机器之心原创
作者:张倩
攀登 Scaling Law,打造万亿参数大模型,前微软 NLP 大牛姜大昕披露创业路线图。
前段时间,OpenAI 科学家 Jason Wei 的一份作息时间表引发了广泛关注。表中有很多让人看了会心一笑的梗,比如「9 点 45:背诵 OpenAI 章程,向最优化的神祷告,学习《苦涩的教训》」「10 点用 Google Meet 开会,讨论怎么在更多数据上训练更大的模型」「11 点写代码,用来在更多数据上训练更大的模型」「1 点:实操,在更多数据上训练更大的模型」「4 点:对用更多数据训练的更大的模型进行提示工程」……

在短短的十几行字中,「在更多数据上训练更大的模型」出现了四次,而且《苦涩的教训》也毫不意外地早早出场。对于一家信仰 Scaling Law 并因此而取得巨大成功的公司来说,这些表述可能不仅仅是在玩梗。
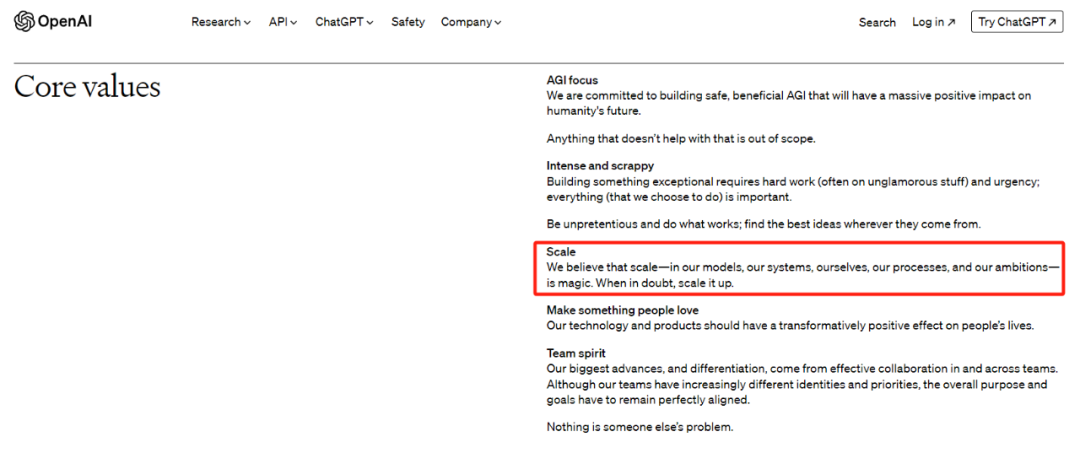
在公司官网公布的核心价值观里,OpenAI 写到,「我们相信 scale(规模)—— 在我们的模型、我们的系统、我们自己、我们的流程和我们的抱负中 —— 是有魔力的。如果对此产生了怀疑,那就扩大 scale。」
多年来,依靠对于自身技术路线的充分自信和坚持,OpenAI 一路推高 GPT 系列模型的参数。外界推测,GPT-4 的规模可能是 GPT-3 的 10 倍以上,有约 1.8 万亿个参数,而效果的提升也是显而易见的。因此,在追逐 AGI 的道路上,越来越多的公司也开始相信 Scaling Law,从千亿参数模型向万亿参数模型进发。
然而,万亿参数模型对于算力、数据的海量需求也注定了,这不会是一场「百模大战」,而是少数一些玩家才能参与的角逐。就像前微软全球副总裁、如今的阶跃星辰创始人姜大昕所说,「GPT-3.5 会是一个分水岭,在超过 GPT-3.5 之后,可能只有极少数的公司会继续攀登 Scaling Law。在算力、系统、数据和算法等各个方面,万亿参数模型的难度都上升了几十倍。如果这里面有任何一个短板,Scaling Law 都很难攀登上去。」
作为一位大模型领域的创业者,这番话其实也道出了姜大昕创业以来的一些体会。目前,他带领的阶跃星辰已经做出了超过 GPT-3.5 的千亿参数模型 Step-1 和比肩 GPT-4V 的多模态大模型 Step-1V,甚至正在打造的万亿参数 MoE 语言大模型 Step-2 也有了预览版。
