多模态模型,是指具备理解来自不同模态(如视觉、自然语言、语音等)的混合信号能力的神经网络模型,是当今人工智能模型发展的重要方向之一。本文将要介绍的文献题目为《16.1 MulTCIM: A 28nm 2.24μJ/Token Attention-Token-Bit Hybrid Sparse Digital CIM-Based Accelerator for Multimodal Transformers》,作者是来自清华大学集成电路学院和香港科技大学电子与计算机学院(Department of Electronic and Computer Engineering)的涂锋斌博士,提出了一种数字存算一体核心设计,可以支持多模态Transformer模型的计算。
一.文章基本信息[1]
神经网络模型的终极目的是具备像人一样的感知和处理能力,多模态模型为此而被提出,其中的佼佼者即为多模态Transformer模型。但是,当前的多模态Transformer模型在硬件上执行时面临以下三项稀疏度方面的挑战:
(1)注意力稀疏性方面,作为Transformer模型重要组成部分的注意力矩阵,具有不规则的稀疏性,可能导致较长的复用距离。例如,在ViLBERT-base模型中可以覆盖了78.6%~81.7%的令牌数。为了支持这样的运算,存算核中需长期存储大量权重,而这些权重的使用率极低;
(2)令牌稀疏性方面,尽管可以通过令牌剪枝降低计算量,但不同模态的令牌具有不同的长度会导致跨模态注意力层产生计算空闲或流水线延时;
(3)位稀疏性方面,Softmax、GERU等激活函数会产生很多接近0的数据,增强待处理数据的稀疏度,CIM核心的同一组输入的有效位宽会反复变化。而传统CIM中的串行乘累加计算方案,使得计算时间受到最长位宽的限制。
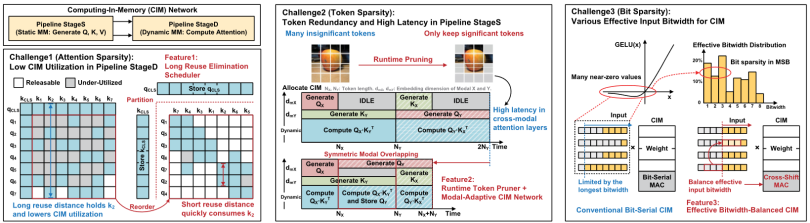
针对以上问题,本文提出了三项针对性解决方案:
(1)针对注意力矩阵不规则稀疏性导致的较长复用距离,本文提出一种长重用消除调度器(LRES,Long Reuse Elimination Scheduler)。LRES将注意力矩阵拆分为全局+局部稀疏的模式,其中全局类似的注意力权重向量会在CIM中存储更长时间,局部类似的权重向量则会更频繁地消耗和更新,以减少不必要的长时间重用距离,而并非像传统的Transformer那样依次生成Q、K、V的令牌,可以提高存算一体核的利用率;
(2)针对不同模态的令牌长度不同导致计算空闲或流水线延时的问题,本文提出了运行时令牌剪枝器(RTP,Runtime Token Pruner)和模态自适应CIM网络(MACN,Modal-Adaptive CIM Network)来优化此过程。RTP能够移除不重要的令牌,而MACN则能够动态地在注意力层中的不同模态之间进行切换,减少CIM的闲置时间,并降低生成Q、K令牌的延迟;
(3)针对激活函数稀疏性带来的最长位宽变化的问题,本文引入了有效位宽平衡CIM(Effective Bitwidth Balanced CIM,EBB-CIM)宏架构来解决该问题。EBB-CIM通过检测输入向量中每个元素的有效位宽并进行位平衡处理,以平衡在存储器MAC中的输入位,从而减少计算时间。这通过为较短的有效位宽元素重新分配较长的有效位宽元素中的位来实现,进而使整体的输入位宽更加平衡。
二.论文内容解析[1]
下面,本文将针对作者提出的三项稀疏度方面的挑战,详细介绍文章创新点:
(1)LRES
LRES包含三个依次工作的部分:
1)注意力稀疏管理器:用于存储初始的稀疏注意力模式,并根据运行时的令牌剪枝信息更新这一模式,在这一步骤中,管理器会识别产生广泛注意的Q和K向量,因为这些向量需要在CIM核心中存储更长的时间,以提高CIM的利用率;
2)局部注意力排序器:对剩余的注意力矩阵,Q和K向量进行重新排序,其中K作为权重,Q作为输入向量在CIM中进行频繁消耗和切换。这意味着K向量会频繁被新生成的K向量替代,从而减少CIM的闲置;
3)重塑注意力生成器:基于前两个步骤的输出生成配置信息,用于优化CIM核心的工作流程。
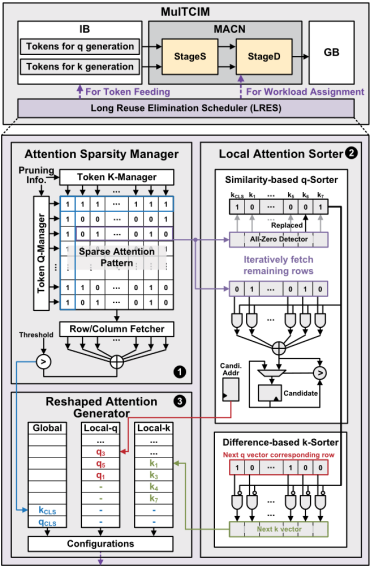
(2)RTP与MACN
如图3所示,描述了针对令牌稀疏性进行优化的RTP和MACN模块。其中,RTP模块主要负责删除无关紧要的令牌。MACN则是将所有CIM核动态地划分为两个流水线阶段:StageS用于Q、K和V令牌生成中的静态矩阵乘法(MM);StageD用于注意力计算的动态MM,下面将详细分析两个模块。
首先由于类(CLS)标记表征了其他标记的重要性,因此RTP需要接收前一层的CLS分数,并选择当前层的前n个最重要标记。而MACN包括一个模态工作负载分配器(Modal Workload Allocator,MWA)、16个CIM内核和一个流水线总线。在工作时,MWA需要将CIM内核划分为StageS和StageD,并根据分配表预先分配StageS的权重。此外,在跨模态交换方面,传统方法顺次计算模态,不同的模态参数会导致跨模态交换机中有许多空闲的CIM宏;而MACN利用模态对称性来重叠多模态Q、K令牌的生成,从而降低延迟。具体实现方案为,CIM的4:1激活结构将多模态权重存储在一个宏中,并通过时间多路复用切换模态:在时间为1~NX时,MACN处于Phase1状态,Core1在示例中存储WQX和WQY;在时间为NX~NY时,MACN切换到Phase2状态,Core1激活WQY以生成QY;在时间为NY~NX+NY时,MACN切换到Phase3状态,Core1激活WQY和WKX以生成QY和KX。模态对称性使QY、KX的生成同时完成,并具有更好的CIM利用率。
最终结果表明,RTP将单模态和跨模态注意力的延迟降低了2.13倍和1.58倍,模态对称性为跨模态注意力提供了额外的1.69倍加速。

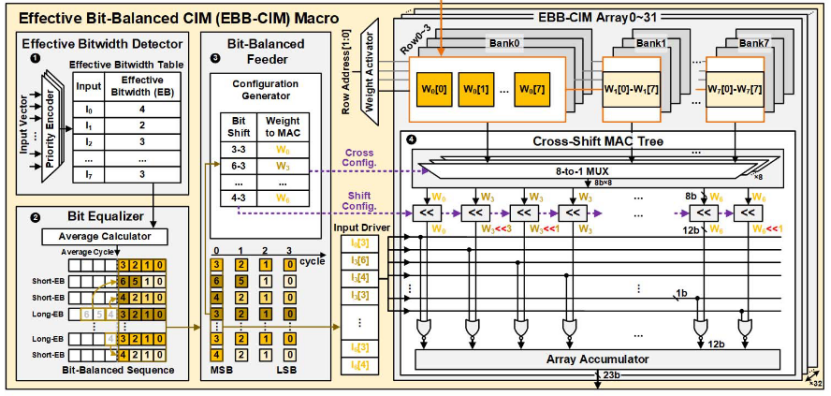
(3)EBB-CIM
如图4所示,显示了针对位稀疏性进行优化的EBB-CIM宏。它包括32个EBB-CIM阵列、一个有效的比特宽检测器、一个位均衡器和一个位平衡馈线。其中每个EBB-CIM阵列有4×64个6T-SRAM位单元(8个组)和一个交叉移位乘累加树(Cross-Shift MAC Tree),EBB-CIM使用4:1激活的全数字CIM架构,在INT16下实现了高计算精度,同时保持内存密度;检测器在运行时接收输入并检测有效比特宽(EB);位均衡器计算平均EB,将长EB数据的位分配给短EB数据,产生位平衡输入序列;位平衡馈线获取序列并生成交叉移位配置。此外,EBB-CIM可通过每两次INT8操作融合来针对INT16重新配置。
最终结果表明,与传统的位串行CIM相比,EBB-CIM将softmaxMM、GELU-MM和整个编码器的延迟分别降低了2.38倍、2.20倍和1.58倍,功耗开销仅占5.1%,面积开销仅占4.6%。
三.多模态模型
(1)概念和原理
