
使用 Python 抓取 Reddit
在本文中,我们将了解如何使用Python来抓取Reddit,这里我们将使用Python的PRAW(Python Reddit API Wrapper)模块来抓取数据。Praw 是 Python Reddit API 包装器的缩写,它允许通过 Python 脚本使用 Reddit API。
安装
要安装 PRAW,请在命令提示符下运行以下命令:
pip install praw创建 Reddit 应用程序
第 1 步:要从 Reddit 中提取数据,我们需要创建一个 Reddit 应用程序。您可以创建一个新的 Reddit 应用程序 (https://www.reddit.com/prefs/apps)。

第2步:点击“你是开发者吗?” 创建一个应用程序......”。
第 3 步:类似这样的表格将显示在您的屏幕上。输入您选择的名称和描述。在重定向 uri框中输入http://localhost:8080
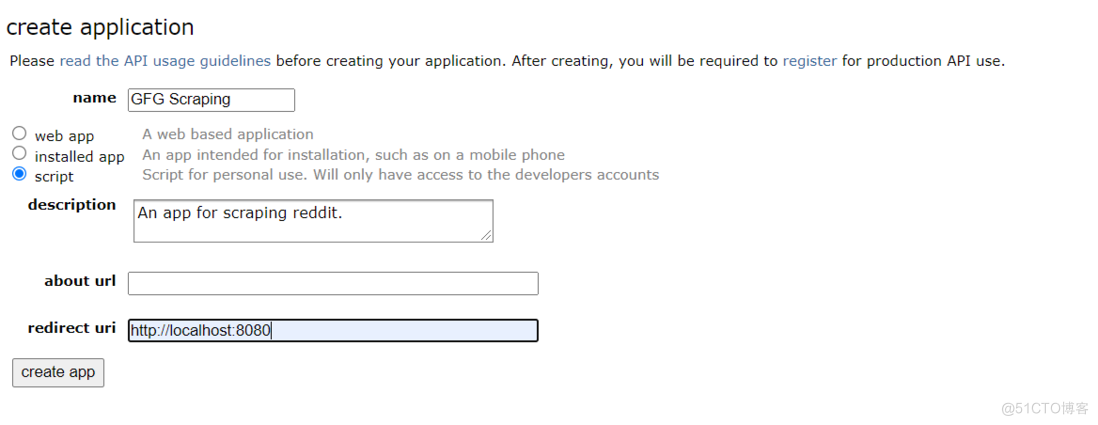
申请表格
第四步:输入详细信息后,点击“创建应用程序”。
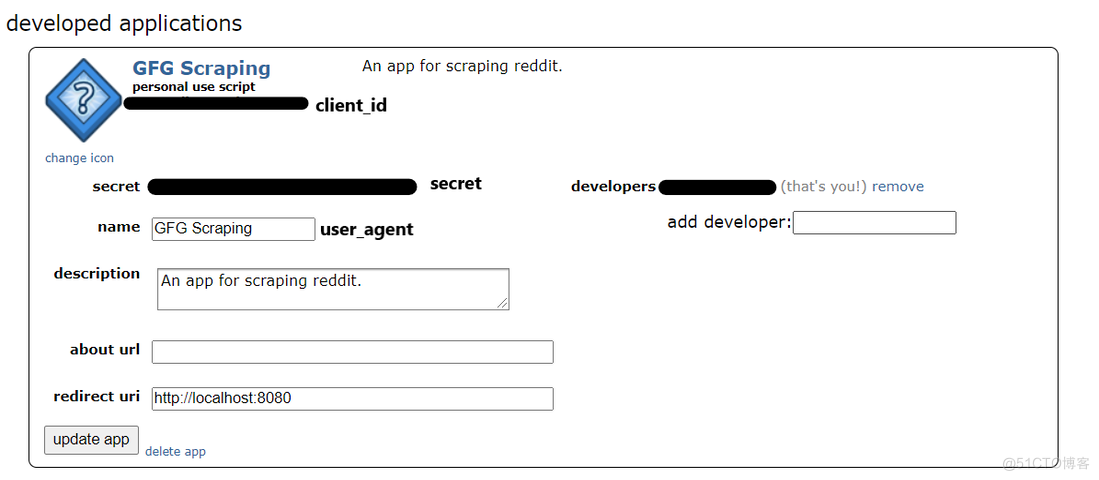
开发的应用程序
Reddit 应用程序已创建。现在,我们可以使用 python 和 praw 从 Reddit 上抓取数据。记下 client_id、secret 和 user_agent 值。这些值将用于使用 python 连接到 Reddit。
创建 PRAW 实例
为了连接到 Reddit,我们需要创建一个 praw 实例。有 2 种类型的 praw 实例:
- 只读实例:使用只读实例,我们只能抓取 Reddit 上公开的信息。例如,从特定的 Reddit 子版块中检索排名前 5 的帖子。
- 授权实例:使用授权实例,您可以使用 Reddit 帐户执行所有操作。可以执行点赞、发帖、评论等操作。
reddit_read_only = praw.Reddit(client_id="", # your client id client_secret="", # your client secret user_agent="") # your user agent授权实例
reddit_authorized = praw.Reddit(client_id="", # 您的客户 ID
client_secret="", # 您的客户秘密
user_agent="", # 您的用户代理
username="", # 您的 reddit 用户名
password="") # 您的 reddit 密码
现在我们已经创建了一个实例,我们可以使用 Reddit 的 API 来提取数据。在本教程中,我们将仅使用只读实例。
抓取 Reddit 子 Reddit
从 Reddit 子版块中提取数据的方法有多种。Reddit 子版块中的帖子按热门、新、热门、争议等排序。您可以使用您选择的任何排序方法。
让我们从 redditdev subreddit 中提取一些信息。
import praw
import pandas as pdreddit_read_only = praw.Reddit(client_id="", # 您的客户 ID
client_secret="", # 您的客户秘密
user_agent="") # 您的用户代理subreddit = reddit_read_only.subreddit("redditdev")
显示 Subreddit 的名称
print("Display Name:", subreddit.display_name)
显示 Subreddit 的标题
print("Title:", subreddit.title)
显示 Subreddit 的描述
print("Description:", subreddit.description)
输出:

名称、标题和描述
现在让我们从 Reddit 的 Python subreddit 中提取 5 篇热门帖子:
subreddit = reddit_read_only.subreddit("Python")
for post in subreddit.hot(limit=5):
print(post.title)
print()
输出:

热门帖子前 5 名
我们现在将 python subreddit 的热门帖子保存在 pandas 数据框中:
posts = subreddit.top("month")posts_dict = {"Title": [], "Post Text": [],
"ID": [], "Score": [],
"Total Comments": [], "Post URL": []
}for post in posts:
# 每个帖子的标题
posts_dict["Title"].append(post.title)# 职位内的文本 posts_dict["Post Text"].append(post.selftext) # 每个帖子的唯一 ID posts_dict["ID"].append(post.id) # 职位的得分 posts_dict["Score"].append(post.score) # 帖子内的评论总数 posts_dict["Total Comments"].append(post.num_comments) # 每个帖子的 URL posts_dict["Post URL"].append(post.url)在 pandas 数据框中保存数据
top_posts = pd.DataFrame(posts_dict)
top_posts
输出:
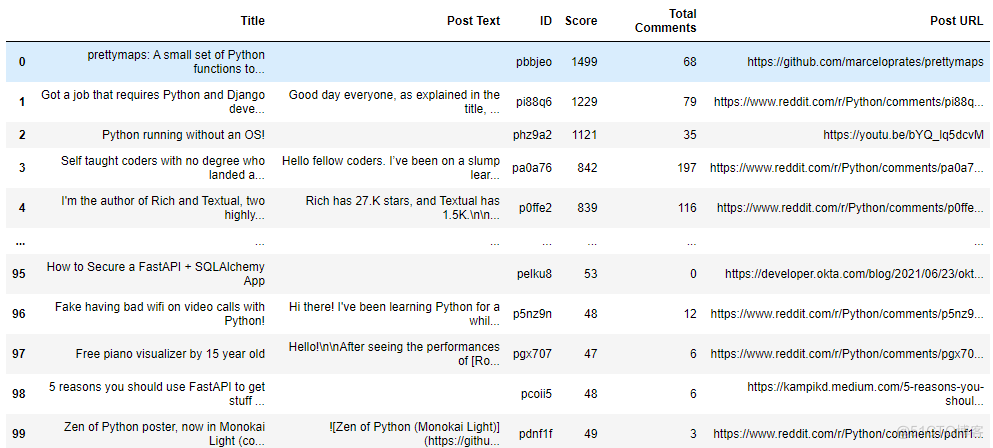
python Reddit 子版块的热门帖子
将数据导出到 CSV 文件:
import pandas as pd
top_posts.to_csv("Top Posts.csv", index=True)
输出:

热门帖子的 CSV 文件
抓取 Reddit 帖子:
要从 Reddit 帖子中提取数据,我们需要帖子的 URL。获得 URL 后,我们需要创建一个提交对象。
import praw
import pandas as pdreddit_read_only = praw.Reddit(client_id="", # your client id
client_secret="", # your client secret
user_agent="") # your user agentURL of the post
url = "https://www.reddit.com/r/IAmA/comments/m8n4vt/
im_bill_gates_cochair_of_the_bill_and_melinda/"创建一个提交对象
submission = reddit_read_only.submission(url=url)
我们将从我们选择的帖子中提取最佳评论。我们需要 praw 模块中的 MoreComments 对象。为了提取评论,我们将在提交对象上使用 for 循环。所有评论都会添加到 post_comments 列表中。我们还将在 for 循环中添加一个 if 语句来检查任何评论是否具有 more comments 的对象类型。如果是这样,则意味着我们的帖子有更多可用评论。因此,我们也将这些评论添加到我们的列表中。最后,我们将列表转换为 pandas 数据框。
from praw.models import MoreCommentspost_comments = []
for comment in submission.comments:
if type(comment) == MoreComments:
continuepost_comments.append(comment.body)创建数据帧
comments_df = pd.DataFrame(post_comments, columns=['comment'])
comments_df
输出:
