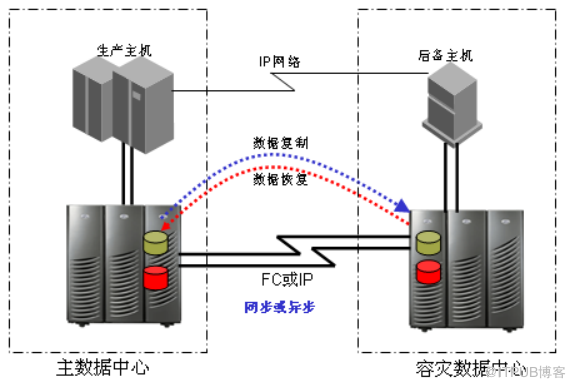
基于存储设备的复制可以是如上示意图的 “一对一”复制方式,也可以是“一对多或多对一”的复制方式,即一个存储的数据复制到多个远程存储或多个存储的数据复制到同一远程存储;而且复制可以是双向的。
基于存储的数据 复制技术 有两种方式:同步方式和异步方式。
同步方式:可以做到主 / 备数据中心磁盘阵列同步地进行数据更新,应用系统的 I/O 写入主磁盘阵列后 ( 写入 Cache 中 ) ,主磁盘阵列将利用自身的机制同时将写 I/O 写入后备磁盘阵列,后备磁盘阵列确认后,主中心磁盘阵列才返回应用的写操作完成信息。
异步方式:是在应用系统的 I/O 写入主磁盘阵列后 ( 写入 Cache 中 ) ,主磁盘阵列立即返回给主机应用系统“写完成”信息,主机应用可以继续进行写 I/O 操作。同时,主中心磁盘阵列将利用自身的机制将写 I/O 写入后备磁盘阵列,实现数据保护。
采用同步方式,使得后备磁盘阵列中的数据总是与生产系统数据同步,因此当生产数据中心发生灾难事件时,不会造成数据丢失,可以 实现 RPO 为零。为避免对生产系统性能的影响,同步方式通常在近距离范围内( FC 连接通常是 200KM 范围内,实际用户部署多在 35KM 之内)。
而采用异步方式应用程序不必等待远程更新的完成,因此远程备份 存储设备 的性能的影响通常较小,并且生产中心的距离和灾备 中心 的距离理论上没有限制(通常基于 IP 连接来实现数据的异步复制)。
采用基于存储设备 数据 复制技术构建容灾方案的必要前提是:
Ø 通常必须采用同一厂家统一 系列的 且同时 具有数据复制技术的高端 存储平台,给用户的存储平台选择带来一定的限制。
Ø 采用同步方式可能对生产系统性能产生影响,而且对通信链路要求较高,有距离限制,通常在近距离范围内实现(同城容灾或园区容灾方案)
Ø 采用异步方式与其他种类的异步容灾方案一样,存在数据丢失的风险 , 通常在远距离通信链路带宽有限的情况下实施。
尽管有以上限制,基于存储设备 的数据复制技术 仍然是当前选择较多的容灾技术平台,这主要是由于基于存储的复制技术方案有如下优点:
Ø 采用基于存储的数据复制独立于主机平台和应用,对各种应用都适用,而且完全不消耗主机的处理资源;
Ø 基于存储得数据复制技术,由于在最底层,实施起来受应用、主机环境等相关技术的影响最小,非常适合于主机和业务系统很多、很复杂的环境,采用此种方式可以有效降低实施和管理难度;
Ø 采用同步方式可以完全不丢失数据,在同城容灾或园区内容灾方案中,只要通信链路带宽许可,完全可以采用同步方案,而不会对主数据中心的生产系统性能产生显著影响;
Ø 采用异步方式虽然存在一定的数据丢失的风险,但没有距离限制,可以实现远距离保护;
Ø 灾备中心的数据可以得到一定 程度上的 有效利用(用作 测试或 报表 等) 。
构建 成本 :
存储层容灾产品报价,都是采用磁盘阵列的高级功能许可授权方式进行报价。并按照磁盘阵列的具体数量进行报价。越是高端盘阵,高级功能模块授权价格成阶梯式增长。
除了这些高级功能授权的许可外,其还有 MA (维护)费用以及实施费用, MA 费用整体磁盘阵列报价(含高级功能模块)的 25% 左右。
实施费用一般按人天费用方式进行计算,总体成本很高。
另外,其对带宽要求很高,容灾网络建设费用更高。
适用 场景 :
存储设备 复制技术 利用磁盘阵列自身卷复制功能实现,首先要求必须是同构高端存储系统,其次对带宽要求较高,实现的是底层数据块级别的复制,属于数据层容灾范畴。
这类容灾产品由于其自身的功能特性,作为高端盘阵衍生出来的附加高级功能来实现容灾,其投资巨大,从盘阵本身到链路的要求都极高,需要专门的链路确保数据的一致性。当灾难 发生时,需要通过 人工调整的方式,将镜像卷提供给远端生产业务系统,实现业务系统的容灾, RTO 在 数小时以上。
经过 以上分析可以看出,基于 存储层 的灾备方案对 存储 平台要求 非常 严格, 适合用于为底层 存储平台单一、服务器平台 构成 复杂、上层应用 繁多 的 IT 系统构建数据级 的容灾方案 ,不 适合 于复杂 、 异构 存储平台 的 容灾场景 需求 。
1.4.1.2. 基于 虚拟化 存储技术 的 数据复制
存储虚拟化的技术方法, 是 将系统中各种异构的存储设备映射为一个单一的存储资源,对用户完全透明,达到 屏蔽存储设备异构的 目的。通过虚拟化技术,用户可以利用已有的硬件资源,把 SAN 内部的各种异构的存储资源统一成对用户来说是单一视图的存储资源( Storage Pool ),而且采用 Striping 、 LUN Masking 、 Zoning 等技术,用户可以根据自己的需求对这个大的存储池进行方便的分割、分配,保护了用户的已有投资,减少了总体拥有成本( TCO )。另外也可以根据业务的需要,实现存储池对服务器的动态而透明的增长与缩减。
通过存储虚拟化技术可以实现数据的远程复制,这种 数据复制技术原理和基于存储设备的 原理 基本一样,唯一的区别就是前者由存储虚拟化控制器实现,或者由磁盘阵列控制器实现 , 所以这种技术不要求底层磁盘阵列同构。 存储虚拟化技术通常 在 存储 网络 层面实现, 其 数据复制同样也可以有同步复制方案和异步复制方案,需要根据具体的需求选择合适的技术。
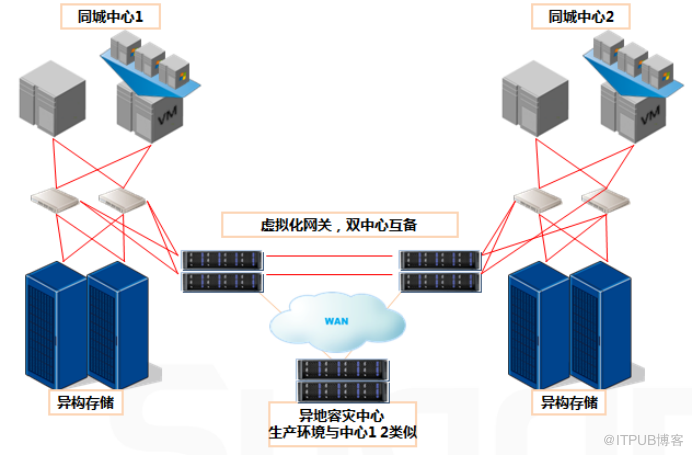
基于 存储虚拟化控制器的 两地三中心容灾方案架构
采用 虚拟存储 化技术建设容灾方案有以下优点:
Ø 主生产中心和容灾中心的存储阵列可以是不同厂家的产品,存储平台选择不受现有存储平台厂商的限制;
Ø 对不同厂家的存储阵列提供统一的管理界面。
在虚拟存储环境下,无论后端物理存储是什么设备,服务器及其应用系统看到的都是其熟悉的存储设备的逻辑镜像。即便物理存储发生变化,这种逻辑镜像也永远不变,系统管理员不必再关心后端存储,只需专注于管理存储空间,所有的存储管理操作,如系统升级、建立和分配虚拟磁盘、改变 RAID 级别、扩充存储空间等比从前的任何产品都容易,存储管理变得轻松简单。
采用 虚拟存储 化技术建设容灾方案需要考虑以下问题:
Ø 需要验证选择的产品和技术的成熟性以及和现有设备、未来设备的兼容性能力;
Ø 存储 虚拟化控制器作为一种带内接管方式, 存储 系统的性能直接和存储虚拟化控制器相关,在 高 I/O 负载 应用场景下,需要考虑存储虚拟化控制器的性能瓶颈问题 。
虚拟化技术 即继承了基于存储设备实现数据复制方案的优点,同时又能 兼容 异构存储系统, 并且 切换过程 比较 简单,甚至可以实现自动切换,成为越来越多 容灾 用户的选择。
构建 成本 :
存储网络层产品报价,一般采用虚拟化网关的数量和容量结合起来的报价方式,存储网关数量的多少和虚拟化存储容量的多少都直接影响整个报价。
除此之外还有 MA 费用和实施费用, MA 费用整体价格的 25% 左右。
实施费用一般按人天费用方式进行计算,总体成本较高。
另外,其对带宽要求比较高,容灾网络建设费用比较高。
适用场景 :
存储网络层容灾产品,利用了存储虚拟化技术,将后台存储进行统一池化的方式进行管理。利用其镜像和复制技术,实现池化后数据块的镜像和复制,保证数据的一致性。从实现方式上面来讲,属于数据层容灾范畴。
其有两种实现方式:
一种是镜像的方式,通过镜像技术实现数据块的完全同步,这种采用的是同步方式,对带宽要求极高。
另外一种复制的方式,采用虚拟化网关机头之间的数据复制实现,它可以采用同步方式也可以采用异步的方式,往往受限于带宽的限制,这种复制方式往往采用异步的方式进行复制。
不管采用哪种方式进行数据的一致性保证,数据卷都存在主备关系,远端数据卷不能被前端业务系统进行访问,当灾难发生时,通过自动 切换 人工调整的方式,将远端卷提供给远端业务系统,实现业务系统的容灾。
这类产品采用的都是带内虚拟化方式,很好的解决了异构存储容灾问题,但是其数据流都要经过虚拟化网关,前端业务系统性能会有所下降,其吞吐能力受到限制。
综合这类产品的特性,其适合用于为 拥有较多型号的 异构 磁盘阵列 并 承担多 个 应用的 现有 IT 系统构建容灾 平台方案。
1.4.2. 基于 主机数据复制技术 的 灾备方案
采用基于主机复制 技术 的容灾方案的示意图如下:
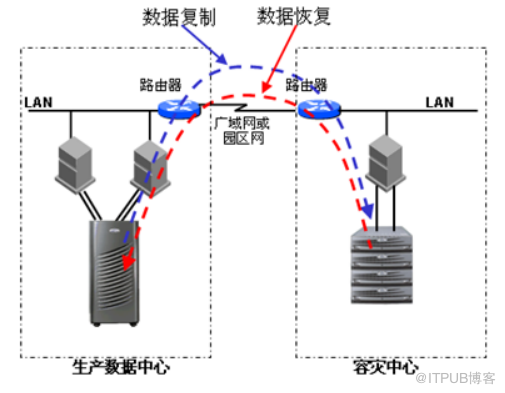
图1-1. 基于主机的容灾方案示意图
采用基于主机系统的数据 复制技术 的核心是利用主、备中心主机系统通过 IP 网络建立数据传输通道,通过主机数据管理软件实现数据的远程复制,当主数据中心的数据遭到破坏时,可以随时从备份中心恢复应用或从备份中心恢复数据,从而给企业提供了应用系统容灾的能力。
实现主机 层 数据复制的数据管理软件有很多产品,如 Symantec 公司 的 Veritas Volume Replicator ( VVR ) 以及 Rose HA 公司 的 Rose Replicator 等, 这些方案 可实现基于主机的远程数据复制,从而构建基于主机的容灾系统。
采用基于主机的数据复制技术建设容灾方案有以下优点:
Ø 基于主机的方案最主要的优点是只和服务器平台和主机数据 管理 软件相关 , 完全不依赖于底层存储平台,生产中心和灾备中心可以采用不同的存储平台;
Ø 可 同时 对数据库和 文件系统提供 容灾保护;
Ø 有很多不同的基于主机的方案,可以满足用户的不同数据保护要求,提供多种不同数据保护模式;
Ø 基于 IP 网络 , 没有距离限制;
同时,采用主机的数据复制技术建设容灾方案有以下局限:
Ø 基于主机的方案需要主机平台同构;
