引言
本研究展示了一种新型Transformer的语言模型:Mixture-of-Depths Transformer,该模型能够动态地分配计算资源到输入序列的特定位置,而不是像传统模型那样均匀地分配计算资源。通过动态计算分配方式,可以在保持性能的同时显著提高模型速度,可比isoFLOP最优基线模型快66%!

https://arxiv.org/pdf/2404.02258.pdf
背景介绍
生活中,并非所有的问题都需要相同的时间来解决。同样在语言模型中也是,并非所有Token和序列都需要相同的算力来进行预测。然而,Transformer模型在前向传播中为每个Token花费了相同的计算量,针对这个问题,我们能否让Transformer省去这些不必要的计算呢?
条件计算(Conditional computation)是一种减少总计算量的技术,它只会在需要时才会进行计算。何时需要计算、需要多少的计算量,目前已经有了多种解决方案。然而,这些算法在现有硬件下并不一定适用,因为它们倾向于引入动态计算图,而现有硬件更倾向于使用的静态计算图。
为了克服这一挑战,本文作者考虑在静态计算预算下进行语言建模,并且该静态预算可以小于普通Transformer所需的计算预算。其中,对于每一层的Token决策,神经网络必须要学会如何动态分配计算资源。在实现过程中,总计算量是由用户定义的,并且在训练前是不变的,而不是网络动态决策的函数。因此,硬件使用效率的提升可以根据占用内存的减少、每次前向传播FLOP的减少进行提前预测。
本文使用了一个类似专家混合(MoE)Transformer的方法,其中动态Token级别路由决策是在整个网络深度上做出的。不同于MoE,本文选择对Token应用计算(类似标准Transformer)、或者通过残差连接进行前向传播。此外,本文还将这种路由方法同时应用于前向多层感知机(MLPs)和多头注意力机制。因此,这也影响了对keys和query的处理,路由不仅决定更新哪些Token,还决定了哪些Token用于注意力机制。本文将这种策略称为深度混合(Mixture-of-Depths, MoD)。
MoD实现
MoD Transformers方法是通过设置一个静态的计算预算,这个预置计算量比传统Transformer模型要小。这个计算预算通过限制在给定层中可以参与自注Token意力和多层感知机(MLP)计算的Token数量来实现。这种方法使用了一个每层的路由器来决定哪些Token应该参与计算,哪些应该通过残差连接绕过计算,从而节省计算资源。
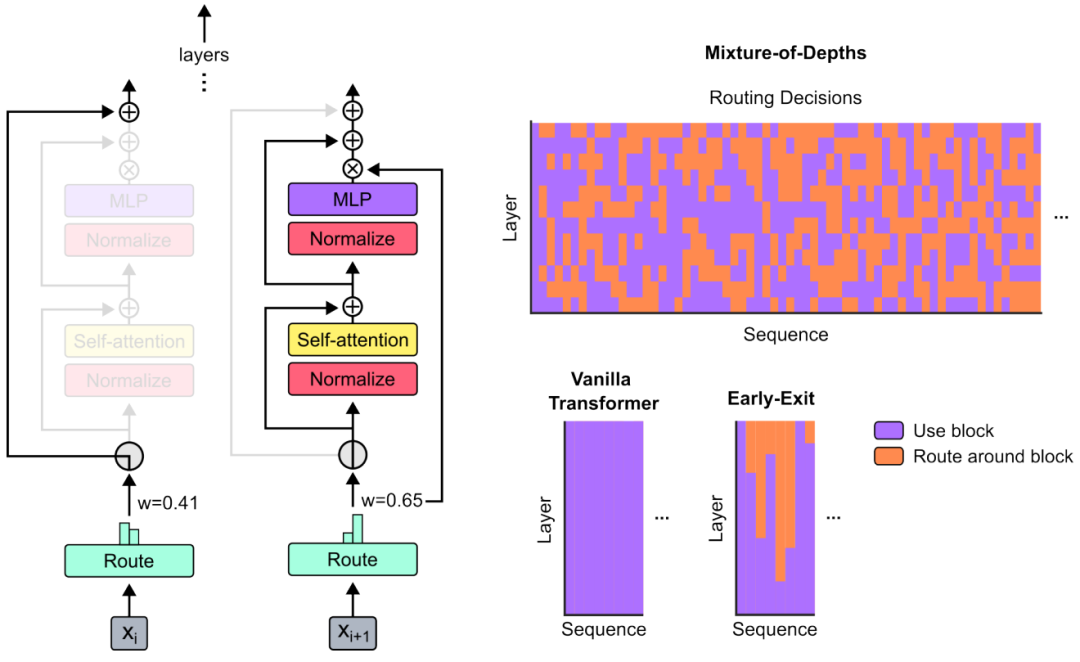
具体实现方式:
「1.定义计算预算」 即通过限制序列中可以参与计算的Token数量来强制执行总体计算预算。为了在Transformer模型中有效控制计算资源,作者通过“容量”概念来限制每次计算的输入Token数量。传统Transformer的自注意力和MLP使用全部Token,而MoE Transformer则为每个专家分配较少的Token,以平衡计算负载。
计算资源的分配取决于Token容量,即使在条件计算中也是如此。通过减少计算容量,可以降低每次前向传播的计算需求,但如果处理不当,可能会影响模型性能。作者认为,不是所有Token都需要同等程度的处理,因此模型可以通过学习来识别哪些Token更重要。这样,网络可以在保持性能的同时,更高效地使用计算资源。
「2.围绕Transformer块的路由」 路由机制可以让模型决定哪些数据需要进行密集计算,哪些可以跳过。这是通过为序列中的每个数据项分配一个权重来实现的,权重高的数据项会参与完整的计算过程,而权重低的则通过一个简单的跳过步骤,以节省计算资源。这种动态选择的方法使得模型在保持处理质量的同时,能够更高效地运行。通过调整这个机制,模型可以在速度和性能之间找到最佳平衡。
「3.路由方案」 用来决定哪些数据项参与复杂计算,哪些可以简化处理的策略。主要有两种方案:1)基于Token的路由:每个数据项根据偏好选择参与计算的路径,但可能导致处理不均衡。2)基于专家的路由:每个计算路径选择一定数量的数据项,保证处理均衡,但可能使某些数据项被过度或不足处理。

本文最终选择了基于专家的路由方案,因为它可以更有效地平衡计算资源,并且简化了实施过程,如上图所示。通过这种方法,模型能够在保持性能的同时减少计算量,提高运行效率。
「4.采样」 在MoD Transformer模型的自回归采样阶段,面临着如何在不依赖未来Token信息的情况下进行有效路由决策的挑战。为了应对这一挑战,文中提出了两种策略。第一种是引入辅助损失,通过二元交叉熵损失函数调整路由器输出,使得模型能够基于当前和过去的Token信息做出因果路由决策。
第二种策略是使用一个辅助预测器,它作为一个小型的辅助网络,预测每个Token是否应该参与计算,从而在采样过程中提供必要的路由信息。这两种方法都避免了对未来Token的依赖,确保了模型在序列生成时的高性能和效率。
「5.模型训练」所有模型都使用相同的基本超参数配置(例如,128batch、2048 序列长度)。
实验结果
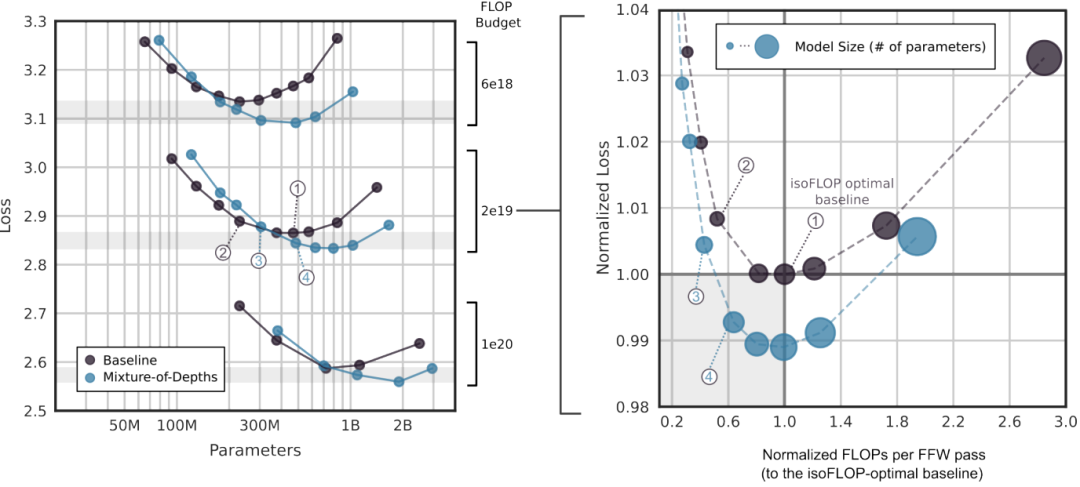
「速度提升」 下图展示了MoD超参数微调结果,其中包括不同模型变体的性能比较,以及学习曲线,说明了模型在保持相同性能的同时,速度比isoFLOP最优基线模型快66%。
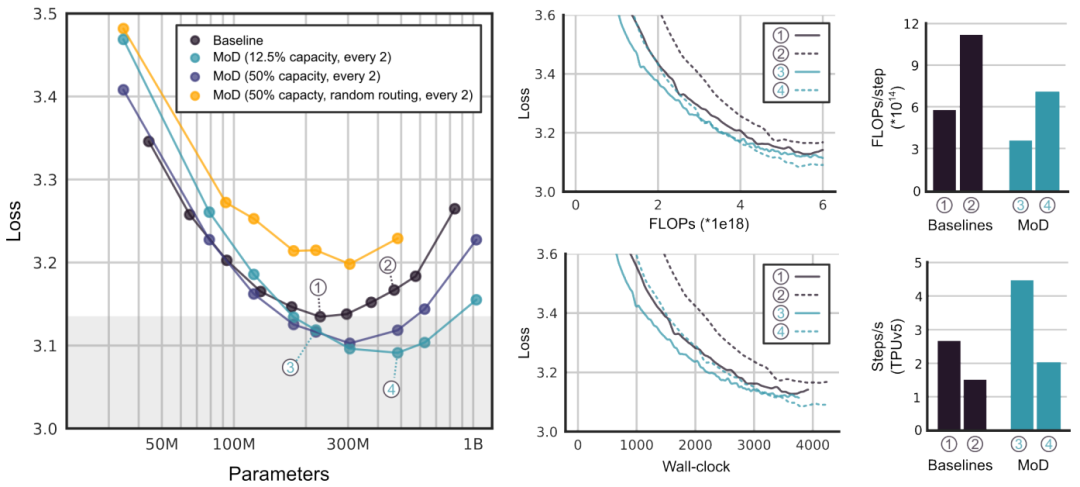
「isoFLOP分析」 如下图所示,存在一些MoD变体在步骤速度上比isoFLOP最优基线模型更快,同时实现更低的训练损失。这些结果表明MoD模型在保持性能的同时,能够实现更高的计算效率