1.介绍
Google Analytics 无处不在,对于大多数营销功能的统计报告至关重要。作为加入 ClickHouse 之前没有营销分析经验并发现自己定期以博客形式贡献内容的人,我长期以来一直认为 Google Analytics (GA4) 提供了一种快速、无缝的方式来衡量网站。因此,当我们负责报告我们内容策略的成功情况并确保我们制作的内容与您(我们的用户)相关时,GA4 似乎是一个明显的起点。
带着天真的热情,我提出了一系列我认为在 GA4 中回答起来微不足道的问题,例如“从发布之日起,每个博客的浏览量分布情况如何?” 我们的营销运营主管阿德里安(Adrian)的反应“礼貌地”表示这需要一些时间来制定。意识到我们需要每月报告一次,并且看到他忙于其他更重要的任务,我提供了自己的时间来协助。
报告博客性能很快就成为我这个月最害怕的一天。虽然 Google Analytics 有其优势,尤其是易于集成和使用,但很明显它在许多关键方面受到限制:数据保留、采样、性能和灵活性。我们没有在 GA4 中辛苦劳作,也没有担心每个月的第二个星期一,而是开展了一个项目,将所有 Google Analytics 数据转移到 ClickHouse,目的是提供灵活、快速的分析并无限保留。
在这篇博文中,我们解释了我们的架构,希望其他用户可以仅使用 ClickHouse 和几行 SQL 来构建自己的超级 Google Analytics。最重要的是,使用 ClickHouse Cloud 每月只需不到 20 美元即可实现这一切!
2.GA4 面临的挑战
灵活性。Google Analytics 的优势在于其易于与网站集成以及简单的查询界面。这种简单性是有代价的,主要是灵活性。该界面虽然易于使用,但具有限制性,限制了用户回答更复杂问题的能力,例如“博客发布之日的浏览量分布情况如何?” 我们的许多问题还需要外部数据集,例如阅读时间和博客主题。虽然我们通常能够通过导出数据并使用clickhouse local查询文件或使用 GA4 的导入数据功能来克服这些挑战,但该过程缓慢且耗时。作为一个自认为半技术性的人,我渴望 SQL 的灵活性。
性能。Clickhouse.com 的流量很高 - 每天有数十万。虽然这看起来可能很高,但实际上,对于我们在 ClickHouse 中习惯的大小来说,这个数据量非常小。尽管如此,GA4 界面总是很缓慢,查询需要很长时间才能加载。这使得迭代查询成为一种极其令人沮丧的体验。而且,作为一家习惯于以闪电般的快速响应时间对数据进行实时分析的公司,这种性能往好里说是令人沮丧,往坏了说,导致我们回避提出有关数据的新问题。
抽样和临时查询。鉴于数据量相对较低,令人惊讶的是 Google Analytics 中的查询经常报告数据正在被采样。对于我们来说,当发出使用大量维度或跨越很宽时间段的临时查询(报告似乎更可靠)时,这一点就性能出来了。GA4 提供了解决此问题的方法,包括升级到 Google Analytics 360(每年 150,000 美元!)或只是等待很长时间才能得到结果。这些对我们来说都是不可接受的,而且作为习惯于快速、精确响应的 ClickHouse 用户,获得不可靠结果的挫败感尤其令人沮丧。

数据保留。默认情况下,GA4 会将数据保留两个月。这可以增加到 14 个月,更长的期限可到 360 个月(同样,每年 150,000 美元)。虽然我们目前没有多年的数据,但我们希望能够使用 2 个月以上的数据点来识别随时间变化的Schema,例如季节性趋势。
3.为什么选择 ClickHouse 获取 Google Analytics 数据
虽然 ClickHouse 对我们来说是显而易见的选择,但作为一项测试活动,它实际上也是用于网络分析的数据库 - “Click”一词来自 Click Analytics,这是数据库开发的原始类似 Google Analytics 的用例。
作为一个支持SQL的实时数据仓库,ClickHouse提供了我们所需要的查询灵活性。几乎我们所有的查询都可以轻松地表示为 SQL。ClickHouse 词典还提供了完美的解决方案来集成我们的外部数据源,例如博客主题和阅读时间。
这些查询中的大多数都包含聚合,ClickHouse 作为面向列的数据库进行了优化,能够在不采样的情况下对数千亿行提供亚秒级响应时间 - 远远超出了我们在 GA4 中看到的规模。
ClickHouse 支持广泛的集成,使报告的生成更加简单。除了支持 MySQL 接口,允许使用Looker、Tableau和QuickSight等工具外,对 Superset 和 Grafana 等工具的本机支持还提供了开源 BI 体验。最后,我们相信 ClickHouse 可以很好地压缩原始数据,并且有可能以较低的成本无限期地保存 - 特别是因为 ClickCloud Cloud 使用对象存储。
4.内部数据仓库
此时,很明显我们可以解决的不仅仅是博客报告问题。我们的营销团队在报告更广泛的网站指标时也面临着上述相同的挑战。
作为一家以数据驱动决策而自豪的公司,我们已经拥有专门的团队负责我们的内部数据仓库。如果我们能够找到一种简单的方法来提供数据并提供大部分所需的查询,我们就可以利用他们现有的技术来加载、管理和可视化数据。
虽然 ClickHouse 将是网络分析数据的理想数据存储,但我们仍然希望保留 GA4 和 Google 跟踪代码管理器的数据收集功能。我们对编写自己的负责会话跟踪和数据收集的 Javascript 库兴趣不大。理想情况下,我们可以简单地确保数据以合理的频率导出到 ClickHouse。
5.从 GA4 中获取数据
我们相信上述经历的痛苦不太可能是独一无二的,因此我们探索了从 Google Analytics 导出数据的方法。谷歌提供了多种方法来实现这一目标,其中大多数都有一些限制。最佳解决方案似乎是将数据导出到 BigQuery。与其他解决方案(例如数据 API)相比,这具有许多优势,包括:
l这将导出没有采样的原始数据。
lGoogle每天最多允许将100 万个事件批量导出到每日表中。这足以满足我们的需求并且低于我们当前的阈值。我们将来可能需要要求 Google 增加这一点。
l数据可以以流Schema导出到每日内表中并支持每日导出。日内“实时”表通常会滞后几分钟。最重要的是,这种导出没有限制!但是,它并不包含所有相同的事件(尽管它符合相同的架构) - 阻止某些查询在实时数据上运行。有趣的是,这开启了实时仪表板的可能性!
流媒体导出每 GB 数据的费用约为 0.05 美元。1 GB 相当于大约 600,000 个 Google Analytics 事件。这对于更多用户来说应该是微不足道的。
如果您为 Google Cloud 帐户启用了 BigQuery,则此连接的配置非常简单且有详细记录。
也许显而易见的问题就变成了:“为什么不直接使用 BigQuery 进行分析呢?”
成本和性能。我们希望通过实时仪表板定期运行查询,尤其是访问实时数据。虽然 BigQuery 非常适合对复杂查询进行临时分析,但它会对扫描的数据收费,从而导致成本难以预测。相反,ClickHouse Cloud 通过小型集群以固定成本提供这些查询(例如每月 < 200 美元的开发层服务)。此外,BigQuery 通常会产生最小的查询延迟。我们知道 ClickHouse 将提供毫秒级响应时间,并且更适合平面Schema(只有两个表)和聚合密集型查询。有关 BigQuery 和 ClickHouse 之间差异的更多详细信息,请参阅此处。
6.BigQuery 到 ClickHouse
有关如何在 BigQuery 和 ClickHouse 之间迁移数据的详细信息,请参阅我们的文档。总之,我们依靠两个计划查询将数据导出到 Parquet 中的 GCS 存储桶:一个用于每日表 (format events_YYYYMMDD),另一个用于实时盘中表 (format events_intraday_YYYYMMDD)。Parquet 是我们首选的导出格式,因为它具有良好的压缩性、结构化Schema以及ClickHouse 对快速读取的出色支持。然后,用户可以使用计划INSERT INTO SELECT查询(使用 cron 服务和gcs 表函数)或最近发布的S3Queue将此数据导入 ClickHouse。
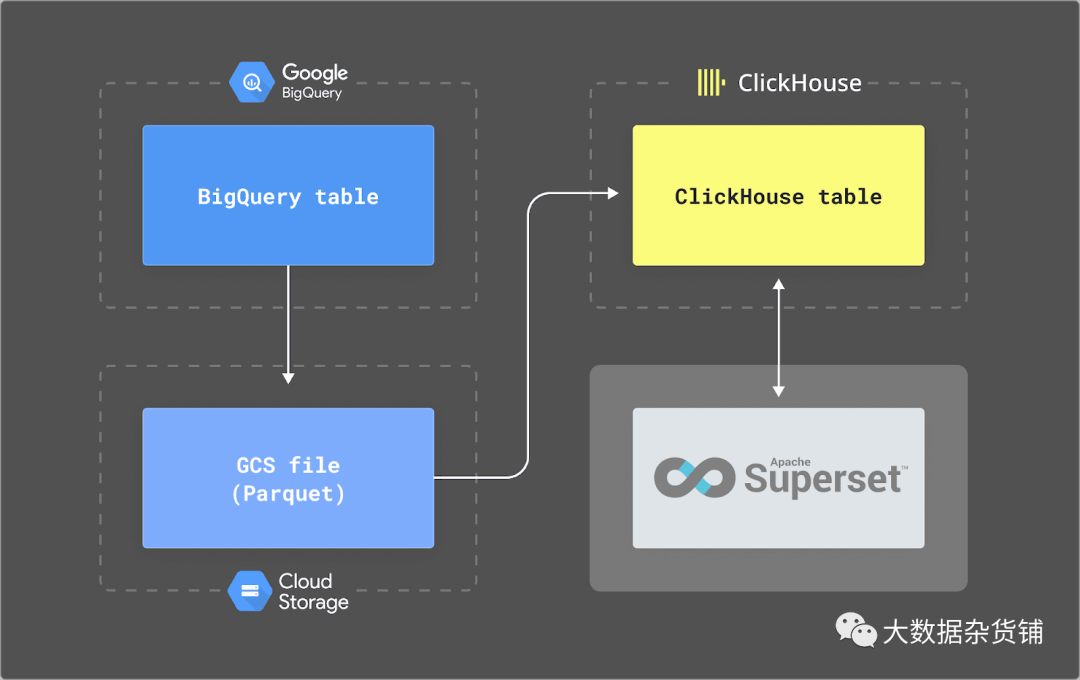
我们在下面提供有关此架构的更多详细信息。
6.1.BigQuery 导出
为了从 BigQuery 导出数据,我们依赖于计划查询及其导出到 GCS 的能力。
我们发现每日表将在格林尼治标准时间下午 4 点左右创建前一天的表。这意味着一天的数据至少有 16 小时不可用。一整天的时间均可一次性提供,因此当天最早的活动最多会延迟 40 小时!这使得盘中数据变得更加重要。为了安全起见,我们在下午 6 点在 BigQuery 中使用以下计划查询进行导出。BigQuery 中的导出每天最多可免费导出 50TiB,且存储成本较低。
DECLARE export_path string;
DECLARE export_day DATE;
SET export_day = DATE_SUB(@run_date, INTERVAL 1 DAY);
SET export_path = CONCAT('gs://clickhouse-website/daily/', FORMAT_DATE('%Y%m%d', export_day),'-*.parquet');
EXECUTE IMMEDIATE format('EXPORT DATA OPTIONS ( uri = \'%s\', format = \'PARQUET\', overwrite = true) AS (SELECT * FROM `..events_%s` ORDER BY event_timestamp ASC)', export_path, FORMAT_DATE('%Y%m%d', export_day));可以更定期地从日内表中导出实时数据。目前,我们每小时安排一次导出。我们每小时导出最后 60 分钟的数据。不过,我们偏移了此窗口,以允许事件可能出现延迟并出现在 BigQuery 中。虽然通常不会超过 4 分钟,但为了安全起见,我们使用 15 分钟。因此,每次运行导出时,我们都会导出从now-75mins到now-15mins的所有行。如下图所示:

该计划查询如下所示。
DECLAREexport_time_lower TIMESTAMP DEFAULT TIMESTAMP_SUB(@run_time, INTERVAL 75 MINUTE);
DECLARE
export_time_upper TIMESTAMP DEFAULT TIMESTAMP_SUB(@run_time, INTERVAL 15 MINUTE);CREATE TEMP TABLE ga_temp AS
SELECT *
FROM..events_intraday_*WHERE TIMESTAMP_MICROS(event_timestamp) > export_time_lower
AND TIMESTAMP_MICROS(event_timestamp) <= export_time_upper;EXPORT DATA
OPTIONS ( uri = CONCAT('gs://clickhouse-website/ga-', FORMAT_TIMESTAMP("%Y%m%d%H%M%S",TIMESTAMP_TRUNC(TIMESTAMP_SUB(CURRENT_TIMESTAMP(),INTERVAL 1 HOUR), HOUR), "UTC"), '_*.parquet'),
