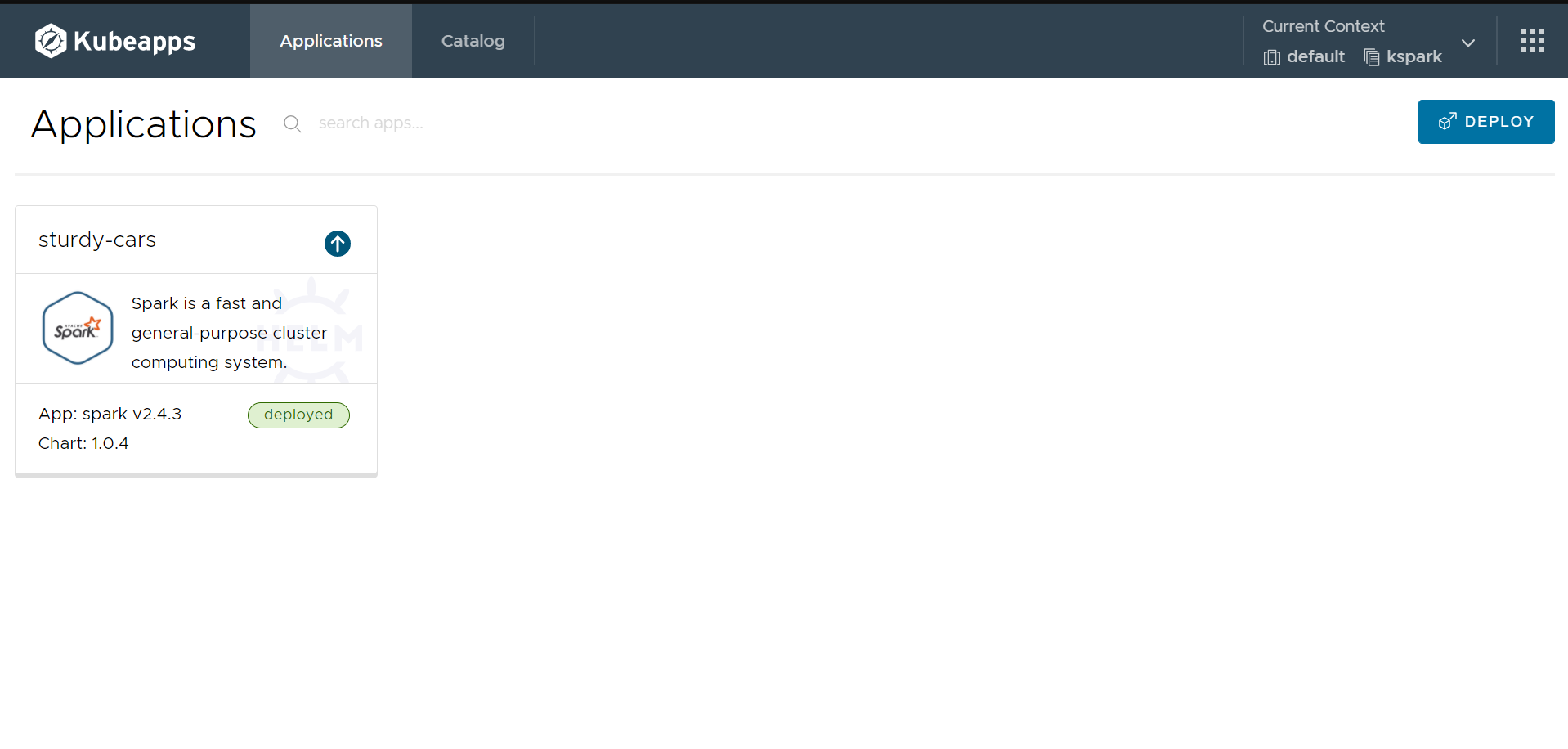
这段时间已经基本实现了产品应用层从原生的springboot微服务架构迁移到k8s上,过程可谓是瞎子过河一步一个坑,但是好在系统总体能跑起来了;今天研究了下产品计算层(spark集群)如何基于k8s部署操作,过程有些取巧了,但总的来说有些进展。 本次部署spark on k8s集群,基于kubeapps,简单便捷且一步到胃:
提示
Client启动一个 pod 运行Spark Driver Spark Driver中运行main函数,并创建SparkSession,后者使用KubernetesClusterManager作为SchedulerBackend,启动Kubernetes pod,创建Executor。 每个Kubernetes pod创建Executor,并执行应用程序代码 运行完程序代码,Spark Driver 清理 Executor 所在的 pod,并保持为“Complete”状态
# 1.安装kubeapps
看这里哟
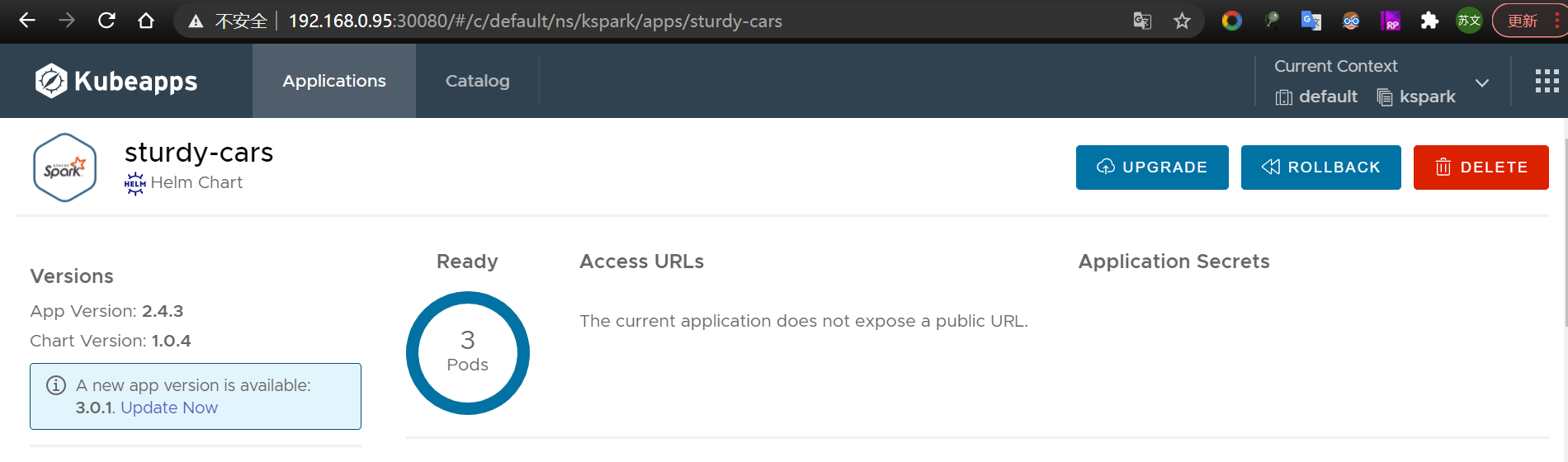
# 2.选择spark版本
# 3.yml配置
点击查看
## Global Docker image parameters ## Please, note that this will override the image parameters, including dependencies, configured to use the global value ## Current available global Docker image parameters: imageRegistry and imagePullSecrets ## # global: # imageRegistry: myRegistryName # imagePullSecrets: # - myRegistryKeySecretNameBitnami Spark image version
ref: https://hub.docker.com/r/bitnami/spark/tags/
image:
registry: docker.io
repository: bitnami/spark
tag: 2.4.3-debian-9-r78Specify a imagePullPolicy
Defaults to 'Always' if image tag is 'latest', else set to 'IfNotPresent'
ref: http://kubernetes.io/docs/user-guide/images/#pre-pulling-images
pullPolicy: IfNotPresent
Pull secret for this image
pullSecrets:
- myRegistryKeySecretName
String to partially override spark.fullname template (will maintain the release name)
nameOverride:
String to fully override spark.fullname template
fullnameOverride:
Spark Components configuration
master:
Spark master specific configuration
Set a custom configuration by using an existing configMap with the configuration file.
configurationConfigMap:
webPort: 8080
clusterPort: 7077Set the master daemon memory limit.
