创建网站
打开宝塔Linux面板,在wordpress网站根目录创建一个api文件夹用来存放自己编写的接口,在api文件夹中新建一个randomimg-api文件夹用来存放随机图片的代码文件。或者也可以直接创建一个新的站点。

具体实现
index.php
代码语言:javascript
复制
<?php
//获取图片地址文件的绝对路径
$path = dirname(__FILE__);
$file = file($path."/imgurl.txt");
//随机读取一行
$arr = mt_rand( 0, count( $file ) - 1 );
$imgpath = trim($file[$arr]);
//编码判断,用于输出相应的响应头部编码
if (isset($_GET['charset']) && !empty($_GET['charset'])) {
$charset = $_GET['charset'];
if (strcasecmp($charset,"gbk") == 0 ) {
$imgpath = mb_convert_encoding($imgpath,'gbk', 'utf-8');
}
} else {
$charset = 'utf-8';
}
header("Content-Type: text/html; charset=$charset");
die(header("Location: $imgpath"));
?>爬取图片
图片来源:元气壁纸
源码:
main.py
代码语言:javascript
复制
import requests import random import bs4 from ua_info import ua_list import osclass YuanQi(object):
# 初始化 def __init__(self): self.url = None self.kind = None self.page_end = 0 self.page_begin = 0 self.page_now = 0 # 选择下载漫画类型 def select(self): print("请选择需要获取的壁纸类型:\n") print("1.动漫\n2.风景\n3.美女\n") slt = int(input()) if slt == 1: self.url = 'https://bizhi.cheetahfun.com/dn/c2j/' self.kind = '动漫' elif slt == 2: self.url = 'https://bizhi.cheetahfun.com/dn/c1j/' self.kind = '风景' else: self.url = 'https://bizhi.cheetahfun.com/dn/c3j/' self.kind = '美女' print('选择成功!!!\n请输入下载的起始页:\n') self.page_begin = int(input()) self.page_end = int(input()) self.page_now = self.page_begin # 请求函数 def get_html(self, url): headers = {'User-Agent': random.choice(ua_list)} req = requests.get(url=url, headers=headers) # req = requests.get(url=url) html_file = open('index.html', 'wb') for chunk in req.iter_content(10000): html_file.write(chunk) html_file.close() # 下载图片 def download_img(self): html_file = open('index.html', encoding='utf-8') soup = bs4.BeautifulSoup(html_file.read(), 'html.parser') elems = soup.select('img[class="w-full h-full object-fill"]') # 获取图片的资源地址 for i in range(0, 18): # headers = {'User-Agent': random.choice(ua_list)} img_url = elems[i].get('src') print(img_url) # 翻页 def next_page(self): self.page_now += 1 next_url = self.url + 'p' + str(self.page_now) return next_url # 主函数 def run(self): self.select() link = self.url + 'p' + str(self.page_begin) for i in range(self.page_begin, self.page_end + 1): self.get_html(link) self.download_img() link = self.next_page() print('下载完成!!!')
