LibCurl是一个开源的免费的多协议数据传输开源库,该框架具备跨平台性,开源免费,并提供了包括HTTP、FTP、SMTP、POP3等协议的功能,使用libcurl可以方便地进行网络数据传输操作,如发送HTTP请求、下载文件、发送电子邮件等。它被广泛应用于各种网络应用开发中,特别是涉及到数据传输的场景。
- 下载地址:https://curl.haxx.se/download.html
首先读者需要自行下载该库,如下笔者选择下载curl-8.0.1.zip这个源代码版本,读者可找到如下页面,并点击对应版本完成下载,当下载好以后读者可自行将其解压缩到任意目录下。
当读者解压缩后,可打开VS2013 开发人员命令提示并切换带该目录中的curl-8.0.1\winbuild目录,通过执行如下两条命令即可分别实现编译静态库或动态库,我们以静态库编译为主,执行如下命令读者可自行等待一段时间。
- 动态库: nmake /f Makefile.vc mode=dll VC=13 MACHINE=x86 DEBUG=no
- 静态库: nmake / f Makefile.vc mode = static VC = 13 ENABLE_IDN = no MACHINE = x86 DEBUG = no
这个库在编译通过后会自动生成文件到builds\libcurl-vc13-x86-release-static-ipv6-sspi-schannel目录内,读者可自行打开该目录,即可看到该目录内的头文件以及库目录文件,如下图所示;

读者可自行配置这个静态库,通常只需要配置include和lib文件即可,该库的使用很简单,首先我们需要调用curl_easy_init()函数对CURL对象进行初始化,接着通过调用curl_easy_setopt()并传入一个访问URL链接,当访问成功后则可调用curl_easy_perform()函数得到访问结果,这就是该库基本使用方法,如下代码。
#define CURL_STATICLIB #define BUILDING_LIBCURL #include <iostream> #include "curl/curl.h"#pragma comment (lib,"libcurl_a.lib")
#pragma comment (lib,"wldap32.lib")
#pragma comment (lib,"ws2_32.lib")
#pragma comment (lib,"Crypt32.lib")using namespace std;
int main(int argc, char *argv[])
{
CURL *curl;
CURLcode res;
curl = curl_easy_init();
if (curl)
{
curl_easy_setopt(curl, CURLOPT_URL, "https://www.lyshark.com");
res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
}std::cout << "返回状态: " << res << std::endl; system("pause"); return 0;
}
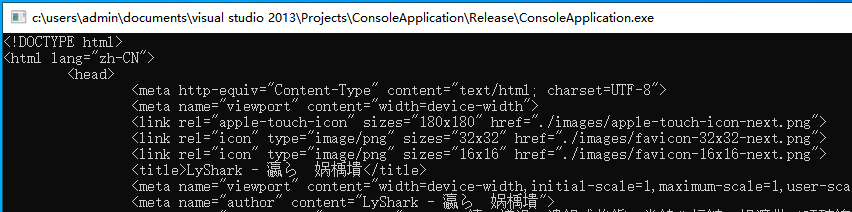
运行上述代码,读者可看到网站www.lyshark.com的源代码,如下图所示;
上述代码中的curl_easy_setopt()函数第二个参数可以使用多种类型的变量定义,我们可以通过传入不同的常量来定义请求头中的参数,例如当我们需要修改协议头时,可以使用CURLOPT_HTTPHEADER常量,并在其后第三个参数中传入该常量所对应的结构即可,这个结构体定义有许多类型,具体如下下表所示;
常量名称 | 描述 |
|---|---|
CURLINFO_EFFECTIVE_URL | 最后一个有效的URL地址 |
CURLINFO_HTTP_CODE | 最后一个收到的HTTP代码 |
CURLINFO_FILETIME | 远程获取文档的时间,如果无法获取,则返回值为-1 |
CURLINFO_TOTAL_TIME | 最后一次传输所消耗的时间 |
CURLINFO_NAMELOOKUP_TIME | 名称解析所消耗的时间 |
CURLINFO_CONNECT_TIME | 建立连接所消耗的时间 |
CURLINFO_PRETRANSFER_TIME | 从建立连接到准备传输所使用的时间 |
CURLINFO_STARTTRANSFER_TIME | 从建立连接到传输开始所使用的时间 |
CURLINFO_REDIRECT_TIME | 在事务传输开始前重定向所使用的时间 |
CURLINFO_SIZE_UPLOAD | 以字节为单位返回上传数据量的总值 |
CURLINFO_SIZE_DOWNLOAD | 以字节为单位返回下载数据量的总值 |
CURLINFO_SPEED_DOWNLOAD | 平均下载速度 |
CURLINFO_SPEED_UPLOAD | 平均上传速度 |
CURLINFO_HEADER_SIZE | header部分的大小 |
CURLINFO_HEADER_OUT | 发送请求的字符串 |
CURLINFO_REQUEST_SIZE | 在HTTP请求中有问题的请求的大小 |