daemonMemoryLimit:
Use a string to set the config options for in the form "-Dx=y"
configOptions:
Set to true if you would like to see extra information on logs
It turns BASH and NAMI debugging in minideb
ref: https://github.com/bitnami/minideb-extras/#turn-on-bash-debugging
debug: false
An array to add extra env vars
For example:
extraEnvVars:
- name: SPARK_DAEMON_JAVA_OPTS
value: -Dx=y
extraEnvVars:
Kubernetes Security Context
https://kubernetes.io/docs/tasks/configure-pod-container/security-context/
securityContext:
enabled: true
fsGroup: 1001
runAsUser: 1001Node labels for pod assignment
Ref: https://kubernetes.io/docs/user-guide/node-selection/
nodeSelector: {}
Tolerations for pod assignment
Ref: https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/
tolerations: []
Affinity for pod assignment
Ref: https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#affinity-and-anti-affinity
affinity: {}
Configure resource requests and limits
ref: http://kubernetes.io/docs/user-guide/compute-resources/
resources:
limits:
cpu: 200m
memory: 1Gi
requests:
memory: 256Mi
cpu: 250m
Configure extra options for liveness and readiness probes
ref: https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/#configure-probes)
livenessProbe:
enabled: true
initialDelaySeconds: 180
periodSeconds: 20
timeoutSeconds: 5
failureThreshold: 6
successThreshold: 1readinessProbe:
enabled: true
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 6
successThreshold: 1worker:
Spark worker specific configuration
Set a custom configuration by using an existing configMap with the configuration file.
configurationConfigMap:
webPort: 8081
Set to true to use a custom cluster port instead of a random port.
clusterPort:
Set the daemonMemoryLimit as the daemon max memory
daemonMemoryLimit:
Set the worker memory limit
memoryLimit:
Set the maximun number of cores
coreLimit:
Working directory for the application
dir:
Options for the JVM as "-Dx=y"
javaOptions:
Configuraion options in the form "-Dx=y"
configOptions:
Number of spark workers (will be the min number when autoscaling is enabled)
replicaCount: 3
autoscaling:
## Enable replica autoscaling depending on CPU
enabled: false
CpuTargetPercentage: 50
## Max number of workers when using autoscaling
replicasMax: 5Set to true if you would like to see extra information on logs
It turns BASH and NAMI debugging in minideb
ref: https://github.com/bitnami/minideb-extras/#turn-on-bash-debugging
debug: false
An array to add extra env vars
For example:
extraEnvVars:
- name: SPARK_DAEMON_JAVA_OPTS
value: -Dx=y
extraEnvVars:
Kubernetes Security Context
https://kubernetes.io/docs/tasks/configure-pod-container/security-context/
securityContext:
enabled: true
fsGroup: 1001
runAsUser: 1001Node labels for pod assignment
Ref: https://kubernetes.io/docs/user-guide/node-selection/
nodeSelector: {}
Tolerations for pod assignment
Ref: https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/
tolerations: []
Affinity for pod assignment
Ref: https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#affinity-and-anti-affinity
affinity: {}
Configure resource requests and limits
ref: http://kubernetes.io/docs/user-guide/compute-resources/
resources:
limits:
cpu: 200m
memory: 1Gi
requests:
memory: 256Mi
cpu: 250m
Configure extra options for liveness and readiness probes
ref: https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/#configure-probes)
livenessProbe:
enabled: true
initialDelaySeconds: 180
periodSeconds: 20
timeoutSeconds: 5
failureThreshold: 6
successThreshold: 1readinessProbe:
enabled: true
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 6
successThreshold: 1Security configuration
security:
Name of the secret that contains all the passwords. This is optional, by default random passwords are generated.
passwordsSecretName:
RPC configuration
rpc:
authenticationEnabled: false
encryptionEnabled: falseEnables local storage encryption
storageEncryptionEnabled: false
SSL configuration
ssl:
enabled: false
needClientAuth: false
protocol: TLSv1.2Name of the secret that contains the certificates
It should contains two keys called "spark-keystore.jks" and "spark-truststore.jks" with the files in JKS format.
certificatesSecretName:
Service to access the master from the workers and to the WebUI
service:
type: NodePort
clusterPort: 7077
webPort: 80Specify the NodePort value for the LoadBalancer and NodePort service types.
ref: https://kubernetes.io/docs/concepts/services-networking/service/#type-nodeport
nodePort:
Use loadBalancerIP to request a specific static IP,
loadBalancerIP:
Service annotations done as key:value pairs
annotations:
Ingress controller to access the web UI.
ingress:
enabled: falseSet this to true in order to add the corresponding annotations for cert-manager
certManager: false
If certManager is set to true, annotation kubernetes.io/tls-acme: "true" will automatically be set
annotations:
The list of hostnames to be covered with this ingress record.