format = 'PARQUET', overwrite = true) AS (
SELECT * FROM ga_temp ORDER BY event_timestamp ASC);
6.2.Schema
每日表和日内表的Schema是相同的并记录在此处。上述导出过程生成的 Parquet 文件的架构可以在此处找到以供参考。我们将此Schema映射到以下 ClickHouse Schema:
CREATE OR REPLACE TABLE default.ga_daily
(
event_date Date,
event_timestamp DateTime64(3),
event_name String,
event_params Map(String, String),
ga_session_number MATERIALIZED CAST(event_params['ga_session_number'], 'Int64'),
ga_session_id MATERIALIZED CAST(event_params['ga_session_id'], 'String'),
page_location MATERIALIZED CAST(event_params['page_location'], 'String'),
page_title MATERIALIZED CAST(event_params['page_title'], 'String'),
page_referrer MATERIALIZED CAST(event_params['page_referrer'], 'String'),
event_previous_timestamp DateTime64(3),
event_bundle_sequence_id Nullable(Int64),
event_server_timestamp_offset Nullable(Int64),
user_id Nullable(String),
user_pseudo_id Nullable(String),
privacy_info Tuple(analytics_storage Nullable(String), ads_storage Nullable(String), uses_transient_token Nullable(String)),
user_first_touch_timestamp DateTime64(3),
device Tuple(category Nullable(String), mobile_brand_name Nullable(String), mobile_model_name Nullable(String), mobile_marketing_name Nullable(String), mobile_os_hardware_model Nullable(String), operating_system Nullable(String), operating_system_version Nullable(String), vendor_id Nullable(String), advertising_id Nullable(String), language Nullable(String), is_limited_ad_tracking Nullable(String), time_zone_offset_seconds Nullable(Int64), browser Nullable(String), browser_version Nullable(String), web_info Tuple(browser Nullable(String), browser_version Nullable(String), hostname Nullable(String))),
geo Tuple(city Nullable(String), country Nullable(String), continent Nullable(String), region Nullable(String), sub_continent Nullable(String), metro Nullable(String)),
app_info Tuple(id Nullable(String), version Nullable(String), install_store Nullable(String), firebase_app_id Nullable(String), install_source Nullable(String)),
traffic_source Tuple(name Nullable(String), medium Nullable(String), source Nullable(String)),
stream_id Nullable(String),
platform Nullable(String),
event_dimensions Tuple(hostname Nullable(String)),
collected_traffic_source Tuple(manual_campaign_id Nullable(String), manual_campaign_name Nullable(String), manual_source Nullable(String), manual_medium Nullable(String), manual_term Nullable(String), manual_content Nullable(String), gclid Nullable(String), dclid Nullable(String), srsltid Nullable(String)),