Ø 基于主机的数据复制方案由于生产主机既要处理生产请求,又要处理远程数据复制,必须消耗生产主机的计算资源,对于主机的内存、 CPU 进行升级是非常昂贵的,因而对生产主机性能产生较大的影响,甚至是产生严重影响;
Ø 灾备中心的数据一般不可用,如果用户需要在远程数据中心使用生产数据进行开发测试、 DW/BI 应用使用将非常困难;
Ø 利用主机数据复制软件的方案比较复杂,尤其是和数据库应用结合的时候需要很复杂的机制或多种软件的结合,从而对生产系统的稳定性、可靠性、性能带来较大影响;
Ø 如果有多个系统、多种应用需要灾难保护,采用基于主机的方案将无法用统一的技术方案来实现。
Ø 管理复杂,需要大量的人工干预过程,容易发生错误。
主流产品 列表 :
厂家名称 | 产品型号 | 容灾功能 |
|---|---|---|
赛门铁克 | Storage F oundation | 镜像 / 复制 |
构建 成本 :
主机层卷复制容灾产品,通常的报价方式是按照主机的 CPU 数据进行报价,主机数量越多, CPU 数量越多价格也越高,同样也存在 MA 费用和实施费用。
此类容灾产品,相应的容灾网络建设成本相对较低。
适用 场景:
目前,企业采用基于主机的数据复制技术建设容灾方案的 案例 相对比较少,通常适合单一应用或系统在 I/O 规模不大的情况下局部使用。在应用 I/O 负载比较大,需要灾难保护的应用及应用类型比较多、主机环境复杂的时候,基于主机系统的方案并不适用。
1.4.3. 基于 数据库 的数据复制 技术 构建灾备方案
基于 数据库的数据复制技术大体上可 分为 两类:数据库自己提供的数据容灾模块和第三方厂商提供的数据库复制 技术 。 以 最常见的 Oracle 数据库 为例, Oracle 自己的数据 复制 技术有 Data Guard , Streams , Advanced Replication 和 Golden Gate 数据复制软件。第三方厂商的数据复制技术有 Quest 公司的 Share Plex 和 DSG 的 RealSync 等。
1.4.3.1. 几种 常见数据库复制技术
Data Guard 数据复制技术
Data Guard 是 Oracle 数据库自带的数据同步功能,基本原理是将日志文件从原数据库传输到目标数据库,然后在目标数据库上应用( Apply )这些日志文件,从而使目标数据库与源数据库保持同步。 Data Guard 提供了三种日志传输( Redo Transport )方式,分别是 ARCH 传输、 LGWR 同步传输和 LGWR 异步传输。在上述三种日志传输方式的基础上,提供了三种数据保护模式,即最大性能( Maximum Performance Mode )、最大保护( Maximum Protection Mode )和最大可用( Maximum Availability Mode ),其中最大保护模式和最大可用模式要求日志传输必须用 LGWR 同步传输方式,最大性能模式下可用任何一种日志传输方式。
最大性能模式:这种模式是默认的数据保护模式,在不影响源数据库性能的条件下提供尽可能高的数据保护等级。在该种模式下,一旦日志数据写到源数据库的联机日志文件,事务即可提交,不必等待日志写到目标数据库,如果网络带宽充足,该种模式可提供类似于最大可用模式的数据保护等级。
最大保护模式:在这种模式下,日志数据必须同时写到源数据库的联机日志文件和至少一个目标库的备用日志文件( standby redo log ),事务才能提交。这种模式可确保数据零丢失,但代价是源数据库的可用性,一旦日志数据不能写到至少一个目标库的备用日志文件( standby redo log ),源数据库将会被关闭。这也是目前市场上唯一的一种可确保数据零丢失的数据库同步解决方案。
最大可用模式:这种模式在不牺牲源数据库可用性的条件下提供了尽可能高的数据保护等级。与最大保护模式一样,日志数据需同时写到源数据库的联机日志文件和至少一个目标库的备用日志文件( standby redo log ),事务才能提交,与最大保护模式不同的是,如果日志数据不能写到至少一个目标库的备用日志文件( standby redo log ),源数据库不会被关闭,而是运行在最大性能模式下,待故障解决并将延迟的日志成功应用在目标库上以后,源数据库将会自动回到最大可用模式下。
根据在目标库上日志应用( Log Apply )方式的不同, Data Guard 可分为 Physical Standby ( Redo Apply )和 Logical Standby ( SQL Apply )两种。
Physical Standby 数据库,在这种方式下,目标库通过介质恢复的方式保持与源数据库同步,这种方式支持任何类型的数据对象和数据类型,一些对数据库物理结构的操作如数据文件的添加,删除等也可支持。如果需要, Physical Standby 数据库可以只读方式打开,用于报表查询、数据校验等操作,待这些操作完成后再将数据库置于日志应用模式下。
Logical Standby 数据库,在这种方式下,目标库处于打开状态,通过 LogMiner 挖掘从源数据库传输过来的日志,构造成 SQL 语句,然后在目标库上执行这些 SQL ,使之与源数据库保持同步。由于数据库处于打开状态,因此可以在 SQL Apply 更新数据库的同时将原来在源数据库上执行的一些查询、报表等操作放到目标库上来执行,以减轻源数据库的压力,提高其性能。
Data Guard 数据同步技术有以下优势:
1 ) Oracle 数据库自身内置的功能,与每个 Oracle 新版本的新特性(如 ASM )都完全兼容,且不需要另外付费;
2 ) 配置管理较简单,不需要熟悉其他第三方的软件产品;
3 ) Physical Standby 数据库支持任何类型的数据对象和数据类型;
4 ) Logical Standby 数据库处于打开状态,可以在保持数据同步的同时执行查询等操作;
5 ) 在最大保护模式下,可确保数据的零丢失;
Data Guard 数据同步技术的劣势体现在以下几个方面:
1 ) 由于传输整个日志文件,因此需要较高的网络传输带宽;
2 ) Physical Standby 数据库虽然可以只读方式打开,然后做些查询、报表等操作,但需要停止应用日志,这将使目标库与源数据不能保持同步,如果在此期间源数据库发生故障,将延长切换的时间;
3 ) Logical Standby 数据库不能支持某些特定的数据对象和数据类型;
4 ) 不支持一对多复制,不支持双向复制,因此无法应用于信息集成的场合;
5 ) 只能复制整个数据库,不能选择某个 schema 或表空间进行单独复制;
6 ) 不支持异构的系统环境,需要相同的操作系统版本和数据库版本;
Data Guard 技术是 Oracle 推荐的用于高可用灾难恢复环境的数据同步技术。
Streams 数据复制技术
Streams 是从版本 Oracle 9i 才开始具有的数据同步功能,是为提高数据库的高可用性和数据的分发和共享功能而设计的, Streams 利用高级队列技术,通过用 LogMiner 挖掘日志文件生成变更的逻辑记录,然后将这些变更应用到目标数据库上,从而实现数据库之间或一个数据库内部的数据同步。
Streams 数据同步大致分如下几个步骤:
1 ) Capture 进程分析日志,生成逻辑记录 LCR ,将其放入一个队列中;
2 ) Propagation 进程将 LCR 发送到另一个数据库中,通常是目标数据库;
3 ) 在目标数据库中, Apply 进程将 LCR 应用到目标库,实现数据的同步;
在简单的 Streams 配置中, Capture 进程一般位于源数据库,因此叫做 Local Capture Process , Capture 进程在分析日志后将生成的 LCR 放入队列中,由 Propagation 进程将 LCR 发送到目标库中。这样做的好处是不用在网络上传送整个的日志文件,因此可提高网络传输的效率,但这一般会给源数据库带来较大的压力,影响其性能。
另一种配置是 Capture 进程位于 Downstream 数据库中,源数据库只负责将日志文件传送(日志传输方式可为 ARCH 传输、 LGWR 同步传输和 LGWR 异步传输中的任何一种)到 Downstream 数据库中,所有的 Capture 操作都在 Downstream 数据库上完成。这种配置的好处是可以大大降低源数据库的压力,缺点是需要传输整个日志文件,对网络带宽要求较高。
Streams 数据同步技术有以下优势:
1 ) 可支持一对多、多对一和双向复制,可用于数据分发和共享,这是 Data Guard 所不具备的;
2 ) 可灵活配置复制数据库中的一部分对象,如可按 Table 复制、 Schema 复制、表空间复制等,并可在复制过程中对数据进行过滤和转换,使之满足不同的需要;
3 ) 同 Data Guard 一样,是 Oracle 内置功能,与每个 Oracle 新版本的新特性(如 ASM )都完全兼容,且不需要额外付费;
4 ) 可用于异构的操作系统和数据库版本,但有一些限制;
5 ) 可支持非 Oracle 数据库和 Oracle 数据库之间的数据同步;
6 ) 目标数据库处于打开状态,可以在保持数据同步的同时执行查询等操作,分担源数据库的压力;
Streams 数据同步技术有以下缺点:
1 ) 配置维护较复杂,需要较高的技术水平;
2 ) 在非 Downstream 复制中,对源数据库压力较大;如果使用 Downstream 复制,则增加了配置的复杂性且需要通过网络传输整个日志文件,对网络带宽要求较高;
3 ) 不能支持某些特定的数据对象和数据类型;
