作者:张小磊,文章转自机器学习与推荐算法
推荐系统,对于我们来说并不陌生,它已经无时无刻不方便着我们的生活、学习、工作等方方面面,并且已经成为许多社交/购物/新闻平台中必不可少的组件。近些年来学术界以及工业界的研究者们已经对其进行了大量研究并提出了许多经典有效的推荐模型,比如UserCF、ItemCF、MF、FM、BPR、Item2vec、NCF、DIN等等。
另外,根据推荐场景的具体情况,分为了基于显式反馈数据的评分预测任务以及基于隐式反馈数据的个性化排序任务、下一个项目推荐任务以及会话推荐任务等。并且基于现实世界中出现的场景与问题,提出了一系列的子研究方向,比如冷启动推荐、可解释性推荐、跨域推荐、序列推荐、社交推荐等。
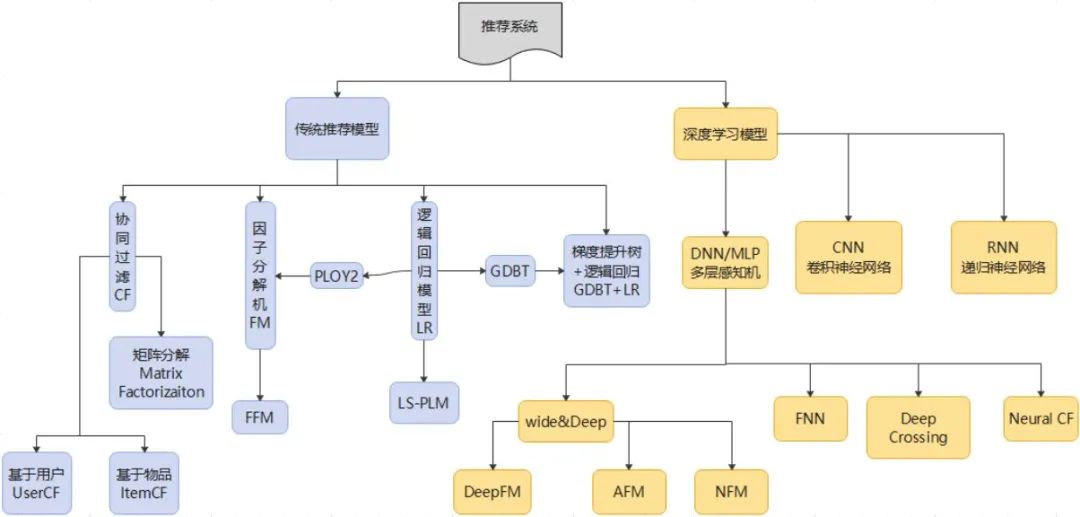
推荐算法部分模型分类,借鉴于[1]
然而,上述场景需要收集大量的用户行为记录以及用户私有属性信息,虽然使得模型能够掌握用户的行为模式,但也不可避免的造成了用户敏感信息以及隐私问题的担忧。随着近年来大数据技术的发展以及用户终端的普及,对于用户数据的收集越来越简单,以及收集的用户数据数量与日俱增,因此用户对于隐私问题的担忧越来越大。
并且最近国家互联网信息办公室开始公开征求《互联网信息服务算法推荐管理规定》的征求意见,都说明了大家对于数据隐私与安全的重视程度,因此如何在为用户提供高效的推荐服务的同时,能够为用户的数据以及隐私提供安全的保障成为了近年来的研究热点。
