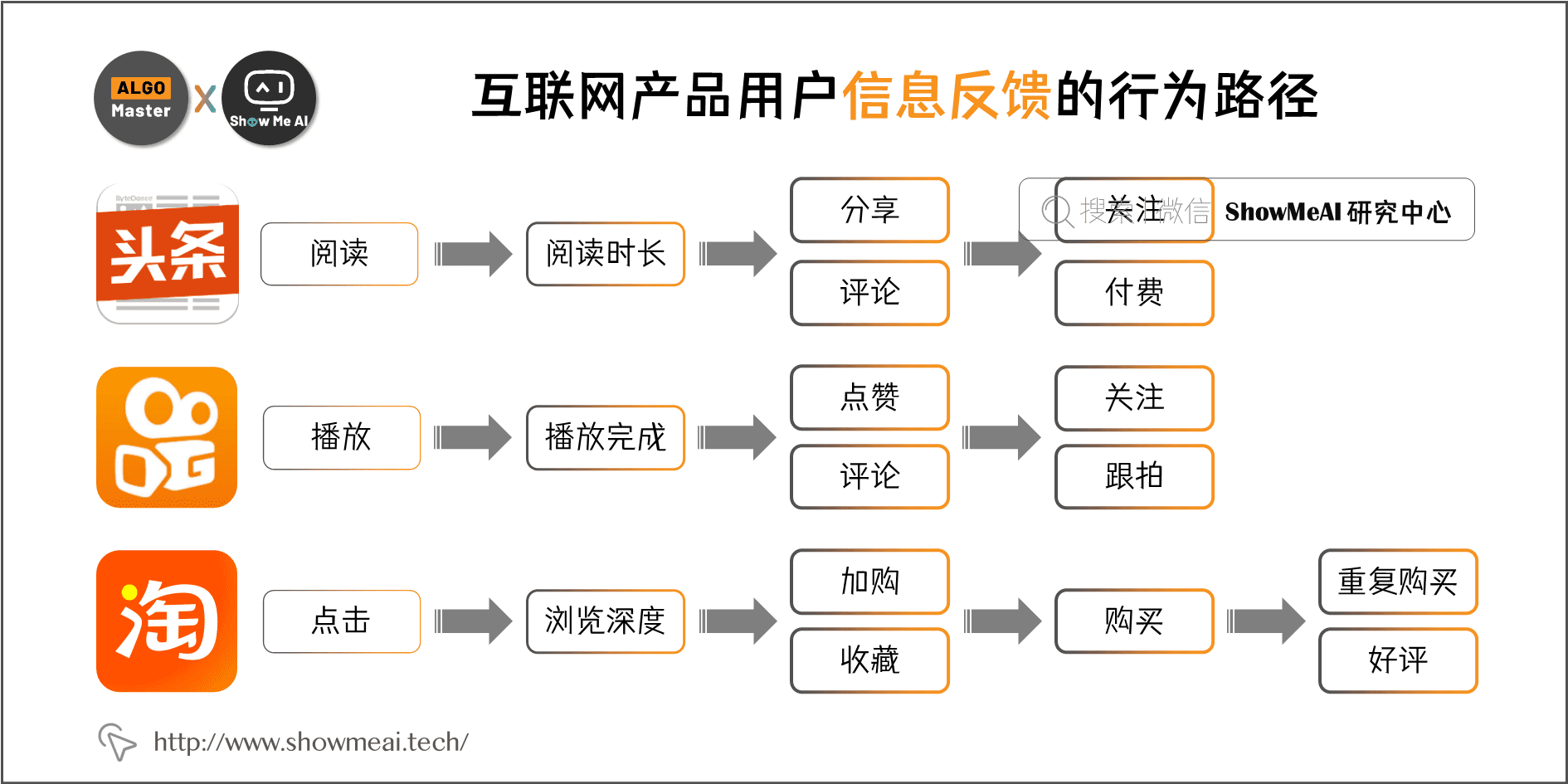
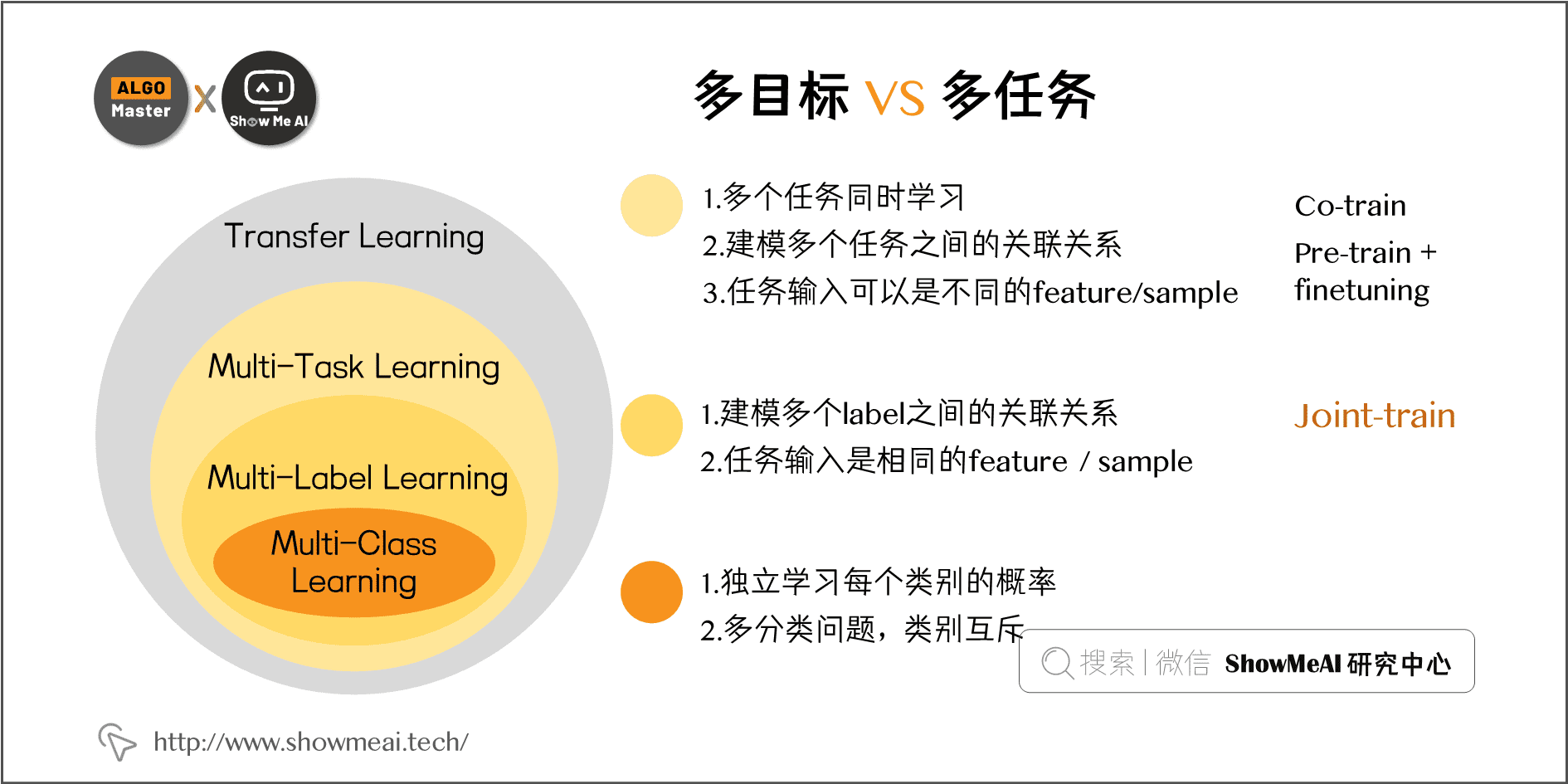
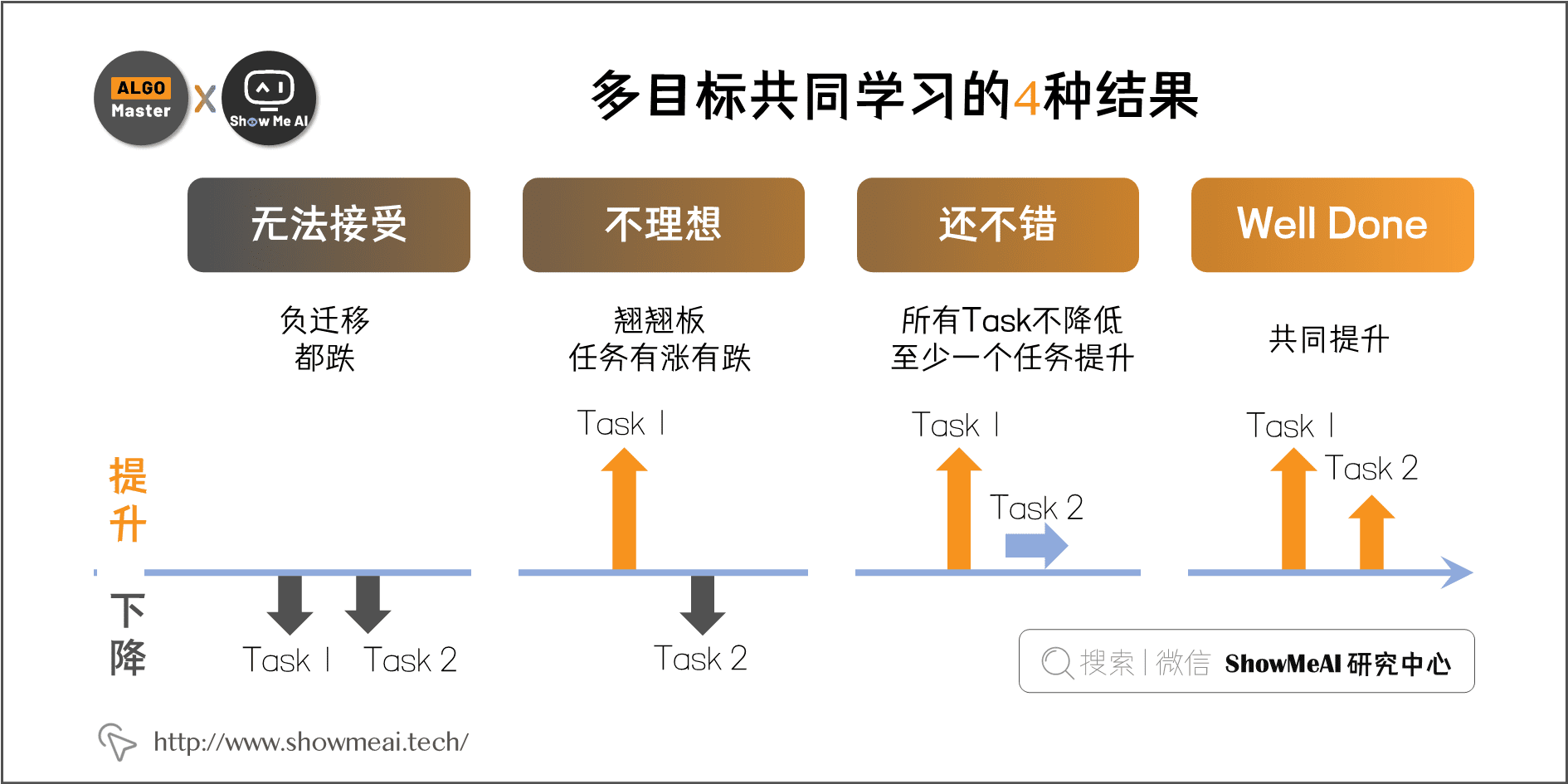
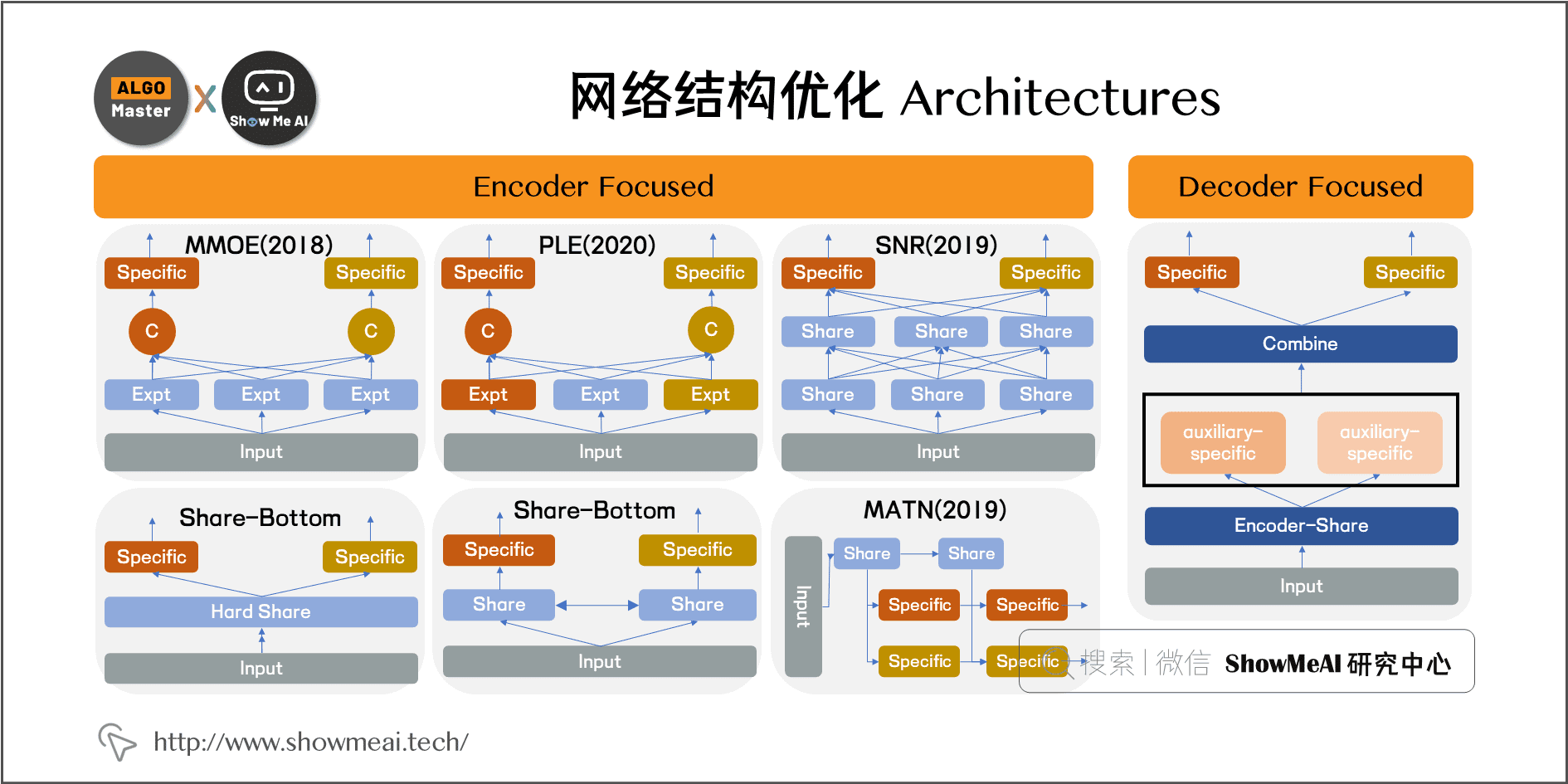
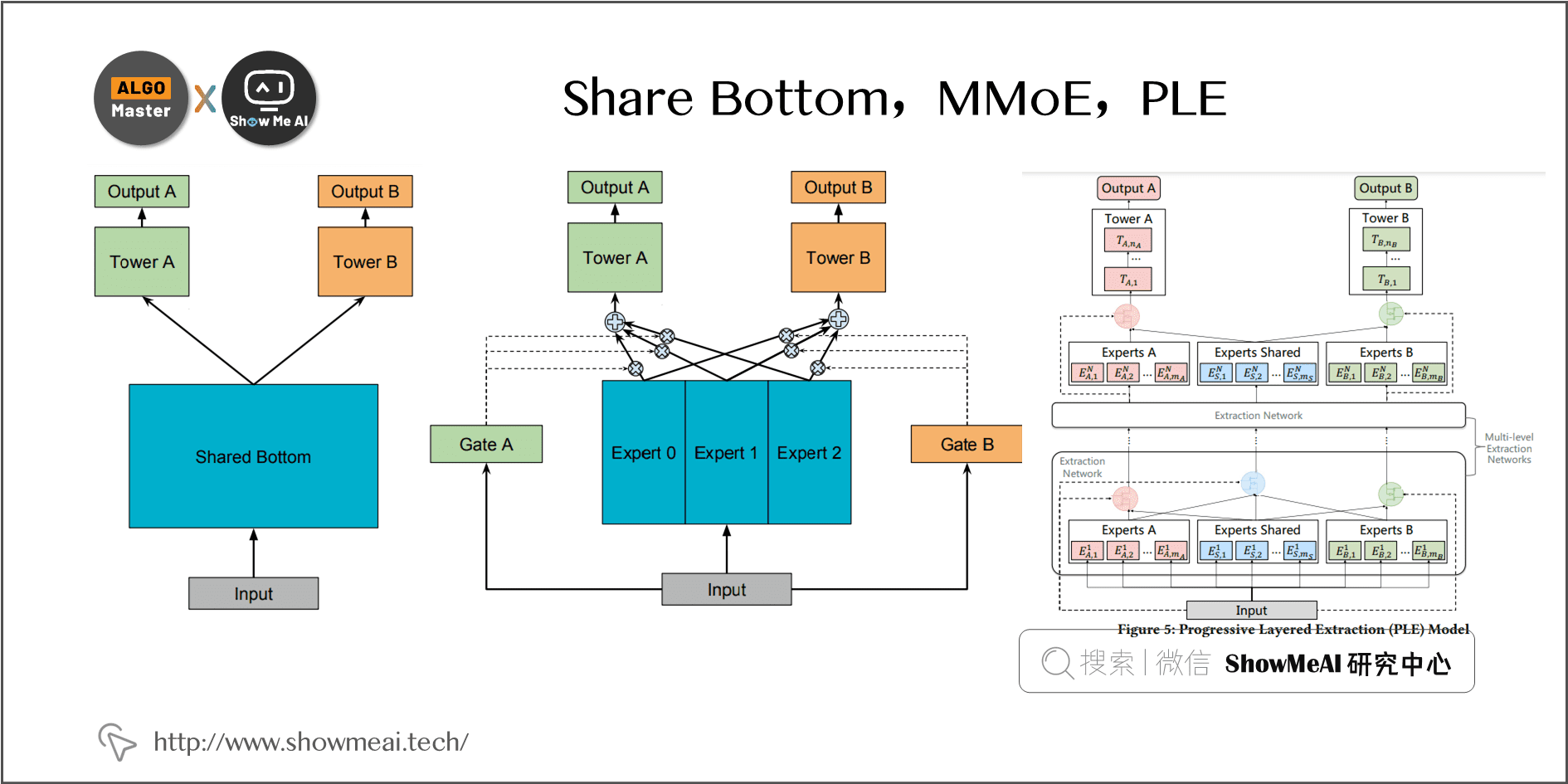
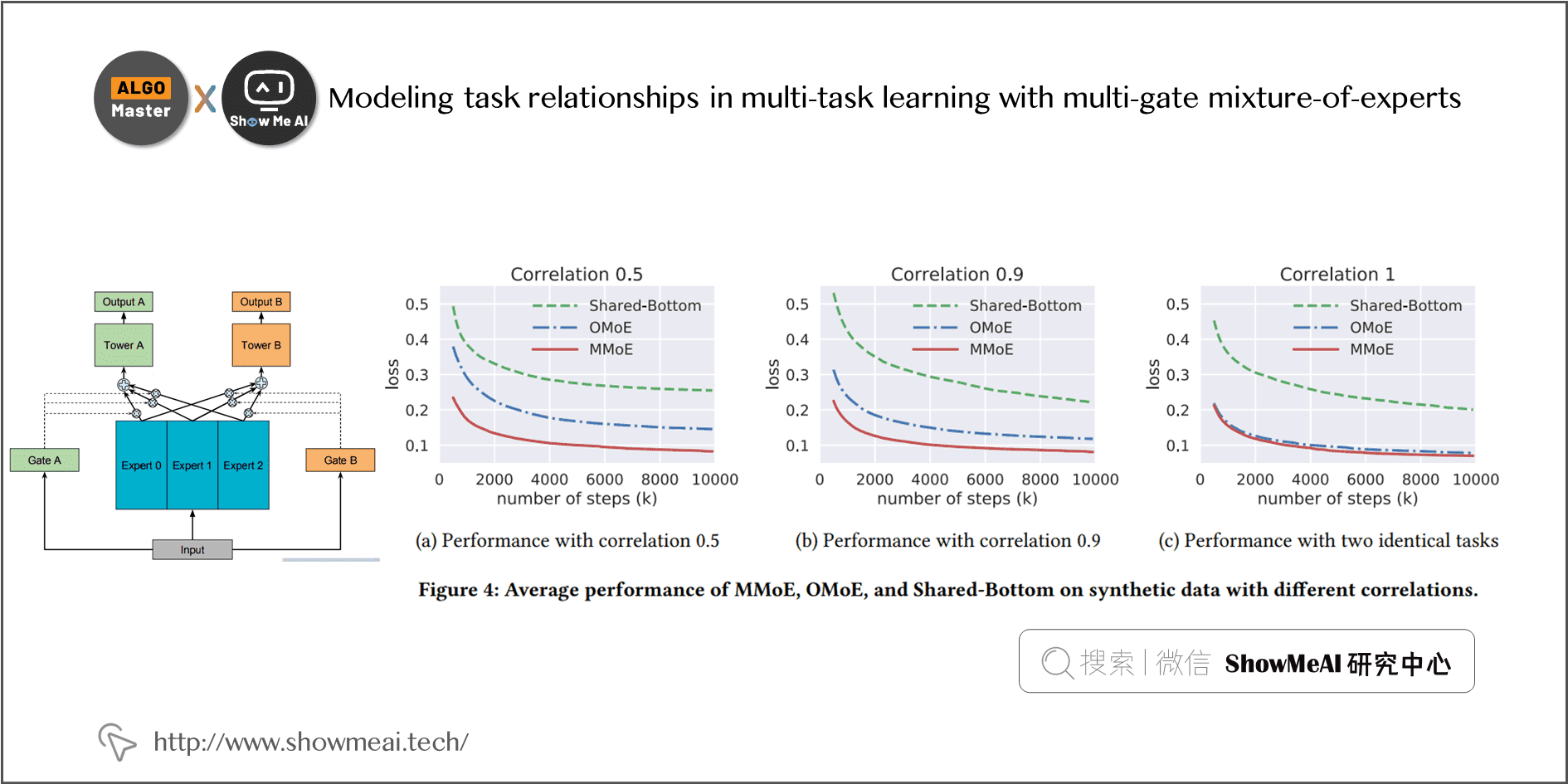
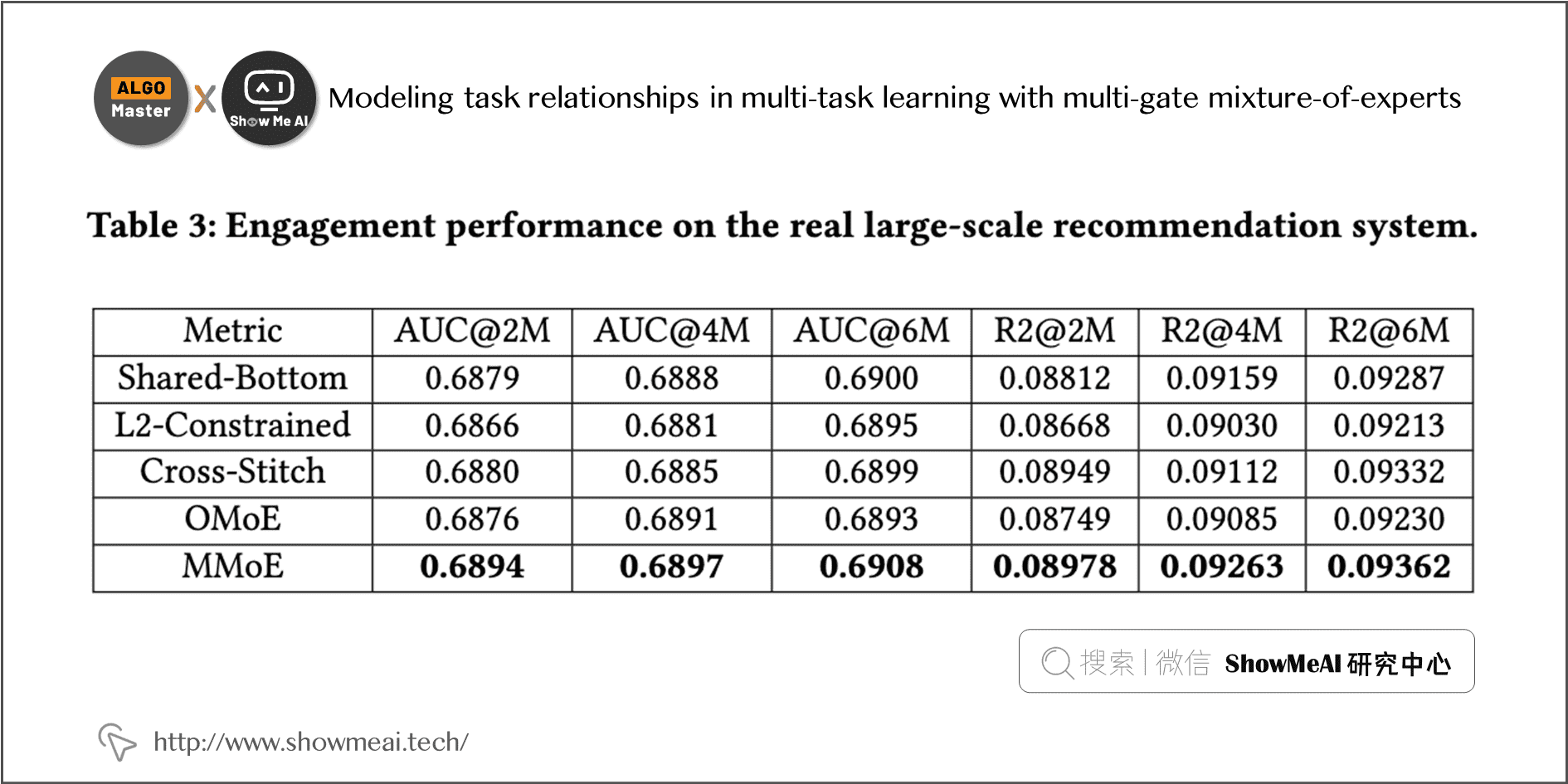
Google《Modeling task relationships in multi-task learning with multi-gate mixture-of-experts》提出的 MMoE 几乎成为各家互联网公司做多任务多目标学习排序的标配结构。 在 Google 这篇 paper 中,研究人员通过人工控制两个任务的相似度,测试和研究不同网络结构的表现效果。
Modeling task relationships in multi-task learning with multi-gate mixture-of-experts; 1-16
MMoE核心代码参考:
代码语言:python
代码运行次数:0
复制
Cloud Studio 代码运行
class MMoE_Layer(tf.keras.layers.Layer):
def __init__(self,expert_dim,n_expert,n_task):
super(MMoE_Layer, self).__init__()
self.n_task = n_task
self.expert_layer = [Dense(expert_dim,activation = 'relu') for i in range(n_expert)]
self.gate_layers = [Dense(n_expert,activation = 'softmax') for i in range(n_task)]
def build(self, input_shape=None):
# 初始化 log_vars
self.log_vars = []
for i in range(self.nb_outputs):
self.log_vars += [self.add_weight(name='log_var' + str(i), shape=(1,),
initializer=Constant(0.), trainable=True)]
super(CustomMultiLossLayer, self).build(input_shape)
def multi_loss(self, ys_true, ys_pred):
assert len(ys_true) == self.nb_outputs and len(ys_pred) == self.nb_outputs
loss = 0
for y_true, y_pred, log_var in zip(ys_true, ys_pred, self.log_vars):
precision = K.exp(-log_var[0])
loss += K.sum(precision * (y_true - y_pred)**2. + log_var[0], -1)
return K.mean(loss)
def call(self, inputs):
ys_true = inputs[:self.nb_outputs]
ys_pred = inputs[self.nb_outputs:]
loss = self.multi_loss(ys_true, ys_pred)
self.add_loss(loss, inputs=inputs)
