作者:曾祥极
编辑:H4O
人工智能之父马文·明斯基曾提到过,「如果机器不能够很好地模拟情感,那么人们可能永远也不会觉得机器具有智能」。
在人们的认知中,机器与人的分界线是机器是否具有情感。举个例子,如果一对情侣吵架,而有一方显得过于冷漠,那么另一方很有可能向对方说出类似于「你是一个没有情感的机器」的话。因此,机器是否具有情感是机器人性化程度高低的关键因素之一。
早在 1997 年,MIT 媒体实验室就提出了情感计算(Affective Computing)的概念,情感计算旨在通过赋予计算机识别、理解和表达人的情感的能力,使得计算机具有更高的智能。
情感智能是让机器更加智能的关键,具有情感的机器不仅更通用,更强大,更有效,而且与人类的价值观相一致。人类的情感机制也使我们能够完成太难编程或难以让当前机器学习的任务 [1]。
例如,我们的恐惧情绪使我们能够意识到危险并保持安全。我们感知他人的情感并站在对方的角度思考问题使我们在复杂的世界中可以做出恰当的决策。饥饿、好奇心、惊喜和喜悦等情感使我们能够规范自己的行为,并让我们追求我们希望实现的目标。除此之外,我们通过情感表达自己内部状态的能力是向他人沟通并可能影响他人决策的绝佳方式。
情感计算主要有「识别」,「表达」和「决策」这三个研究方向,「识别」主要是研究如何让机器准确识人类的情感,并消除不确定性和歧义性。「表达」主要是研究如何把情感以合适的信息载体表示出来,如语言、声音、姿态和表情等。而「决策」则主要研究如何利用情感机制来进行更好地决策。
由于情感识别和表达都是研究历史较长的领域,因此本文主要介绍情感识别和表达的相关概念,以及利用情感进行决策的最新进展。
1. 识别和表达
1.1. 识别
情感识别是一个历史比较悠久的研究领域,最早可以追溯到上个世纪就有学者从各个角度研究情感识别,比如语音、语言、表情和姿态等。它旨在从不同的维度精确捕捉人类的情感表达,主要有两种描述模型可以对情感空间进行描述,一种是离散情感空间,一种是维度情感空间。

图 1-1 Ekman 基本情感 [3]
离散情感空间把每一种情感分为一个个独立的标签,相互之间没有关联性,如喜悦、难过、恐惧等情感。这种描述方式更符合人的认知与日常生活的表达形式,具有天然的可解释性。但是缺点在于不同的情感标签之间没有类似于数值向量的连续性,于是不同标签之间的差异和联系性就无法更好地计算。
此外,由于在学术界尚未存在对情感的统一认识,这导致了目前存在着各种不同版本的情感分类标签。其中最为出名的当属于美国心理学家 Ekman 提出的六大基本情感。如图 1-1 所示,Ekman 列举了六种基本的情感,依次是生气、快乐、惊讶、厌恶、伤心和害怕。
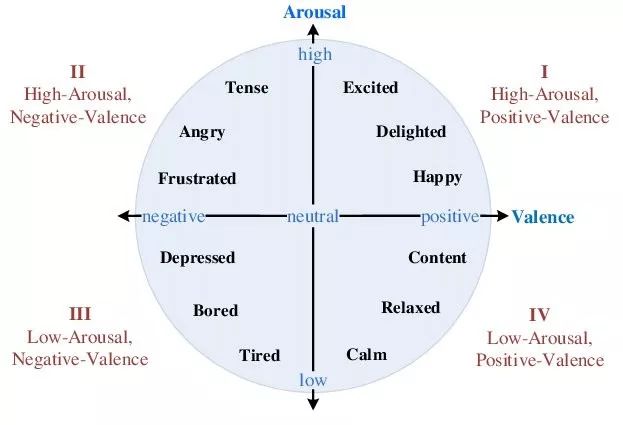
图 1-2 Valence-Arousal 模型 [9]
