在july的网站购买了kaggle课程,自己学习并作笔记记录,非给july打广告,只是为了不忘记或自己学习查询。
在这里感谢july提供的该课程。
下面开始笔记。
- 主要内容

- 应用领域

- 常用算法

- 算法之间的联系
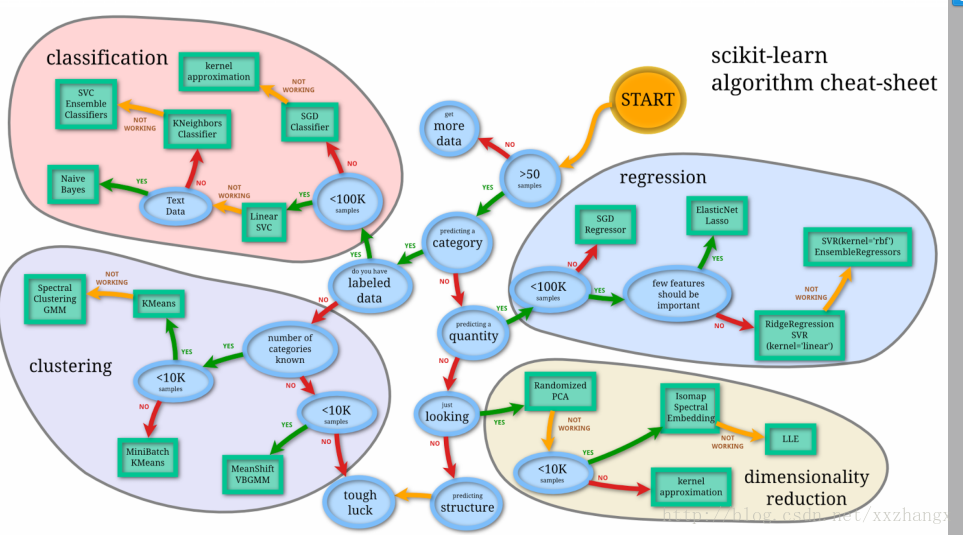
- 工具

常用scikit-learn ,文本分析用gensim,数据处理用Numpy、matplotlib、pandas,深度学习有tensorflow、caffe、keras
- 解决问题的流程

图中的链接: http://blog.csdn.net/han_xiaoyang/article/details/50469334
http://blog.csdn.net/han_xiaoyang/article/details/52910022
内容很详细,值得一看。
- 数据预处理

上采样: 下采样: 数据样本均衡: 正例、负例样本量保持均衡,之间数量差别不要太大。
- 特征工程
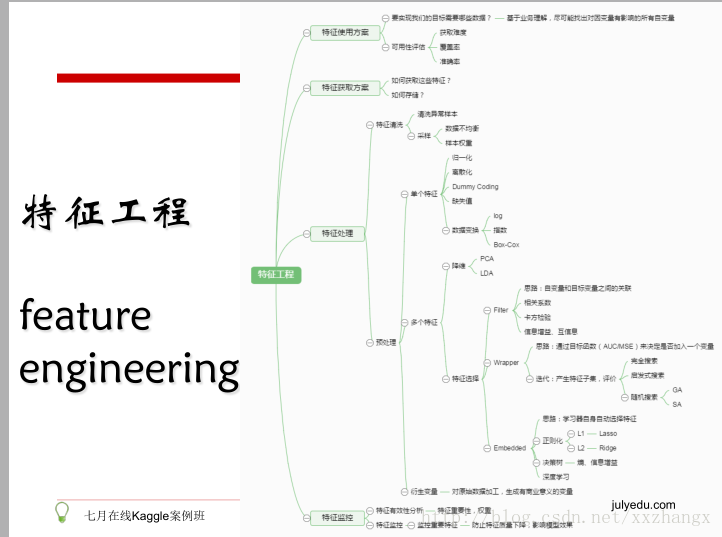
这里建议看特征工程三把刀那篇博文: http://www.36dsj.com/archives/69769
- 特征类型

参考内容: http://scikit-learn.org/stable/modules/preprocessing.html
http://scikit-learn.org/stable/modules/classes.html#module-sklearn.feature_extraction
- 方法