return K.concatenate(inputs, -1)</code></pre></div></div><h4 id="fed08" name="2%EF%BC%89GradNorm-5">2)GradNorm 5</h4><p>Gradient normalization方法的主要思想是:</p><ul class="ul-level-0"><li>希望不同的任务的 <span>Loss</span> 量级是接近的</li><li>希望不同的任务以相似的速度学习</li></ul><p>《<em style="font-style:italic"><strong>Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks</strong></em>》这篇paper尝试将不同任务的梯度调节到相似的量级来控制多任务网络的训练,以鼓励网络以尽可能相同的速度学习所有任务。</p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:100%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723343556633771285.png" /></div><div class="figure-desc">GradNorm; 1-26</div></div></div></figure><p><strong>Gradient normalization具体实现方式如下</strong>:</p><ul class="ul-level-0"><li>定义两种类型的 <span>Loss</span> :<span>Label \quad Loss</span> 和 <span>Gradient \quad Loss</span>。这两种 <span>Loss</span> 独立优化,不进行运算。<ul class="ul-level-1"><li><span>W4</span> 的函数。</li><li><span>w_i(t)</span> 的好坏,Gradient Loss 是关于权重 <span>w_i(t)</span> 的函数。</li></ul></li><li><span>w_i(t)</span> 是一个变量(注意这里 <span>w</span> 与网络参数 <span>W</span> 是不同的),<span>w</span> 也通过梯度下降进行更新,<span>t</span> 表示当前处于网络训练的第 <span>t</span> 步。</li></ul><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:100%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723343556998618556.png" /></div><div class="figure-desc">Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks; 1-27</div></div></div></figure><p><strong>gradnorm在单个batch step的流程总结如下</strong>:</p><ol class="ol-level-0"><li>前向传播计算总损失 <span>operatorname{Loss}=\Sigma_{i} w_{i} l_{i}</span></li><li>计算 <span>G_{W}^{i}(t), r_{i}(t), \bar{G}_{W}^{i}(t)</span> </li><li>计算 <span>Grad \quad Loss</span></li><li>计算 <span>Grad \quad Loss</span> 对 <span>w_{i}</span> 的导数</li><li>利用第1步计算的 <span>Loss</span> 反向传播更新神经网络参数</li><li>利用第4步的倒数更新 <span>w_{i}</span> (更新后在下一个 batch step 生效)</li><li>对 <span>w_{i}</span> 进行 renormalize (下一个batch step使用的是 renormalize 之后的 <span>w_{i}</span> ) </li></ol><p><strong>GradNorm核心代码参考</strong>:</p><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>python</div><div class="rno-markdown-code-toolbar-item is-num"><i class="icon-code"></i><span class="is-m-hidden">代码</span>运行次数:<!