异动分析(四)利用Python计算指标贡献度
小P:有些异动的原因是多方面的,我看网上说可以通过计算贡献度进行量化。 小H:是的,容我想想~
虽然不是必要的,但有时候异动的原因多个,通过计算每个原因的贡献程度即可以很好的分清主次。这里主要根据博客如何快速量化增长指标的各因子贡献[1]进行python化计算,主要采取的是相对贡献,即在指定维度下,各细分维度的总贡献为100%。
⚠️注意:绝对贡献只需要去除共同的分母即可,读者可自行尝试~
指标拆解计算各子指标贡献
这里采用LMDI法,一种指数分解法,可以计算乘法公式中每个因子对整体变动的贡献度,将变动分解到因子
- 计算目标变量y的变化率:
- 计算目标变量y的变化对数:
- 计算各因子的权重:,其中i为第i个子指标
- 计算各因子贡献:
import pandas as pd
import numpy as np
import random
import itertools
from numpy.random import choice
from random import randint, random
# 构造数据
month=[5,6]
sales=[450, 686]
enter_uv=[60000, 65000]
click_rate=[0.1, 0.11]
paid_rate=[0.05, 0.06]
per_buy_cnt=[1.5, 1.6]
data=pd.DataFrame(data={
'month':month,
'sales':sales,
'enter_uv':enter_uv,
'click_rate':click_rate,
'paid_rate':paid_rate,
'per_buy_cnt':per_buy_cnt,
})
data

image-20230206151046535
def cal_metric_contribute(df, period, base_date, cont_date, X, y): ''' df:数据集,只包含两期数据 period:日期字段 base_date:基期时间 cont_date:对照期时间 X:指标列 y:结果列 ''' df=df.copy() # 构造基期与对照期数据集 df_base=df[df[period]==base_date] df_cont=df[df[period]==cont_date] # 计算y的变换率 y_change_rate=df_cont[y].values[0]/df_base[y].values[0]-1 # 计算y的自然对数差值 ln_y_change=np.log(df_cont[y].values[0]/df_base[y].values[0]) # 计算X的自然对数差值 ln_x_change=[] for j in X: ln_x_change.append(np.log(df_cont[j].values[0]/df_base[j].values[0])) # 计算X的自然对数差权重 ln_x_weight=ln_x_change/ln_y_change # 计算指标贡献度 x_contribute=ln_x_weight*y_change_rate # 导出df df_result=pd.DataFrame(x_contribute, index=X, columns=['contribute'])return df_result
period='month'
y='sales'
X=['enter_uv', 'click_rate', 'paid_rate', 'per_buy_cnt']
base_date=5
cont_date=6
cal_metric_contribute(data, period, base_date, cont_date, X, y).sort_values(by='contribute', ascending=False)
contribute | |
|---|---|
paid_rate | 0.226781 |
click_rate | 0.118552 |
enter_uv | 0.099561 |
per_buy_cnt | 0.080276 |
维度下钻衡量各维度权重
# 自定义随机权重,用于定性的控制转化率差异
def rand_weight(x):
wi=random()
lift=[i*0.05 for i in range(5,-5,-1)]
return wi+lift[x]
# 构造维度
ch=['A', 'B', 'C', 'D']
level=['l1', 'l2', 'l3']
gender=['F', 'M']
mon=['1月', '2月']构造基期数据
np.random.seed(4)
u1 = 1000
uc = choice(ch, size=u1, p=[0.6, 0.2, 0.15, 0.05])
ul = choice(level, size=u1, p=[0.7, 0.2, 0.1])
ug = choice(gender, size=u1, p=[0.6, 0.4])
s_rate1 = 0.4
s1 = np.random.binomial(1, s_rate1, u1)自定义权重
w11 = {
'A':3
,'B':1
,'C':2
,'D':3
}w12 = {
'l1':2
,'l2':4
,'l3':0
}w13 = {
'F':1
,'M':3
}df1 = pd.DataFrame(columns=['ch', 'level', 'gender'])
df1['ch'], df1['level'], df1['gender'] = uc, ul, ug
df1['w1'] = df1.apply(lambda x: rand_weight(w11[x['ch']])+
rand_weight(w12[x['level']])+rand_weight(w13[x['gender']])
, axis=1)
df1.sort_values(by="w1", ascending=False, inplace=True)
df1['if_pay'] = abs(np.sort(-s1))
df1_temp = df1.groupby(['ch', 'level', 'gender'])['if_pay'].agg(['count', 'sum']).reset_index()
df1_temp.columns = ['ch', 'level', 'gender', 'users', 'pays']
df1_temp['mon'] = '1月'构造对照期数据
np.random.seed(10)
u2 = 1100
uc = choice(ch, size=u2, p=[0.5, 0.25, 0.2, 0.05]) # 提高BC样本量
ul = choice(level, size=u2, p=[0.7, 0.2, 0.1])
ug = choice(gender, size=u2, p=[0.6, 0.4])