4 ) 不能保证数据的零丢失;
Oracle 公司将 Streams 技术定位于数据的分发和共享,虽然也可用于高可用的灾难恢复场合,但 Oracle 推荐使用的灾难恢复技术是 Data Guard 。
Advanced Replication 数据复制技术
Advanced Replication 配置管理较复杂,且对源数据库性能影响较大,在以后的 Oracle 版本中将可能逐步被 Streams 技术所取代。
Golden Gate 数据复制技术
Golden Gate 原来是一家独立的软件厂商的产品,现该产品已被 Oracle 公司收购, Oracle 将 Golden Gate 软件集成到到其“融合( Fusion )”中间件中,预计以后该产品将与 Oracle 数据库更紧密地集成。 Golden Gate 可以用于多种不同的操作系统平台( Unix 、 Linux 、 Windows )和多种不同数据库系统(如 DB2 、 Oracle 、 Infomix 、 MySQL 、 Sybase 等)之间的数据同步,是一款优秀的数据同步及数据分发产品。
GoldenGate 是一种基于软件的数据复制方式,它从数据库的日志中解析数据的变化(数据量只有日志的四分之一左右), 并 将数据转化为自己的格式,直接通过 TCP/IP 网络传输,无需依赖于数据库自身的传递方式如 Oracle Net ,而且可以通过高达 9:1 的压缩比率对数据进行压缩,大大降低带宽需求。在目标端, GoldenGate 可以通过交易重组 、 分批加载等技术大大加快数据投递的速度和效率,降低目标系统的资源占用,可以在秒一级实现大量数据的复制。
作为一种软件方案, GoldenGate 可以采用非常灵活的方式加以配置,包括 单向 复制、双向复制和多层次的数据复制。特别是其在双向数据复制领域的 先进 技术,可以满足用户在本地或广域网络环境中的各种复杂需求。
GoldenGate 数据库复制 技术具有如下特性 ∶
本机数据改变捕捉 – 作为一个基于日志的同步解决方案,将对源系统和网络的影响减少到最低。
灵活性 – 源和目的系统不需要有一样的操作系统、数据库及模板 ( 例如 ∶ 表,索引,等 ) 。 GoldenGate 能在同一个系统的多个数据库实例之间实现数据复制,或把数据复制到局域网内的其它数据库实例,或把数据复制到广域网上的远端数据库实例。
无需宕机时间的移植 –GoldenGate 能在不同版本的数据库和操作系统之间同步数据。数据库,操作系统或应用系统的更新可以在辅助系统里进行。一旦更新后的辅助系统通过了完整的测试,所有的处理工作就可以切换到辅助系统,然后更新主系统。一旦主系统的更新完成了,主与辅助系统之间能够再一次同步而无宕机时间。
不依赖于硬件和数据库 –GoldenGate 不依赖于操作系统,数据库和硬件。数据可以在不同的环境之间移动,因而消除了客户对任何拓扑结构的依赖性。
RPO 与 RTO 的目标 –GoldenGate 提供了立即恢复备份的装备。这是因为源和备份系统可以配置或构架设计为双向 ” 端到端 ” 的功能。
双向复制 –GoldenGate 提供了两个或两个以上生产系统之间的数据复制功能。这些系统无须具有一样的属性或相同的操作系统,数据库或数据库版本。
数据一致性 – 备份数据库支持读一致性的查询活动 ( 交易的一致性在任何时候都受到保护 ) 。
灵活的拓扑结构 – 在数据库和表一级实现了多种相关数据的分部方式。例如 ∶ 支持一对多,多对一,多对多以及分层的配置。
映射与转换功能 – 列转换能够适应特别的备份需要,包括查看和执行存储过程。
数据选择 – 选择性的复制数据而不是全部,例如表,行和列。
GoldenGate 是一种基于数据库日志的数据复制产品,可以利用极少的系统开支,实时复制数据库,改善数据可用性。 GoldenGate 可以在数据移植、在线维护等场合应用,以减少或消除数据库的停机时间。同时,它还可用于数据容灾、负载均衡、数据集中、数据分布等应用中。 GoldenGate 可确保在这些工作进行时,源系统的正常事务处理得以继续进行,功能上不受影响。
Share Plex 数据复制技术
Share Plex 是 Quest 公司开发的用于专门用于 Oracle 数据库的数据同步软件,可以运行在异构的操作系统平台上和 Oracle 数据库的不同版本之间。
Share Plex 的数据复制原理与 Golden Gate 类似,需要分别在源数据库服务器和目标数据库服务器上安装 Share Plex 软件。具体处理过程是: Capture 进程分析源数据库的日志文件,抓取所需的数据变更操作,将其存储在 Share Plex 自己专有的 queue 文件中,放入到 Capture Queue ,然后由 Read 进程对 queue 文件进行封装处理,将其放入到 Export Queue 中,由 Export 进程将 queue 文件通过网络发送到目标服务器上,目标服务器上的 Import 进程接收这些 queue 文件,将其放入到 Post Queue 中,最后由 Post 进程将这些 queue 文件中的变更应用到目标数据库中,其处理流程如下图:

Share Plex 数据同步技术的优势有:
Ø 支持异构的操作系统平台,便于数据库管理系统的版本升级及操作系统平台切换;
Ø 跟 Data Guard 传输整个日志文件相比, Share Plex 传输的数据量大大降低,这点跟 Golden Gate 差不多;
Ø 目标数据库处于打开状态,且支持一对多、多对一、双向复制等配置,也可以选择部分对象进行复制,可满足数据分发和数据集成的需要,减轻源数据库压力,这方面也类似于 Golden Gate ;
Ø 所占系统资源较少,通常在 10% 以下。
Share Plex 数据同步技术的劣势体现在以下几个方面:
Ø 需要支付额外的 Liscense 费用,通常是一笔不小的支出;
Ø 需要在数据库软件外安装一套专门数据同步软件,增加了管理维护的复杂程度;
Ø 由于数据复制操作独立于数据库管理系统,因此不能确保数据零丢失;
Ø 由于是第三方的软件产品,在对某些特定的数据对象、数据类型和 Oracle 某些新特性如 ASM 的支持方面不如数据库厂商自己的解决方案;另外,还有一种可能就是如果 Oracle 对自己的日志格式做些改变或加密, Share Plex 将无能为力。
从上述分析可知, Share Plex 虽然专用于 Oracle 数据库同步,但同 Golden Gate 相比并无明显优势, Golden Gate 对异构数据库的支持更是 Share Plex 所不能比。
DSG Real Sync 数据 复制技术
除了上述数据同步技术外,在国内市场上用于 Oracle 数据同步的产品还有 DSG 公司的 Real Sync 软件, Real Sync 的实现原理及功能与 Share Plex 基本类似,也是只支持 Oracle 数据库,也可以跨越不同的操作系统平台。值得一提的是 Real Sync 在目标数据库的数据装载方面,不是通过主键或唯一键来实现数据记录的定位,而是自己维护一个源数据库和目标数据库的数据记录的 rowid mapping 表,通过 rowid 来实现记录的定为,因此在数据装载效率方面有不小的提高。
1.4.3.2. 主流产品 列表
对比项 | DataGuard | Stream | Advenced Replication | GoldenGate |
|---|---|---|---|---|
原理 | 基于 日志挖掘,通过传播 线程 将归档日志由源数据库传到目的数据库 | 基于 日志挖掘 | 基于触发器( trigger )所有复制对象结构( DDL )的改变,都必须通过 oracle 提供的复制包来实施 | 基于 日志挖掘 |
主要 用途 | 灾备 恢复、高可用性 | 数据 共享 | 数据 同步 | 高可用 与容灾、 实时 数据集成 |
实现 简易程度 | 实现 过程和管理简单 | 实现 过程复杂,对 DBA的 要求非常高 | 配置 和管理复杂 | 配置 较简单 |
安全性 与稳定性 | 较稳定 、可靠 | 稳定 、可靠 | 稳定 、一般 | 稳定 、可靠 |
对 源数据库的性能影响 | 一般 | 一般 | 基于 触发器原理,对主库 影响 比较大,生产系统一般不 适用 | 亚 秒级复制,对源数据库影响非常小 (独立 的软件,并且只是针对 re do 日志 的扫描) |
拓扑 结构 | 支持 一对多模式,standby 数据库 最多为 9个 | 支持 一对一、一对多、多对一、双向复制等多种拓扑结构 | 支持 一对多模式或者包含多个 Master Site | 支持 一对一、一对多、多对一、双向复制等多种拓扑结构 |
是否 支持操作系统异构 | 不支持 | 支持 ,但是有限制 | 支持 | |
收费 情况 | 免费 | 免费 | 免费 | 收费 |
1.4.3.3. 构建 成本
Oracle 数据库类应用容灾产品,目前分为两种类型:
Oracle 企业版自身提供的 DataGuard 功能模块,其模块是免费的。
商业版的如 GoldenGate , SharePlex 等软件,按照 CPU 的数量进行收费,主机的 CPU 数量越多,价格也越高,同样也具有 MA 费用和实施费用。
下表为 Golden gate 的 list 价格:
Oracle产品组件 | 描述 | license List 价格 |
|---|---|---|