Most likely this will be just one host, but in the event more hosts are needed, this is an array
hosts:
- name: spark.local
path: /
# 4.执行后耐心等待即可
[root@master ~]# kubectl get pod -n kspark
NAME READY STATUS RESTARTS AGE
sulky-selection-spark-master-0 1/1 Running 0 22h
sulky-selection-spark-worker-0 1/1 Running 0 22h
sulky-selection-spark-worker-1 1/1 Running 0 22h
sulky-selection-spark-worker-2 1/1 Running 0 22h# 5.验证
1. Get the Spark master WebUI URL by running these commands:export NODE_PORT=$(kubectl get --namespace kspark -o jsonpath="{.spec.ports[?(@.name=='http')].nodePort}" services sulky-selection-spark-master-svc)
export NODE_IP=$(kubectl get nodes --namespace kspark -o jsonpath="{.items[0].status.addresses[0].address}")
echo http://NODE_IP:NODE_PORT
- Submit an application to the cluster:
To submit an application to the cluster the spark-submit script must be used. That script can be
obtained at https://github.com/apache/spark/tree/master/bin. Also you can use kubectl run.Run the commands below to obtain the master IP and submit your application.
export EXAMPLE_JAR=$(kubectl exec -ti --namespace kspark sulky-selection-spark-worker-0 -- find examples/jars/ -name 'spark-example*.jar' | tr -d '\r')
export SUBMIT_PORT=$(kubectl get --namespace kspark -o jsonpath="{.spec.ports[?(@.name=='cluster')].nodePort}" services sulky-selection-spark-master-svc)
export SUBMIT_IP=$(kubectl get nodes --namespace kspark -o jsonpath="{.items[0].status.addresses[0].address}")kubectl run --namespace kspark sulky-selection-spark-client --rm --tty -i --restart='Never'
--image docker.io/bitnami/spark:2.4.3-debian-9-r78
-- spark-submit --master spark://SUBMIT_IP:SUBMIT_PORT
--class org.apache.spark.examples.SparkPi
--deploy-mode cluster
$EXAMPLE_JAR 1000** IMPORTANT: When submit an application the --master parameter should be set to the service IP, if not, the application will not resolve the master. **
** Please be patient while the chart is being deployed **
- 访问NodePort
这里可以看到NodePort指向的是30423
[root@master ~]# kubectl get svc --namespace kspark
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sulky-selection-spark-headless ClusterIP None <none> <none> 22h
sulky-selection-spark-master-svc NodePort 10.107.246.253 <none> 7077:30028/TCP,80:30423/TCP 22h- 进入master启动spark shell
[root@master home]# kubectl exec -ti sulky-selection-spark-master-0 -n kspark /bin/sh
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl kubectl exec [POD] -- [COMMAND] instead.
$ ls
LICENSE NOTICE R README.md RELEASE bin conf data examples jars kubernetes licenses logs python sbin tmp work yarn
$ ls
LICENSE NOTICE R README.md RELEASE bin conf data examples jars kubernetes licenses logs python sbin tmp work yarn
$ cd bin
$ ls
beeline find-spark-home load-spark-env.sh pyspark2.cmd spark-class spark-shell spark-sql spark-submit sparkR
beeline.cmd find-spark-home.cmd pyspark run-example spark-class.cmd spark-shell.cmd spark-sql.cmd spark-submit.cmd sparkR.cmd
docker-image-tool.sh load-spark-env.cmd pyspark.cmd run-example.cmd spark-class2.cmd spark-shell2.cmd spark-sql2.cmd spark-submit2.cmd sparkR2.cmd
$ cd ../sbin
$ ls
slaves.sh start-all.sh start-mesos-shuffle-service.sh start-thriftserver.sh stop-mesos-dispatcher.sh stop-slaves.sh
spark-config.sh start-history-server.sh start-shuffle-service.sh stop-all.sh stop-mesos-shuffle-service.sh stop-thriftserver.sh
spark-daemon.sh start-master.sh start-slave.sh stop-history-server.sh stop-shuffle-service.sh
spark-daemons.sh start-mesos-dispatcher.sh start-slaves.sh stop-master.sh stop-slave.sh
$ pwd
/opt/bitnami/spark/sbin
$ ./spark-shell --master spark://sturdy-cars-spark-master-0.sturdy-cars-spark-headless.kspark.svc.cluster.local
20/12/29 08:11:21 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://sturdy-cars-spark-master-0.sturdy-cars-spark-headless.kspark.svc.cluster.local:4040
Spark context available as 'sc' (master = spark://sturdy-cars-spark-master-0.sturdy-cars-spark-headless.kspark.svc.cluster.local app id = app-20201229081130-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ / ___ / /
\ / _ / _ `/ __/ '/
// .__/_,// //_\ version 2.4.3
//Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_222)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
- 测试提交jar到spark
[root@master]# export EXAMPLE_JAR=$(kubectl exec -ti --namespace kspark sulky-selection-spark-worker-0 -- find examples/jars/ -name 'spark-example*.jar' | tr -d '\r')
[root@master]# export SUBMIT_PORT=$(kubectl get --namespace kspark -o jsonpath="{.spec.ports[?(@.name=='cluster')].nodePort}" services sulky-selection-spark-master-svc)
[root@master]# export SUBMIT_IP=$(kubectl get nodes --namespace kspark -o jsonpath="{.items[0].status.addresses[0].address}")
[root@master]# kubectl run --namespace kspark sulky-selection-spark-client --rm --tty -i --restart='Never'
> --image docker.io/bitnami/spark:2.4.3-debian-9-r78
> -- spark-submit --master spark://SUBMIT_IP:SUBMIT_PORT
> --class org.apache.spark.examples.SparkPi
> --deploy-mode cluster
> $EXAMPLE_JAR 1000
If you don't see a command prompt, try pressing enter.