s_rate2 = 0.5
s2 = np.random.binomial(1, s_rate2, u2)自定义权重
w21 = {
'A':3
,'B':1
,'C':2
,'D':3
}提高L1、L2权重
w22 = {
'l1':1
,'l2':3
,'l3':0
}提高F权重
w23 = {
'F':0
,'M':3
}df2 = pd.DataFrame(columns=['ch', 'level', 'gender'])
df2['ch'], df2['level'], df2['gender'] = uc, ul, ug
df2['w2'] = df2.apply(lambda x: rand_weight(w21[x['ch']])+
rand_weight(w22[x['level']])+rand_weight(w23[x['gender']])
, axis=1)
df2.sort_values(by="w2", ascending=False, inplace=True)
df2['if_pay'] = abs(np.sort(-s2))
df2_temp = df2.groupby(['ch', 'level', 'gender'])['if_pay'].agg(['count', 'sum']).reset_index()
df2_temp.columns = ['ch', 'level', 'gender', 'users', 'pays']
df2_temp['mon'] = '2月'拼接数据
df_result = pd.concat([df1_temp, df2_temp])
衡量两样本的维度差异有很多方法,例如KS检验、相对熵,但大多数的目标变量是连续值。由于只是简单的考虑各维度变化的波动大小,所以这里采用计算变化值的方差衡量波动浮动。
def cal_s2(df, period, base_date, cont_date, X, y0, y1=None, calRate=None):
'''
df:数据集,只包含两期数据
period:日期字段
base_date:基期时间
cont_date:对照期时间
X:维度列
y0:指标列-分子
y1:指标列-分母
'''
df=df.copy()
# 构造基期与对照期数据集
df_base=df[df[period]==base_date]
df_cont=df[df[period]==cont_date]# 计算波动值的方差 s2=[] for j in X: if calRate: df_change=(df_cont.groupby(j)[y0].sum()/df_cont.groupby(j)[y1].sum() )-(df_base.groupby(j)[y0].sum()/df_base.groupby(j)[y1].sum()) else: df_change=df_cont.groupby(j)[y0].sum()-df_base.groupby(j)[y0].sum() s2.append(np.var(df_change)) # 导出df df_result=pd.DataFrame(s2, index=X, columns=['s2']).sort_values(by='s2', ascending=False) return df_result
period='mon'
base_date='1月'
cont_date='2月'
X=['ch', 'level', 'gender']
y0='pays'
y1='users'计算各维度销售额方差
print(cal_s2(df_result, period, base_date, cont_date, X, y0=y1))
计算各维度购买率方差
print(cal_s2(df_result, period, base_date, cont_date, X, y0, y1, calRate=1))
s2
gender 2704.000000
ch 1762.500000
level 574.888889
s2
ch 0.003322
gender 0.002216
level 0.001378
绝对值指标贡献度计算
- 计算目标变量y的变化
- 计算维度各取值的变化 ,其中i表示第i个维度,j表示该维度下的第j个取值
- 计算贡献度
def cal_abs_contribute(df, period, base_date, cont_date, X, y):
'''
df:数据集,只包含两期数据
period:日期字段
base_date:基期时间
cont_date:对照期时间
X:维度列
y:指标列
'''
df=df.copy()
# 构造基期与对照期数据集
df_base=df[df[period]==base_date]
df_cont=df[df[period]==cont_date]
# 计算整体变化
all_change=df_cont[y].sum()-df_base[y].sum()
# 计算所有组合的贡献度
df_contribute=pd.DataFrame(columns=['contribute', 'dim_value', 'dim_name',
'dim', 'base', 'change', 'all_base', 'all_change'])
for i in range(len(X)):
comb=itertools.combinations(X, i+1)
for j in comb:
# 计算贡献值
dc=df_cont.groupby(list(j))[y].sum()-df_base.groupby(list(j))[y].sum()
# 计算贡献百分比
dr=dc/all_change
df_temp=pd.DataFrame(dr).reset_index(drop=True)
df_temp['dim_value'] = dr.index
df_temp['dim_name']=str(dr.index.names)
df_temp['dim']=i+1
df_temp['base']=df_base.groupby(list(j))[y].sum().values
df_temp['change']=dc.values
df_temp['all_base']=df_base[y].sum()
df_temp['all_change']=all_change
df_temp.columns=['contribute', 'dim_value', 'dim_name',
'dim', 'base', 'change', 'all_base', 'all_change']
df_contribute=df_contribute.append(df_temp)
df_result=df_contribute[['dim', 'dim_name', 'dim_value', 'base', 'all_base',