is_active_user Nullable(Bool)
)
ENGINE = MergeTree
ORDER BY (event_timestamp, event_name, ga_session_id)
这个Schema代表了我们的初始迭代,用户可能希望适应。通常,用户可能希望在视图中向其业务用户呈现此数据,以便于使用,或者具体化特定列以便在语法上更容易(更快)访问,例如在上面,我们已经具体化了列ga_session_id、page_location和page_titlepage_referer。
我们的排序键已针对我们的访问Schema和下面的查询进行了选择。
有经验的 ClickHouse 用户会注意到 Nullable 的使用,这通常是 ClickHouse 中表示空值的低效方法。目前,我们在将 event_params 转换为更易于访问的 Map(String,String) 时根据需要保留它们。将来,我们计划为 Parquet 文件添加Schema提示,以允许我们关闭默认情况下使 Parquet 列可为空的功能schema_inference_make_columns_nullable = 0,即 。然而,由于 ClickHouse 的数据量较低,我们预计这种 Nullable 开销会很小。
我们可以使用 gcs 函数和INSERT INTO SELECT将数据从 Parquet 文件插入到此Schema中。该语句对于两个表都是相同的。
INSERT INTO ga_daily SELECT
event_date::Date as event_date,
fromUnixTimestamp64Micro(event_timestamp) as event_timestamp,
ifNull(event_name, '') as event_name,
mapFromArrays(
arrayMap(x -> x.1::String, event_params),
arrayMap(x -> arrayFilter(val -> isNotNull(val),array(untuple(x.2:: Tuple(string_value Nullable(String), int_value Nullable(String), float_value Nullable(String), double_value Nullable(String))))::Array(Nullable(String)))[1], event_params)
)::Map(String, String) as event_params,
fromUnixTimestamp64Micro(ifNull(event_previous_timestamp,0)) as event_previous_timestamp,
event_bundle_sequence_id,
event_server_timestamp_offset,
user_id,
user_pseudo_id,
privacy_info,
fromUnixTimestamp64Micro(ifNull(user_first_touch_timestamp,0)) as user_first_touch_timestamp,
device,
geo,
app_info,
traffic_source,
stream_id,
platform,
event_dimensions,
collected_traffic_source,
is_active_user
FROM gcs('https://storage.googleapis.com/clickhouse-website/ga-.parquet','','')这里的大多数列都是直接映射。但是,我们确实将event_params列转换为 Map(String,String),将格式转换成Array(Tuple(key Nullable(String), value Tuple(string_value Nullable(String), int_value Nullable(Int64), float_value Nullable(Float64), double_value Nullable(Float64)))),
以使查询在语法上更简单。
6.3.GCS 到 ClickHouse
虽然我们的内部数据仓库有自己的自定义加载数据机制,但 ClickHouse 用户可以通过计划INSERT INTO SELECT(例如使用简单的 cron或通过Cloud Scheduler)或使用最近发布的 S3Queue 表引擎来重现上述Schema。我们在下面演示这一点:
CREATE TABLE ga_queue
ENGINE = S3Queue('https://storage.googleapis.com/clickhouse-website/daily/.parquet', '', '', 'Parquet')
SETTINGS mode = 'unordered', s3queue_enable_logging_to_s3queue_log=1, s3queue_tracked_files_limit=10000
CREATE MATERIALIZED VIEW ga_mv TO ga_daily AS
SELECT
event_date::Date as event_date,
fromUnixTimestamp64Micro(event_timestamp) as event_timestamp,