多模态模型指的是能够处理和理解多种类型数据的模型,例如文本、图像、音频、视频等。与单一模态模型相比,多模态模型能够融合来自不同模态的信息,从而提升信息理解和任务处理的准确性和全面性。
多模态模型的核心原理在于跨模态的信息融合与协同处理,其主要过程包括:
1)数据表示:将不同模态的数据转换为模型可以处理的形式。通常使用特定的编码器将各模态数据表示为向量或嵌入;
2)特征提取:从不同模态的数据中提取有意义的特征。例如,使用卷积神经网络(CNN)处理图像,使用循环神经网络(RNN)或Transformer架构来处理文本;
3)跨模态对齐:在不同模态间建立关联,例如通过对齐时间戳或利用共享注意力机制,确保不同模态的信息可以有效融合;
4)信息融合:将对齐后的多模态特征进行融合,常用的方法包括简单的拼接、加权求和、以及使用更复杂的融合网络;
5)决策和输出:通过融合后的特征进行任务处理和决策输出,如分类、生成或检索。
(2)应用和前景
多模态模型在很多领域有着广泛的应用,比如最典型的是视觉问答(Visual Question Answering)和图像描述生成(Image Captioning),即将图片输入给ChatGPT让其理解含义(如图5),或输入一段话让ChatGPT生成图像(如图6)。
除此之外,2月发布的Sora、4月发布的Vidu等视频生成大模型,具有视频描述生成(Video Captioning)功能;上周发布的ChatGPT-4o大模型还具有多模型情感分析(Multimodal Sentiment Analysis)、跨模态检索(Cross-modal Retrieval)、多模态翻译(Multimodal Translation)等功能,他们都依托多模态大模型来实现。

多模态模型带来的网络规模增大、参数剧增、训练成本提升等问题将对传统芯片架构提出挑战,而存内计算技术可以很好的应对这些问题。存内计算技术将带来更高的能耗效率、计算效率、数据处理并行度与更低的传输延迟、计算功耗,这些特点使得存内计算芯片在多模态模型的训练、推理等场景中占据优势,有望取代传统冯﹒诺依曼架构成为新一代AI芯片的架构选择。国内知存科技已在存内计算芯片领域深耕多年,自2019年11月发布国际首个存内计算芯片产品WTM1001起,五年间已实现WTM1001量产投片、国际首个存内计算SoC芯片WTM2101验证与小批量试产投片、WTM-8系列新一代计算视觉芯片量产等等。在未来,存内计算芯片将在多模态模型领域发挥更大的作用,为多模态模型的广泛应用提供有力支持。
参考文献:
[1]Tu F, Wu Z, Wang Y, et al. 16.1 MuITCIM: A 28nm 2.24μJ/Token Attention-Token-Bit Hybrid Sparse Digital CIM-Based Accelerator for Multimodal Transformers[C]//2023 IEEE International Solid-State Circuits Conference (ISSCC). IEEE, 2023: 248-250.
[2]Tu F, Wu Z, Wang Y, et al. MulTCIM: Digital Computing-in-Memory-Based Multimodal Transformer Accelerator With Attention-Token-Bit Hybrid Sparsity[J]. IEEE Journal of Solid-State Circuits, 2023.