-- -->0</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div><button class="rno-markdown-code-toolbar-run"><i class="icon-run"></i><span class="is-m-hidden">Cloud Studio</span> 代码运行</button></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-python"><code class="language-python" style="margin-left:0">class GradNorm:
def __init__(self,
device,
model,
model_manager,
task_ids,
losses,
metrics,
train_loaders,
test_loaders,
tensorboard_writer,
optimizers,
alpha=1.):
super().__init__(
device, model, model_manager, task_ids, losses, metrics,
train_loaders, test_loaders, tensorboard_writer)
self.coeffs = torch.ones(
len(task_ids), requires_grad=True, device=device)
optimizer_def = getattr(optim, optimizers['method'])
self.model_optimizer = optimizer_def(
model.parameters(), **optimizers['kwargs'])
self.grad_optimizer = optimizer_def(
[self.coeffs], **optimizers['kwargs'])
self.has_loss_zero = False
self.loss_zero = torch.empty(len(task_ids), device=device)
self.alpha = torch.tensor(alpha, device=device)
def train_epoch(self):
"""
训练1轮
"""
self.model.train()
loader_iterators = dict([(k, iter(v))
for k, v in self.train_loaders.items()])
train_losses_ts = dict(
[(k, torch.tensor(0.).to(self.device)) for k in self.task_ids])
train_metrics_ts = dict(
[(k, torch.tensor(0.).to(self.device)) for k in self.task_ids])
total_batches = min([len(loader)
for _, loader in self.train_loaders.items()])
num_tasks = torch.tensor(len(self.task_ids)).to(self.device)
relative_inverse = torch.empty(
len(self.task_ids), device=self.device)
_, all_branching_ids = self.model.execution_plan(self.task_ids)
grad_norm = dict([
(k, torch.zeros(len(self.task_ids), device=self.device))
for k in all_branching_ids])