CURLINFO_SSL_VERIFYRESULT | 通过设置CURLOPT_SSL_VERIFYPEER返回的SSL证书验证请求的结果 |
CURLINFO_CONTENT_LENGTH_DOWNLOAD | 从Content-Length: field中读取的下载内容长度 |
CURLINFO_CONTENT_LENGTH_UPLOAD | 上传内容大小的说明 |
CURLINFO_CONTENT_TYPE | 下载内容的Content-Type:值,NULL表示服务器没有发送有效的Content-Type:header |
如下案例是一个简单的GET请求封装,通过调用GetStatus()函数实现对特定页面发起请求的功能,其中curl_slist_append()用于增加新的请求头数据,在调用curl_easy_setopt()函数时,分别传入了CURLOPT_HTTPHEADER设置请求头,CURLOPT_WRITEFUNCTION设置回调,CURLINFO_PRIMARY_IP获取目标IP地址,CURLINFO_RESPONSE_CODE获取目标返回代码,此处的write_data()函数直接返回0则表示屏蔽所有的页面输出内容。
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include "curl/curl.h"#pragma comment (lib,"libcurl_a.lib")
#pragma comment (lib,"wldap32.lib")
#pragma comment (lib,"ws2_32.lib")
#pragma comment (lib,"Crypt32.lib")using namespace std;
// 设置CURLOPT_WRITEFUNCTION回调函数,返回为空屏蔽输出
static size_t write_data(char *d, size_t n, size_t l, void *p)
{
return 0;
}// 获取网站返回值
void GetStatus(char *UrlPage)
{
CURLcode return_code;// 初始化模块 return_code = curl_global_init(CURL_GLOBAL_WIN32); if (CURLE_OK != return_code) { return; } // 初始化填充请求头 struct curl_slist *headers = NULL; headers = curl_slist_append(headers, "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:76.0)"); headers = curl_slist_append(headers, "Referer: https://www.lyshark.com"); // 初始化请求库 CURL *easy_handle = curl_easy_init(); if (NULL != easy_handle) { // CURLOPT_HTTPHEADER 自定义设置请求头 curl_easy_setopt(easy_handle, CURLOPT_HTTPHEADER, headers); // CURLOPT_URL 自定义请求的网站 curl_easy_setopt(easy_handle, CURLOPT_URL, UrlPage); // CURLOPT_WRITEFUNCTION 设置回调函数,屏蔽输出 curl_easy_setopt(easy_handle, CURLOPT_WRITEFUNCTION, write_data); // 执行CURL访问网站 return_code = curl_easy_perform(easy_handle); char *ipAddress = { 0 }; // CURLINFO_PRIMARY_IP 获取目标IP信息 return_code = curl_easy_getinfo(easy_handle, CURLINFO_PRIMARY_IP, &ipAddress); if ((CURLE_OK == return_code) && ipAddress) { std::cout << "目标IP: " << ipAddress << std::endl; } long retcode = 0; // CURLINFO_RESPONSE_CODE 获取目标返回状态 return_code = curl_easy_getinfo(easy_handle, CURLINFO_RESPONSE_CODE, &retcode); if ((CURLE_OK == return_code) && retcode) { std::cout << "返回状态码: " << retcode << std::endl; } } curl_easy_cleanup(easy_handle); curl_global_cleanup();}
int main(int argc, char *argv[])
{
GetStatus("https://www.lyshark.com");