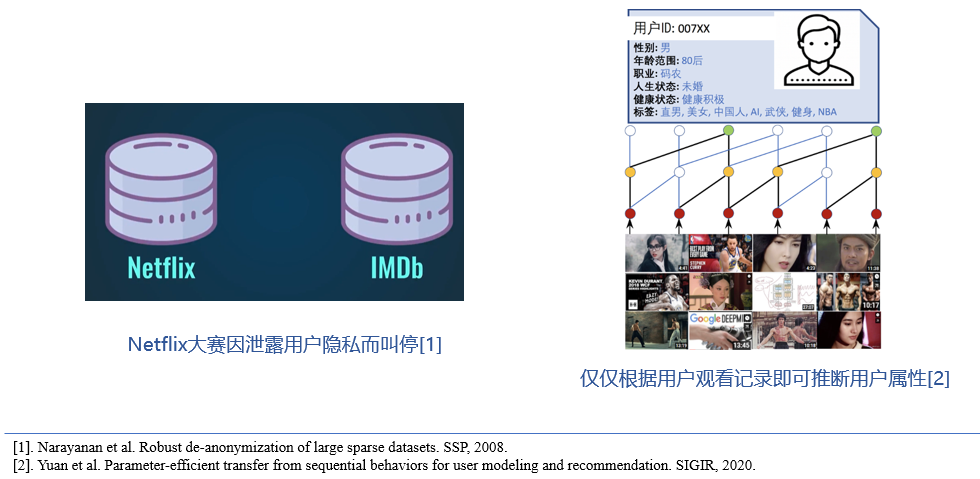
其实,对于推荐算法关于隐私和安全问题的研究早已开始。早在推荐算法被提出来的初期,就一直有关于基于隐私保护的推荐系统的研究。比如,正如我们所熟知的Netflix大赛把研究人员关于推荐系统的研究热情带到了高点,但后来却因开放出来的数据集导致用户隐私泄露而叫停。
而攻击的方法也很简单,文献[Arvind et al. 2008]通过将释放出的Netflix数据集与IMDb数据集进行关联就挖掘出了一部分用户的敏感信息。因此后续对于数据的隐私保护方法在推荐中进行了大量尝试,比如匿名化、差分隐私、本地化的差分隐私、同态加密算法、安全多方计算等与推荐方法的结合;以及机器学习思想在推荐中的尝试,比如对抗机器学习、对抗样本生成等,都在一定程度上保护了用户的隐私和安全。
然而,上述保护隐私的场景都是考虑在集中收集用户的个人数据并且上传到受信的中心服务器来进行存储与训练模型的方式进行的。显然,这样的模式会在个人数据传输过程中以及在服务器存储环节中出现隐私泄露以及安全问题。因此基于联邦学习范式的推荐算法登上了历史舞台。
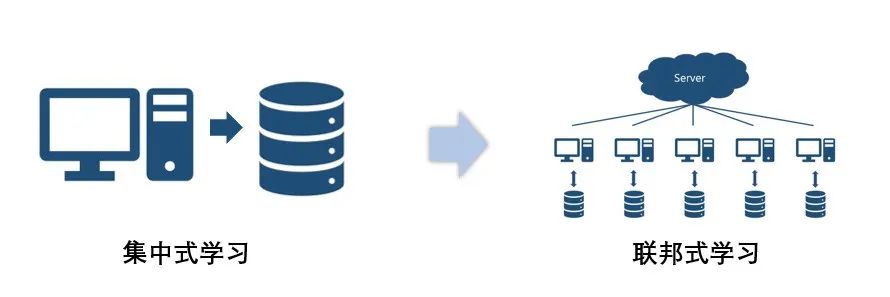
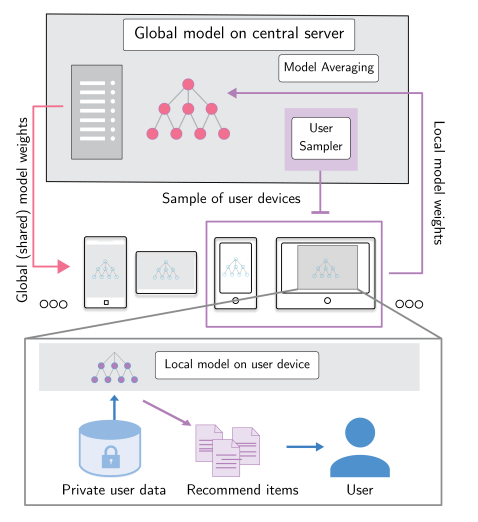