维度情感空间把不同的情感利用连续的多维向量表示,也称作维度理论。在维度情感空间中,每一个点都表示一种情感,具有数值向量的连续性,可以方便地计算不同情感之间的差异和联系,但是对于人来说,不具备很强的直观可解释性。
比较著名的维度情感模型是 Hanjalic 提出的激活度-效价(Valence-Arousal)空间理论,如图 1-2 所示。激活度-效价理论把情感分为激活度和效价两个维度,不同的激活度和效价表示不同的情感,激活度和效价越高则代表情感越积极,反之则越消极。
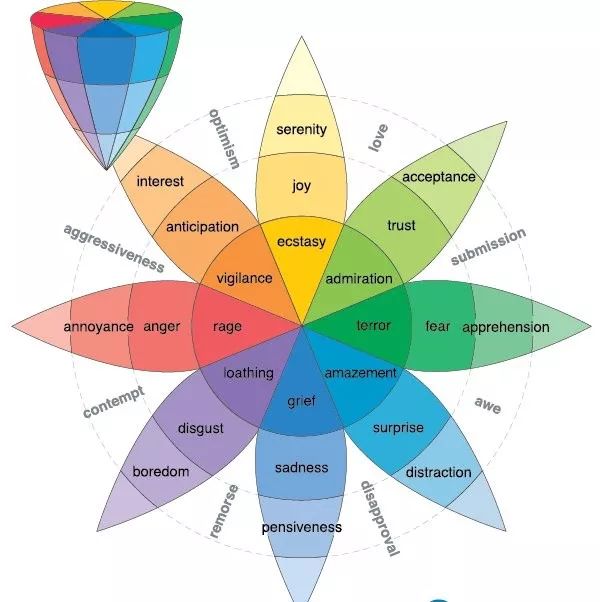
图 1-3 Plutchik 情感轮 [11][12]
另一个著名的维度情感模型是 Plutchik 提出的 Plutchik 情感轮模型,如图 1-3 所示。该模型把情感分为八种主要的情绪,位于圆圈的第二层,分别是喜悦、信任、恐惧、惊喜、伤心、厌恶、生气和期望,其它所有复杂的情绪都是由这八种情绪组合而成的。越靠近圆圈里面,情绪越强烈,颜色也会增强。移动到外层,颜色变得不那么饱和,情绪的强度降低。
情感识别技术在许多领域都有比较好的应用,比如在教育领域,教师利用情感识别技术来帮助孤独症患者或者抑郁症患者建立一个健康的身心,并提高学习能力。
情感识别在商业领域也有很大的用处,例如商业公司利用情感识别算法观察消费者在观看广告时的表情,这可以帮助商家预测产品销量的上升、下降或者是保持原状,从而为下一步产品的开发做好准备。
1.2. 表达
人在与机器进行交互的时候,如果机器不能够对人的情感进行合理的反馈,即机器能够表达自己的情感,那么可能在人类看来机器总是冷冰冰的,不那么智能。因此,在实现通用人工智能的过程中让机器能够合理的表达情感是一件非常重要的事情,情感表达旨在让机器从不同的维度表达特定的情感,比如通过语音、肢体和表情等。
语音是表达情感的主要方式之一,因为我们人类总是能够通过他人的语音轻易地判断他人的情感状态。语音的情感主要表现在两个部分,一个是语音中所包含的语言内容,另一个是声音本身所具有的特征,比如音调的高低变化等。我们可以利用特定的声音风格加上文字内容合成语音,便可以表达特定的情感,带有情感的语音可以让消费者在使用的时候感觉更人性化、更温暖。
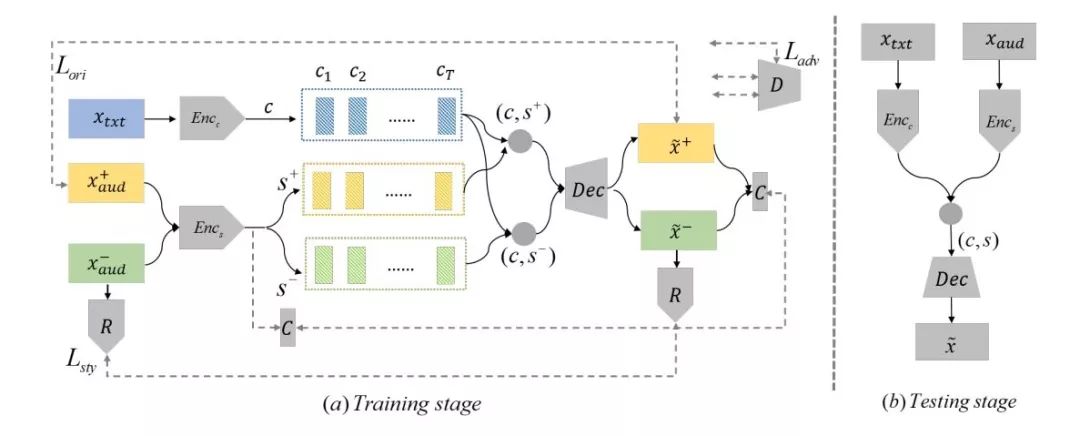
图 1-4 对抗和合作式语音合成 [6]
目前的语音合成通常都是通过将需要合成的文字内容和特定风格的语音输入到神经网络中,然后让神经网络合成特定风格的语音。然而,目前的神经网络无法高效地将语音内容和风格分解。如图 1-4 所示,微软的研究者在最近提出利用博弈论中对抗和合作的思想来生成特定风格的语音数据,这个模型能够有效地将语音内容和风格分解,从而使得在语音生成方面风格可控,该模型在风格迁移、情感建模等任务上均取得了不错的进展。生成样例可参考 [7]。
