本文整理自Syntiant公司副总裁Mallik P. MOTURI的讲座:

小编注:Syntiant是边缘人工智能的领军企业,专注于为各类设备提供深度学习解决方案。其独特的神经决策处理器和深度学习算法,使得音频、视频、语音等能实现实时智能处理,广泛应用于从小型助听器到大型汽车的多种设备中。Syntiant的技术不仅提升了设备的智能化水平,还大幅降低了功耗,引领着边缘AI技术的发展。
让我来介绍一下Syntiant公司。自创立以来,我们一直致力于改善人类与技术的联系。我们的目标是通过整合语音和视觉等自然界面,使日常设备更加智能和直观。在早期,我们专注于语音交互,并为此开发了相关设备。然而,随着语音技术和大型语言模型的发展,我们看到了一个跃进的机会。
将这些先进的模型集成到边缘设备中是我们发展的下一个合理步骤。通过这样做,我们增强了像对话语音这样的能力,利用了我们之前在唤醒词、命令、视觉和自动语音识别(ASR)方面的Aji芯片的工作。现在,我们正处于通过集成大型语言模型(LLM)进一步提升这些能力的边缘。
转向边缘计算的原因是由客户对边缘AI功能的需求推动的。这些需求的规模和紧迫性是前所未有的。他们寻求的技术不仅要能够实时响应,还要优先考虑隐私和效率。这一需求推动我们在边缘部署了超过2500万个神经网络芯片和5000多万个模型。
总而言之,我们正朝着技术无缝融入我们生活的未来迈进。Syntiant站在这一运动的前沿,引领AI向边缘发展,使大型语言模型能够在本地运行,从而确保更快的响应时间、增强的隐私保护以及更直观的用户体验。

大模型往边缘设备的发展经历了一个引人注目的过程,以下是其主要阶段:
- 早期基于规则的系统:
- 近50年前,人工智能系统主要是基于规则的。
- RNN和LSTM的发展:
- 随后,循环神经网络(RNN)和长短期记忆网络(LSTM)开始发展,为大模型奠定了基础。
- 注意力机制的突破:
- “Attention is All You Need”论文的发表标志着注意力机制的突破,为大模型的发展带来了新的方向。
- 大模型的崛起与主流应用:
- 从最初的小众研究领域逐渐走向主流应用,大模型如Lama 2等展现出强大的能力。
- 边缘设备上的应用:
- Lama 2等模型现在可以在像Raspberry Pi这样紧凑的设备上运行,这突显了我们对于边缘设备托管复杂人工智能模型的信念。
- 更高效的大模型即将到来:
- 目前已经有10亿参数模型在边缘设备上运行,而更高效的大语言模型(LLM)也正在开发中。
- 资源受限环境下的广泛应用:
- 我们正在推动这些大模型在资源受限环境下具备更广泛的能力,以满足不同应用场景的需求。
这个过程展示了大型语言模型从最初的研究阶段到如今在边缘设备上的广泛应用的显著进步。随着技术的不断发展,我们可以期待未来在更多领域看到大模型的身影。
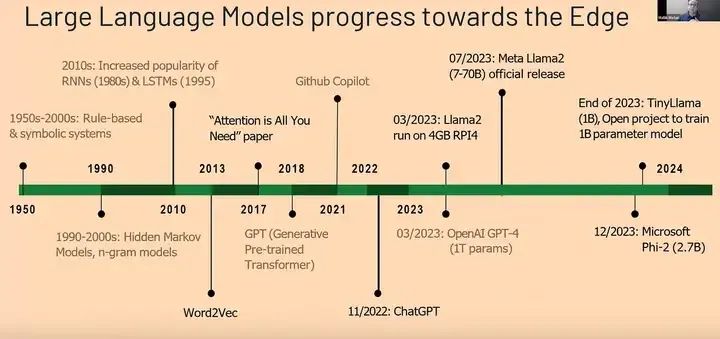
当今的顶尖技术水平是什么样的呢?目前,像Llama 2或微软的Phi2等先进的大型语言模型(LLM)在不需要大型服务器的情况下就表现出了非常高的性能。高通或英特尔等公司的技术进步,加之他们所做的架构优化,使得这些模型能够在计算资源非常低的环境下高效运行。这种向边缘的高效强大模型的转变才刚刚开始。对于实时大型语言模型应用,如对话语音,我们每秒仅需要三到四个标记,这对于小型大型语言模型的实用实现来说是一个需要注意的重要点。了解大型语言模型的架构对于我们下一步的发展至关重要。