pbar = tqdm(desc=' train', total=total_batches, ascii=True)
for batch_idx in range(total_batches):
tmp_coeffs = self.coeffs.clone().detach()
self.model.zero_grad()
self.grad_optimizer.zero_grad()
for k, v in self.model.rep_tensors.items():
if v.grad is not None:
v.grad.zero_()
if v is not None:
v.detach()
# 对每个task, 计算梯度,反向传播, 累计gradients norms
for task_idx, task_id in enumerate(self.task_ids):
data, target = loader_iterators[task_id].next()
data, target = data.to(self.device), target.to(self.device)
# do inference and accumulate losses
output = self.model(data, task_id, retain_tensors=True)
for index in all_branching_ids:
self.model.rep_tensors[index].retain_grad()
loss = self.losses[task_id](output, target)
weighted_loss = tmp_coeffs[task_idx] * loss
weighted_loss.backward(retain_graph=False, create_graph=True)
output.detach()
# GradNorm relative inverse training rate accumulation
if not self.has_loss_zero:
self.loss_zero[task_idx] = loss.clone().detach()
relative_inverse[task_idx] = loss.clone().detach()
# GradNorm accumulate gradients
for index in all_branching_ids:
grad = self.model.rep_tensors[index].grad
grad_norm[index][task_idx] = torch.sqrt(
torch.sum(torch.pow(grad, 2)))
# calculate training metrics
with torch.no_grad():
train_losses_ts[task_id] += loss.sum()
train_metrics_ts[task_id] += \
self.metrics[task_id](output, target)
# GradNorm calculate relative inverse and avg gradients norm
self.has_loss_zero = True
relative_inverse = relative_inverse / self.loss_zero.clone().detach()
relative_inverse = relative_inverse / torch.mean(relative_inverse).clone().detach()
relative_inverse = torch.pow(relative_inverse, self.alpha.clone().detach())
coeff_loss = torch.tensor(0., device=self.device)
for k, rep_grads in grad_norm.items():
mean_norm = torch.mean(rep_grads)
target = relative_inverse * mean_norm