肢体语言主要是指通过头、眼、手和腿等人体部位的协调活动来表达人的想法。同样地,我们也可以让机器学会肢体语言来表达特定的情感。肢体情感表达主要是通过分析动作的基本单元,用运动单元之间的运动特征构造单元库,然后再根据不同情感表达的动作需要合成相应的交互动作,并让机器人执行相应的动作。

图 1-5 NAO 机器人 [8]
如图 1-5 所示,NAO 机器人是由 Aldebaran Robotics 公司推出的一款人形机器人,该机器人可以通过改变肢体的运动来表达不同的情感。它能模拟 1 岁小孩子的生气、恐惧、伤感、喜悦等情绪,比如,你使劲抱它,它会感到紧张。或者你长时间不理它,它会感到焦虑。这个机器人可以较好地帮助治疗自闭症患者。
面部表情是表现情感的一个重要途径,主要通过脸部、眼睛或者肌肉位置的变化来表达情感。不同国家的人面部表情各不相同,亚洲人民的面部表情的强度相对较低,因为在亚洲文化中,面部表现出一些特殊情绪是不礼貌的。

图 1-6 ExprGAN[10]
面部表情的生成是一项具有挑战性的任务,因为它需要对输入面部图像进行高级语义理解。在传统方法中,合成的面部分辨率通常很低。目前主要流行基于深度学习的方法进行面部表情图像生成,比如有研究利用生成对抗网络(GAN)进行带有指定情绪的面部表情生成,如图 1-6 所示,该模型可用于可控表情的面部表情生成,可以很好地表达不同的情感。
一个更为综合的情感表达的例子是对话系统,图灵在 1950 年就提出了著名的图灵测试,他认为如果一台机器能够与人类展开对话而不能被辨别出其机器身份,那么称这台机器具有智能。我们在文章的开头谈到,如果机器不具有情感表达,那么人们可能会认为机器一点都不够智能。

图 1-7 情感表达对话 [13]
因此在与机器进行对话时,机器能够识别和表达情感是一件非常重要的事情。来自哈佛和微软的研究者们就尝试着让对话机器人能够综合语言信息和视觉信息进行带有情感表达的对话,如图 1-7 所示,针对问题「Did you have a good time?」,对话机器在看到不同的视觉场景会有不同情感表达。左边的图像是一个抬头并带有笑脸的小男孩,因此机器会回复「We had a great time at the beach!」,而右边的图像却是一个低头的小女孩,因此机器会回复「She just hates going for a walk!」。
2. 决策
大量的研究表明,人在解决某些问题的时候,纯理性的决策过程并不是一个最优解,在决策的过程中,如果有生理反应(如情感)加入到决策过程中,这有可能帮助我们找到更优的解。如果我们将情感机制纳入到强化学习算法的设计当中,那么智能体(Agent)会发什么有趣的事情?