联邦学习,即通过将用户数据保存在本地,然后利用本地数据训练本地模型,然后在服务端协同多个本地模型进行优化,进而聚合多个本地模型的中间参数来得到服务端全局较优的模型,最终下发到每个终端设备上。因此联邦学习实现了模型出域,用户的本地数据不出域的目的,最终达到保护用户原始数据以及隐私的需求。早期比较经典的联邦学习算法为FedAvg,其根据联邦学习的训练过程,大致分为4个部分,即:
- 本地数据收集与模型初始化;
- 本地模型训练并上传参数;
- 服务器聚合本地参数进行全局更新;
- 更新本地模型。
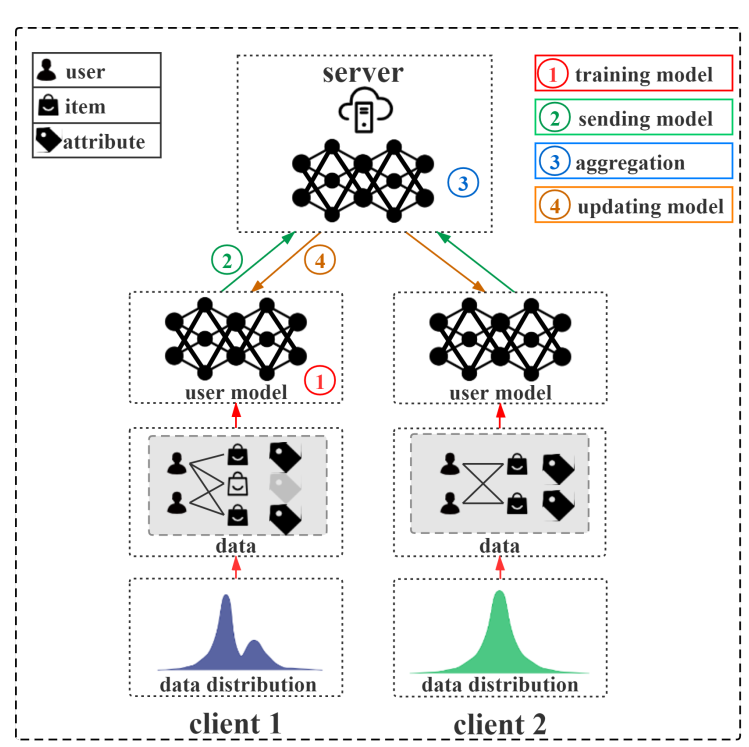
当然,根据用户的重叠程度、特征的重叠程度等,可以细分为横向联邦学习、纵向联邦学习、迁移联邦学习等(本文中大部分的介绍是基于横向的联邦学习)。根据以上步骤,研究者针对其中涉及到的每个部分进行了更进一步的研究,比如:
- 如何更好的研究符合实际场景的本地数据(Non-IID数据);
- 如何挑选有代表性的本地模型参与训练;
- 如何在服务端进行更加有效的参数聚合;
- 如何用尽可能少量的交互而达到最优效果;
- 如何在参数上传下载过程中进行安全与隐私保护等。
最近也有一些研究将联邦学习与表示学习以及自监督学习进行结合的文章,旨在更好的在联邦优化过程中学习更优的特征表示。
推荐算法为了保护用户隐私的需求,很容易迁移到联邦学习范式的场景中,即每个用户表示一个客户端,用户所产生的个人行为(比如浏览历史、点赞收藏历史等)保存在本地,通过与中心服务器进行协同优化,最终达到在本地模型进行预测推理的功能。
首个基于联邦学习范式的推荐框架