Oracle GoldenGate | 包括GoldenGate Capture,Deliver and Active DataGuard On oracle DB | $17500/CPU |
Oracle GoldenGateVeridata | Add-on capabilityto validate date inreplicated systems | $30000/CPU |
Management Pack forGoldenGate | Add-onmanagement pack | $3500/CPU |
这类容灾产品,如果 采用商业版本,软件费用和实施服务费用也比较高 。
1.4.3.4. 适用 场景
数据库类 应用容灾产品, 采用 安装在 主机 端的应用软件实现容灾,其最大的优势是可为数据库数据提供应用级别的保护,对网络带宽要求较低, 容灾 网络基于 IP 网络构建 ,成本较低; 其 劣势是仅能对数据库数据提供保护,并且 对源数据库 都有或多或少的性能影响。
经过 对以上几种数据库复制技术的分析, DataGuard 、 Stream 、 Advenced Replication 是专为 Oracle 数据库 开发的灾备模块,适合于同构平台的 Oracle 数据库容灾 ; Shareplex 适合于异构平台 的 Oracle 数据库 容灾; GoldenGate 适合于 异构平台和异构数据库的容灾与应急备份,消除计划内停机、双业务中心 、 数据仓库实时供给、实时 报表 等应用场景需求。
1.5. 如何 选择 最优 的容灾方案
1.5.1. 数据 容灾技术 选择 原理
图: 沙漏模型
1.5.2. 数据容灾技术选择度量标准
在构建 容灾 系统时,首先考虑的是结合实际情况选择合理的数据复制技术。 在 选择合理的数据复制技术时主要考虑以下因素:
Ø 灾难承受程度 :明确计算机系统需要承受的灾难类型,系统故障、通信故障、长时间断电、火灾及地震等各种意外情况所采取的备份、保护方案不尽相同。
Ø 业务影响程度 :必须明确当计算机系统发生意外无法工作时,导致业务停顿所造成的损失程度,也就是定义用户对于计算机系统发生故障的最大容忍时间。这是设计备份方案的重要技术指标。
Ø 数据保护程度 :是否要求数据库恢复所有提交的交易 , 并且要求实时同步 ,保证 数据的连续性和一致性, 这是 备份方案复杂程度的重要依据。
1.6. 本 项目容灾模式及 技术 的选择
1.6.1. 容灾 模式选择
在灾备模式选择上,目前, XX 市 各委办局 信息中心信息系统直接面向群众提供服务,业务的连续性以及数据安全的保障是在选择容灾模式时首要考虑的两个方面。既要在生产中心发生灾难时,保证关键业务不中断,又要保证在同城发生灾难时,各委办局所有关键数据保存一份相对完整的备份。新建 的 XX 市云计算中心 作为 未来的主生产中心,未来各委办局的业务系统会逐步迁移到该中心运行,承载当前 XX 市电子政务信息系统的 主要 业务 , 提供对内对外服务; 同城容灾中心做为生产中心的容灾备份,在生产环境发生灾难不能运作的时候,将接管生产,暂时作为主数据中心运行,恢复各委办局 关键业务 的应用运行。同城容灾中心作为生产中心的区域内备份,不能防御区域性灾害。异地容灾中心用于防范区域性灾难,从 《 中国 地理杂志》 发布 的《 中国 地震带 分布 》 图上可以看出, XX 位于中国第 4 大断裂带“郯庐断裂带”的 边沿 上,有发生区域性灾难的可能性。当发生区域性灾难时,生产中心和同城容灾中心都不可用,异地容灾中心可以保证关键数据还有一份拷贝, 并且 核心 应用可以选择在异地容灾中心重新启动 。因此,从整个容灾体系来看,省厅容灾模式应选择 “两地三中心”的方式。
1.6.2. 容灾 中心选址
1.6.2.1. 同城灾备中心地址选择
选择该地点作为同城灾备中心具有以下优势:
Ø 具备完善的物业服务、市电供电、消防设施等,各种配套设施比较齐全。
Ø 该机房建设时已经充分考虑了承重、抗震、防雷、防水等内容,选择该处可以大大降低建设成本和建设周期。
Ø 该机房内的设备可以作为灾备设备使用,无需搬迁,降低搬迁费用和搬迁风险。
Ø XX 市电子政务外网的光纤专线全部汇聚到该机房,在云计算中心建成后可以利用这些光纤专线作为 XX 市电子政务外网的备份线路。
1.6.2.2. 异地灾备地址选择
按照国家有关要求,电子政务灾备中心须依托电子政务网络进行建设,达到共享灾备基础设施、降低昂贵的线路租赁费用等目的。XX 市政府网站管理中心先期对国内知名的云计算中心进行考察并同国内部分城市的电子政务管理部门进行了沟通和交流,已经有广州、成都、无锡等城市表达了愿意同 XX 市等价交换机房、网络、安全、运维人员等方面资源的意愿,形成互惠机制,最大限度的发挥双方的优势。
广州、成都、无锡等城市均已经建成了云计算中心,南京的云计算中心也是高标准云计算中心。这些中心均具有良好的机房环境、网络设施和较强的运维能力,完全具备灾备中心必须具备的硬件条件和技术服务能力。
灾备中心除了需要考虑机房、网络和运维能力等因素以外,还需考虑距离、地震带、地质结构、电网、江河流域、建筑环境等各种因素。
目前, XX 市政府网站管理中心正在积极同其他城市联系,拟在初步设计阶段同其他城市达成正式的合作协议,明确机房交换、网络设施使用、运维人员互用等事宜。
考虑到 CNGI 的建设情况,本项目拟在项目建议书阶段选择城市 A 或是 城市 B 作为异地灾备城市,理由如下:
Ø 城市 A 和 城市 B 是 距离 XX 市较近的且 不在地震带上的 CNGI 主节点城市,总带宽为 2.5GB 。
Ø 中国移动辽宁分公司已在城市 A 建设了高标准机房,完全能够满足异地容灾对机房环境的要求。
Ø 城市 B 市 已经 建设了高标准云计算 中心 ,完全能够满足异地容灾对机房环境的要求。
CNGI主干网拓扑图如下:

1.6.3. 数据 复制技术的选择
在数据 复制技术的 选择上,通过比较存储层 、主机层以及数据库层的数据复制技术 的优缺点后,以及 结合用户的业务系统现状, 我们认为,本项目采用支持 异构平台的 基于数据库层 和存储层的数据复制技术 。
经过调研 发现,各委办局的关键数据多为结构化的数据库数据,存储在 Oracle 、 SQL Server 等 异构数据库平台上,采用支持异构平台的数据库 层 数据复制技术,可以实现异构数据库平台的统一容灾, 具有 良好的扩展性和开放性,同时具有较高级别的 RTO 和 RPO ,并且支持两地三中心的架构。
用户另一类 关键数据是 大量 的虚拟机镜像、文档等非结构化数据,这些数据也是分散存储在多套异构磁盘阵列上 。因此 本方案采用基于存储虚拟化功能的 异构 平台存储层数据复制技术, 该 技术 对 底层磁盘阵列没有严格的限制, 可以 在同构盘阵和异构盘阵之间 实现 数据复制,具有同步、异步多种工作模式,满足不同级别 RPO 、 RTO 用户 的要求 。同时 , 存储 虚拟化技术支持存储设备进行横向和纵向的扩展,满足 未来各委办局 数据增长 的 需要,具有良好的扩展性。
数据 复制技术是用来解决 设备 down 机 、机房断电 、 自然灾害等物理故障的技术,为了解决 人为 误删除、病毒感染等逻辑故障对生产系统的业务连续性影响,本方案 又 引进数据备份 这项 技术。
2. 推荐 方案概述
2.1. 技术 路线选择
经过上述 现状的综合分析 , 我们 计划 基于 两地 三中心灾备模式构建 XX 电子政务 灾备 方案 ,其中 以 新建 的 XX 市云计算中心作为各委办局业务系统的主数据中心, XX 市网站管理中心作为同城 灾备 中心, 可以 选用 成都 云计算中心作为异地灾备中心 。
云计算 中心作为 主生产中心,负责日常的各委办局所有业务系统的运行。 在灾难发生时,在同城容灾中心恢复各委办局 关键业务 的应用运行。 在成都 异地灾备 中心完成各 委办局 关键 数据的 保护,在发生地区级( XX )的灾难时,保证各个业务系统的核心数据不丢失。
根据各委办局 的 技术架构现状与策略制定,结合容灾技术的关键技术分析与最佳实践,制定如下容灾架构:
Ø 容灾 模式为两地三中心灾备模式
Ø 容灾 级别 为数据库 系统实现应用 级别 容灾,其他应用系统基于同城容灾中心实现应用级容灾,基于远程容灾中心实现数据级容灾
Ø 结构化 数据复制采用 支持 异构平台的基于数据库层 的 GoldenGate 数据 复制 技术 ,虚拟机 镜像等这类关键 非结构化 数据复制 采用 基于 存储层 的数据复制 技术
Ø 虚拟机 之间的 系统 切换技术 以自动 切换方式为主,物理机之间以及物理机和虚拟机之间的系统切换以手工切换方式为主,并配合 切换 脚本 减少 系统切换时间
Ø 容灾网络,建议 同城数据中心之间采用大二层的存储网络架构,数据网络和存储网络的物理连接采用 DWDM 裸光纤 高速网络连接, 本地 和异地数据中心之间采用 IP 网络 连接,网络带宽要保证 系统切换的顺畅和数据复制的带宽需求
Ø 前端(客户端 ) 网络切换 技术有手工切换、 DNS 重定向 和负载均衡器的健康路由注入几种,本方案建议根据实际情况选择以上切换技术的一种或几种
Ø 容灾 系统和生产系统之间的配对关系为降级配对,就是容灾中心和生产中心之间的软、硬件配置不遵循 1:1 比例 , 容灾 中心硬件配置的性能低于生产中心 ,容灾 应用服务器以虚拟机平台为主, 从而 进一步提升灾备系统的投入产出比
2.2. 总体 方案架构
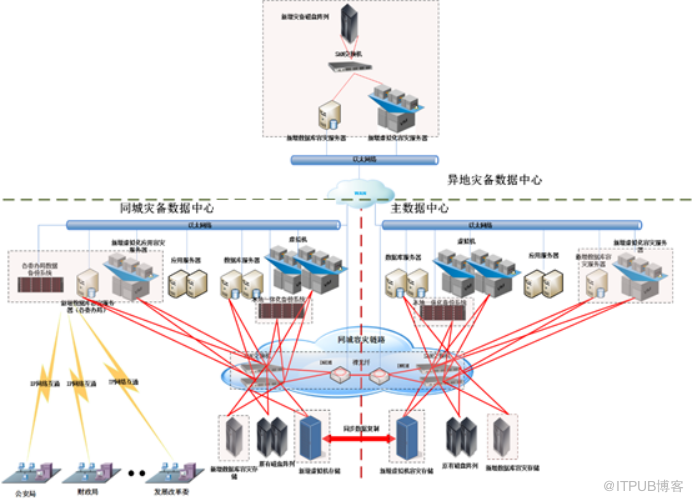
本 项目 两地三中心灾备项目的整体架构图如上 所示。 从 容灾层次上来说 ,本 方案 包括 备份和容灾两个层次 。
