上一期我们留下了一个题目: 判断一个字符串是否是另一个字符串左旋后的字符: 其实我们只要将原字符串用memcpy加到原字符串的后面构成一个新的字符串,只要你给出的字符串在这个新的字符串里面(用strstr函数),那么他就是这个字符串左旋后的字符串 例如:BCDA如果在下面的这个字符串中,所以是左旋后的字符串

冒泡排序
首先我们来了解一下在不使用qsort函数下的冒泡排序代码: 这里的第一个循环的目的是要对这个数组进行排序的次数 而第二个循环就是这一趟排序要比较的数字的个数 假如size等于10 按规律来就是第一趟要将第一个元素比较其他的9个元素进行比较 但是第二趟就只需要8个,以此进行减一操作 因为下标是从零开始,所以j的范围是小于size-i-1,而不是小于等于
void Bubble_sort(int arr[], int size)
{
int j,i,tem;
for (i = 0; i < size-1;i ++)
{
int count = 0;
for (j = 0; j < size-1 - i; j++)
{
if (arr[j] > arr[j+1])
{
tem = arr[j];
arr[j] = arr[j+1];
arr[j+1] = tem;
count = 1;
}
}
if (count == 0)
break;
}
}qsort函数
下面我们来了解一下qsort函数: 推荐大家一个网站,用来了解不懂的函数,可以去里面搜索它的用法 https://cplusplus.com/
为了方便理解,我将其转为中文进行讲解:
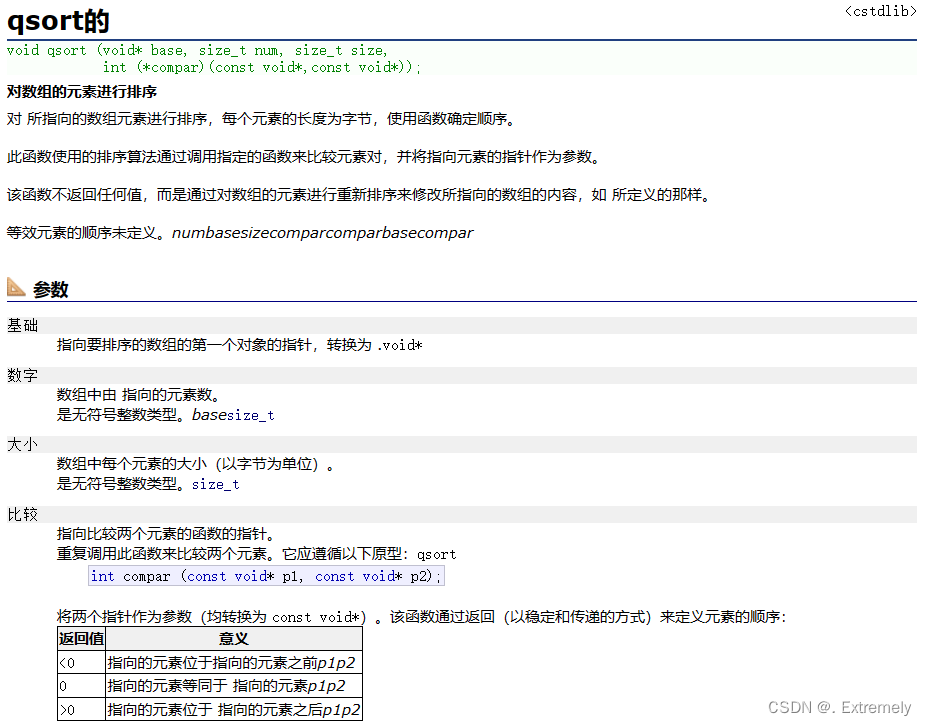
可以看到,qsort的函数用法如下: 一共需要四个元素,第一个base就是你要排序的数组 num就是base的元素个数 size是base一个元素的大小,单位是字节 而(compar)(const void,const void*))就是一个函数指针了
void qsort (void* base, size_t num, size_t size,
int (*compar)(const void*,const void*));关于这个函数指针,cplusplus上面也有相对应的解释: 他是用于比较两个元素的一个函数的指针 如果他返回的值小于0,就是p1小于p2 等于0就是p1等于p2,大于0就是p1大于p2

所以,qsort函数就是直接将base里的所有元素进行快速的冒泡排序,也可以是字符型,而我们此前写的冒泡排序只是针对于整形数据的。
qsort函数的模拟实现
下面我们将进行qsort函数的模拟实现 首先,我们要知道,qsort函数就是基于冒泡排序的,所以,我们先构建一个基本的冒泡排序框架:
void bubble_sqort(void* arr, int sz, int size, int(*cmp)(const void*, const void*))
{
int i = 0;
int j = 0;
int* tmp = (int*)arr;
for (i = 0; i < sz; i++)
{
for (j = 0; j < sz - 1 - i; j++)
{
...........
}
}
}这个大家都知道吧,就和上面的冒泡排序的一样,就是循环内部的语句不一样,下面我们对for循环里面的执行语句展开分析: 我们知道,要进行排序就是要进行比较然后再进行位置的交换呗,并且qsort函数的cmp函数就是判断元素的大小关系的,所以我们就可以展开构思: 注意,排序是将其进行升序处理
if (cmp(x, y > 0)
{
..............
}当cmp的返回值大于0是,就是x大于y,我们就要将x和y在数组中的位置进行调换,这个时候我们就可以写一个交换函数: 这里我们将其要比较的元素强制类型转换成为字符型,因为如果我们要比较的是字符型的话就可以直接比较,而且当要比较整形的时候也不影响,因为我们是一个字节一个字节的比较,所以引入了元素字节的大小size
void swap(char* buf1, char* buf2, int size)
{
int i = 0;
for (i = 0; i < size; i++)
{
char temp = *buf1;
*buf1 = *buf2;
*buf2 = temp;
buf1++;
buf2++;
}
}我们将其放入:
if (cmp((char*)arr + j * size, (char*)arr + (j + 1) * size) > 0)
//我们将j*size+上arr的地址就是第j个元素的的地址,即下标为j的元素的地址
{
swap((char*)arr + j * size, (char*)arr + (j + 1) * size, size);
}然后我们开始写cmp函数 我们回想qsort函数的定义,里面的cmp函数的定义就可以很容易的构造出这个函数:

如果是整形就是如下代码
int cmp_int(const void* x, const void* y)
{
return *((int*)x) - *((int*)y);
}同理我们可以利用strcmp函数得出字符型的cmp函数: 我们用网站查一查
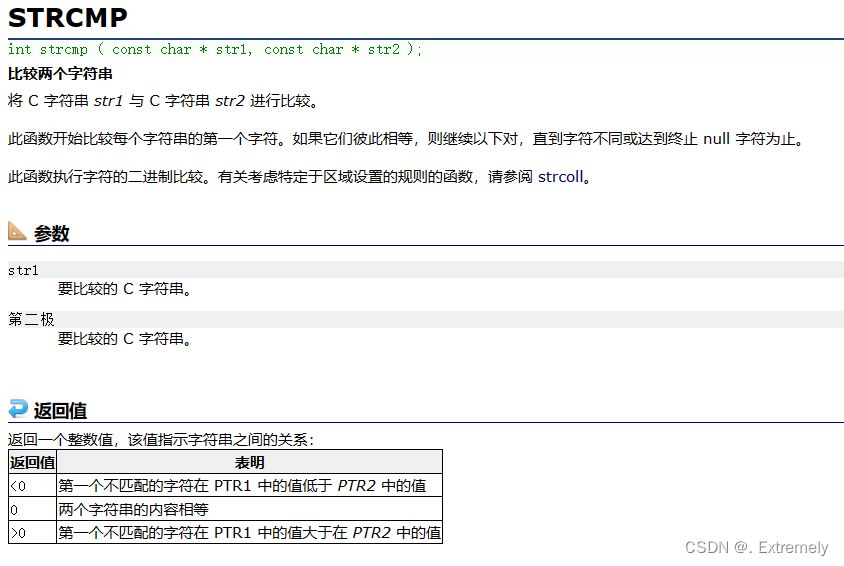
写出这个cmp_char
int cmp_char(const void* x, const void* y)
{
return strcmp((char*)x, (char*)y);
}整体代码如下:
void swap(char* buf1, char* buf2, int size)
{
int i = 0;
for (i = 0; i < size; i++)
{
char temp = *buf1;
*buf1 = *buf2;
*buf2 = temp;
buf1++;
buf2++;
}
}
int cmp_int(const void* x, const void* y)
{
return *((int*)x) - *((int*)y);
}
int cmp_char(const void* x, const void* y)
{
return strcmp((char*)x, (char*)y);
}
void bubble_sqort(void* arr, int sz, int size, int(*cmp)(const void*, const void*))
{
int i = 0;
int j = 0;
int* tmp = (int*)arr;
for (i = 0; i < sz; i++)
{
for (j = 0; j < sz - 1 - i; j++)
{
if (cmp_int((char*)arr + j * size, (char*)arr + (j + 1) * size) > 0)
{
swap((char*)arr + j * size, (char*)arr + (j + 1) * size, size);
}
}
}
}针对于具体的情况,我写了一个针对于结构体的的具体题目,大家可以试着参考:
struct stu { char name[20]; int age; }; void swap(char* buf1, char* buf2, int size) { int i = 0; for (i = 0; i < size; i++) { char temp = *buf1; *buf1 = *buf2; *buf2 = temp; buf1++; buf2++; } } int cmp_int(const void* x, const void* y) { return *((int*)x) - *((int*)y); } void bubble_sqort(void* arr, int sz, int size, int(*cmp)(const void*, const void*)) { int i = 0; int j = 0; int* tmp = (int*)arr; for (i = 0; i < sz; i++) { for (j = 0; j < sz - 1 - i; j++) {if (cmp((char*)arr + j * size, (char*)arr + (j + 1) * size) > 0) { swap((char*)arr + j * size, (char*)arr + (j + 1) * size, size); } } }
}
int cmp_stu_by_age(const void* x, const void* y)
{
return (((struct stu*)x)->age - ((struct stu*)y)->age);
}
int cmp_stu_by_name(const void* x, const void* y)
{
return strcmp(((struct stu*)x)->name, ((struct stu*)y)->name);
}
void test1()
{
int arr[] = { 2,4,11,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sqort(arr, sz, sizeof(arr[0]), cmp_int);
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
void test2()
{
struct stu arr[] = { {"zhangsan",20},{"lisi",30},{"wangwu",50} };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sqort(arr, sz, sizeof(arr[0]), cmp_stu_by_age);
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i].age);
}
}
void test3()
{
struct stu arr[3] = { {"zhangsan",20},{"lisi",30},{"wangwu",50} };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sqort(arr, sz, sizeof(arr[0]), cmp_stu_by_name);
for (int i = 0; i < sz; i++)
{
printf("%s ", arr[i].name);
}
}
int main()
{
//test1();
test3();
return 0;
}
好了,今天的分享就到这了,谢谢大家的支持!