在姜大昕看来,他们的路径是非常清晰的,就是沿着「单模→多模→具身智能→世界模型」的路线一步步往下走。打造万亿参数(甚至更大的)模型是其中必要的一环,在此基础上,他们还将推进多模态理解与生成的融合与统一。上述模型都是他们在前进道路上取得的阶段性成果,其终极目标指向 AGI,Scaling Law 贯穿始终。

姜大昕展示 AGI 技术路线图。姜大昕是自然语言处理领域的全球知名专家,曾任微软全球副总裁并领导必应搜索引擎的研发工作。
当然,树立这样的目标是需要底气的。对于姜大昕来说,这种底气既来自他对 AGI 技术路线的洞察,也来自他背后强大的技术团队。在最近的一次媒体沟通会中,姜大昕首次与外界分享了他对于大模型技术路线的思考,以及他们能打造出万亿参数大模型和优秀的多模态大模型的背后原因。
一条清晰的道路
在姜大昕看来,在通往 AGI 的路上,大模型的演进会经历三个阶段。
在第一个阶段,也就是早期阶段,语言、视觉、声音等各个模态是独立发展的,每个模态的模型专注于学习和表征其特定模态的特点。
在第二个阶段,即我们当前所处的阶段,不同的模态、任务会走向融合。也就是说,它不仅要求语言、视觉、声音等各个模态实现融合,还要将多模态的理解和生成能力统一起来,这是通往 AGI 的必经之路。
在第三个阶段,已经实现多模统一的大模型将和机器人充分结合,去主动探索物理世界,然后逐步演变成世界模型,进而实现 AGI。
「从一开始我们的布局就是沿着这么一条路往前走的。」姜大昕说。
基于这一路线,他们在过去的一年里打造了 Step 系列大模型。其中,Step-1 在逻辑推理、中文知识、英文知识、数学、代码方面的性能全面超过 GPT-3.5;Step-1V 在中国权威的大型模型评估平台「司南」(OpenCompass)多模态模型评测榜单中位列第一,性能比肩 GPT-4V。

其实,在姜大昕看来,OpenAI 也是沿着这条路在走的。
最近一段时间,OpenAI 的动作有些让人眼花缭乱,先是推出了一个名叫 DALL・E 3 的模型,春节的时候又扔了个炸弹 ——Sora。前几天,他们又投资了一个名叫 Figure 的机器人项目。此外,他们内部还不断有消息传出,比如神秘的 Q * 计划、7 万亿的芯片计划、今年可能发布 GPT-5 或 GPT-4.5…… 这些消息难辨真伪,引发了一连串的疑问:OpenAI 是不是在下一盘大棋?他们这些杂乱无章的动作背后有没有一个统一的逻辑?我们应该怎么解读这些动作背后的真实意图?