举个例子,我们人类在遇到不利于我们生存的情况下,我们的交感神经系统(Sympathetic Nervous System, SNS)会分泌一系列激素促使我们的心跳、血压以及肾上腺素升高,并导致我们产生恐惧的情绪,这种恐惧的情绪会加速我们对风险规避的学习。如果我们将这种恐惧情绪加入到强化学习的智能体并辅助智能体决策,智能体在探索效率上可能会发生一定的变化。
2.1. 算法
微软的研究者在这个问题上给出了自己的答案,他们提出了一种基于周围血管搏动测量(Peripheral Pulse Measurements)的内在奖励的强化学习新方法,这种内在奖励是与人类神经系统的响应相关的 [5]。作者的假设是这种奖励函数可以帮助强化学习解决稀疏性(sparse)和倾斜性(skewed),以此提高采样效率。
汽车驾驶是一个生活中很常见的任务,这既依赖于内部的奖励,也依赖于外表的奖励。当我们在高速驾驶汽车的时候,我们的神经系统是高度激活的,这有助于我们应对驾驶过程中出现的突发状况,比如需要紧急调整方向来防止撞到突然走向道路中间的行人以避免事故。因此,当遇到突发情况时,这种生理内部的反馈会有助于我们更好地评估当前的环境并帮助我们做出有利的决策。
作者在一个模拟的驾驶环境中进行了实验,实验表明这种奖励在学习阶段能够提高学习速度以及减少碰撞次数,即有效减少奖励信号的稀疏性。
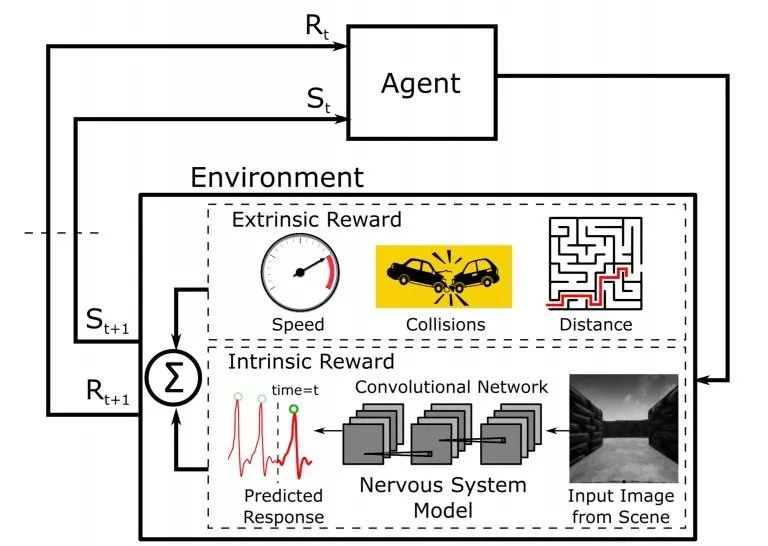
图 2-1 基于内在生理奖励的强化学习 [5]
如图 2-1 所示,与一般强化学习模型的不同之处在于,作者提出的强化学习模型的奖励主要分为两个部分,一个是外部环境的奖励(Extrinsic Reward),一个是由内部生理反应产生的内部奖励(Intrinsic Reward)。作者利用皮肤周围血管血液体积,即比如血容量脉搏波动(Blood Volume Pulse Wave),来模拟内部生理状态的反应。核心思想是如果人在遇到某种紧急的情况,那么人的紧张情绪就会通过生理反应表现出来,比如血容量脉搏波动变大。作者提出的模型设计了一个新的奖励函数,该奖励函数如下:

公式中前者 r 代表外部环境的奖励,而后者 r~(上波浪线)代表内部奖励,λ代表权重。
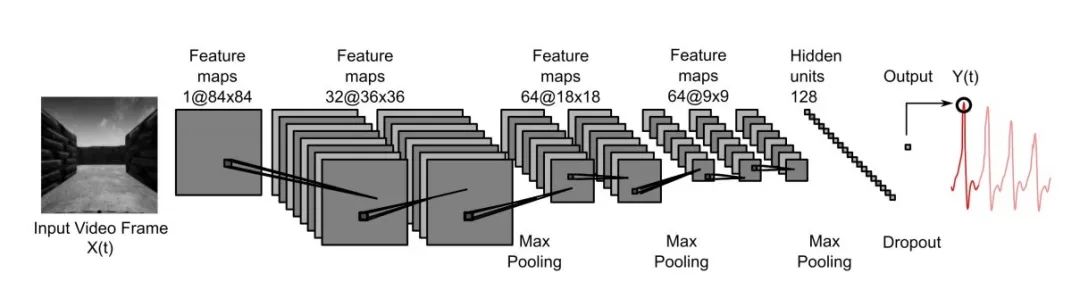
图 2-2 根据场景预测血容量脉冲波动的卷积神经网络模型 [5]
