大家好,这是专栏《计算摄影》的第四篇文章,这一个专栏来自于计算机科学与摄影艺术的交叉学科。今天我们讨论的问题是如何学会做图像增强。
作者&编辑 | 言有三
1 图像美学增强基础
1.1 什么是美学增强
一幅图像要有更好的美感,最基本的要求就是对比度分布合理,饱和度以及色调符合图像主题,本次我们从图像对比度增强和色调增强两个方面来谈论自动地美学增强问题。
图像对比度增强,即增强图像中的有用信息,抑制无用信息,从而改善图像的视觉效果。图像色调增强,即改善图像的色调效果,创造色彩更加丰富以及突出主题的效果。
摄影师,尤其是专业摄影师,基本上都会对拍摄的作品进行后期的图像增强操作,包含亮度、清晰度、饱和度、对比度、色调甚至是内容的调整操作。
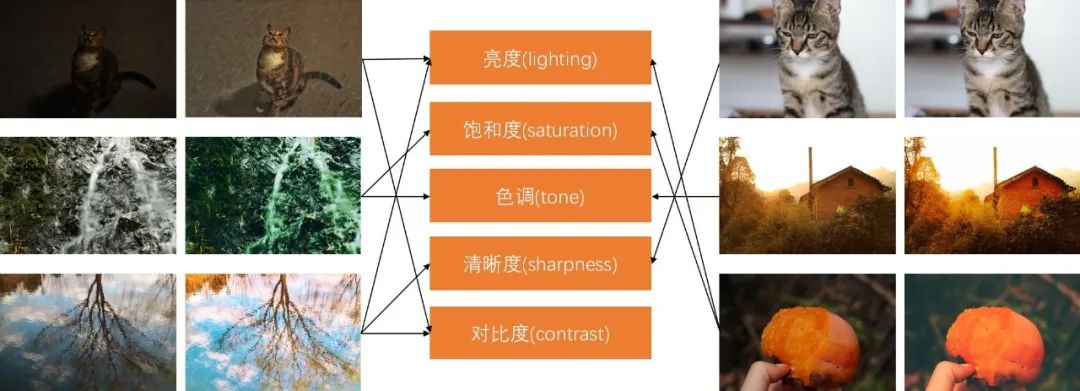
上图中展示了 6 组对比图,其中每组的左面是原图,右面是经过图像增强的图,可以看出明显增加了图像的美感。
1.2 美学增强常见数据集
为了研究自动图像增强问题,需要建立相关的数据集,目前有的数据集通过在同样的场景下采用不同的参数配置进行拍摄,适合于静态场景。有的则采用了不同的设备在同一个时间进行拍摄,需要进行视角的匹配,下面我们对其中使用较多的两个数据集进行介绍。
(1) MIT-Adobe FiveK 数据集[1]
这个数据集发布于 2011 年,包含 5000 张单反相机拍摄的 RAW 格式的照片,每一张照片都被 5 个经验丰富的摄影师使用Adobe Lightroom工具进行后期调整,调整内容主要是针对色调。因为该数据集包含了原图和 5 张后期图的成对数据,而且有同一个摄影师的多种后期修图图片,因此它可以被用于某一后期风格的学习。

(2) DPED 数据集[2]
这个数据集发布于 2018 年,采用了 3 个不同的手机和一个数码相机进行拍摄然后进行图片匹配和裁剪。三个手机分别是iPhone 3GS、BlackBerry Passport和Sony Xperia Z,相机则是 Canon 70D DSLR。该数据集覆盖了白天的各种常见光照和天气情况,采集时间持续3 周,都使用了自动拍摄模式。

因为 4 个设备同时进行图像采集,所拍摄出来的图前期不可能完全对齐,因此需要进行后处理对齐,作者们使用了 SIFT 算法对图像进行对齐,最终成对图之间保证不超过 5 个像素的偏差。
除了上述 2 个数据集,很多研究者在提出算法时都会自己采集相关的数据集,大家可以自己关注相关研究。
2 基于深度学习的图像增强
传统的对比度等增强方法包括伽马变换,直方图均衡,Retinex模型等,对参数敏感,而深度学习模型则可以从数据中进行学习,下面我们简单说说其中的核心算法,可以从两个方向来说。
2.1 端到端预测模型
卷积神经网络模型拥有强大的表达能力,被证明可以直接学会图像里的很多全局和局部的操作,包括图像风格迁移、去雾、上色、增加细节等,因此我们可以按照需要学习的类型,准备好相关的成对数据进行学习,这一类就是端到端的预测模型。