coeff_loss = coeff_loss + mean_norm.mean()
# GradNorm optimize coefficients
coeff_loss.backward()
# optimize the model
self.model_optimizer.step()
pbar.update()
for task_id in self.task_ids:
train_losses_ts[task_id] /= \
len(self.train_loaders[task_id].dataset)
train_metrics_ts[task_id] /= \
len(self.train_loaders[task_id].dataset)
train_losses = dict([(k, v.item())
for k, v in train_losses_ts.items()])
train_metrics = dict([(k, v.item())
for k, v in train_metrics_ts.items()])
pbar.close()
return train_losses, train_metrics</code></pre></div></div><h4 id="aed0s" name="3%EF%BC%89DWA-6">3)DWA 6</h4><p>《<em style="font-style:italic"><strong>End-to-End Multi-Task Learning with Attention</strong></em>》这篇paper中直接定义了一个指标来衡量任务学习的快慢,然后来指导调节任务的权重。</p><p>用这一轮 <span>Loss</span> 除以上一轮 <span>Loss</span> ,这样可以得到这个任务 <span>Loss</span> 的下降情况用来衡量任务的学习速度,然后直接进行归一化得到任务的权重。当一个任务 <span>Loss</span> 比其他任务下降的慢时,这个任务的权重就会增加,下降的快时权重就会减小。是只考虑了任务下降速度的简化版的 Gradient normalization,简单直接。</p><h4 id="39tet" name="4%EF%BC%89PCGrad-7">4)PCGrad 7</h4><p>PCGrad 是 Google 在 NIPS 2020《<em style="font-style:italic"><strong>Gradient surgery for multi-task learning</strong></em>》这篇 paper 里提出的方法,PCGrad 指出 MTL 多目标优化存在3个问题:</p><p>① 方向不一致,导致撕扯,需要解决</p><p>② 量级不一致,导致大 gradients 主导,需要解决</p><p>③ 大曲率,导致容易过拟合,需要解决</p><p><strong>解决办法如下</strong>:</p><ul class="ul-level-0"><li>先检测不同任务的梯度是否冲突,冲突的标准就是是否有 negative similarity;</li><li>如果有冲突,就把冲突的分量 clip 掉(即,把其中一个任务的梯度投影到另一个任务梯度的正交方向上)。</li></ul><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:100%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723343557529238483.png" /></div><div class="figure-desc">Gradient surgery for multi-task learning; 1-28</div></div></div></figure><p><strong>论文中的算法步骤如下</strong>:</p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:100%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723343557846405132.png" /></div><div