ifNull(event_name, '') as event_name,
mapFromArrays(
arrayMap(x -> x.1::String, event_params),
arrayMap(x -> arrayFilter(val -> isNotNull(val),array(untuple(x.2:: Tuple(string_value Nullable(String), int_value Nullable(String), float_value Nullable(String), double_value Nullable(String))))::Array(Nullable(String)))[1], event_params)
)::Map(String, String) as event_params,
fromUnixTimestamp64Micro(ifNull(event_previous_timestamp,0)) as event_previous_timestamp,
event_bundle_sequence_id,
event_server_timestamp_offset,
user_id,
user_pseudo_id,
privacy_info,
fromUnixTimestamp64Micro(ifNull(user_first_touch_timestamp,0)) as user_first_touch_timestamp,
device,
geo,
app_info,
traffic_source,
stream_id,
platform,
event_dimensions,
collected_traffic_source,
is_active_user
FROM ga_queue
可以在此处找到此功能的更多示例。
将来,我们还计划添加对使用ClickPipes从对象存储增量加载数据的支持:ClickHouse Cloud 的本机数据摄取服务引擎,使加载数据就像单击几个按钮一样简单。
7.查询
将所有数据转移到 Clickhouse 的主要问题之一是能否从 Google 在导出中提供的原始数据复制 Google Analytics 提供的指标。虽然 Google 记录了一些查询,但它们没有为新用户、活跃用户、总用户、回访用户或总会话的标准报告概念提供等效查询。为了让营销人员能够利用 ClickHouse 解决方案,我们需要能够提供与历史报告数据相当的数据的查询。
以下查询显示了我们当前使用的查询以及它们相对于 GA4 报告的数字的误差范围。这一差异是在一个月内计算得出的。请注意,由于未提供某些必需的列,因此无法对实时盘中数据进行所有查询。我们在下面指出这一点。
指标 | ClickHouse查询 | 与GA4的区别 | 支持日内事务 |
|---|---|---|---|
用户总数 | SELECT event_date, uniqExact(user_pseudo_id) AS total_users FROM ga_daily WHERE event_name = 'session_start' GROUP BY event_date ORDER BY event_date ASC | -0.71% | Yes |
活跃用户 | SELECT event_date, uniqExact(user_pseudo_id) AS active_usersFROM ga_dailyWHERE ((event_name = 'session_start') AND is_active_user) OR (event_name = 'first_visit')GROUP BY event_dateORDER BY event_date ASC | -0.84 | No.is_active_user未填充 |
新用户 | SELECT event_date, count() AS new_usersFROM ga_dailyWHERE event_name = 'first_visit'GROUP BY event_dateORDER BY event_date ASC | 0% | Yes |
回访用户 | SELECT event_date, uniqExact(user_pseudo_id) AS returning_usersFROM ga_dailyWHERE (event_name = 'session_start') AND is_active_user AND (ga_session_number > 1 OR user_first_touch_timestamp < event_date)GROUP BY event_dateORDER BY event_date ASC | +1.03% | No.is_active_user未填充 |
总会话数 | SELECT event_date, uniqExact(ga_session_id, '_', user_pseudo_id) AS session_idFROM ga_dailyGROUP BY event_dateORDER BY event_date ASC | -0.56% | Yes |
虽然我们继续尝试缩小上述差异,但上述差异对于后续报告来说被认为是可以接受的。我们欢迎对上述查询进行改进。
8.验证方法
我们的数据被加载到我们的内部数据仓库中,该仓库托管着许多具有大量资源的数据集,因此很难对运行我们的 ClickHouse 增强型 GA 解决方案的成本进行精确评估。然而,我们的初始测试是在 ClickHouse 云开发层服务中执行的。这将存储限制为 1TiB,并在两个节点上提供总共 4vCPU 和 16GiB RAM,对于大多数组织来说足以运行上述解决方案。