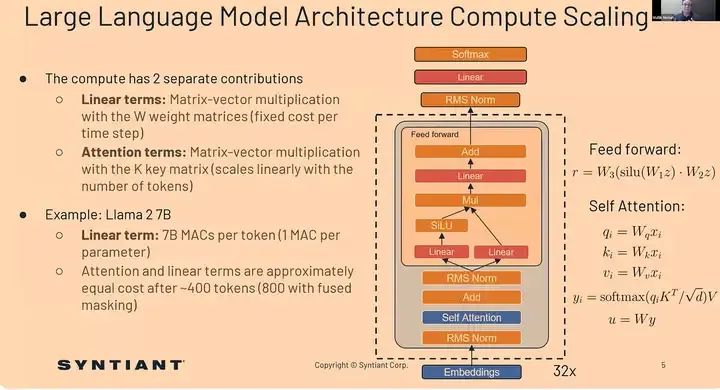
这只是我在这里展示的大型语言模型中的一个元素。它揭示了如何平衡计算需求以实现高效利用。例如,Llama 2的设计优化了线性和注意力项。这种维护可以帮助在非常紧凑的设备上保持高性能。因此,这种平衡对于在最需要人工智能的地方部署它至关重要——直接在边缘端。优化注意力项的能力,例如在Llama 2中,是我们稍后将在几张幻灯片中展示的内容。如果你能有效地实现它,你可以获得更快的速度和保持准确性。如果你看一下不同的优化方法和途径,你就会明白这种平衡的重要性。
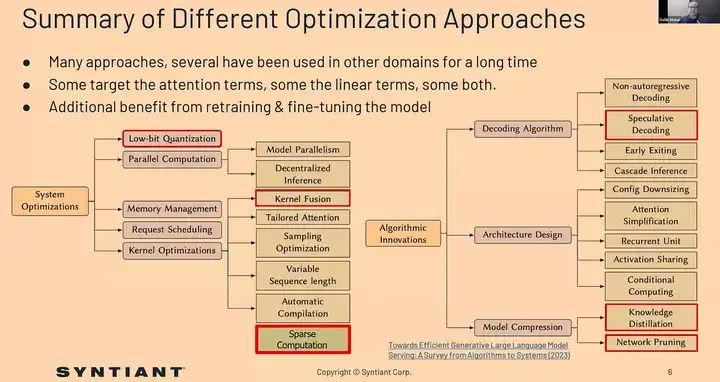
多年来,在不同的领域已经采用了多种优化策略。如果我们关注之前提到的线性项或模型再训练的目标,这些优化方法能够在不损害模型完整性的情况下提高性能。我们发现的一些关键优化方法包括量化、内核融合等,我将在下一张幻灯片中详细讨论。我们探索过的优化方法还有预测解码、知识蒸馏和网络剪枝。通过进一步稀疏微调或再训练量化,我们在保持准确性的同时,实现了显著的加速。
让我详细介绍一下其中的几个优化策略。这里我想强调的是动态规范化和有监督的微调。这两种技术基本上展示了我们是如何根据需求量身定制大型语言模型的。这两种方法显著降低了内存需求,并充分加速以实现实时操作,当然,这仅用于评估目的。
我们根据输入确定模型的关键部分,以确保在没有任何精度损失的情况下高效运行。我们特别关注利用稀疏性和近似值,将小值视为零,这种方法最初为我们带来了约30%的显著加速,且没有任何精度损失。此外,我们还探索了多种优化方法来减少数据量,包括输入输出的稀疏性以及高效的内存管理数据结构。
之后,我们进一步使用了有监督的微调,对自定义数据集进行再训练。由于我们采用的内存减少技术,我们仅使用非常有限的资源就完成了所有的再训练,具体来说,我们使用了16个A100 GPU进行再训练。这是我们部署的一个非常关键和重要的特性,这种方法使性能提高了两倍,与我们的硬件优化相结合,实现了显著的加速。这些是我们展示的,对于大型语言模型和人工智能的实际需求。最后,我在一个旧的x86 CPU上展示了一个小例子。
动态稀疏化与再训练是一种创新的深度学习模型优化方法。它涉及基于输入选择性评估模型的不同部分,从而提高效率。针对边缘应用,我们使用16个A100 GPU在资源有限的情况下对自定义数据集进行了监督微调(SFT)。如果模型采用ReLU激活函数,则自然会得到稀疏性。然而,即使不采用ReLU,也可以将小值近似为0以产生稀疏性。这种方法可以在不显著降低准确性的情况下实现约1.3倍的速度提升。此外,可以实现许多优化以减少数据需求,例如量化感知训练和稀疏感知训练。通过利用输入稀疏性、输出稀疏性和内存管理的有效数据结构(如行列绑定),我们可以实现显著的2倍速度提升。