'change', 'all_change', 'contribute']]
return df_result
period='mon'
base_date='1月'
cont_date='2月'
X=['ch', 'level', 'gender']
y='pays'
cal_abs_contribute(df_result, period, base_date, cont_date, X, y).sort_values(by='contribute', ascending=False).head()
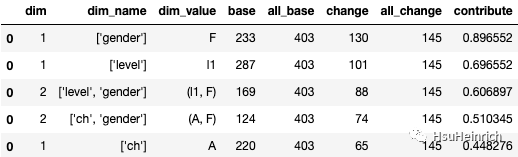
image-20230206151015949
比率值指标贡献度计算
分别计算分母占比变化的贡献和指标变化的贡献,具体见下面的代码(这个公式写起来有点繁琐...)。
def cal_rate_contribute(df, period, base_date, cont_date, X, y0, y1):
'''
df:数据集,只包含两期数据
period:日期字段
base_date:基期时间
cont_date:对照期时间
X:维度列
y0:指标列-分子
y1:指标列-分母
'''
df=df.copy()
# 构造基期与对照期数据集
df_base=df[df[period]==base_date]
df_cont=df[df[period]==cont_date]
# 计算指标基期、本期整体数据
all_base=df_base[y0].sum()/df_base[y1].sum()
all_cont=df_cont[y0].sum()/df_cont[y1].sum()
# 计算整体变化
all_change=all_cont-all_base# 计算所有组合的贡献度 df_contribute=pd.DataFrame(columns=['contribute', 'dim_value', 'dim_name', 'dim', 'metric_base', 'rate_base', 'all_base', 'metric_change', 'rate_change', 'all_change', 'metric_contribute', 'rate_contribute']) for i in range(len(X)): comb=itertools.combinations(X, i+1) for j in comb: # 1、计算占比变化 # 计算分母基期、本期数量 df_y1_base=df_base.groupby(list(j))[y1].sum() df_y1_cont=df_cont.groupby(list(j))[y1].sum() # 计算分母基期、本期占比 df_rate_base=df_y1_base/df_base[y1].sum() df_rate_cont=df_y1_cont/df_cont[y1].sum() # 计算占比变化 df_rate_change=df_rate_cont-df_rate_base # 2、计算指标变化 # 计算指标基期、本期数值 df_metric_base=df_base.groupby(list(j))[y0].sum()/df_base.groupby(list(j))[y1].sum() df_metric_cont=df_cont.groupby(list(j))[y0].sum()/df_cont.groupby(list(j))[y1].sum() # 计算指标变化 df_metric_change=df_metric_cont-df_metric_base # 计算指标变化贡献 df_metric_contribute=df_metric_change*df_rate_base # 计算占比变化贡献 df_rate_contribute=df_rate_change*(df_metric_cont-all_base) # 计算整体贡献值 dc=(df_metric_contribute+df_rate_contribute) # 计算整体贡献百分比 dr=dc/all_change df_temp=pd.DataFrame(dr).reset_index(drop=True) df_temp['dim_value'] = dr.index df_temp['dim_name']=str(dr.index.names) df_temp['dim']=i+1 df_temp['metric_base']=df_metric_base.values df_temp['rate_base']=df_rate_base.values df_temp['all_base']=all_base df_temp['metric_change']=df_metric_change.values df_temp['rate_change']=df_rate_change.values df_temp['all_change']=all_change df_temp['metric_contribute']=df_metric_contribute.values df_temp['rate_contribute']=df_rate_contribute.values df_temp.columns=['contribute', 'dim_value', 'dim_name', 'dim', 'metric_base', 'rate_base', 'all_base', 'metric_change', 'rate_change', 'all_change', 'metric_contribute', 'rate_contribute'] df_contribute=df_contribute.append(df_temp) df_result=df_contribute[['dim', 'dim_name', 'dim_value', 'metric_base', 'rate_base', 'all_base', 'metric_change', 'rate_change', 'all_change', 'metric_contribute', 'rate_contribute', 'contribute']] return df_result
period='mon'
base_date='1月'
cont_date='2月'
X=['ch', 'level', 'gender']
y0='pays'
y1='users'
cal_rate_contribute(df_result, period, base_date,
cont_date, X, y0, y1).sort_values(by='contribute', ascending=False).head()

image-20230206150947751
参考资料
[1]
如何快速量化增长指标的各因子贡献: https://zhuanlan.zhihu.com/p/455696026