if name == 'main':
# 捕捉异常错误
try:
spider = YuanQi()
spider.run()
except Exception as e:
print("错误:", e)
ua_info.py
代码语言:javascript
复制
ua_list = [
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'User-Agent:Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
]运行之后,爬完图片资源地址,将url放入imgurl.txt即可。
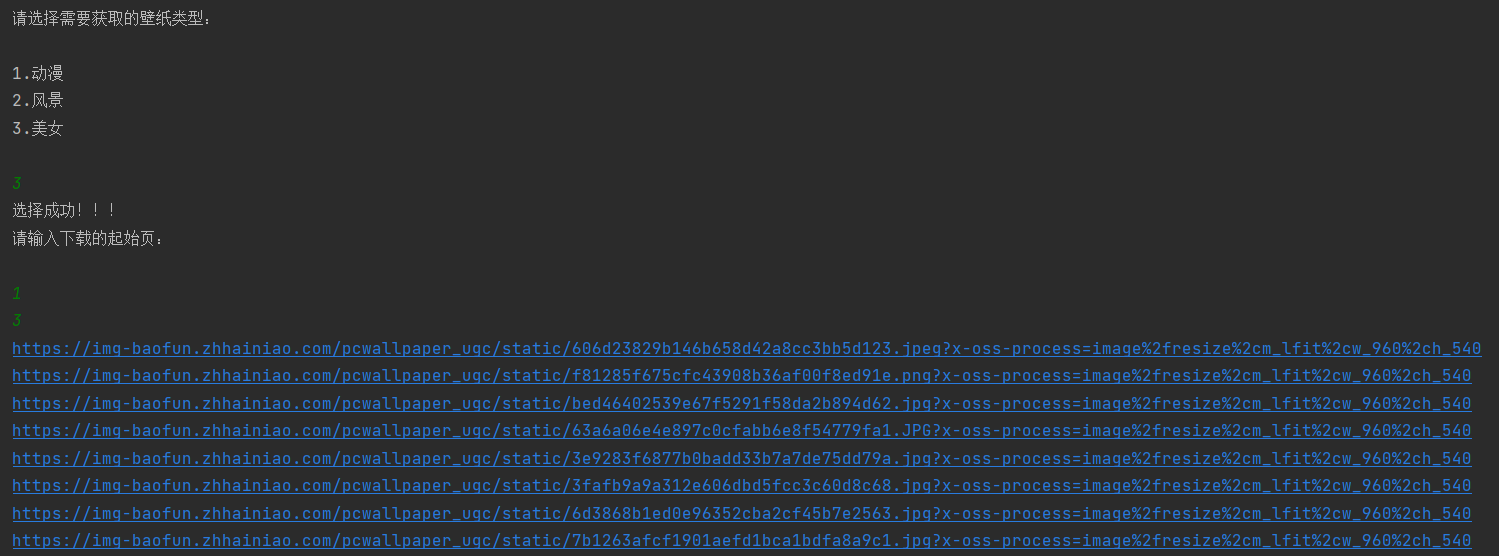
我总共爬了两千多张壁纸,应该是完全够了。

访问接口,我的是随机图片api
大概是这样的效果。
补充
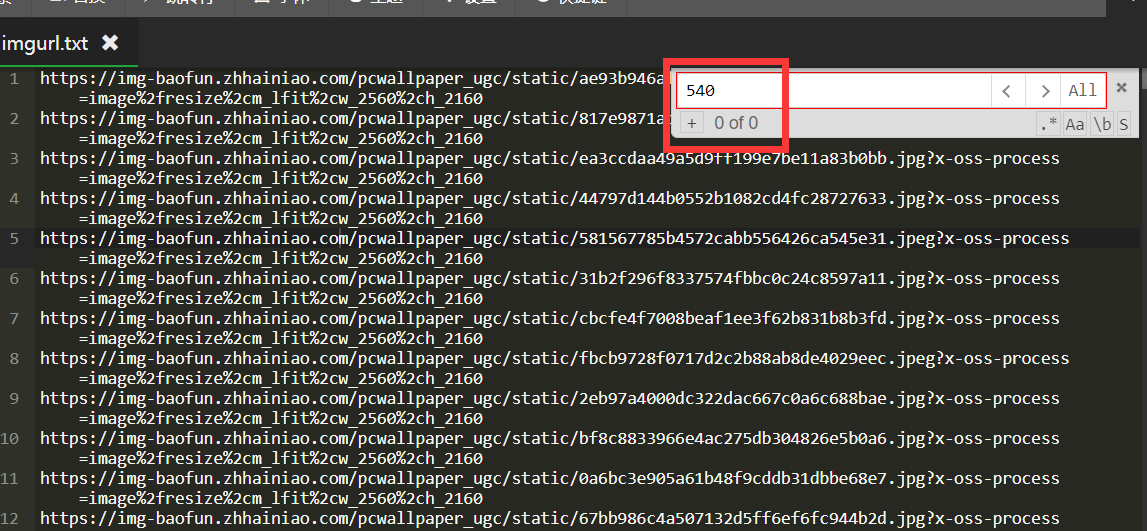
下载下来的图片貌似有点小有点糊,因为下下来的的是这个站点的预览缩略图,所以我们需要在imgurl.txt里面改下尺寸。
将540全部修改为2160,960全部修改为2560即可。
代码语言:javascript
复制
现在的效果应该好多了
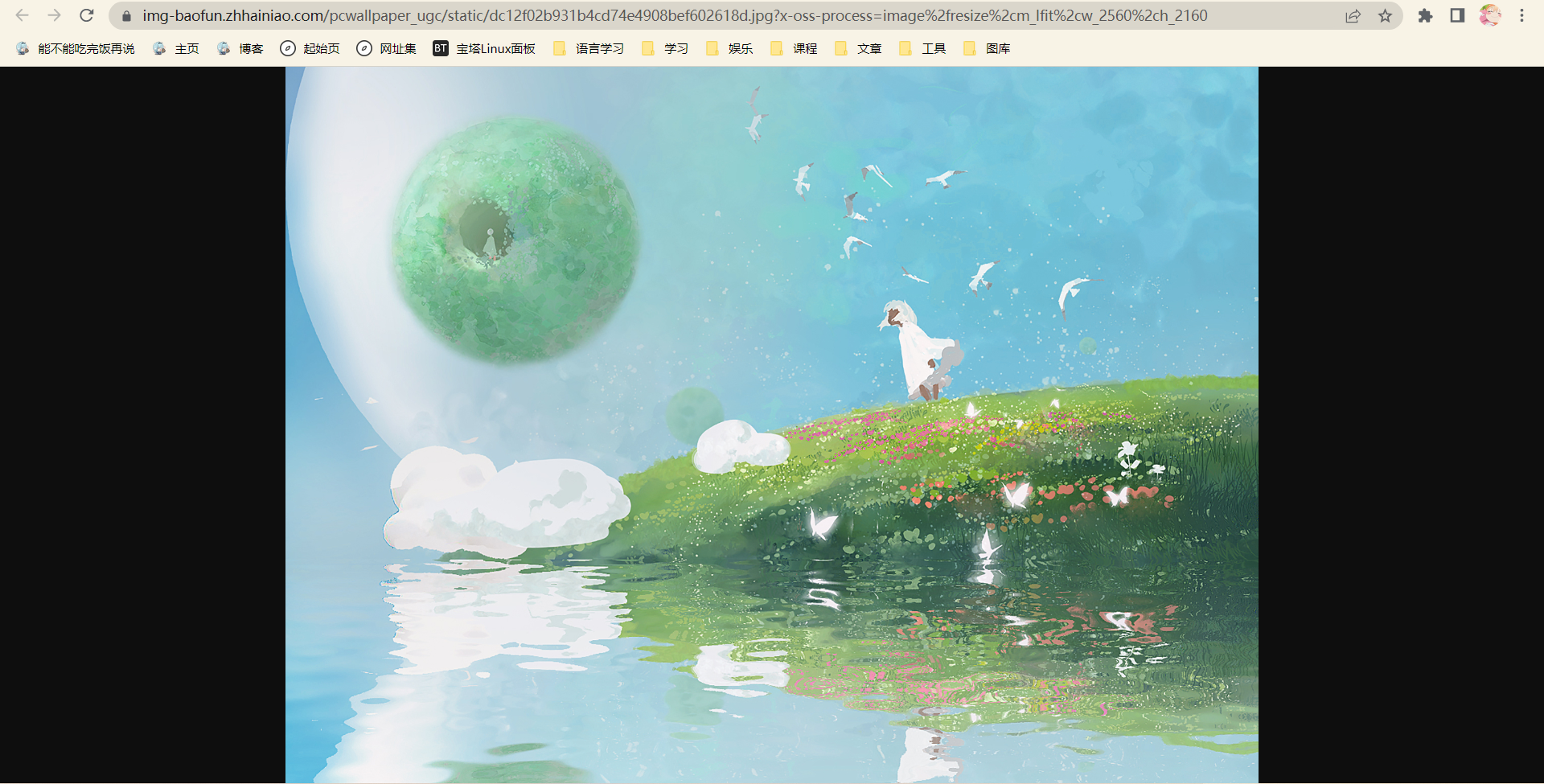
效果展示,这是api调用的图片

自建随机图片接口