这种方法的关键问题之一就是如何确定在开车过程中哪种驾驶场景会导致驾驶者心理出现波动,比如心跳加快和血压升高。作者找了四个人来获取皮肤周围血液体积的变化,具体做法是让这四个人分别在这个模拟驾驶场景中进行驾驶,并记录每一帧图像(驾驶场景)的变化以及参与者本人对应的血容量脉冲波动数据。如图 2-2 所示,作者利用获取到的数据对一个八层的卷积神经网络进行训练,图像帧作为输入数据,血容量脉冲波动作为标签,值在 0 到 1 之间。训练好的模型便可用来预测特定驾驶场景的心理反应,这种心理反应就是我们前面提到的内部奖励。
2.2. 实验
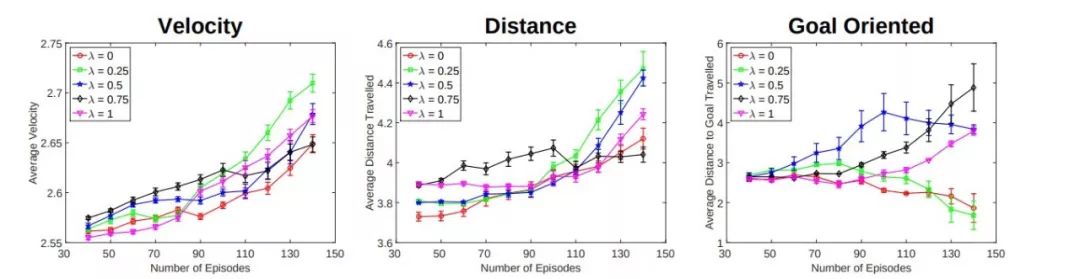
图 2-3 实验结果 1[5]
如图 2-3 所示,纵坐标代表不同的测试指标,如平均速度、平均距离和目标导向的平均距离,而横坐标则代表不同数目的模拟次数。其中λ是我们前面提到的奖励函数的权值,λ越大,则代表越依赖于外部奖励,当λ=1 时,则退化成传统的深度 Q 学习算法,当λ=0 时,则代表完全依赖于内部生理状态的奖励。从实验结果我们可以看到,λ处于中间值时,这既能改善学习速率,又能促使代理更好地采取与任务相关的特定行为。
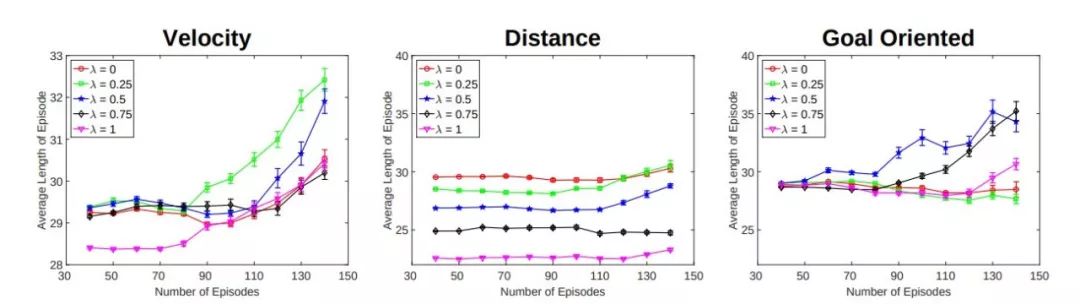
图 2-4 实验结果 2[5]
为了测试内部奖励能否帮助智能体减少碰撞,作者调查了在不同λ情况下,智能体在碰撞之前所经历的模拟次数(episodes)。如图 2-4 所示,我们可以看到当λ=1(完全依赖于外部奖励)时,在第一次碰撞之前的平均模拟次数几乎总是最低的,这说明内部奖励确实能够帮助智能体有效减少碰撞。
3. 总结
北宋著名词人柳永曾在蝶恋花中写道,「衣带渐宽终不悔,为伊消得人憔悴」,这描述了一种怀念意中人到极致而憔悴的状态。
喜悦、忧愁等情感塑造了我们人类自身,决定了我们自己是谁,并影响着我们的日常行为。情感涉及到了人类的认知,是人类智能最核心的部分,更好地了解情感将会更好地帮助我们设计出更强大的机器智能。
参考:
[1] https://www.microsoft.com/en-us/research/blog/toward-emotionally-intelligent-artificial-intelligence/
[2] https://book.yunzhan365.com/poui/pudn/mobile/index.html?from=timeline&isappinstalled=0