在姜大昕看来,OpenAI 的这些动作其实一点也不乱,反而非常符合预期,因为这家公司其实也一直在沿着上述路线推进他们的 AGI 计划:GPT-4 是他们在第一阶段的代表(单模态),GPT-4V 和 Sora 则是第二阶段的代表(多模态)。
根据这一路线推断,Sora 的出现有其必然性。从技术报告中披露的内容可知,Sora 的训练数据(图像、视频)用到了 OpenAI 的内部工具(很可能是 GPT-4V)进行标注,这点非常重要,提高了模型遵循 prompt 的能力和视频的质量。此外,OpenAI 还会用 GPT 来扩充用户的描述。
「我们看到 OpenAI 是一环扣一环的,它能做出 Sora 是因为它有 GPT-4V,它有 GPT-4V 是因为它有 GPT-4。当我们看清了这样一个发展历程之后,很多问题就很容易理解了,比如为什么 Sora 会出现在这样一个时间段,为什么它可以把视频做到 1 分钟。沿着这条路线,OpenAI 已经形成了自己的科研和工程体系,甚至能够做到左脚踩右脚。」姜大昕解释说。
但作为一个中间状态,Sora 显然还不完美。比如在一个老师写板书的例子中,Sora 可以掌握「老师用手拿粉笔写字、手的运动趋势、粉笔和黑板的接触留下印记」等生成,但却不擅长「板书的内容、老师接下来会写什么」等需要推理能力的生成,这需要语言模型的预测。

图片来源于网络
姜大昕认为,之所以出现这种情况,是因为在现阶段,多模态理解和生成的任务是分开来进行的(分成了两条支线),造成的后果是理解模型的理解能力强,但是生成能力弱;生成模型的生成能力强,但理解能力弱。要解决这个问题,就要实现多模态理解和生成的统一。这是「通向 AGI 的必经之路」,也是阶跃星辰现在主攻的方向。
目前,阶跃星辰已经在多模态的理解方面取得了显著进展。他们的 Step-1V 多模理解能力突出,可以精准描述和理解图像中的文字、数据、图表等信息,并根据图像信息实现内容创作、逻辑推理、数据分析等多项任务。这为后续的多模态生成以及多模态理解与生成的统一打下了一个良好的基础。
「我们内部说,学习 OpenAI 的时候,要学其『神』,而不能只学其『形』。不能看它今天出个模型,明天出个模型,感到非常焦虑。我们要看清它背后整个的规划,以及围绕着一条主线、两条支线所建立起的整个技术体系,这是非常重要的。」姜大昕说到。
攀登 Scaling Law 道路上的「铁人四项」
就像姜大昕所说,OpenAI 的成功是一环套一环的。这就意味着,你每一步都要走得足够扎实,后面的路才能走好。所以,在 Step-1 千亿参数语言大模型训练成功后,阶跃星辰随即开展了 Step-2 万亿参数语言大模型的训练工作。
姜大昕用「铁人四项」来形容这项工作的难度。所谓的「铁人四项」,指的是训练万亿参数模型对于算法、算力、系统、数据的要求都很高。
首先,在算法层面,MoE 架构的万亿参数模型究竟怎么训练,目前在业界鲜有公开资料可以参考,完全靠算法团队和系统团队紧密结合,一起去摸索。
在算力层面,训练这个体量的模型需要上万张 GPU 卡。而且,这些卡要放在一个单一的集群里,搭建起一个高效、稳定的系统,这是非常有挑战性的。
首先是效率方面的挑战。在训练过程中,计算、内存和网络通信是三个关键要素。为了避免宝贵的计算资源(如 GPU)在数据存储和网络通信时处于空闲状态,系统必须设计成一个流水线,使得这些操作能够尽可能重叠进行,从而最大化 GPU 的使用效率。这种效率可以通过 Model FLOPs Utilization(MFU)这一指标来衡量,即有效算力输出。不同的模型架构、网络拓扑结构和优化策略都会影响这一指标,考验着系统设计的功力。
其次是训练稳定性方面的挑战。在拥有上万张 GPU 卡的大型集群中,不可避免地,有些卡会出故障,就像人群中会有人生病一样。系统必须能够自动检测到故障卡,将其任务隔离并迁移到正常卡上,然后自动同步数据,确保训练过程不受影响。这种稳定性是系统设计的基础,但由于涉及的卡数量巨大,系统变得极其复杂。
前段时间,从谷歌出走创业的科学家 Yi Tay 曾发文感慨,创业做大模型比自己之前想象的要难。他意识到在大公司时,由于有专门的系统团队支持,他感觉不到搭建和维护大型 AI 训练系统的复杂性和困难。但当自己独立面对这些挑战时,他遭遇了许多问题,这些经历让他深刻理解了系统搭建的难度(参见《「还是谷歌好」,离职创业一年,我才发现训练大模型有这么多坑》)。