system("pause");
return 0;
}
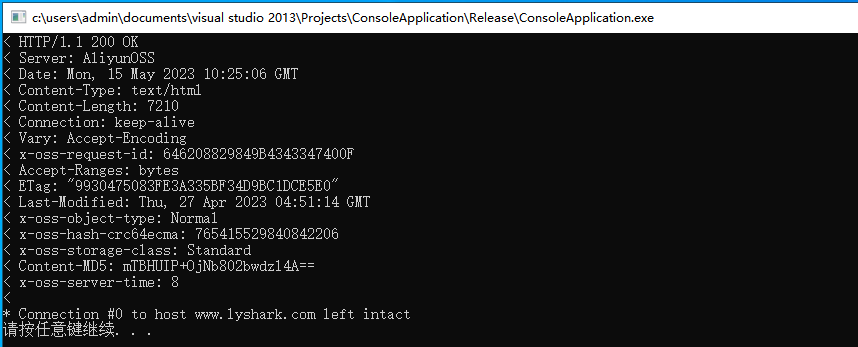
运行上述代码,则可以获取到www.lyshark.com目标主机的IP地址以及页面返回状态,如下图所示;

当然该库同样支持POST请求方式,在使用POST请求时我们可以通过CURLOPT_COOKIEFILE参数指定Cookie参数,通过CURLOPT_POSTFIELDS指定POST的数据集,而如果需要使用代理模式则可以通过CURLOPT_PROXY方式来指定代理地址,
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include "curl/curl.h"#pragma comment (lib,"libcurl_a.lib")
#pragma comment (lib,"wldap32.lib")
#pragma comment (lib,"ws2_32.lib")
#pragma comment (lib,"Crypt32.lib")using namespace std;
bool SendPost(char *Url, char *Cookie, char *PostVal)
{
CURL *curl;
CURLcode res;// 初始化库 curl = curl_easy_init(); if (curl) { // 设置请求头 struct curl_slist *headers = NULL; headers = curl_slist_append(headers, "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:76.0)"); headers = curl_slist_append(headers, "Referer: https://www.lyshark.com"); // 设置请求头 curl_easy_setopt(curl, CURLOPT_HTTPHEADER, headers); // 指定URL curl_easy_setopt(curl, CURLOPT_URL, Url); // 指定cookie参数 curl_easy_setopt(curl, CURLOPT_COOKIEFILE, Cookie); // 指定post内容 curl_easy_setopt(curl, CURLOPT_POSTFIELDS, PostVal); // 是否代理 // curl_easy_setopt(curl, CURLOPT_PROXY, "10.99.60.201:8080"); res = curl_easy_perform(curl); curl_easy_cleanup(curl); } return true;}
int main(int argc, char *argv[])
{
// 传入网址 cookie 以及post参数
SendPost("https://www.lyshark.com/post.php", "1e12sde342r2", "&logintype=uid&u=xieyan&psw=xxx86");system("pause"); return 0;
}
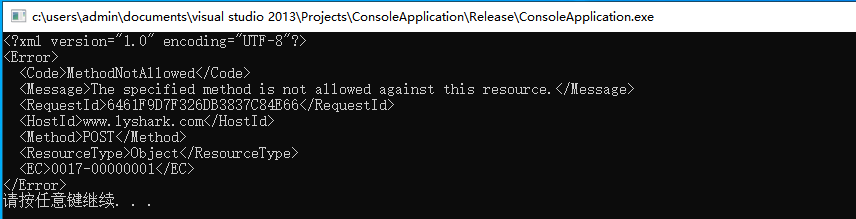
该函数的调用需要有一个POST结构才可测试,此处由于我并没有指定接口所有返回了页面错误信息,如下图所示;
接着继续实现下载页面到本地的功能,该功能实现的原理是利用write_data回调函数,当页面数据被读入到内存时回调函数会被触发,在该回调函数的内部通过调用fwrite函数将ptr指针中的数据保存本地,实现这段代码如下所示;
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include "curl/curl.h"#pragma comment (lib,"libcurl_a.lib")
#pragma comment (lib,"wldap32.lib")
#pragma comment (lib,"ws2_32.lib")
#pragma comment (lib,"Crypt32.lib")using namespace std;
FILE *fp;
size_t write_data(void *ptr, size_t size, size_t nmemb, void *stream)
{
int written = fwrite(ptr, size, nmemb, (FILE *)fp);
return written;
}BOOL GetUrl(char *URL, char *FileName)
{