下面,我们介绍了运行基于此服务的解决方案的可能成本,并评估了可能存储的 GA4 数据量。我们还表明查询性能仍然非常快。我们的样本数据涵盖 42 天的时间段。
8.1.压缩
SELECT
table,
formatReadableQuantity(sum(rows)) AS total_rows,
round(sum(rows) / 42) AS events_per_day,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
round(sum(data_uncompressed_bytes) / sum(data_compressed_bytes), 2) AS ratio
FROM system.parts
WHERE (table LIKE 'ga_daily') AND active
GROUP BY table
ORDER BY sum(rows) ASC
┌─table────┬─total_rows───┬─events_per_day─┬─compressed_size─┬─uncompressed_size─┬─ratio─┐
│ ga_daily │ 5.75 million │ 136832 │ 525.34 MiB │ 4.56 GiB │ 8.88 │
└──────────┴──────────────┴────────────────┴─────────────────┴───────────────────┴───────┘
1 row in set. Elapsed: 0.008 sec.上图显示,42 天的未压缩数据大小约为 4.6GiB,每天约有 135k 个事件。然而,磁盘空间被压缩为仅 525MiB。我们假设我们的日内表消耗类似的空间量。因此,这可能允许开发层服务存储 = 420429 ( (1048576/(525*2)) * 421) 天或 1100 年的 GA4 数据。这对于我们的用例来说可能绰绰有余!*
用户应该能够根据每天的事件推断出上述内容。即使是比 clickhouse.com 大 100 倍的网站也应该能够在单个开发层实例中托管 10 年的数据。
*这是在进一步的架构优化之前,例如删除 Nullable。
8.2.查询性能
GA4 的 BigQuery 导出服务不支持历史数据导出。这使我们无法在此阶段执行广泛的查询测试(我们稍后将根据实际使用情况进行分享),从而将下面的查询限制为 42 天(自我们开始将数据从 BigQuery 移至 ClickHouse 以来的时间)。这对于我们的用例来说已经足够了,因为我们的大多数查询都涵盖一个月的时间,而分析历史趋势的查询则很少见。以下查询查询我们网站blog区域10 月份的总用户数、回访用户数和新用户数,按天对结果进行分组。
用户总数
SELECT
event_date,
uniqExact(user_pseudo_id) AS total_users
FROM ga_daily
WHERE (event_name = 'session_start') AND ((event_timestamp >= '2023-10-01') AND (event_timestamp <= '2023-10-31')) AND (page_location LIKE '%/blog/%')
GROUP BY event_date
ORDER BY event_date ASC
31 rows in set. Elapsed: 0.354 sec. Processed 4.05 million rows, 535.37 MB (11.43 million rows/s., 1.51 GB/s.)
Peak memory usage: 110.98 MiB.
回访用户
SELECT event_date, uniqExact(user_pseudo_id) AS returning_users
FROM ga_daily
WHERE (event_name = 'session_start') AND is_active_user AND (ga_session_number > 1 OR user_first_touch_timestamp < event_date) AND ((event_timestamp >= '2023-10-01') AND (event_timestamp <= '2023-10-31')) AND (page_location LIKE '%/blog/%')
GROUP BY event_date
ORDER BY event_date ASC
31 rows in set. Elapsed: 0.536 sec. Processed 4.05 million rows, 608.24 MB (7.55 million rows/s., 1.13 GB/s.)
Peak memory usage: 155.48 MiB.
新用户
SELECT
event_date, count() AS new_users
FROM
ga_daily
WHERE
event_name = 'first_visit' AND ((event_timestamp >= '2023-10-01') AND
(event_timestamp <= '2023-10-31')) AND (page_location LIKE '%/blog/%')
GROUP
BY event_date
ORDER
BY event_date ASC
31
rows in set. Elapsed: 0.320 sec. Processed 4.05 million rows, 411.97 MB (12.66
million rows/s., 1.29 GB/s.)