其中备份( 主要是 数据备份) 是指 在专用的备份系统 中 保存多个历史点的 生产 数据, 当 生产数据因为人为误操作、病毒感染等原因出现逻辑故障时,可以从 备份 系统中 选择 合适历史点的数据进行恢复, 备份 的数据类型可以是常见的数据库这类结构化数据,也可以是操作系统、虚拟机镜像、文件和应用程序等这类非结构化数据,由于备份窗口的原因,数据备份的 频率 通常不会 很 频繁,通常为 小时 、天甚至是周级别。
容灾 是为了防止硬件故障、电力中断、地震灾难等 物理 故障对业务系统所 造成 的应用中断, 其 最关键的技术就是数据复制技术。 本 方案数据 复制 分为结构化数据的复制和非结构化数据的复制两部分,其中 结构化 数据复制由 支持 异构数据库复制的 GoldenGate 实现,虚拟机 镜像等非结构化数据 的复制 由存储层的技术实现。
一 、 基于数据库复制 技术的结构化数据 容灾 系统
数据库系统的容灾方案,本 方案 建议基于成熟 的商业版软件 Golden Gate 实现,采用 Golden Gate 复制日志记录,实现各 委办局多个数据库在同城容灾中心和异地容灾中心的容灾、以及本地两个数据中心之间 数据库的互备,保证结构化 数据 访问的连续性。
Golden Gate 实现数据库容灾的技术手段成熟,管理维护相对容易, 没有操作系统和数据库版本的限制 (不过 Golden Gate 对 Oracle 9 i 及以下 版本 的 支持 有些 限制 , 对 10g 及 以上版本支持 的 更好),具有更好的兼容性 。对于 TB 级数据库,其传输日志的带宽需求在 10M 一下,网络建设成本比较低。
二 、 基于存储层 数据复制技术构建 非结构化 数据 容灾 系统
对于 虚拟机镜像、应用程序等关键 非 结构化数据的保护 建议 采用 存储 层次的 容灾 方案, 该 方案建议基于 高效 的存储层复制技术实现, 利用某公司高端 磁盘阵列 的 Metro Cluster 和 SnapMirror 数据镜像和数据复制功能,可以实现 两地 三中心 多套磁盘阵列 的互备, 保证 数据 访问 的连续性。 同时 , 可以 整合其他厂商的磁盘阵列,通过这种技术,可以实现异构 存储 平台之间的数据迁移和数据复制,是构建复杂异构 IT 系统容灾 方案的理想平台。
2.3. 数据库 容灾系统设计
对于 数据库 这类 核心应用系统,建议 构建 高级别的 容灾 方案。 综合 分析现有业务 系统数据库 应用情况,本方案建议采用 成熟 的商业版软件 Golden Gate 构建 数据库容灾方案。
Golden Gate 的数据延迟为亚秒级,处理数据能力高。支持广泛 的 异构数据库 应用环境 ,源和目标数据库端的操作系统和数据库可以任意组合,支持一对一、一对多、多对一、双向复制等多种灵活拓扑结构,并 且 有完整的技术支持方案,是建立异构平台或异构数据库的容灾与应急备份方案 、 双活 数据 中心的唯一 选择。
结合容灾 性能指标以及预算的情况,本方案建议在 同城 容灾中心 和 远程容灾中心 各新增 1 套 ( 1 台 或多台) Standby 数据库服务器 , 基于 Golden Gate 灾备 技术实现多个委办局异构数据库平台到 同城 容灾中心 的 集中容灾 ,同时实现同城灾备 中心 数据库 系统到 远程 灾备中心和数据库 远程 容灾。
对于各委办局 的 某一个 数据库应用来说,当 某个生产库 出现故障时 :如果生产库 和容灾库同构, 在 理想情况下( 数据 完全同步且可用、 容灾 链路带宽充足、设备运行良好) , 可以在 分钟 级别切换到 同城 容灾数据库 ; 如果生产库和容灾库异构,那么无法进行数据库切换操作,只能通过方向复制的方法把容灾库的数据恢复到生产库中。 如果同城 数据中心的数据库系统同时出现故障, 可以利用 远程容灾库进行生产库数据的恢复,由于异地容灾数据库与生产库的数据有一定的延迟,有可能会丢失部分数据。
Standby 数据库 服务器的数据和配置可以低于生产数据库 服务器 , 采用 降级容灾配置方案 , 用于节省硬件平台的投资预算 ;可以 先对几个关键业务 实现 数据库灾备保护, 未来实现 全业务数据库容灾。
2.3.1. Golden Gate技术 原理
Golden Gate 软件需要安装在源数据库服务器和目标数据库服务器上,所需的操作系统资源在 10% 以下。 Golden Gate 数据同步的基本原理是由 Extract 进程读取源数据库的事物日志( Oracle 中是 redo log ),将其中的变更操作( insert 、 update 、 delete 等)按事务执行的顺序组合在一起,直接将其发送到目标服务器上,或者存放到 Trails 文件中,然后由 Data Pump 进程将 Trails 文件传输到目标服务器上,在目标服务器上 Collector 进程接收从源服务器传送过来的 Trails 文件,最后由 Replicat 进程将 Trails 文件中的数据装载到目标数据库中,其处理过程如下图:
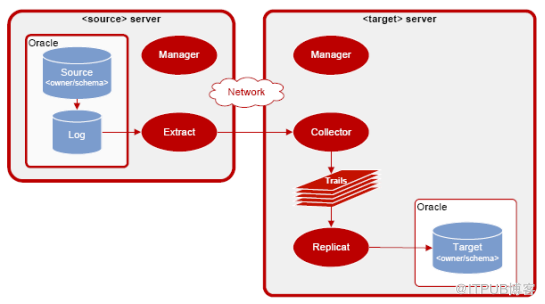
由于 Golden Gate 将数据存储到自己的统一格式的 Trail 文件中,因此可以将 Trail 文件传送到不同的操作系统,应用在不同的数据库系统上,大大增强其灵活性。
另外,由于 Golden Gate 只收集必要的数据到 Trail 文件中,且 Trail 文件可以压缩,因此大大减少通过网络传输的数据量,压缩后传输的数据量通常是日志量的 1/4 或更少。
Golden Gate 还可以分流查询,如下图所示:
Golden Gate 有以下优点:
Ø 支持异构的操作系统和数据库管理系统,便于客户在不同数据库管理系统和操作系统平台之间的数据同步,这是其核心优势所在;
Ø 跟 Data Guard 传输整个日志文件相比, Golden Gate 传输的数据量大大降低,在没有 LOB 等数据对象的情况下,通常是整个日志文件 1/4 或更少;
Ø 目标数据库处于打开状态,且支持一对多、多对一,双向复制等,也可以选择部分对象进行复制,可满足数据分发和数据集成的需要,减轻源数据库压力;

Ø 所占系统资源较少,通常在 10% 以下;
Ø Golden Gate 被 Oracle 公司收购后,对 Oracle 数据库的支持方面做的更好。
2.3.2. 各 委办局和同城容灾中心之间的数据库复制
为了能够便于维护和管理、最少 化 投资, 个委办局和同城容灾中心之间采用 N+1 模式 的数据库容灾, 同时 ,为了提升同城容灾中心数据库系统的可靠性和性能,同城容灾中心 建议 配置 2 台 以上 X86 架构 的 高性能 多路服务器组成 Oracle RAC 集群 系统 。各委办局 的多个 异构 Oracle 、 SQL Server 数据 库系统 通过 GoldenGate 数据复制软件实时备份到此 Oracle RAC 集群 系统 ,从而达到了容灾的目的。系统拓扑参考图如下:
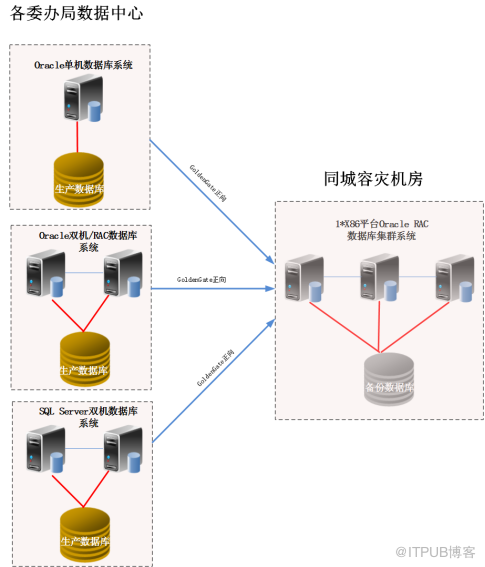
鉴于建立同城 容灾中心的 的目的是为了应用 级别 容灾,因此我们在同城 容灾中心 为各 委办局的多个核心应用 建立了不同数据库用户,将各 委办局的 各核心 应用 数据库数据复制到各自用户下的表中,一旦生产中心处于计划停机或非计划停机状态,同城 灾备 中心将接管生产中心的服务,保障业务的持续进行。为了在集群环境下实现节点间的负载均衡,我们可以 将生产中心的多个核心数据库应用划分为 N ( N = 同城容灾中心 Oracle RAC 集群节点 数量) 个小组 ,每个小组传送过来的数据由 RAC 集群 中的某个节点承担, 从而实现 RAC 多节点共同工作完成所有委办局数据的接收。
该 方案的应用特点:
N+1 灾备模式
各委办局 的多个业务的生产数据库分布在多套异构数据库系统 中 , 使用 GoldenGate 数据复制 技术 可以将多个 业务的 数据库集中备份到一套数据库备份系统,从而实现了 N+1 的备份模式,以较低的成本实现了容灾。 GoldenGate N+1 模式区别于其它技术的特点在于其能够实现多个数据库数据向一个数据库的逻辑集中,从而使得同城 灾备 中心在一个库中对各 委办局相关 数据的进行查询和统计,为今后建立数据仓库和开展 BI 等业务创造了条件。
异构平台支持
在本 方案中, 各 委办局的生产数据库系统是异构 的 , GoldenGate 支持 异构 数据库 系统之间的数据复制 。GoldenGate 这种跨平台复制的特性降低了 容灾中心的硬件投资, 减少 了后期管理和维护的成本 。
支持 双向复制
Golde Gate 支持 双向数据复制 模式 ,通过该模式,可以将 各 委办局的某些数据库负载均衡到同城容灾中心, 从而 提高同城容灾中心的设备利用率 , 降低生产中心的负载。

双向数据复制是基于单向数据复制原理之上,两端互为源 / 目的数据复制对象,两端生产系统同时保持 Active 状态。在这种配置模式下, GoldenGate 采用必要的冲突处理机制来解决可能发生的冲突。
为了避免出现刚被复制进对端目的数据库数据马上又被捕捉进程复制回源端,陷入死循环的状态。 GoldenGate 采用了相应的判别机制来保证对捕捉数据的识别,当应用程序和 GoldenGate 复制进程同时更新同一个表时 , 捕捉进程使用了一个跟踪表机制。在配置双向数据复制时 , 需要通过命令行向两边的数据库中加入跟踪表。当捕捉进程读到一个交易中有针对跟踪表的更新 , 捕捉进程就知道这个交易是由复制进程产生的并且把这笔交易忽略掉 . 如果没有针对跟踪表的更新 , 捕捉进程就知道这个交易是由应用程序产生的并且把这笔交易读取出来 .