class="figure-desc">Gradient surgery for multi-task learning; 1-29</div></div></div></figure><p><strong>PCGrad核心代码参考</strong>:</p><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>python</div><div class="rno-markdown-code-toolbar-item is-num"><i class="icon-code"></i><span class="is-m-hidden">代码</span>运行次数:<!-- -->0</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div><button class="rno-markdown-code-toolbar-run"><i class="icon-run"></i><span class="is-m-hidden">Cloud Studio</span> 代码运行</button></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-python"><code class="language-python" style="margin-left:0">class PCGrad(optimizer.Optimizer):
def __init__(self, optimizer, use_locking=False, name="PCGrad"):
"""
optimizer优化器
"""
super(PCGrad, self).__init__(use_locking, name)
self.optimizer = optimizer
def compute_gradients(self, loss, var_list=None,
gate_gradients=GATE_OP,
aggregation_method=None,
colocate_gradients_with_ops=False,
grad_loss=None):
assert type(loss) is list
num_tasks = len(loss)
loss = tf.stack(loss)
tf.random.shuffle(loss)
# 计算每个任务的梯度
grads_task = tf.vectorized_map(lambda x: tf.concat([tf.reshape(grad, [-1,])
for grad in tf.gradients(x, var_list)
if grad is not None], axis=0), loss)
# 计算梯度投影
def proj_grad(grad_task):
for k in range(num_tasks):
inner_product = tf.reduce_sum(grad_task*grads_task[k])
proj_direction = inner_product / tf.reduce_sum(grads_task[k]*grads_task[k])
grad_task = grad_task - tf.minimum(proj_direction, 0.) * grads_task[k]
return grad_task
proj_grads_flatten = tf.vectorized_map(proj_grad, grads_task)
# 把展平的投影梯度恢复原始shape
proj_grads = []
for j in range(num_tasks):
start_idx = 0
for idx, var in enumerate(var_list):
grad_shape = var.get_shape()
flatten_dim = np.prod([grad_shape.dims[i].value for i in range(len(grad_shape.dims))])
