CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
点击下方卡片,关注「AiCharm」公众号
Subjects: cs.CV
1.Let's Go Shopping (LGS) -- Web-Scale Image-Text Dataset for Visual Concept Understanding

标题:Let's Go Shopping (LGS)——用于视觉概念理解的网络规模图像文本数据集
作者:Yatong Bai, Utsav Garg, Apaar Shanker, Haoming Zhang, Samyak Parajuli, Erhan Bas, Isidora Filipovic, Amelia N. Chu, Eugenia D Fomitcheva, Elliot Branson, Aerin Kim, Somayeh Sojoudi, Kyunghyun Cho
文章链接:https://arxiv.org/abs/2401.04575




摘要:
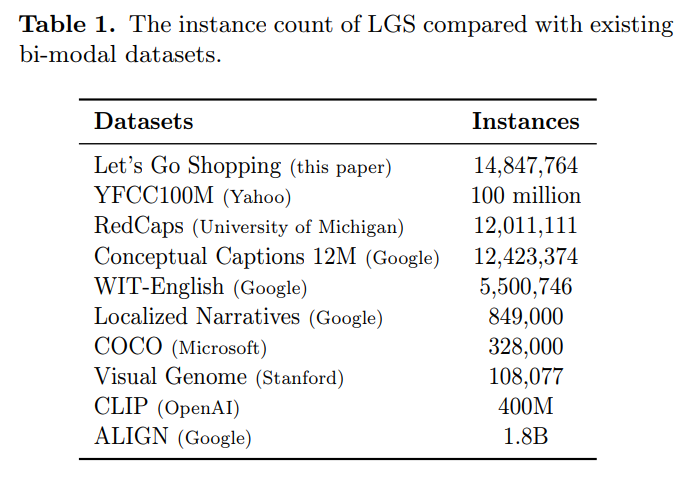
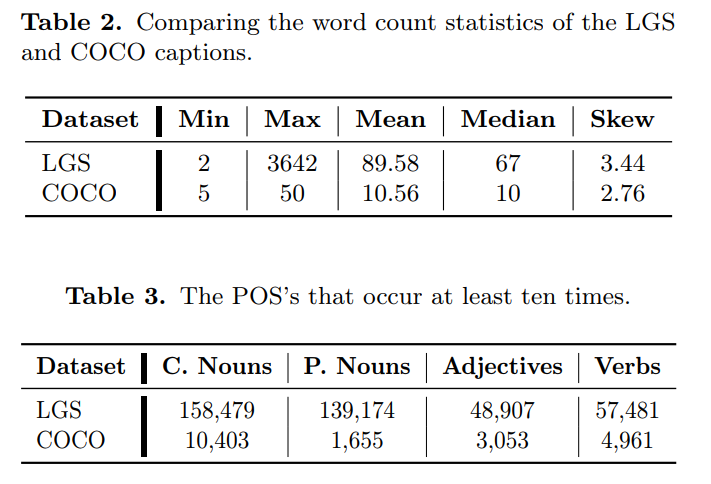
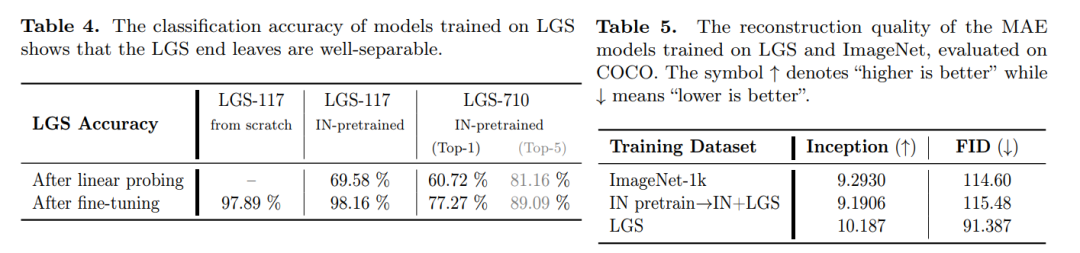
神经网络的视觉和视觉语言应用(例如图像分类和字幕)依赖于需要非平凡数据收集过程的大规模注释数据集。这种耗时的工作阻碍了大规模数据集的出现,将研究人员和从业者的选择限制在少数。因此,我们寻求更有效的方法来收集和注释图像。以前的举措是从 HTML 替代文本中收集标题并抓取社交媒体帖子,但这些数据源存在噪音、稀疏性或主观性。因此,我们选择数据符合三个标准的商业购物网站:干净、信息丰富、流畅。