Federated Collaborative Filtering for Privacy-Preserving Personalized Recommendation System. arxiv, 2019.
比较经典的联邦推荐系统是19年华为提出的FCF,它是第一个基于联邦学习范式的隐式反馈协同过滤框架。

通过在本地利用个人数据更新自己的用户隐向量
,以及计算本地的物品隐向量梯度
并上传到中心服务器,其中
表示第
个客户端。最后客户端聚合物品隐向量
实现整体物品隐矩阵的更新。

以上提及的算法可以算是基本的联邦学习推荐系统的框架,后续人们对于联邦学习的每个部分进行了优化,接下来将一一介绍。
针对于显式数据的联邦学习推荐系统框架FedRec

FedRec: Federated Recommendation with Explicit Feedback. IEEEIntelligent Systems, 2020.
通过对上述FCF算法的分析,隐式数据在做联邦学习的时候有天然优势,即不会轻易的泄露出用户产生行为的物品,通过以下更新公式可以看出,对于所有未产生行为的物品当成了负样本,这样就间接的保护了用户的行为隐私,因为服务器很难判别
里面的哪些项目是用户喜欢的。

然而显式数据的求导就比较容易被服务器识别出用户的偏好物品,即求导的式子中只包含用户评过分的物品,因此不能直接将FCF方法应用于显式的评分预测任务中。
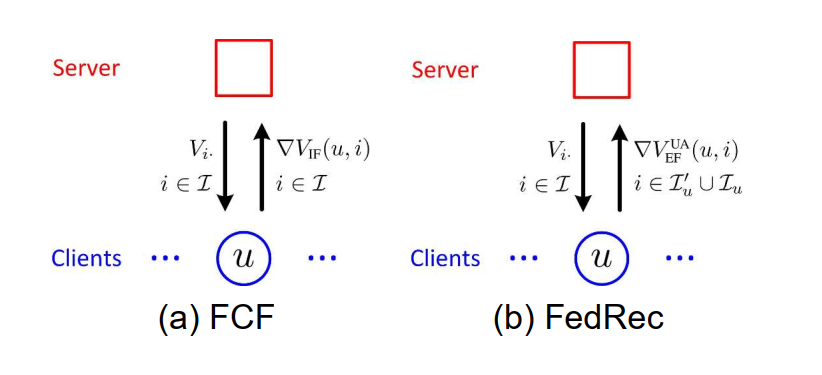
因此,本文提出了名为FedRec的方法来执行评分预测任务,即在上传用户梯度的时候,除了上传用户产出行为的物品集合外
,还随机采样了一些其他物品
来达到隐私保护的作用。值得一提的是,对于随机采样的物品集合来说,需要对他们模拟一些评分,因此论文中采用了两种机制来生成采样物品的评分,分别是用户平均的评分以及混合评分机制,更具体内容可阅读原文。
针对显式数据的无损失联邦学习推荐系统FedRec++

FedRec++: Lossless Federated Recommendation with Explicit Feedback. AAAI, 2021.
更进一步的,通过对上述FedRec算法的分析可以看出,通过为用户添加随机采样的物品以及模拟的评分确实可以混淆服务器使得无法精确识别用户对物品的喜好进而保护用户的隐私,但一定程度上向模型的梯度中添加了不容忽视的噪声,因此本文提出了一个消除噪声的推荐模型FedRec++。
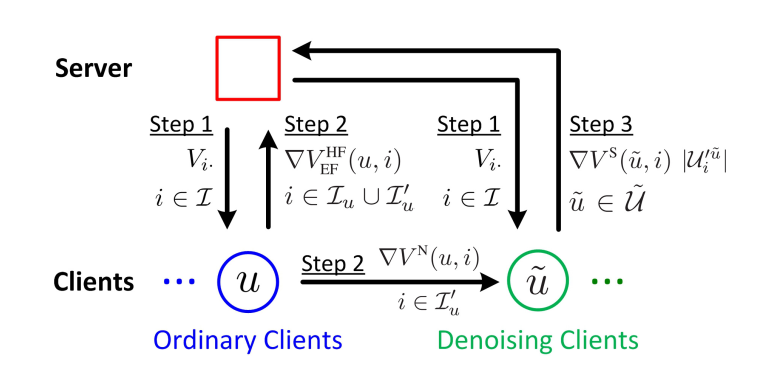
具体的,本文提出利用随机采样的去噪客户端(Denoising Clients)去收集普通客户端(Ordinary Clients)的带有噪声的梯度然后进行上传,当服务端收集到所有客户端的梯度后利用这种机制可以缓解梯度的噪声问题,随后再进行常规的聚合更新操作。更详细的技术细节可以参考原文。
改进聚合与更新策略的联邦推荐模型FedFast

FedFast Going Beyond Average for Faster Training of Federated Recommender Systems. KDD, 2020.
常规的联邦学习是通过随机的挑选客户端来进行参数的平均聚合更新,针对于此,本文对客户端更新的选择以及参数的聚合方式进行了优化,使得模型更快速的达到收敛的状态。
本文通过设计一个ActvSAMP算法来对客户端进行聚类,然后再从不同的聚类中挑选待更新的客户端
,随后再利用ActvAGG聚合算法对类内的客户端(subordinates)进行与挑选出的客户端(delegates)同样的更新,这样就可以减少通信的次数。

更具体的,ActvSAMP算法是利用客户端的其他具有隐私保护属性(比如设备类型、地区等)的特征来进行聚类
,然后再从每个聚类中挑选出
个区别较大的客户端组成待更新的客户端集合
。

对于ActvAGG组件,不是简单的加权聚合,而是把参数大致分为了三部分,即non-embedding部分、item embedding部分、user embedding部分。对于前两部分比较常规,对于user embedding的更新,首先对delegates进行更新,随后再对subordinates基于聚类结果和delegates进行更新。

基于元学习的个性化联邦推荐系统MetaMF

Meta Matrix Factorization for Federated Rating Predictions. SIGIR, 2020.
传统的联邦学习假设服务端模型与客户端模型的大小一样,但这样就对用户的终端设备带来了严峻的考验,因为并不是所有用户都使用土豪金的手机,所以不能像中心服务器训练模型那样可以肆无忌惮的对神经网络加层。因此本文考虑了客户端对存储、内存以及计算开销的限制,提出了一个基于元学习的联邦推荐算法,旨在对每个客户端学习一个小的个性化的模型,以此实现精准的推荐服务。