通过以上处理机制后,就可以很好的解决双向数据复制中所担心的重复捕捉变化数据的操作出现。
2.3.3. 同城 容灾中心和异地 容灾 中心之间的数据库复制
同城 容灾中心和 异地 灾备中心之间采用 1+1 模式 的数据库容灾, 本方案 建议 在 远程容灾中心 配置 1 台 X86 架构 的 高性能 多路服务器组成 Oracle 异地 容灾数据库系统 。同城容灾 中心的 Oracle RAC 集群 中 的数据通过 GoldenGate 数据复制软件备份到远程 容灾中心 Oracle 数据库 系统 ,从而达到了远程容灾的目的。系统拓扑参考图如下:
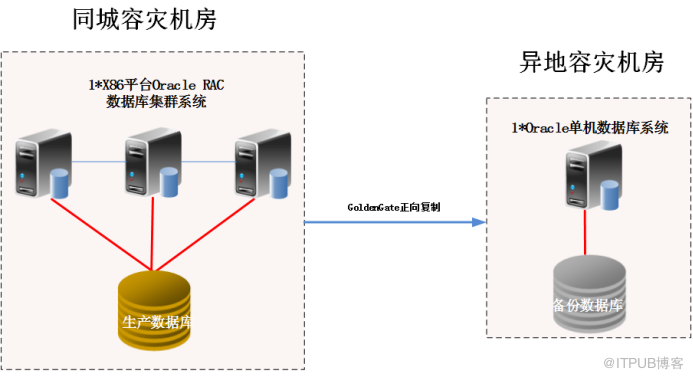
为了 进一步节省投资,同城容灾机房和异地容灾机房之间的 同构 Oracle 数据库 复制可以采用免费开源的 DataGuard 数据库 复制 技术 实现。
2.4. 非 结构化数据容灾系统设计
对于虚拟机 镜像、 应用 程序以及关键文档这类存储在多台异构磁盘阵列中的关键数据,本方案建议 基于 存储层的数据复制技术构建容灾方案。 存储 层数据复制技术 支持 数据镜像和数据复制技术, 与 上层应用 无关 , 不占用 上层应用服务器的资源, 是 应用最广、最成熟的数据复制技术,是构建异构 平台 双活数据中心、两地三中心数据灾备方案的理想选择。
本 方案 建议 在主生产中心、同城容灾数据中心 新增 一套 双活 存储系统, 每个 数据中心各放置一半的存储 设备 , MetroCluster 是 一种基于同步数据镜像技术 的 存储高可用技术,上层应用的每一次 I/O 操作 会 在 两个数据中心之间的 存储 设备之间 同步 ,任一扩展柜或是控制器出现故障不会 影响 上层应用的正常访问, 可以 实现数据近乎不丢失( RPO=0 ) 。
同时在远程 容灾 中心 新增一套 磁盘阵列 , 通过盘阵的 SnapMirror 数据 复制技术实现同城容灾中心 关键 非结构化数据到远程数据中心的容灾, 由于 同城容灾中心和远程容灾中心之间的距离较长, 网络 延迟较高,建议采用异步数据复制模式 。 当本地 两个 数据中心的存储系统同时出现故障时,可以 从 远程容灾中心实现数据的快速恢复 (可能 会丢失部分数据)。
同步数据 镜像模式对灾备链路要求较高,建议本地两个数据中心 之间 租用性能不低于 4Gb 的 裸光纤链路连接 , 为了 提高 容灾链路的利用率,建议配置 DWDM 设备 , 实现存储层数据 复制链路和 上层 应用数据链路 的 复用, 从而 减少容灾链路的投资 。异步 数据复制模式对数据带宽和延迟要求没那么严格,因此,同城 和 异地数据中心之间采用 IP 网络 连接即可。
为了 进一步节省成本, 远程 容灾磁盘阵列的配置可以适当低于生产磁盘阵列。
2.4.1. 同城 容灾中心和生产中心之间的数据容灾
本方案 同城容灾中心需要基于存储层的数据复制技术使用应用级容灾,为了实现该灾备目标,本方案 建议 对同城容灾中心和各委办局生产中心做适当的改造 : 一、把 同城 容灾中心和生产中心需要进行灾备保护的关键非结构化数据如虚拟机镜像、关键文档 等 集中迁移 或 存储到新增 磁盘阵列 中 ;二 、 首先对各 委办局需要实现应用级容灾的 物理 应用服务器 进行 适当的改造 , 把应用服务器需要 修改 的数据集中存储在 数据库或是 盘阵中,不需要修改的数据可以存储在本地 硬盘中 , 然后 利用 VWware 的 P2V 工具 为这些物理应用服务器做 虚拟机 镜像,并把镜像数据存储在新增 盘阵中。
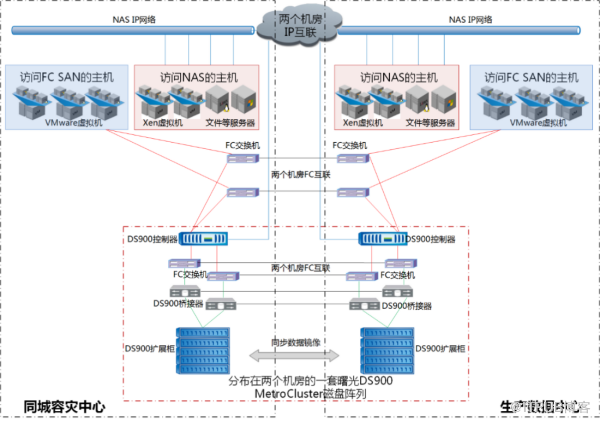
改造 完成后, 利用 DS900 的 MetroCluster 功能实现 关键数据在同城容灾中心和生产数据 中心 的互备, 构建 双活存储系统,系统架构图如上所示 。
本 方案在 同城 容灾中心和 生产 数据中心 各 部署 1 个 DS900 控制器 、 2 个 DS900 扩展柜 、 2 套 24 端口 FC 交换机 ( 若现 、新大楼之间的距离少于 500 米 ,可以不用交换机) 、 2 套 DS900 FC-SAS 桥接器 , 两个中心 之间的 DS900 主机头 和扩展柜通过 FC 交换机和 桥接器 组成 高可靠的冗余 存储 网络; 两个 数据中心 DS900 盘阵 里的数据基于 MetroCluster 技术 实现实时 数据 同步 , 两个中心之间的 任一 主机头或是扩展柜出现故障,不影响前端应用的正常运行 , 任一 中心 的 DS900 设备全部故障,也 可以 确保在很短的时间内 将 存储 自动 切换到 另一中心 。
同城容灾 中心和生产数据中心之间通过 DWDM 裸光纤 实现 FC 存储和 IP 数据链路 互通, DS900 同时 支持 FC 、 iSCSI 和 NAS 存储 协议,这样 基于 MetroCluster 技术 实现的双活存储系统本身就具备了统一存储功能, 可以为 上层 各种 应用按需提供 存储 服务。
同时, DS900 支持 异构存储资源整合,后期用户新购的 异构 磁盘阵列可以 通过 这套 DS900 主机头 进行整合, 形成 统一存储资源池,便于后期扩展、管理和使用,并有效的提高存储资源率。
两个 数据中心的 DS900 MetroCluster 双活 架构 实现了存储服务与数据的热备( 有 两份实时同步副本) , 同时为了预防数据误删除的恢复、查看调用某个阶段的原始数据,以及应对一些灾难情况,本方案同时为 DS900 配置 SnapShot 功能 进行数据备份 。SnapShot 基于时间点的指针型数据快照技术 ,结合 SnapRestore 快照数据恢复软件可以 显著节省备份时间和恢复时间 , 同时节省备份空间 。 基于 快照 技术实现的备份数据 无需 恢复,可直接挂接到主机上进行验证和分析。
考虑 到实际情况,这套 DS900 MetroCluster 双活 存储系统 初期 全部放置在同城容灾中心,等生产数据中心完成建设后,再把 一半 的存储系统迁移到 生产 数据中心。
Metro Cluster 工作 原理
MetroCluster 技术是结合了 的 数据镜像功能、数据快照功能、阵列双控制器双活和故障切换保护功能 , 并在这些功能远距离实现(最远 160 公里)的基础上所实现的一项提供存储系统高可靠性保证和数据访问双活架构的存储功能 。
MetroCluster 技术把一套 DS900 标准的双控制器配置的存储系统分为两部分,每部分包括各自的控制器和磁盘柜,然后把两部分分开部署,最长距离可以达到 160 公里。如果两部分之间的距离不超过 5 米,则可以直接使用普通的 FC 和 SAS 连接线相互连接,如果两部分之间的距离超过 5 米,则需要配置 4 套专用的 SAN 交换机 和 4 套 FC-SAS 桥接器 实现两部分的互连。这样一套 MetroCluster 存储系统的两部分可以部署在同一个机房中,也可以分开部署在用户的两个机房,而在逻辑上,这分开部署的两部分组成的存储系统仍旧是一套存储系统,两个控制器之间的负载均衡和故障切换功能和标准的本地双控制器的存储系统完全一致,一个部分的控制器失效,另外一个部分的控制器会自动接管其工作,且对前端应用系统透明。
MetroCluster 技术增强了 DS900 的 Sync Mirror 数据镜像功能从而实现数据的远距离镜像,即数据在一套 MetroCluster 存储系统分开部署的两部分之间实现镜像,只要镜像的这两份拷贝有一个有效,就可以保证数据的正常访问。
结合上述两点, MetroCluster 为用户提供了一种比传统的硬件冗余保护架构更高级别的可靠性保证,就算组成 MetroCluster 存储系统的两部分中的某部分存储部件完全失效,另外一部分的控制器可以利用镜像过来的数据接管故障部件所承担的工作,以保证用户应用系统的持续性,且这个接管动作由存储系统自动进行,对前端应用透明。
如果 MetroCluster 存储系统的两部分分开部署在两个机房,则利用两个机房互连的 SAN FC 网络和 NAS IP 网络,前端应用主机可以在任何一个机房访问同一份数据,因此实现了数据访问的双活架构。用户可以根据自己的实际情况把应用系统部署在 任意 一个机房甚至同时部署在两个机房。
在 MetroCluster 存储系统的任何一部分中所进行的数据快照,都会被自动的镜像到另外一部分中进行保存,因此实现了数据快照的镜像保护,提升了数据快照对逻辑性错误和硬件错误的双重抵御能力。
2.4.2. 同城 容灾中心和远程容灾中心的 数据 容灾
为了进一步 提高数据保护的级别,可以 在 另外一个城市 建立 远程 容灾 中心 。在远程 容灾中心新增一套磁盘阵列, 基于 SnapMirror 技术 , 实现 同城容灾中心关键非结构化数据到远程容灾中心的复制,当本地 MetroCluster 双活 存储系统 都 出现故障后,可以 利用 远程 盘阵 里的数据实现数据恢复。 基于 以上措施构成的 完全 数据保护 方案 架构图 如下 所示:
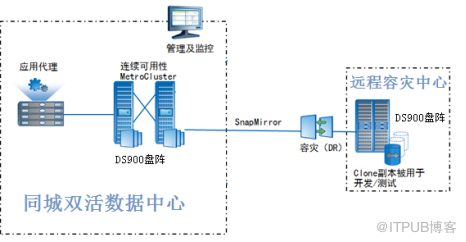
SnapMirror 技术 原理
SnapMirror 技术将数据镜像到一个或多个网络 Filer 上。 SnapMirror 不断地更新镜像数据,以确保数据是最新的,并且能够用于进行灾难恢复、减少磁带备份、发布只读数据、在非生产性 Filer 上进行测试、执行联机数据迁移等等。 SnapMirror 可以将同一数据发布到所有地点。通过自动更新这些数据,并支持对镜像数据的本地访问方式, SnapMirror 可以大大提高员工的工作效率 , 提高数据保护级别。
SnapMirror 技术 优势
Ø SnapMirror 支持多种复制方式,用于适应不同的容灾环境,包括:同步,准同步,异步。异步方式的复制对于距离没有限制。
Ø SnapMirror 支持多种网络环境,用于适应不同的容灾环境,包括: IP 接口和 FC 接口。
Ø SnapMirror 支持多种拓扑方式的复制,包括: 1 对多;多对 1 ;级联复制等。
Ø SnapMirror 支持对多种数据的复制,包括:基于卷的复制,基于 qtree 的复制,支持对 NAS / SAN /iSCSI 中的数据复制。
Ø SnapMirror 只传输变化的数据块,可以大大节省网络带宽和减轻 Filer 的负载。
Ø 通过使用 SnapManager ,与 SQL 、 Oracle 、 Exchange 、 SharePoint 、 Virt 等实现了集成,从而简化故障转移和灾难恢复。
由于 同城 容灾 中心和远程 容灾 中心之间的距离相距较远, 为了减少 容灾链路带宽投入,本方案建议 采用 SanpMirror 异步 数据复制技术,容灾链路采用 IP 网络 构建即可。
2.4.3. 应用级 容灾几种实现方式
基于 存储复制技术实现应用级 容灾 ,可有如下 几种 方式:
Ø 受保护 和 容灾的应用服务器同为虚拟机,那么基于 DS900 MetroCluster 双活 存储系统, 利用 虚拟机的 HA 技术 即可实现虚拟机应用级别容灾;
Ø 如果 受保护 的 应用服务器为物理机,容灾的 应用 服务器为虚拟机, 那么利用 VMWare 的 P2V 技术 先对 物理机 做 一个 虚拟机镜像,并把该虚拟机镜像存储在 DS900 双活 存储系统中, 物理 应用服务器出现故障时,可以人为启动该虚拟机镜像, 实现 应用级切换;
Ø 如果受 保护和容灾的应用服务器都需要是物理机,那么 可以 利用 成熟 的双机技术或是 物理 备机技术实现应用级容灾,所谓物理备机就是 在 同城容灾中心配置一套 相同 架构的物理服务器, 并 配置成和应用服务器相同的 软件 环境, 当 生产应用服务器出现故障时,管理员 手动 把这台备机启动,也可实现应用级容灾。
2.5. 一体化 集中备份系统
考虑 到人为误操作、病毒感染等 操作 所带来的数据逻辑错误,建议对 各 委办局以及本地两个数据中心 的 关键数据 做 备份保护,结合以上 两种 数据容灾方案,形成完善的数据保护体系。
本 方案 需 配置 3 套 一体化备份系统, 其中 两套 放置 在同城容灾中心,一套放置在生产数据中心。 同城 容灾中心的其中 1 套用于各委办局关键数据在 同城 容灾中心的集中备份, 另外 一套实现对 同城 容灾中心 关键 数据的本地集中备份。 放置 在生产数据中心的 备份系统 实现对生产系统关键数据的本地集中备份。
如果 需要 把 关键数据在远程也集中备份一份,那么 需要在远程的容灾中心配置一台容灾服务器和一个磁盘阵列,容灾服务器上配置备份系统的一个 Lan-Free 智能客户端模块,利用备份系统的 Datacopy 功能将本地备份的数据拷贝到远程智能客户端所连接的磁盘阵列里。备份网络需要租用运营商带宽或建设专网,并要根据网络状况和拷贝的数据量设置合适的时间点和策略。备份功能 架构图如下所示。
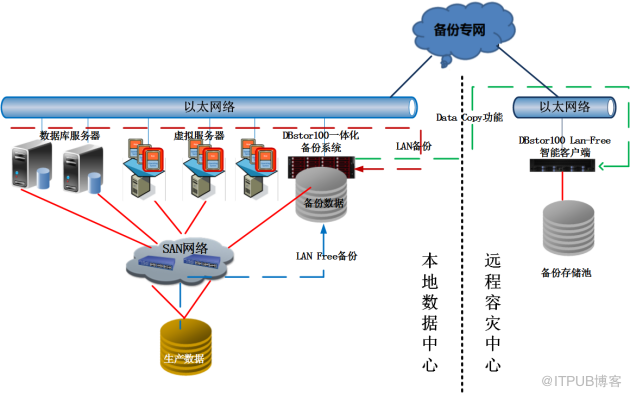
备份 的数据可以是数据库、虚拟机镜像,也可以是操作系统和 关键 文件。 支持 LAN 备份 以及 Lan-Free 备份 模式。 对于 关键数据备份频率可以 设置 为每周一次全备,每天做一次增量备份 或是 差异备份 ,本地局域网的带宽较大,可适当加大备份的频率。
如果各委办局 或是本地 生产 数据 出现人为误操作或是不可恢复的硬件故障所导致的数据逻辑错误时,可以利用本地 的 备份数据进行恢复, 取决于需要恢复的数据量 以及 容灾链路带宽 , 一般恢复操作需要数小时甚至数天。 如果 本地的 备份 数据同样出现 逻辑 故障,可以利用远程的 备份 数据进行恢复 。
2.6. 容灾网络 建设方案设计
容灾通信链路设计是容灾系统建设非常重要的部分,也是容灾方案设计的难点、要点之一,本章节对这一部分内容进行详细描述。
不同的通信链路有不同的要求,如距离限制、带宽能力等;而不同的容灾技术、不同的容灾应用对通信链路的要求不同;采用同步方式或采用异步方式进行数据复制对通信链路的要求也大不相同。
根据用户的不同要求进行科学的通信链路设计是保障用户在合理的通信成本下成功实现容灾系统建设的重要步骤之一。
2.6.1. 整体容灾网络架构设计
根据其作用不同,网络系统分为计算网络、存储网络和对外 服务 网络。其中计算网络用来实现服务器设备之间的通信,根据对带宽、延迟的不同要求,可以基于千兆、万兆以太网或是 Infiniband 、 Myrinet 等高性能网络构建;存储网络用来实现服务器和存储设备或是存储设备之间的数据通信,通常基于 FC 、千兆和万兆 IP 网络( iSCSI 、 NFS 、 CIFS 等)或是 Infiniband 网络构建;服务网络用来为 互联网或是局域网用户提供服务, 对网络带宽要求不高,通常采用百兆或是千兆以太网络即可。
在设计网络系统的时候,计算、存储和对外 服务 网络可以共用一套物理网络,但是为了提高系统可靠性,减少不同类型通信之间的性能影响,建议这三套网络要实现物理隔离,各自构建自己的网络链路。另外,为了进一步提高 IT 系统可靠性和性能,计算网络和存储网络一般采用双网架构,双网以主、备或是负载均衡模式工作。

经过以上分析,若要实现应用级的容灾,那么生产中心和容灾中心之间通常需部署三种互联链路,每种互联链路所承载的数据不同,实现的功能不同,并且这三种链路在逻辑上相互隔离。
网络三层互联。也称为数据中心前端服务网络互联,所谓 “前端服务网络”是指数据中心面向广域网的出口。不同数据中心(主中心、灾备中心)的前端网络通过 IP 技术实现互联,客户端通过前端网络访问各数据中心。当主数据中心发生灾难时,前端网络将实现快速收敛,客户端通过访问灾备中心以保障业务连续性;
网络二层互联。也称为数据中心服务器数据网络互联。在不同的数据中心服务器网络接入层,构建一个跨数据中心的大二层网络( VLAN ),以满足服务器集群或虚拟机动态迁移等场景对二层网络接入的需求;
SAN 互联。也称为后端存储网络互联。借助传输技术(裸光纤、 DWDM 、 FCIP 等)实现主中心和灾备中心间磁盘阵列的数据复制。
2.6.2. 前端服务网络容灾方案
正常情况下,用户、分支机构等都是连接到主数据中心,当主数据中心发生故障之后,用户、分支机构等都应该能切换为与备份数据中心相连接,实现这种前端网络(客户端)切换的技术主要有以下几种:手工切换、 DNS 和 HTTP 重定向以及健康路由导入等。
手工切换
手工切换的技术通常应用于异地灾备中心或是同城容灾中心。
例如:生产中心的 IP 子网为 A.B.0.0 ,正常情况下,用户和分支机构都会通过这个网段来连接到生产中心,容灾中心的子网也是设置为 A.B.0.0 ,但正常情况下容灾中心的网段是关闭着的,当生产中心发生灾难时,此时手动操作打开容灾中心的网段,用户和分支机构不做任何修改便可以连接到容灾中心。
这种方式操作最简单,也不需要额外的设备和技术支持,但是需要人工干预。
DNS 重定向
DNS 重定向是同城容灾中心和双活数据中心常使用的一种网络切换技术。
要实现 DNS 切换方式,在主数据中心和容灾中心的部署中必须要有一个智能的 DNS 设备作为站点的域名解析 服务器 ,当用户需要访问某一个应用服务器时,系统首先会将请求发送到数据中心的 DNS 服务器 进行处理, DNS 设备常具有应用感知功能,它可以监控数据中心 WEB 服务器 、应用服务器等的状态。当主数据中心正常时, DNS 会将主数据中心服务器的 IP 地址回给用户,这时用户就连接到主数据中心了。
当主数据中心发生灾难时,主数据中心的 DNS 设备检测不到它的服务器状态,此时灾备中心的 DNS 设备便将备份数据中心服务器的 IP 地址回给用户,用户连接到灾备中心。
健康路由注入
健康路由导入也是同城容灾中心和双活数据中心常使用的另一种网络切换技术。