姜大昕也仔细地读了这篇文章,但他的感觉却是「为什么他掉的坑我一个都没碰到过?」后来他转念一想,这都是因为他背后有一个强大的系统团队,而这个团队的负责人朱亦博拥有多次搭建和管理万卡集群的经验。在 Step-2 的训练过程中,朱亦博带领阶跃团队突破了 5D 并行、极致显存管理、完全自动化运维等关键技术,使得集群的训练效率和稳定性处于业界领先水平。「如果没有亦博和他的团队,我们可能掉过很多次坑了。」姜大昕感慨地说。
训练万亿参数模型,另一个令人头疼的问题是数据。在互联网上,中文高质量数据是极度匮乏的,比如常用的 Common Crawl 数据集中仅有 0.5% 的中文可用数据,信噪比极低。
阶跃星辰的做法是拿全球的语料来弥补中文语料的不足,因为大模型对语种是不敏感的,就像姜大昕所说,「一个知识点,不管你拿英文教它,还是中文教它,它都能学会。」
不过,全球互联网上有数亿个网站,质量好、能够用来训练大模型的网站只有不到 100 万个,怎么找到这些网站呢?姜大昕说,「这个信息只有做过搜索引擎的人才知道。」因为在做搜索引擎的时候,他们会建一个很大的图谱,可以通过网站之间的连接关系来判断网站的权威度和网站的质量。
在创业之前,姜大昕以及另一位创始成员焦斌星都长期致力于搜索引擎方面的工作(焦斌星曾担任微软必应引擎核心搜索团队负责人)。他们在微软研发的必应搜索引擎已经成为全球第二大搜索引擎,支持 100 多种语言,服务于全球 200 多个国家和地区。所以,他们知道全球互联网上高质量语料的分布是怎样的。此外,在数据处理 pipeline 上,焦斌星带领的数据团队也有丰富的经验可以参考。
除了这些公开数据,在非公开的行业数据层面,阶跃星辰与国内优秀的数据资源实现了深度合作。
所以,总体来看,虽然训练万亿参数模型困难重重,阶跃星辰依然凭借自己独特的优势取得了巨大进展,这体现了阶跃的核心技术能力,也说明了公司探索通用人工智能的决心。
以阶跃之力,赴星辰大海
阶跃星辰成立于 2023 年 4 月,在过去的一年一直非常低调。在媒体沟通会上,姜大昕解释了公司名字的来历:「阶跃」取自阶跃函数(step function)。他们认为,通用人工智能技术会让每个人、每个领域迎来从 0 到 1 跃变的时刻,因此也需要用更坚定的信念去一步一步(step by step)地实现它。
在谈到为什么会有创业这个想法时,姜大昕回忆说,在接触了 ChatGPT 后,他意识到这将是一个跨时代的变革。但是,在微软,这个模型对他们来说是一个黑盒子 —— 他们只能通过 API 与之交互,无法获取模型的内部结构和参数,连 decode 之前的东西都看不到。这种限制意味着,即使发现了模型的问题,他们也没有办法改进。
而且,他们的工作不仅涉及模型的构建,还包括将模型应用于实际场景。所以,他们更希望从模型的基础出发,进行更深入的创新,而不仅仅是编写提示来使用现有的模型。对于他们这些专注于算法研究的人来说,通向 AGI 的旅程中,解决 system 2(逻辑分析系统)相关的问题才是真正令人充满激情和动力的挑战。
如今,姜大昕已经带领他的团队构建起了自己的大模型,自然可以更加自如将其部署到应用层。目前,他们已经上线了两款面向 C 端用户的大模型产品 —— 跃问和冒泡鸭 。其中,跃问是 AI 聊天类应用,定位为个人效率助手;冒泡鸭是由剧情和角色组成的 AI 开放世界平台,满足娱乐和社交需求。二者均已全面开放使用。

跃问界面。试用地址:https://stepchat.cn/chats/new
冒泡鸭 APP 界面。可在手机应用商店下载。
冒泡鸭对话结果。图片来自朋友圈分享。
此外,阶跃星辰在金融、网络文学、知识服务等领域已与合作伙伴达成深度合作,共同探索面向 C 端用户的创新应用。
在经历了过去一年的「百模大战」后,大模型创业正在进入一个新的阶段,资源、人才的争夺也变得更加激烈。在阶跃星辰身上,我们看到了他们攀登 Scaling Law 的决心和强大的人才、资源配置。这样的开局让我们对这家公司的未来充满期待。