CURL *curl;curl_global_init(CURL_GLOBAL_ALL); curl = curl_easy_init(); curl_easy_setopt(curl, CURLOPT_URL, URL); // 在屏幕打印请求连接过程和返回http数据 curl_easy_setopt(curl, CURLOPT_VERBOSE, 1L); // 查找次数,防止查找太深 curl_easy_setopt(curl, CURLOPT_MAXREDIRS, 1); // 设置连接超时 curl_easy_setopt(curl, CURLOPT_CONNECTTIMEOUT, 3); // 接收数据时超时设置 curl_easy_setopt(curl, CURLOPT_TIMEOUT, 3); if ((fp = fopen(FileName, "w")) == NULL) { curl_easy_cleanup(curl); return FALSE; } // CURLOPT_WRITEFUNCTION 将后继的动作交给write_data函数处理 curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, write_data); curl_easy_perform(curl); curl_easy_cleanup(curl); return TRUE;}
int main(int argc, char *argv[])
{
// 下载网页到本地
GetUrl("https://www.lyshark.com", "./lyshark.html");system("pause"); return 0;
}
当读者运行上述程序后,即可将www.lyshark.com网站页面源码,下载到本地当前目录下lyshark.html,输出效果如下图所示;
为了能解析参数,我们还是需要将页面源代码读入到内存中,要实现这个需求并不难,首先我们定义一个std::string容器,然后当有新数据产生时触发WriteCallback在该函数内,我们直接将数据拷贝到一个内存指针中,也就是存储到read_buffer内,并将该缓冲区返回给调用者即可,如下则是完整源代码。
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include <string>
#include "curl/curl.h"#pragma comment (lib,"libcurl_a.lib")
#pragma comment (lib,"wldap32.lib")
#pragma comment (lib,"ws2_32.lib")
#pragma comment (lib,"Crypt32.lib")using namespace std;
// 存储回调函数
size_t WriteCallback(char contents, size_t size, size_t nmemb, void userp)
{
((std::string)userp)->append((char)contents, size * nmemb);
return size * nmemb;
}// 获取数据并放入string中.
std::string GetUrlPageOfString(std::string url)
{
std::string read_buffer;
CURL *curl;curl_global_init(CURL_GLOBAL_ALL); curl = curl_easy_init(); if (curl) { // 忽略证书检查 curl_easy_setopt(curl, CURLOPT_SSL_VERIFYPEER, 0L); // 重定向 curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1); // URL路径 curl_easy_setopt(curl, CURLOPT_URL, url); // 查找次数,防止查找太深 curl_easy_setopt(curl, CURLOPT_MAXREDIRS, 1); // 连接超时 curl_easy_setopt(curl, CURLOPT_CONNECTTIMEOUT, 3); // 接收数据时超时设置 curl_easy_setopt(curl, CURLOPT_TIMEOUT, 3); // 写入回调函数 curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback); curl_easy_setopt(curl, CURLOPT_WRITEDATA, &read_buffer); curl_easy_perform(curl); curl_easy_cleanup(curl); return read_buffer; } return "None";}
int main(int argc, char *argv[])
{
std::string urls = GetUrlPageOfString("https://www.lyshark.com");
std::cout << "接收长度: " << urls.length() << " bytes" << std::endl;system("pause"); return 0;
}
如下图所示,则是运行后输出内存数据长度,当然我们也可以直接输出urls中的数据,也就是网页的源代码;

本文作者: 王瑞
本文链接: https://www.lyshark.com/post/6aa9753b.html
版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!