Chen Qifeng 等人[3]使用了一个基本的场景聚合模型来验证上述操作的学习,网络结构示意图就是常见Concext Aggregation Network,简称 CAN),它最初来自于语义分割任务,使用了不同大小的带孔卷积来实现同样大小的卷积核与不同的感受野。

作者们实验了十个常用的图像增强操作。
(1) Rudin-Osher-Fatemi:一种图像复原模型。
(2) TV-L1 image restoration:一种图像复原模型。 (3) L0 smoothing:一种图像平滑模型。 (4) relative total variation:一种通过剥离细节来提取图像结构的操作。
(5) image enhancement by multiscale tone manipulation:一种多尺度进行图像增强。
(6) multiscale detail manipulation based on local Laplacian filtering:基于拉普拉斯的图像编辑操作。
(7) photographic style transfer from a reference image:图像风格迁移操作。
(8) dark-channel dehazing :暗通道去雾操作。 (9) nonlocal dehazing :非局部去雾操作。 (10) pencil drawing :铅笔画风格操作。
所有任务使用的训练数据集都是Adobe MIT 5k,作者们首先用各类方法的官方实现对输入图进行操作,得到成对的训练数据,然后进行有监督的训练。
对于这一类模型,可以从几个方向进行改进,包括:
(1) 使用美学评估模型[4]进行反馈,以改进效果。

(2) 使用 GAN 模型[2]对生成结果的高层感知进行改进。

2.2 基于参数预测的方法
逐像素的回归模型原理简单,但是端到端的方法可解释性不强,容易过拟合,图像增强可以对应到相机中的曝光调整,对比度调整,色调调整等操作,因此研究者们提出了使用深度学习模型直接学习这几种操作的参数幅度,一个代表性的研究如下[5]。