我们介绍 Let's Go Shopping (LGS) 数据集,这是一个大型公共数据集,包含来自公开电子商务网站的 1500 万个图像标题对。与现有的通用域数据集相比,LGS 图像专注于前景物体,背景不太复杂。我们在 LGS 上的实验表明,在现有基准数据集上训练的分类器不容易泛化到电子商务数据,而特定的自监督视觉特征提取器可以更好地泛化。此外,LGS 的高质量电子商务图像和双模态特性使其在视觉语言双模态任务中具有优势:LGS 使图像字幕模型能够生成更丰富的字幕,并帮助文本到图像生成模型实现电子商务风格转移。
2.Model Editing Can Hurt General Abilities of Large Language Models

标题:模型编辑可能会损害大型语言模型的通用能力
作者:Jia-Chen Gu, Hao-Xiang Xu, Jun-Yu Ma, Pan Lu, Zhen-Hua Ling, Kai-Wei Chang, Nanyun Peng
文章链接:https://arxiv.org/abs/2401.04700
项目代码:https://github.com/JasonForJoy/Model-Editing-Hurt
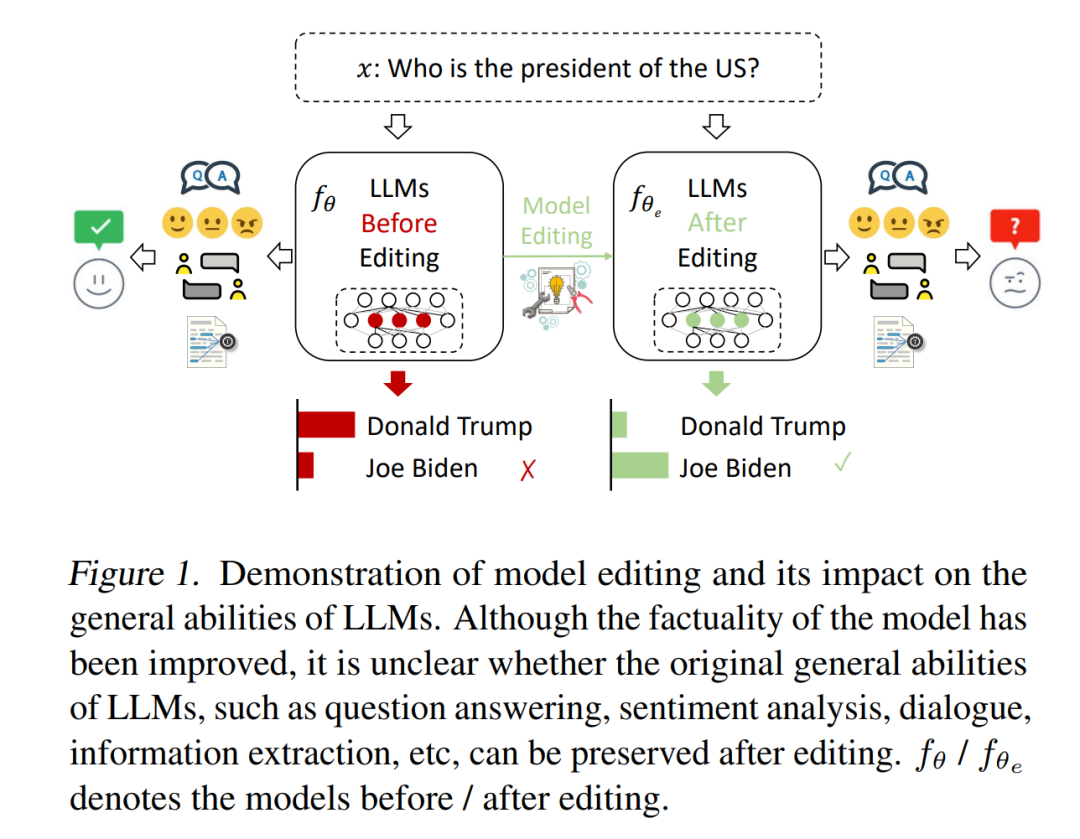
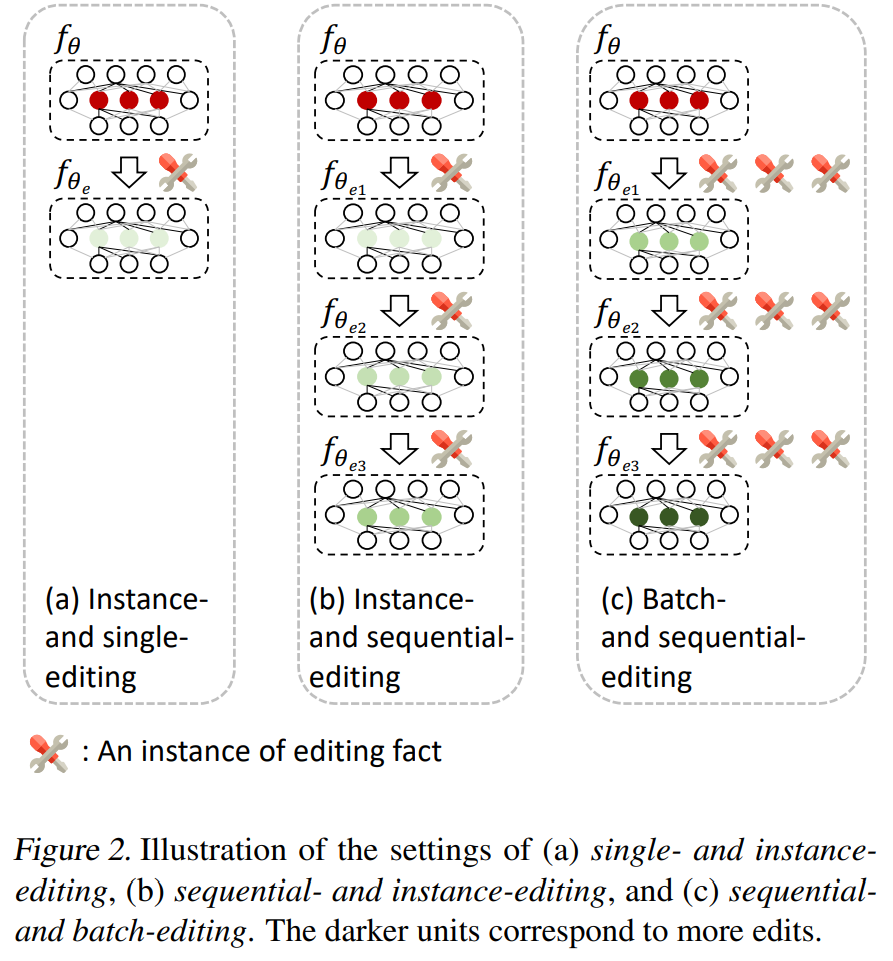
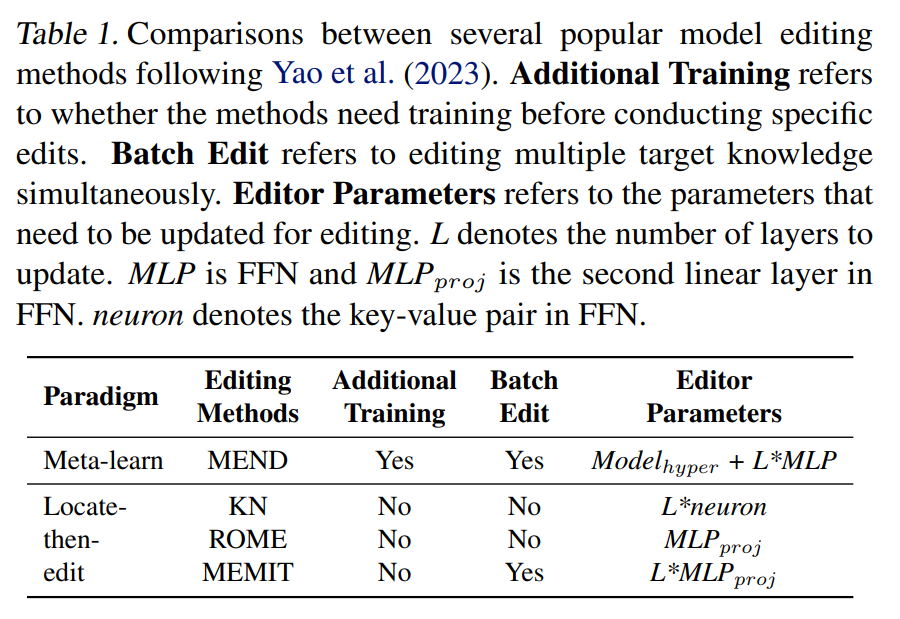
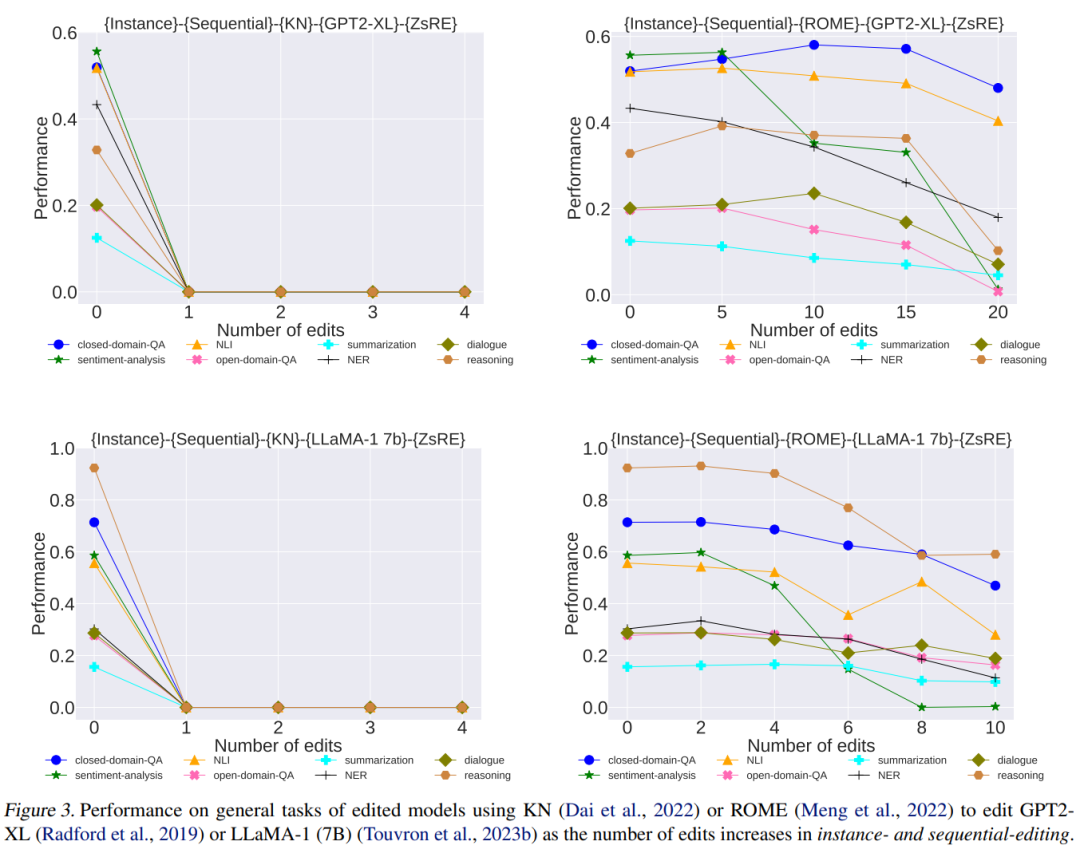
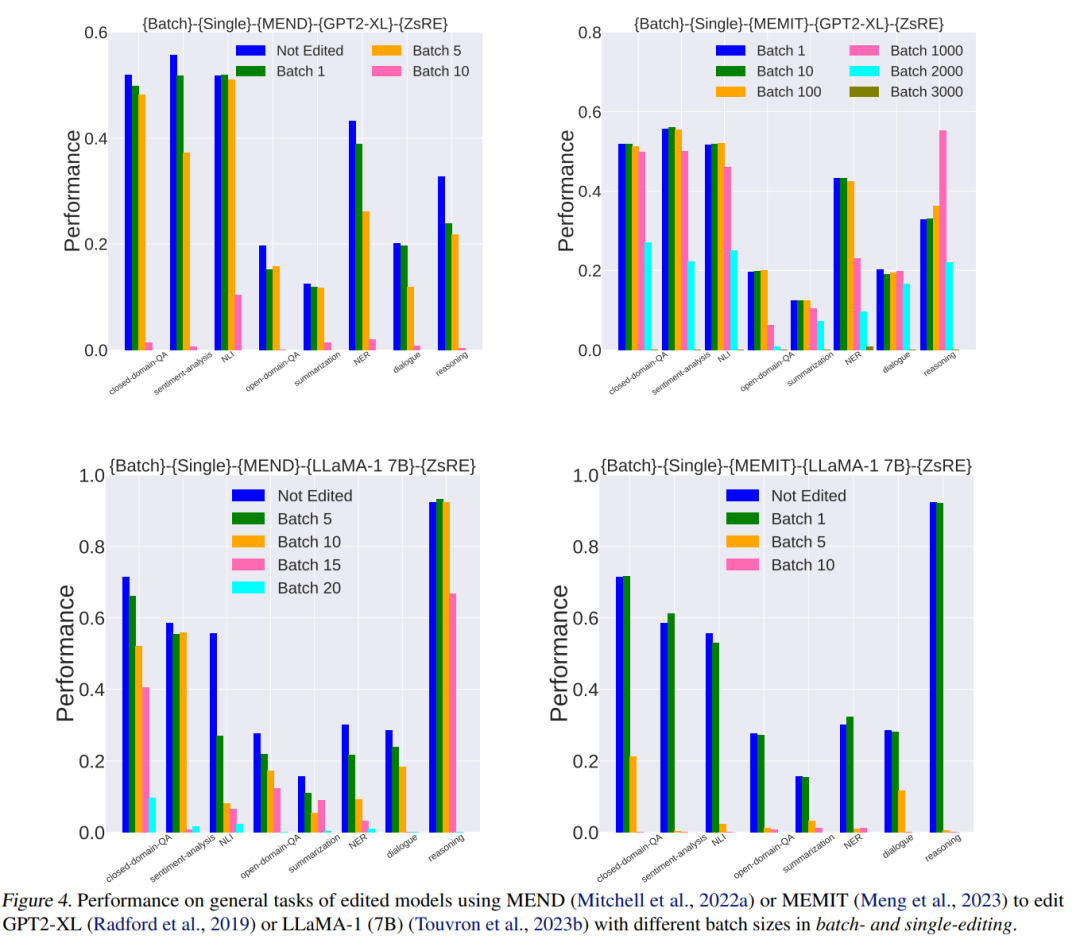
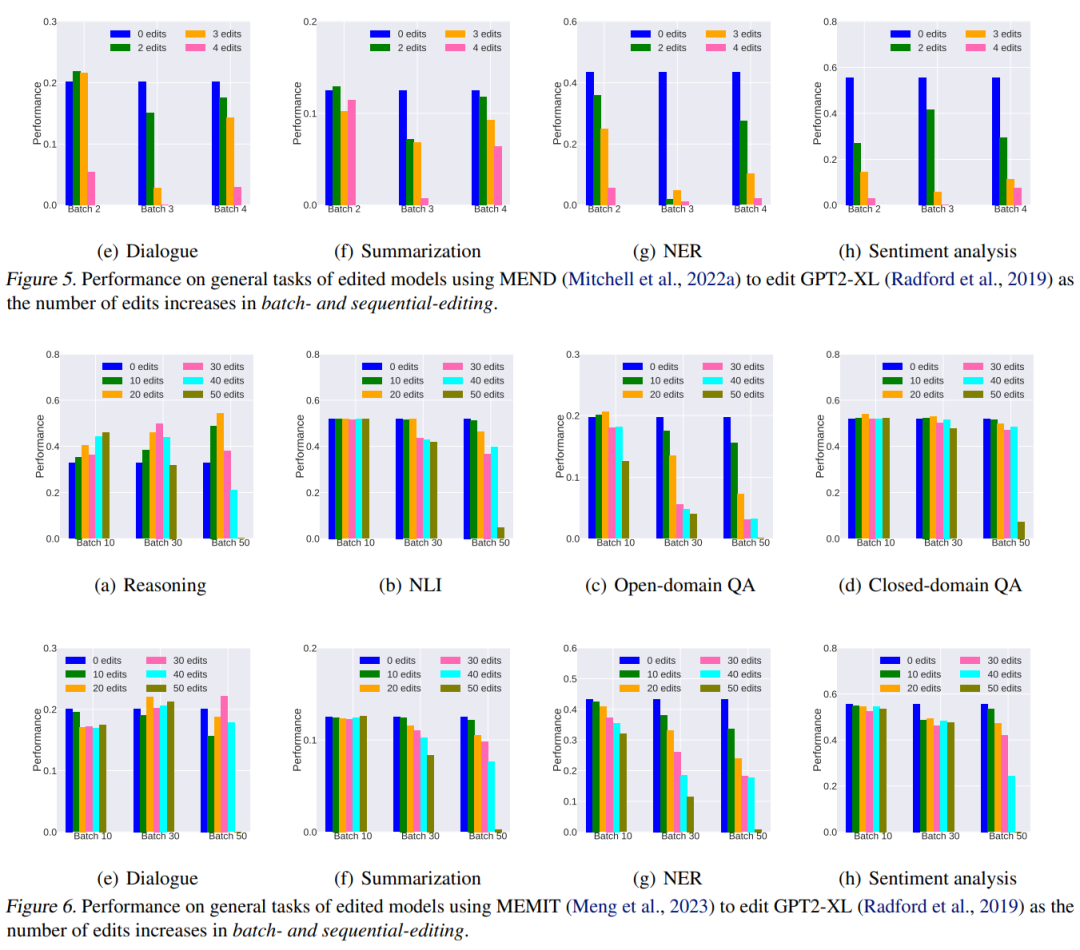