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.NativeCodeLoader).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
21/01/28 01:34:21 INFO SecurityManager: Changing view acls to: spark
21/01/28 01:34:21 INFO SecurityManager: Changing modify acls to: spark
21/01/28 01:34:21 INFO SecurityManager: Changing view acls groups to:
21/01/28 01:34:21 INFO SecurityManager: Changing modify acls groups to:
21/01/28 01:34:21 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(spark); groups with view permissions: Set(); users with modify permissions: Set(spark); groups with modify permissions: Set()
21/01/28 01:34:22 INFO Utils: Successfully started service 'driverClient' on port 44922.
21/01/28 01:34:22 INFO TransportClientFactory: Successfully created connection to /192.168.0.177:30028 after 58 ms (0 ms spent in bootstraps)
21/01/28 01:34:22 INFO ClientEndpoint: Driver successfully submitted as driver-20210128013422-0000
21/01/28 01:34:22 INFO ClientEndpoint: ... waiting before polling master for driver state
21/01/28 01:34:27 INFO ClientEndpoint: ... polling master for driver state
21/01/28 01:34:27 INFO ClientEndpoint: State of driver-20210128013422-0000 is RUNNING
21/01/28 01:34:27 INFO ClientEndpoint: Driver running on 100.67.224.69:42072 (worker-20210127034500-100.67.224.69-42072)
21/01/28 01:34:27 INFO ShutdownHookManager: Shutdown hook called
21/01/28 01:34:27 INFO ShutdownHookManager: Deleting directory /tmp/spark-7667114a-6d54-48a9-83b7-174cabce632a
pod "sulky-selection-spark-client" deleted
[root@master]# Client启动一个名为sulky-selection-spark-client的 pod 运行Spark Driver Spark Driver中运行SparkPi的main函数,并创建SparkSession,后者使用KubernetesClusterManager作为SchedulerBackend,启动Kubernetes pod,创建Executor。 每个Kubernetes pod创建Executor,并执行应用程序代码 运行完程序代码,Spark Driver 清理 Executor 所在的 pod,并保持为“Complete”状态
- web-UI查看

[root@master ~]# kubectl get pod -n kspark
NAME READY STATUS RESTARTS AGE
sulky-selection-spark-master-0 1/1 Running 0 22h
sulky-selection-spark-worker-0 1/1 Running 0 22h
sulky-selection-spark-worker-1 1/1 Running 0 22h
sulky-selection-spark-worker-2 1/1 Running 0 22h
[root@master ~]# kubectl get pod -n kspark
NAME READY STATUS RESTARTS AGE
sulky-selection-spark-client 1/1 Running 0 8s
sulky-selection-spark-master-0 1/1 Running 0 22h
sulky-selection-spark-worker-0 1/1 Running 0 22h
sulky-selection-spark-worker-1 1/1 Running 0 22h
sulky-selection-spark-worker-2 1/1 Running 0 22h
[root@master ~]# kubectl get pod -n kspark
NAME READY STATUS RESTARTS AGE
sulky-selection-spark-master-0 1/1 Running 0 22h
sulky-selection-spark-worker-0 1/1 Running 0 22h
sulky-selection-spark-worker-1 1/1 Running 0 22h
sulky-selection-spark-worker-2 1/1 Running 0 22h