Peak
memory usage: 100.78 MiB.上面显示了所有查询如何在 0.5 秒内返回。我们表的排序键可以进一步优化,如果需要进一步提高性能,用户可以自由使用物化视图和投影等功能。
8.3.成本
在下面的定价中,我们假设使用大约 100GiB 的存储,或 10% 的容量。这实际上相当于 clickhouse.com 大约 110 年的数据,对于 10 倍大小的网站来说,大约 10 年的数据,或者对于 100 倍大小的网站来说,保留 1 年。实际上,如图所示,由于在 ClickHouse Cloud 中使用了对象存储,存储仅占总成本的一小部分,并且较大的站点可以轻松存储多年,并且仍保持在 20 美元以下。
我们假设集群每天总共活跃 2 小时。这应该足以每小时加载日内数据和每日导出,以及由好奇的营销部门执行的额外临时查询。如下所示,较大的每日导出可在 5 秒内插入。
请注意,如果使用完整的 1TiB 存储,则每月最多花费 193 美元。实际上,如果集群不被使用,它将闲置(仅产生存储费用),从而降低成本。
INSERT INTO ga_daily SELECT
...
FROM gcs('https://storage.googleapis.com/clickhouse-website/daily/20231009-000000000000.parquet', '', '')
0 rows in set. Elapsed: 5.747 sec. Processed 174.94 thousand rows, 15.32 MB (30.44 thousand rows/s., 2.67 MB/s.)
每小时计算成本: 0.2160 美元 每月存储成本: 35.33 美元 * 0.1 = 3.53 美元 每天活跃小时数: 2
总成本:(每天 2 小时 * 0.2160 * 30 天)+ 3.53 = 16.50 美元
ClickHouse 中增强型 Google Analytics 的费用为每天 16 美元!
这里有一些额外的成本,我们认为这些成本应该可以忽略不计。这些包括:
l将成本从 GA4 导出到 BigQuery。每 GB 数据 0.05 美元。1 GB 相当于大约 600,000 个 Google Analytics 事件或上述示例数据的 5 倍。我们假设这可以忽略不计,即对于 10 倍大小的网站来说 < 1 美元。