更具体的,在服务端学习协同信号(Collaborative Memory)以及建立元推荐系统(Meta Recommender),然后在客户端进行评分预测模型的建立以及生成物品的embedding,最终实现对物品的评分预测。
利用强化学习实现自适应减少通信量FCF-BTS

A Payload Optimization Method for Federated Recommender Systems-Recsys. RecSys, 2021.
刚才提到,对于联邦推荐系统,需要进行优化与上传更新的基本是全部物品的Embedding矩阵,因为用户终端只需要存储个人的Embedding向量即可,而不需要考虑其他用户向量。因此本文利用强化学习来挑选能够使得反馈具有正向收益的物品向量来进行更新。
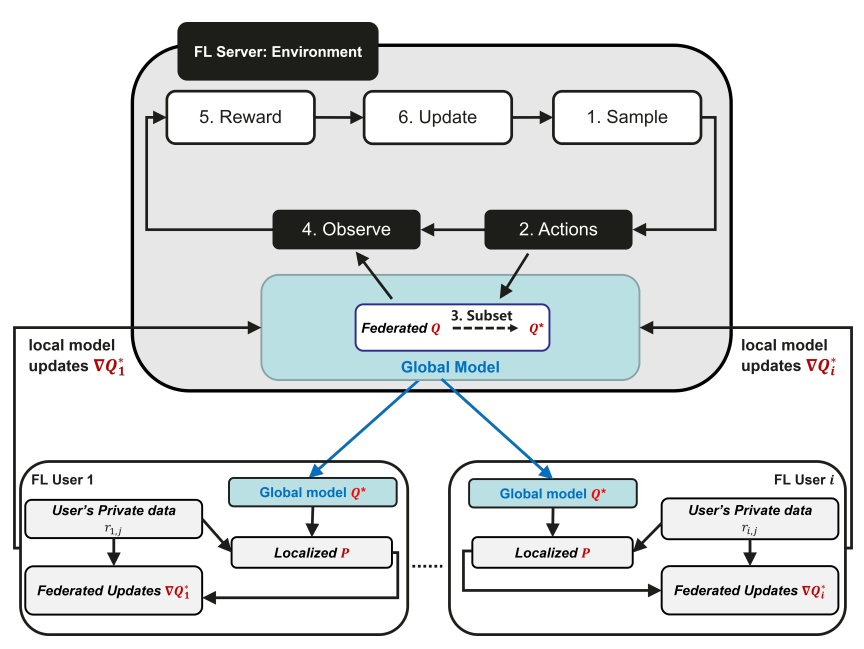
更具体的,首先通过贝叶斯汤姆森采样(BTS)bandit来得到物品的子集
,获得的这些物品能够得到最大的期望收益;然后基于带更新的物品子集
来获得待更新矩阵
的子集,记为
;随后从客户端获取这些物品的梯度,等到一定个数的阈值后进行更新物品矩阵
,随后计算当前的收益,基于此来更新BTS的模型参数。通过进行迭代优化,最终得到最优的模型参数。

基于层次化的个性化联邦推荐系统

Hierarchical Personalized Federated Learning for User Modeling. WWW, 2021.
常规的联邦学习推荐系统通常假设用户的本地数据都是敏感信息,因此对待模型的更新与上传一视同仁。本文从三个异质性的角度来实现更符合实际场景的假设,即统计异质性(Statistical heterogeneity)、隐私异质性(Privacy heterogeneity)和模型异质性(Model heterogeneity)。其中,统计异质性认为用户的数据在不同的客户端是不服从独立同分布的(即non-IID数据),隐私异质性认为用户的本地数据应该包含公开的和敏感的信息,这样就需要对数据进行不同程度的隐私保护,模型异质性认为不同客户端的模型需要被自适应的在服务端进行聚合。
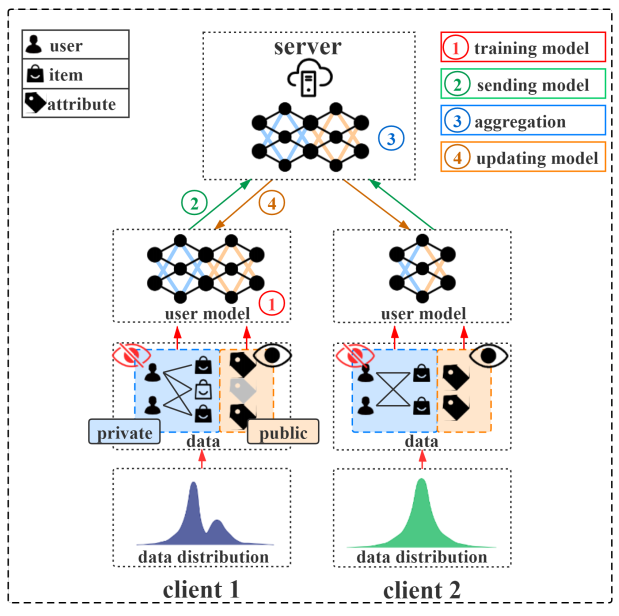
更具体的,该文提出了利用层次信息来划分数据为隐私的(private)和公开的(public)数据来实现隐私异质性。其次,本地模型包含不同的组件来实现模型的异质性。另外,客户端执行细粒度的个性化更新策略来实现统计的异质性。
强隐私保护的隐式反馈联邦推荐系统