可以看出整个增强过程被分解为一系列的操作,包括曝光度,对比度、色度、伽马校正等调整,因此模型需要搜索一系列的操作对输入图进行调整,每个操作过程对应于强化学习里的一个决策过程,通过对这些决策过程的结果进行惩罚就可以实现训练,其奖励回报就是美学分数。每一步调整的结果可以通过梯度的回传给整个网络学习,从而改变每一步的调整参数。
具体学习过程包含两个策略网络(policy network),一个判别模型,一个价值网络。其中两个策略网络分别将图像映射成某一类操作的概率和幅度,这四个网络都使用了同样的结构,输入图像大小为 64×64,包含四个卷积层和一个全连接层。
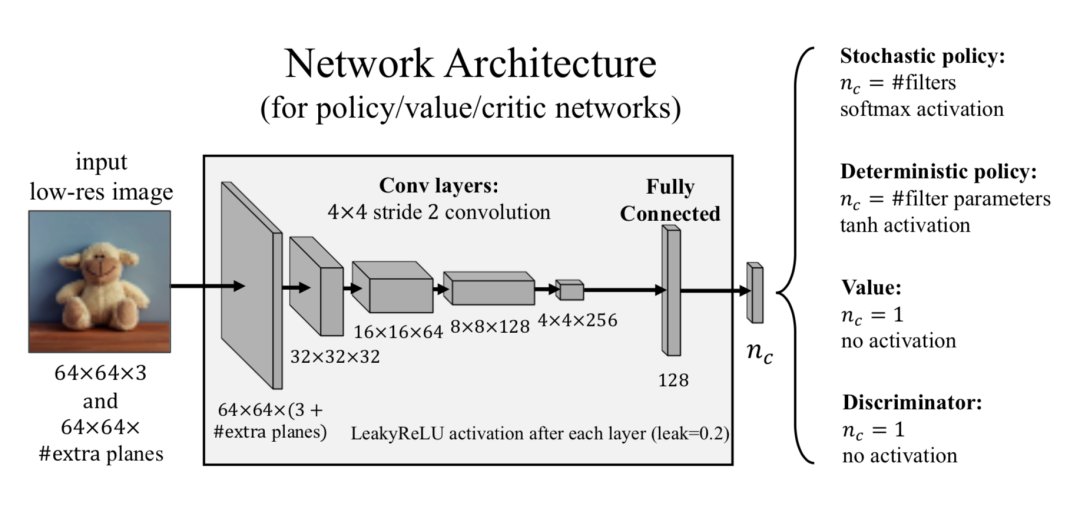
总的来说,该相机参数学习模型有以下三个优点。
(1) 首先这是一个端到端的学习各类变换操作幅度的方法,可以处理任意大小的图片。
(2) 使用了强化学习来给出每一步调色所做的操作,这样对图像的处理就不再是一个黑箱,从而方便人们对模型处理过程的理解,还可以参照模型的处理步骤和参数进行后期操作的学习。
(3) 不需要成对的图像数据来指导模型的学习,因为学习的都是成熟的图像处理操作的幅度,所以基本上不会产生非自然的瑕疵。
另外,还可以直接学习一个综合性质的滤波操作,如深度双边滤波模型[6]。
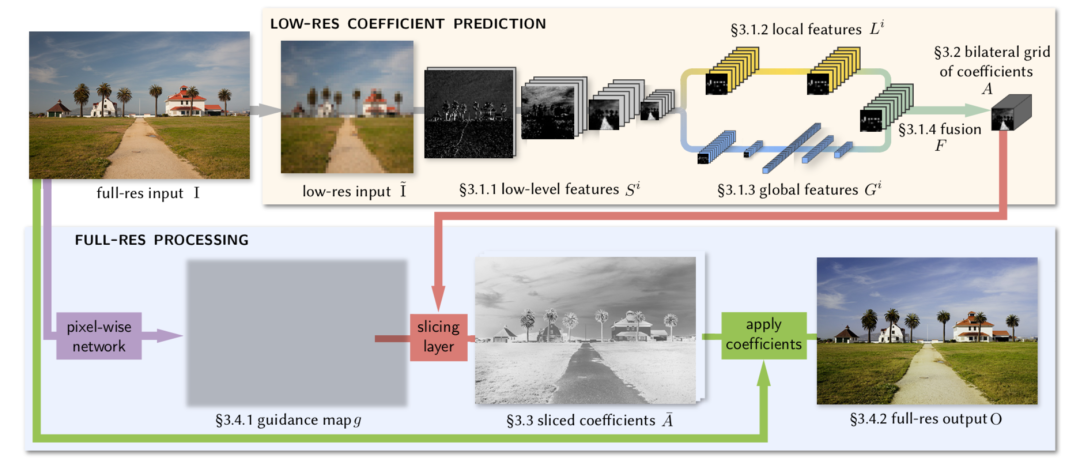
基于参数学习的模型主要问题是计算效率太低,模型训练过程复杂。
[1] Bychkovsky V, Paris S, Chan E, et al. Learning photographic global tonal adjustment with a database of input/output image pairs[C]//CVPR 2011. IEEE, 2011: 97-104.
[2] Ignatov A, Kobyshev N, Timofte R, et al. DSLR-quality photos on mobile devices with deep convolutional networks[C]//Proceedings of the IEEE International Conference on DSLR-quality photos on mobileComputer Vision. 2017: 3277-3285.
[3] Chen Q, Xu J, Koltun V. Fast image processing with fully-convolutional networks[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 2497-2506.
[4] Talebi H, Milanfar P. Learned perceptual image enhancement[C]//2018 IEEE International Conference on Computational Photography (ICCP). IEEE, 2018: 1-13.
[5] Hu Y, He H, Xu C, et al. Exposure: A white-box photo post-processing framework[J]. ACM Transactions on Graphics (TOG), 2018, 37(2): 26.
[6] Gharbi M, Chen J, Barron J T, et al. Deep bilateral learning for real-timeimage enhancement[J]. ACM Transactions on Graphics (TOG), 2017, 36(4): 118.
总结
与美学评估问题相似,图像增强是一个比较主观的问题,没有一对一的标准答案,甚至因为人群的审美而产生非常大的差异,这是一个目前还没有取得非常好的工业级应用的领域。
有三AI秋季划-图像质量图

图像质量小组需要掌握与图像质量相关的内容,学习的东西包括8大方向:图像质量评价,图像构图分析,图像降噪,图像对比度增强,图像去模糊与超分辨,图像风格化,图像深度估计,图像修复。了解详细请阅读以下文章:
【杂谈】如何让2020年秋招CV项目能力更加硬核,可深入学习有三秋季划4大领域32个方向
转载文章请后台联系
侵权必究