要采用这种技术,生产中心和灾备中心均需配置一套负载均衡设备,数据中心的 负载均衡 设备能探测数据中心后台服务器的健康状况,如果探测到的服务器状况良好, 负载均衡 设备便向 网络 中发送一条与负载均衡设备对应的数据中心服务器的主机路由。对于生产中心和灾备中心来说,它们发出的主机路由值不同,生产中心发送低 Cost 值路由,灾备中心发送高 Cost 值路由。两个数据中心都正常工作时,用户发送连接请求后会收到两条 Cost 值不同的主机路由,通常情况下会选择 Cost 值低的路由连接到生产中心。
当生产中心发生灾难时,请求连接的用户只能收到一条来自灾备中心的高 Cost 值路由,用户通过该路由连接到灾备中心。
总结
以上几种前端网络容灾技术综合比较如下:
对比项 | 手工切换 | DNS方式 | 健康路由导入 |
|---|---|---|---|
切换速度 | 分钟 | 1分钟 | 秒 |
客户端软件配置 | 不需要修改 | 不需要修改 | 不需要修改 |
增加设备 | 不需要 | 增加DNS服务器 | 增加负载均衡器 |
可扩展性多中心,多服务器 | 较低 | 高 | 高 |
分pei方法 | 静态连接,用户交易随机发送 | 可根据数据中心负载、用户距离分配 | 只能在数据中心间平均分配 |
2.6.3. 服务器数据网络容灾方案
在传统的数据中心服务器区网络设计中,通常将二层网络的范围限制在网络汇聚层以下,通过配置跨汇聚交换机的 VLAN ,可以将二层网络扩展到多台接入交换机,这种方案为服务器网络接入层提供了灵活扩展能力。近年来,服务器高可用集群技术和虚拟服务器动态迁移技术(如 VMotion )在数据中心容灾及计算资源调pei方面得以广泛应用,这两种技术不仅要求在数据中心内实现大二层网络接入,而且要求在数据中心间也实现大范围二层网络扩展 (DCI: Data Center Interconnection) 。
EVI ( Ethernet Virtual Interconnection ,以太网虚拟化互联)是一种实现异构网络二层互联的技术。 EVI 采用先进的 "MAC in IP" 技术,用于实现基于 IP 核心网络的 L2VPN 。通过 EVI 技术在站点的边缘设备上维护路由和转发信息,而无需改变站点内部和核心网络。
在 EVI 的组网方案中,不需要考虑数据中心之间的网络类型,只需要保证 EVI 边缘设备( Edge Device )之间 IP 可达就可以实现数据中心之间的二层互通。在 EVI 边缘设备之间建立 EVI 隧道,以太报文就可以通过该隧道到达另一个数据中心的二层域内,实现二层互联互通。
EVI 技术可以结合 IRF 技术使用,从而保证边缘设备的 HA 性能和双归属设计。另外,如果数据中心汇聚交换机也支持 IRF ,就可以有效提高边缘设备与数据中心汇聚交换机之间的链路带宽利用率和 HA 性能。
EVI 组网方案的优点非常明显:
支持 Overlay 网络,可以跨裸光纤、 MPLS 或是 IP 网络实现二层互联;
EVI 配置简单,只需要 6 条命令即可以启动;
EVI 支持 IRF ,可以有效提高系统的 HA 性能。
2.6.4. 存储网络容灾方案
当前业界存储网络容灾方案的通讯链路有 “裸光纤直连交换机方式、通过 DWDM 设备连接裸光纤方式、 IP 网络方式 ”等几种,每种方式各有利弊,以下对不同通信链路方式进行比较。
裸光纤直连
采用 FC 协议的通信链路只适用于基于存储复制或虚拟存储复制的容灾方案。在这类方案中,生产中心与备份中心的光纤交换机通过裸光纤直连,如下图所示:
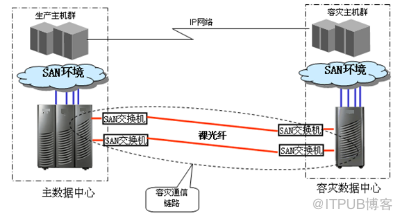
两个中心存储系统的容灾端口通过光纤交换机和裸光纤进行连接,可以保证同步或异步数据复制的性能。为保证高可用,通常采用冗余连接链路设计。容灾链路裸光纤可以和生产主机共享 SAN 交换机,也可以独立 SAN 交换机(也需要冗余)。通常为避免容灾链路通信和主机访问存储的相互干扰,采用独立的 SAN 来连接容灾通信链路的方式采用较多。
不同容灾方案需要的通信链路数量是不同的,具体需要链路的条数(即带宽要求)需要具体分析、计算获得。
CWDM/DWDM 直连裸光纤
采用密集波分复用技术,可以加载多协议,例如 FC 协议、 IP 协议,如下图所示:
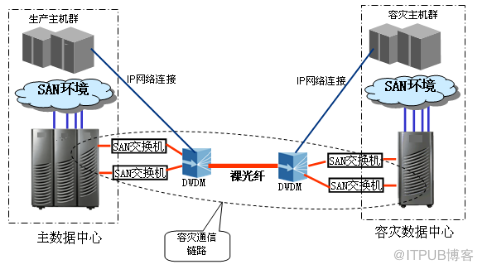
如上图所示 , 通过 CWDM/DWDM 技术,主数据中心和容灾数据中心的 IP 网络连接、 FC 连接都可以复用到共享裸光纤,比较好的解决了裸光纤的利用率和多协议复用的问题。为避免单点故障,同样可以采用冗余连接、没有单点故障的解决方案。同时,采用 CWDM/DWDM 方式有更多的拓扑方案,需要在具体设计时进行分析后确定。
IP 网络连接
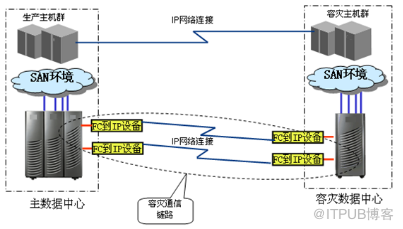
远程容灾中心存储网络通常基于 IP 网络构建。采用 “基于存储或基于虚拟存储”的容灾技术将需要进行 FC 协议到 IP 协议的转换,从而将 FC 加载在 IP 网络中传输。此方案采用国际流行的 IP 网络协议和链路,通过 FC/IP 转换设备,将 FC 通道协议打包在 IP 数据包内,通过 IP 链路传输,理论上没有距离的限制,适用于远程异步数据复制,是性价比很好的选择。连接示意图如下:
1.1. 解决好数据库系统数据复制
各委办局的业务系统普遍使用 Oracle 两种数据库,数据库的数据包括数据文件和日志文件,从原理上来说,数据库复制包括数据文件和日志文件的传输。
Oracle 数据库复制,通常是在两地部署数据库系统,将主站点的数据库全备份在备份站点恢复,此后即时传输变化的日志文件即可。对两地容灾的场景,日志传输采用异步的方式,不会影响主站点数据库性能。目前容灾系统上常用的 DataGuard 、 GoldenGate 、 SharePlex 等都是这种实现机制。
1.2. “现实”的切换策略
容灾规划中关于切换策略的制定,必须基于委办局各业务系统的特点,预先制定并定期演练,以便确保容灾系统有效运行。
切换方式分为两种,即手工方式和自动方式.
手工方式
手工方式是对于复杂的应用系统进行容灾切换的主要方式,手工方式需在备份中心按照对故障的判断,启动预先编写的业务系统切换脚本完成应用系统的切换过程.手工方式容灾切换过程需要人为介入,因此,容灾备份系统安全性以确保人员的安全以及对系统的访问能力为基础。
自动方式
自动方式可以实现应用系统的自动切换功能;保证当突发性灾难发生时,即使在无人值守的情况下,也能够实现系统的正常切换,确保业务系统能够实现全天候的正常运行。但是由于应用系统的复杂性,自动方式要求能够对用户选择的某类或某些业务种类的数据平台、业务平台和接入平台按照正确的关系完整切换。更重要的是,自动方式需要对复杂的系统环境中的各种故障作出正确分析判断,以根据事先定义的策略,触发相应切换流程。这样需要高度客户化、智能化的自动容灾切换系统,目前没有产品化技术可供选择。
切换
当主生产中心发生的故障或灾难影响到业务系统的正常运行时,应首先对业务系统的受影响程度进行检查,尽可能快速定位业务系统的故障部位。分别对机房受损程度、机房电源、计算机网络、系统硬件、操作系统、数据库、应用系统等进行检查,评估恢复时间,然后由相应人员决策是否进行系统切换,应考虑以下因素和原则:
一 、 故障影响程度可以分为两大类:
Ø 业务停顿,但故障范围明确,并且可在可忍受的时间内修复,不需要异地切换。例如:电源发生故障、软硬件故障、消防系统和空调系统等机房环境告警、人为因素误操作的情况,应用系统应建立相应的本地高可用性系统、备份策略,管理流程,采用专业服务支持、基础设施的防护等措施,来预防和避免故障对业务系统连续性运行的影响。
Ø 数据中心系统在可以忍受的时间内无法恢复或彻底破坏,必须进行容灾切换
二 、 优先选择本地恢复原则
当无法判定主中心的业务系统修复所需时间时,应在继续恢复主中心的系统的同时,在备份中心开始进行切换的准备工作。只要主中心的业务系统在可容忍时间内有恢复的可能,就应优先选择本地恢复。
三 、 优先恢复关键性业务原则
对于应用系统的各个子系统,根据停机时间所造成的影响和损失的大小的不同,优先恢复关键性核心业务。当备份中心的主机、网络等资源不足时,优先提供给关键性核心业务使用。
回切
当主生产中心的系统恢复以后,就应将业务系统由容灾中心回切到主生产中心。回切过程中要保证两中心的数据的一致性。
一 、 业务影响最小原则
系统回切不同于系统切换,由于灾难发生的随机性和不确定性,系统切换都是在被动的情况下发生的,有可能造成业务数据的丢失和切换时间较长,对业务的正常进行会造成严重影响。而系统的回切是可以按照事先的计划来实现的,因此在系统回切计划中,应选择业务量较小的时候,采用最简化的步骤回切;
二 、 及时性原则
业务系统由主数据中心切换到容灾中心后,核心数据不再有容灾保护,因此应尽快恢复主数据中心,并将业务系统回切到主中心,使核心数据重新得到容灾保护;
三 、 数据一致性原则
系统回切前需将数据由容灾中心复制到主中心,并保持严格的一致性。