[3] https://managementmania.com/en/six-basic-emotions
[4] https://www.paulekman.com/wp-content/uploads/2013/07/Basic-Emotions.pdf
[5] https://www.microsoft.com/en-us/research/publication/visceral-machines-risk-aversion-in-reinforcement-learning-with-intrinsic-physiological-rewards/
[6] https://www.microsoft.com/en-us/research/publication/neural-tts-stylization-with-adversarial-and-collaborative-games/
[7] https://researchdemopage.wixsite.com/tts-gan
[8] https://robohub.org/nao-next-gen-now-available-for-the-consumer-market/
[9] https://www.researchgate.net/figure/Two-dimensional-valence-arousal-space_fig1_304124018
[10] https://arxiv.org/abs/1709.03842
[11] https://positivepsychology.com/emotion-wheel/
[12] https://www.6seconds.org/2017/04/27/plutchiks-model-of-emotions/
[13] https://www.microsoft.com/en-us/research/publication/emotional-dialogue-generation-using-image-grounded-language-models/
作者介绍:曾祥极是浙江大学计算机方向的硕士,主要研究常识(Commonsense)以及知识图谱(Knowledge Graph),同时也对认知科学和系统科学这两个学科很感兴趣,痴迷于智能是如何涌现。作为机器之心技术分析师的一员,我希望通过文字理清当前技术的发展前沿,与大家一同分享我的见解,也希望我们都能从中有所收获。