摘要:
大型语言模型 (LLMs) 的最新进展为访问存储在其参数中的知识开辟了新的范式。出现的一个关键挑战是由于错误或过时的知识而导致 LLM 输出中出现幻觉。由于使用更新的信息重新训练LLMs需要大量资源,因此人们对模型编辑的兴趣越来越大。然而,许多模型编辑方法虽然在各种场景下都有效,但往往过分强调编辑性能的有效性、泛化性和局部性等方面,往往忽视了对LLMs一般能力的潜在副作用。在本文中,我们担心模型真实性的提高可能会以这些通用能力的显着下降为代价,这不利于LLMs的可持续发展。我们通过评估八个代表性任务类别中两个 LLMs 的四种流行编辑方法来系统地分析副作用。广泛的实证研究表明,模型编辑确实提高了模型的真实性,但代价是严重损害了一般能力。因此,我们主张进行更多的研究工作,以尽量减少在预训练期间获得的一般能力的损失,并最终在模型编辑期间保留它们。
3.InseRF: Text-Driven Generative Object Insertion in Neural 3D Scenes

标题:InseRF:神经 3D 场景中文本驱动的生成对象插入
作者:Mohamad Shahbazi, Liesbeth Claessens, Michael Niemeyer, Edo Collins, Alessio Tonioni, Luc Van Gool, Federico Tombari
文章链接:https://arxiv.org/abs/2401.05335
项目代码:https://mohamad-shahbazi.github.io/inserf/

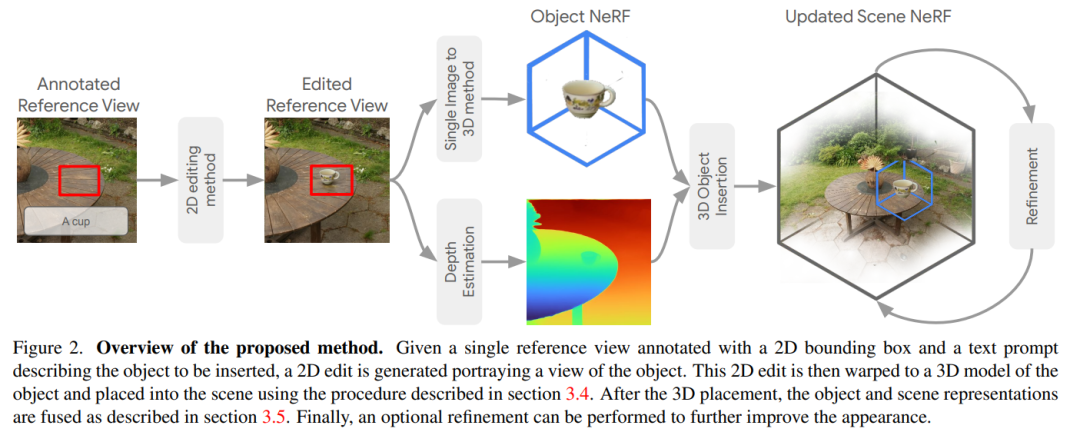



摘要:
我们介绍 InseRF,这是一种在 3D 场景的 NeRF 重建中生成对象插入的新方法。基于用户提供的文本描述和参考视点中的 2D 边界框,InseRF 在 3D 场景中生成新对象。最近,由于在 3D 生成建模中使用了文本到图像扩散模型的强先验,3D 场景编辑方法已经发生了深刻的转变。现有方法在通过样式和外观更改或删除现有对象来编辑 3D 场景时最有效。然而,生成新对象仍然是此类方法的一个挑战,我们在本研究中解决了这个问题。具体来说,我们建议将 3D 对象插入基础为场景参考视图中的 2D 对象插入。然后使用单视图对象重建方法将 2D 编辑提升为 3D。然后,在单目深度估计方法的先验指导下,将重建的对象插入场景中。我们在各种 3D 场景上评估我们的方法,并对所提出的组件进行深入分析。我们在多个 3D 场景中生成对象插入的实验表明,与现有方法相比,我们的方法是有效的。InseRF 能够进行可控且 3D 一致的对象插入,而不需要明确的 3D 信息作为输入。