让我来解释一下,上周我们在Jetson Nano上展示了这种加速效果。目前,我们正在与更小的微控制器(MCUs)和微处理器(MPUs)合作,以部署相同的加速示例。根据硬件资源,我们可以实现每秒5、10或20个标记的生成速度。对于对话语音,最多需要每秒三到四个标记;然而,在这个演示中,我们实现了大约每秒五个标记的速度。本实现采用了GML,这是一个专为机器学习设计的C库,重点是支持大型模型并促进在商用硬件上进行高性能计算。采用的模型是来自GML的Llama DocB,它在右侧运行,而左侧运行的是Syntiant优化语言模型。值得注意的是,在应用最先进的技术后,系统的运行速度大约是原来的两倍。在这个演示中,模型的任务是列出化学元素的原子序数。显然,这里生成标记的速度翻倍,并且所有操作都在同一台机器上执行。值得一提的是,如果在不同或更先进的PC上执行,与替代方法相比,我们的实现可以潜在地达到每秒大约10个标记的生成速度,而后者每秒生成五个或更少的标记。接下来,总的来说,Syntiant并不仅仅是在跟随趋势。

总结
- 边缘计算的需求正在增长:
- 这意味着在靠近数据源的设备或终端上进行数据处理和分析的需求正在不断增加。边缘计算有助于减少数据传输延迟,提高处理效率,并增强数据安全性。
- 在受限的计算环境中运营(与其他大多数AI行业不同):
- 这表明Syntiant关注的是在资源有限的环境中运行人工智能模型,这与其他主要依赖强大计算资源的人工智能应用有所不同。在边缘设备上运行AI模型需要特别的优化技术,以适应内存、计算能力和功耗等方面的限制。
- 开发了一种基于状态的Art LLMa-7B模型,以每秒1.3x-2x的速度加速多线程x86机器:
- Syntiant已经开发了一种优化的大型语言模型(LLM),即Art LLMa-7B,它能够在多线程x86架构的机器上实现1.3倍到2倍的加速。这表明该模型在保持性能的同时,显著提高了处理速度。
- 支持的Syntiant Inference SDK(Ambarella、Qualcomm等)实现了高达30个令牌/秒的性能:
- Syntiant提供的推理软件开发工具包(Inference SDK)已与多家硬件供应商(如Ambarella、Qualcomm等)合作,实现了高达每秒处理30个令牌的高性能。这显示了Syntiant在优化AI模型以在不同硬件平台上高效运行方面的能力。
- 客户使用案例的例子,包括家用电器、商业设备、服务和大型零售店:
- 这部分列举了Syntiant技术的实际应用场景。从家用电器到商业设备,再到服务和大型零售店,Syntiant的技术正在各种场景中发挥作用,提升设备的智能化水平和用户体验。
- 相信优化LLMs在运行硬件上将获得更广泛的采用:
- 这是Syntiant对未来的展望。随着边缘计算和人工智能技术的不断发展,以及硬件性能的不断提升,优化后的大型语言模型将在更多领域得到广泛应用。Syntiant对此充满信心,并致力于推动这一趋势的发展。

我们展望未来,我们的愿景是明确的。我们希望继续开拓和整合更小、更高效的小语言模型和定制硅技术。这是真正需要彻底改变存储技术和使用的。所以,你知道,我们将为前进设定新的趋势和状态。此外,生成式人工智能不仅仅是技术创新,它实际上是在创造一个世界,在这个世界里,人工智能无缝地融入我们的日常生活,并与每个设备进行自然交互。这是为明天铺平道路。这就是我们认为小语言模型即将到达的边缘,也将保持在那里。