Stronger Privacy for Federated Collaborative Filtering With Implicit Feedback. RecSys, 2021.
通常来说,保存在客户端的模型包含该用户的隐特征向量
以及与用户无关的全部物品的隐特征矩阵
。对于用户向量的更新
由于不需要上传到服务器而不离开本地而得到很好的保护。由于上传物品特征矩阵的更新梯度容易被第三方攻击者获取进而进行重构攻击(有研究表明可以从中间梯度获取到原始输入的图像数据[]),因此本文对物品的更新梯度矩阵进行了严格的隐私保护。
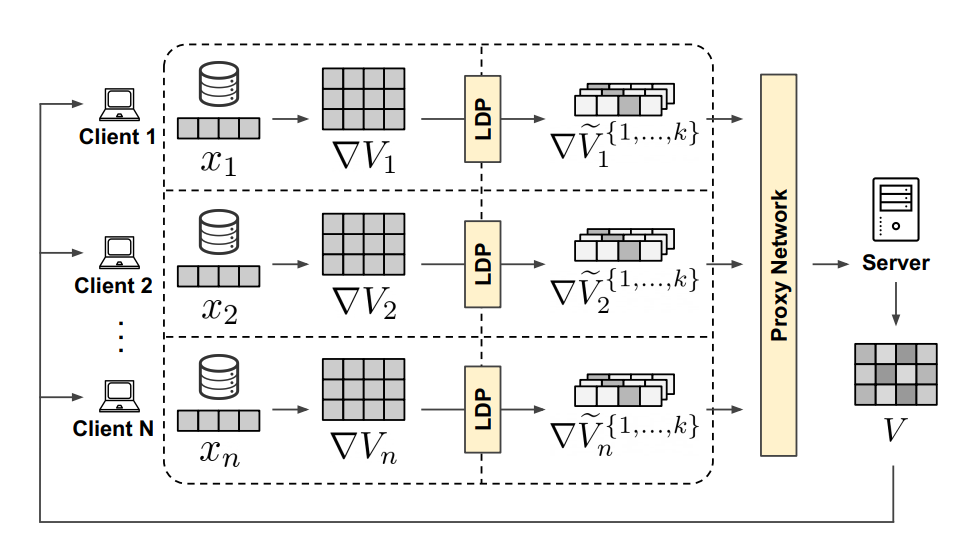
更具体的,对于客户端得到的物品更新梯度矩阵
,经过LDP(Local Differential Privacy, 本地差分隐私)模块以及代理网络(Proxy Network)来得到不包含用户元数据的隐私保护的物品更新梯度矩阵
,随后再进行平均聚合。

总结

本文总结了几篇基于联邦学习范式的推荐系统,分别从不同的层面对基本的联邦学习更新方式进行了优化,比如如何实现更好的聚合参数、如何更好的挑选待更新的客户端、如何保持更严格的隐私保护、如何减少更新过程中的通信量等。
该方向相对来说是一个比较新的方向,其目标是在保护用户隐私的前提下如何实现本地模型更精准的推荐服务,但现在的实验验证方式基本都是靠模拟来完成的,即手动将完整的数据集切分为符合联邦学习方式的多个本地数据集。另外由于推荐系统的特殊性(不同于计算机视觉中假设本地客户端在100-500左右),即每个用户即为一个客户端,真实场景的用户数量可达上百万,这就对实验的验证带来了考验。由于本人水平有限,难免文中观点会存在纰漏,欢迎指正,另外更多关于联邦学习推荐系统的思考欢迎小伙伴补充。