链接:http://scikit-learn.org/stable/modules/feature_selection.html
- 交叉验证

链接:http://scikit-learn.org/stable/modules/cross_validation.html
- 模型参数选择

链接: 交叉验证http://scikit-learn.org/stable/modules/grid_search.html
http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html
- 模型状态评估
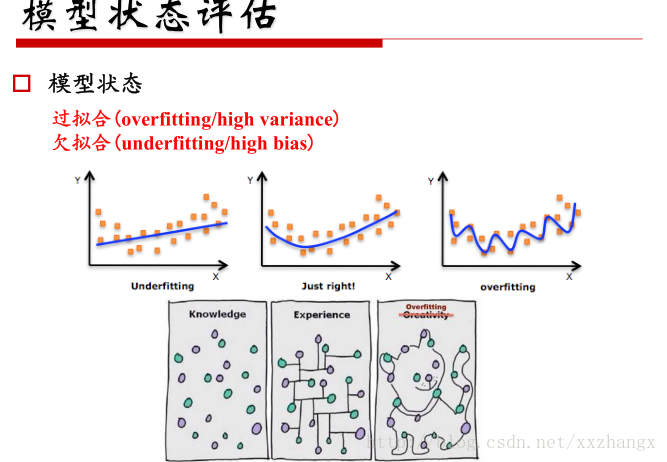
用于判断模型是否过拟合还是欠拟合
- 学习曲线
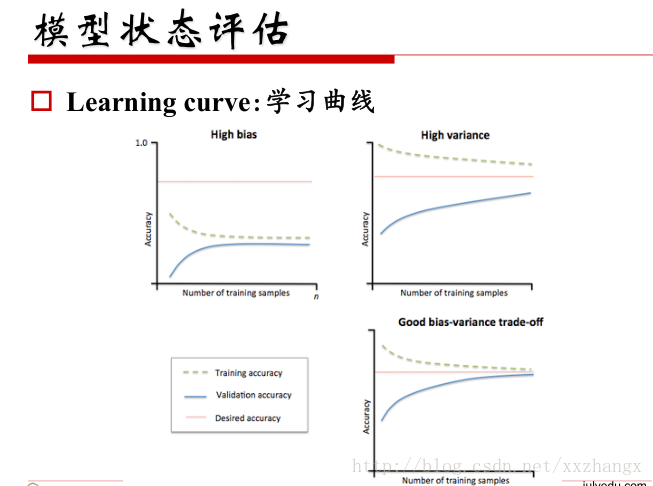
模型训练后的训练误差和测试误差
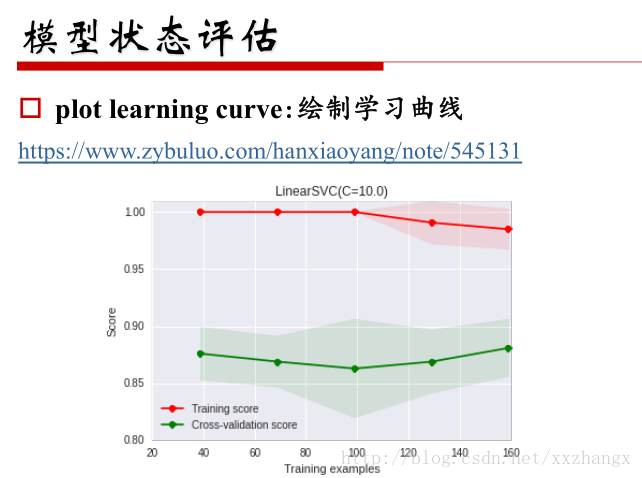
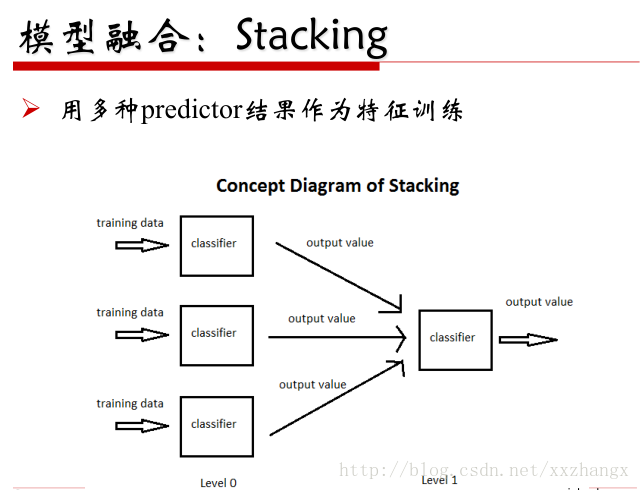
- 模型融合



链接:http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.BaggingClassifier.html

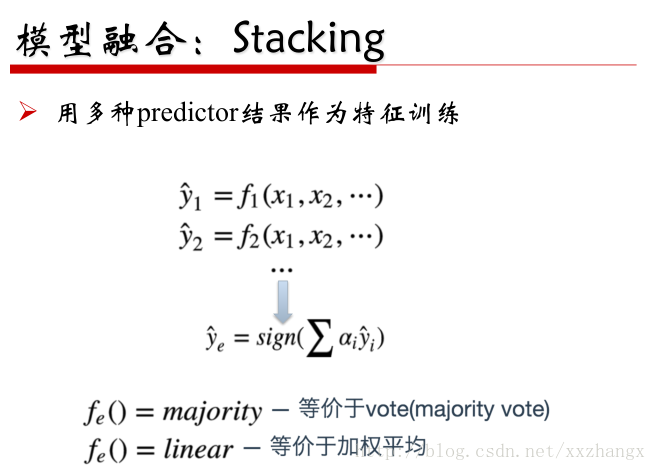
- Boosting

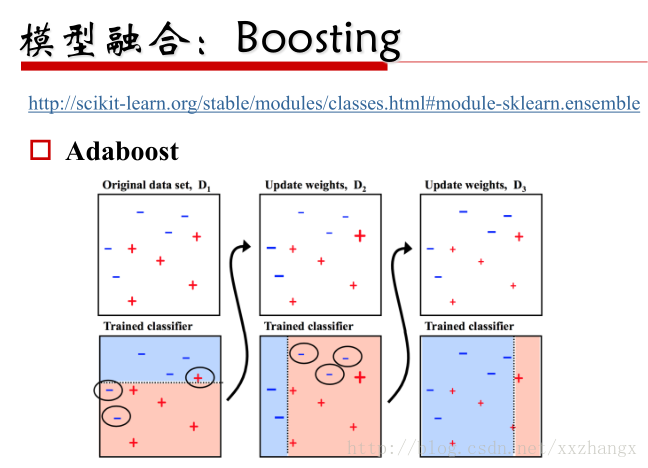
链接:http://scikit-learn.org/stable/modules/classes.html#module-sklearn.ensemble