proj_grad = proj_grads_flatten[j][start_idx:start_idx+flatten_dim]
proj_grad = tf.reshape(proj_grad, grad_shape)
if len(proj_grads) < len(var_list):
proj_grads.append(proj_grad)
else:
proj_grads[idx] += proj_grad
start_idx += flatten_dim
grads_and_vars = list(zip(proj_grads, var_list))
return grads_and_vars</code></pre></div></div><h4 id="579eb" name="5%EF%BC%89GradVac-8">5)GradVac 8</h4><p>GradVac是Google在ICLR 2021《<em style="font-style:italic"><strong>Investigating and improving multi-task optimization in massively multilingual models</strong></em>》这篇paper里提出的方法,作为PCGrad的改进应用在多语种机器翻译任务上。</p><p><strong>对比PCGrad,我们看看GradVac的做法</strong>:</p><ul class="ul-level-0"><li>PCGrad 只是设置了一个下界。让两个任务的 cosine 相似度至少是大于等于 <span>0</span> 的,不能出现负数。这个下界非常容易达到。</li><li>两个任务的真实相似度,其实是会逐渐收敛到一个水位。这个值可以认为是两个任务的真实相似度。</li><li>两个任务的 Gradinet 相似度,应当去靠近这个相似度,而不是只满足 PCGrad 设置的下界。</li></ul><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:100%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723343558344150004.png" /></div><div class="figure-desc">Investigating and improving multi-task optimization in massively multilingual models; 1-30</div></div></div></figure><h2 id="eckpm" name="%E5%85%AD%E3%80%81%E6%80%BB%E7%BB%93">六、总结</h2><p>总结一下,本文提到了多目标多任务场景下的优化方法,主要包含 网络结构优化 和 优化方法和策略提升两方面,最终目标都是希望缓解任务间的冲突和内耗,尽量优化提升所有业务目标。要构建一个 promising 的共赢多任务多目标解决方案,一些经验 tips 如下:</p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:100%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723343558831662979.png" /></div><div class="figure-desc">经验Tips | 构建共赢多任务多目标解决方案; 1-31</div></div></div></figure><ul class="ul-level-0"><li><strong>1)首先关注业务场景,思考业务目标优化重点,进而确定多任务的组合形式</strong>:<ul class="ul-level-1"><li>主任务 + 主任务:解决业务场景既要又要的诉求,多个任务都希望提升</li><li>主任务 + 辅任务:辅助任务为主任务提供一些知识信息的增强,帮助主任务提升 2.考虑不同任务间的重要度和相似性,考虑清楚辅助任务和主任务的关系;</li></ul></li><li><strong>2)实际训练过程中,可以训练优化其中1个任务,观察其他任务的</strong> <span>Loss</span> <strong>变化</strong>。<ul class="ul-level-1"><li>其他任务 <span>Loss</span> 同步下降,则关联性较强</li><li>其他任务 <span>Loss</span> 抖动或有上升趋势,要回到业务本身思考是否要联合多任务训练 </li></ul></li><li><strong>3)网络结构选择 MMoE 或者 PLE</strong>。</li><li><strong>4)训练过程中关注</strong> <span>Loss</span> <strong>的量级,如果不同任务之间差异很大,注意约束和控制</strong>。</li><li><strong>5)训练过程的优化策略,可以尝试 PCGrad 等方法对梯度进行调整,并观察效果</strong>。</li></ul><h2 id="fvb9a" name="%E5%8F%82%E8%80%83%E6%96%87%E7%8C%AE">参考文献</h2><blockquote><p><strong>1</strong> Ma J, Zhao Z, Yi X, et al. Modeling task relationships in multi-task learning with multi-gate mixture-of-expertsC//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 1930-1939.
2 Jiaqi Ma, Zhe Zhao, Jilin Chen,et al. SNR: Sub-Network Routing forFlexible Parameter Sharing in Multi-Task LearningC//The Thirty-Third AAAI Conference on Artificial Intelligence (AAAI-19).2019: 216-223 3 Tang H, Liu J, Zhao M, et al. Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendationsC//Fourteenth ACM Conference on Recommender Systems. 2020: 269-278. 4 Kendall A, Gal Y, Cipolla R. Multi-task learning using uncertainty to weigh losses for scene geometry and semanticsC//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7482-7491. 5 Chen Z, Badrinarayanan V, Lee C Y, et al. Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networksC//International Conference on Machine Learning. PMLR, 2018: 794-803. 6 Liu S, Johns E, Davison A J. End-to-end multi-task learning with attentionC//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 1871-1880. 7 Yu T, Kumar S, Gupta A, et al. Gradient surgery for multi-task learningJ. arXiv preprint arXiv:2001.06782, 2020. 8 Wang Z, Tsvetkov Y, Firat O, et al. Gradient vaccine: Investigating and improving multi-task optimization in massively multilingual modelsJ. arXiv preprint arXiv:2010.05874, 2020.