lBigQuery 中的数据存储。每月前1 TiB 免费;此后按需定价约为每 TiB 6 美元。考虑到上述数量,用户不应在此处产生费用,并且如果担心的话,可以在 N 天后使 BigQuery 中的数据过期。
9.可视化
ClickHouse 支持从 Tableau 到 QuickSight 的各种可视化工具。对于我们的内部数据仓库,我们使用 Superset 和官方 ClickHouse 连接器。凭借大量的可视化选项,我们发现这是一个出色的解决方案,足以满足我们的需求。我们确实建议将表公开为物理数据集,以便可以通过超集和应用于架构中所有列的仪表板的过滤器来组成查询。下面,我们展示了一些可视化的示例。
9.1.概览仪表板
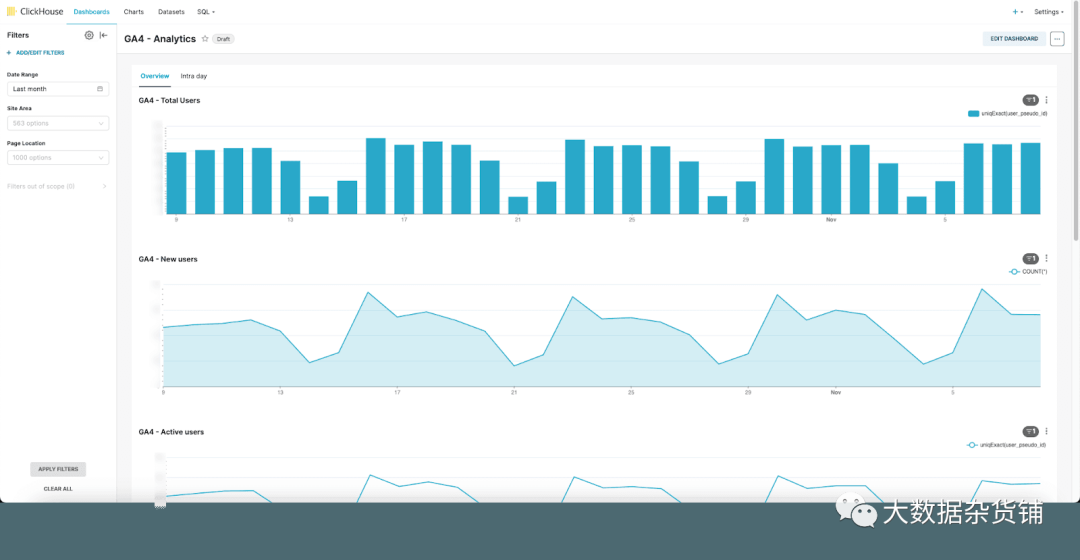
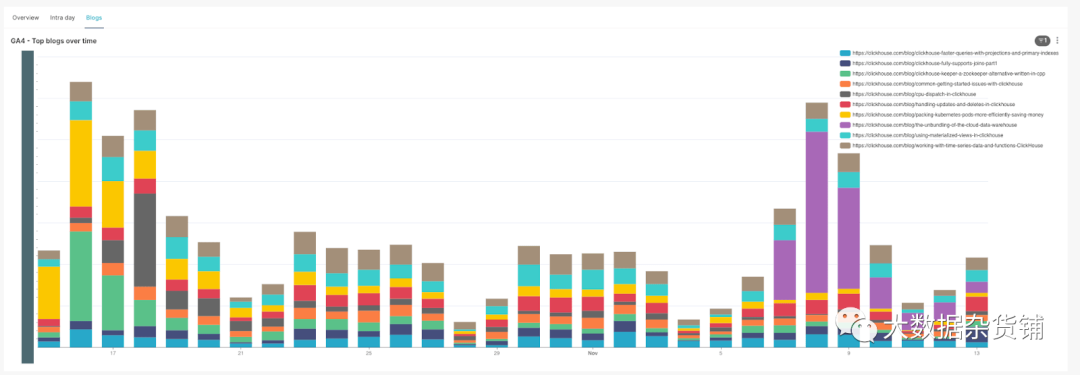
随着时间的推移最受欢迎的博客文章
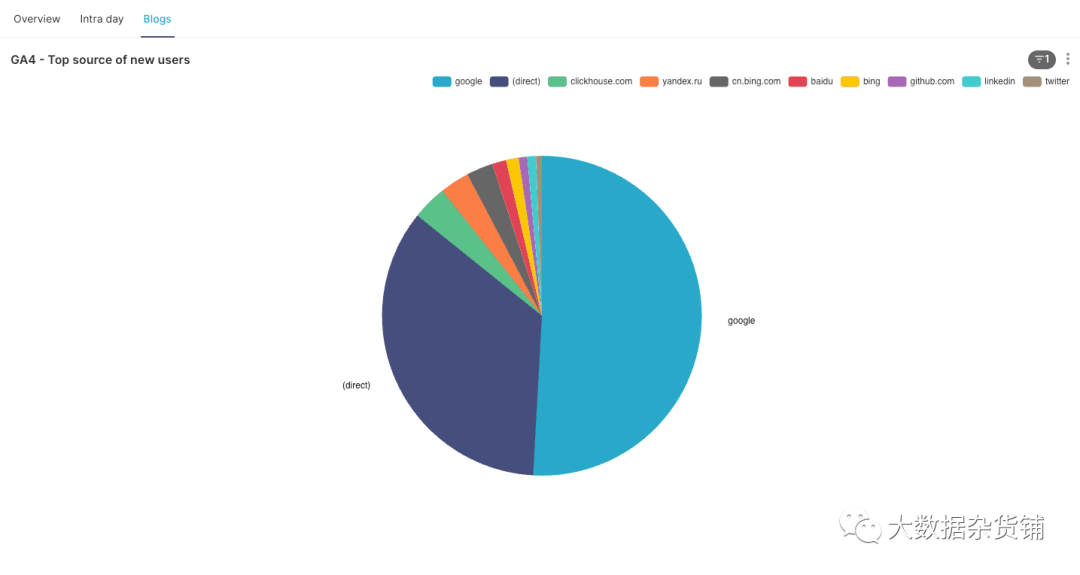
热门流量来源
10.下一步是什么
我们剩下的工作主要围绕确保数据集在我们的内部数据仓库中可用,我们可以用它来丰富我们的分析。例如,许多页面都按主题进行分类,以便我们可以根据这些数据进行使用情况分析。这些数据非常小,主要用于查询时的查找。一旦我们能够通过我们的 CMS 优雅地公开这些数据,我们计划通过字典来管理这些数据。
字典为我们提供了数据的内存中键值对表示,并针对低潜在查找查询进行了优化。一般而言,我们可以利用这种结构来提高查询的性能,尤其是在 JOIN 的一侧表示适合内存的查找表的情况下,JOIN 特别受益。更多详细信息请参见此处。
最后,认识到并不是每个人都对 SQL 感到满意,并且本着一切都需要生成人工智能才能变得很酷且值得做的精神,我决定衍生一个副项目,看看我们是否可以通过自然语言回答 Google Analytics 问题。想象一下这样一个世界,您只需输入“向我显示去年一段时间内有关 X 的页面的新用户”,您就会神奇地看到一张图表。是的,雄心勃勃。可能是一个童话故事。敬请关注。
10.1.结论
我们提出了一种使用 ClickHouse 增强 Google Analytics 数据的简单方法,以每月不到 20 美元的价格提供灵活、快速的分析和无限保留。
原文链接:https://clickhouse.com/blog/enhancing-google-analytics-data-with-clickhouse