第 2 节:使用 TensorFlow 的计算机视觉高级概念
在本节中,您将基于在上一节中学到的知识来执行复杂的计算机视觉任务,例如视觉搜索,对象检测和神经样式迁移。 您将巩固对神经网络的理解,并使用 TensorFlow 进行许多动手的编码练习。
在本节结束之前,您将能够执行以下操作:
- 对各种神经网络模型有基本的了解,包括 AlexNet,VGG,ResNet,Inception,基于区域的 CNN(RCNN),生成对抗网络(GAN),强化学习和迁移学习(第 5 章)
- 学习一些著名模型用于图像识别和对象检测的技术(第 5 章)
- 使用 Keras 数据生成器和
tf.data将图像及其类别输入到 TensorFlow 模型中(第 6 章) - 使用迁移学习的家具图像开发 TensorFlow 模型,并使用该模型对家具图像进行视觉搜索(第 6 章)
- 对图像执行边界框标注以生成
.xml文件,并将其转换为.txt文件格式,以输入到 YOLO 对象检测器中(第 7 章) - 了解 YOLO 和 RetinaNet 的功能,并学习如何使用 YOLO 检测物体(第 7 章)
- 训练 YOLO 对象检测器并优化其参数以完成训练(第 7 章)
- 使用 TensorFlow DeepLab 执行语义分割,并编写 TensorFlow 代码以在 Google Colab 中进行神经样式迁移(第 8 章)
- 使用 DCGAN 生成人工图像,并使用 OpenCV 进行图像修复(第 8 章)
本节包括以下章节:
- “第 5 章”,“神经网络架构和模型”
- “第 6 章”,“使用迁移学习的视觉搜索”
- “第 7 章”,“使用 YOLO 的对象检测”
- “第 8 章”,“语义分割和神经样式迁移”
五、神经网络架构和模型
卷积神经网络(CNN)是计算机视觉中用于分类和检测对象的最广泛使用的工具。 CNN 通过堆叠许多不同的线性和非线性函数层,将输入图像映射到输出类别或边界框。 线性函数包括卷积,池化,全连接和 softmax 层,而非线性层是激活函数。 神经网络具有许多不同的参数和权重因子,需要针对给定的问题集进行优化。 随机梯度下降和反向传播是训练神经网络的两种方法。
在“第 4 章”,“图像深度学习”中,您学习了一些基本的编码技巧来构建和训练神经网络,并了解了特征映射在不同层次上的视觉转换。 神经网络。 在本章中,您将深入了解神经网络架构和模型背后的理论,并了解诸如神经网络深度饱和,梯度梯度消失,由于大参数集导致的过拟合等关键概念。 这将帮助您为自己的研究目的创建自己的有效模型,并遵循在代码中应用这些理论的下几章的主题。
本章涵盖的主题如下:
- AlexNet 概述
- VGG16 概述
- 初始模型概述
- ResNet 概述
- R-CNN 概述
- 快速 R-CNN 概述
- 更快的 R-CNN 概述
- GAN 概述
- GNN 概述
- 强化学习概述
- 迁移学习概述
AlexNet 概述
AlexNet 由 Alex Krizhevsky,Ilya Sutskever 和 Geoffrey E. Hinton 于 2012 年在名为《深度卷积神经网络的图像网络分类》中引入。 原始论文可以在这个页面中找到。
这是首次成功引入优化的 CNN 模型,以解决有关许多类别(超过 22,000 个)中的大量图像(超过 1,500 万个)的分类的计算机视觉问题。 在 AlexNet 之前,计算机视觉问题主要是通过传统的机器学习方法解决的,该方法通过收集更大的数据集并改进模型和技术以最大程度地减少过拟合来进行逐步改进。
CNN 模型根据前五位错误率对错误率进行分类,前五位错误率是指给定图像的真实类不在前五位预测类中的实例所占的百分比。 AlexNet 以 15.3% 的前五名错误率赢得了 2012 年 ILSVRC(ImageNet 大规模视觉识别挑战赛),与第二名的错误率 26.2% 的前五名遥遥领先。 下图显示了 AlexNet 架构:
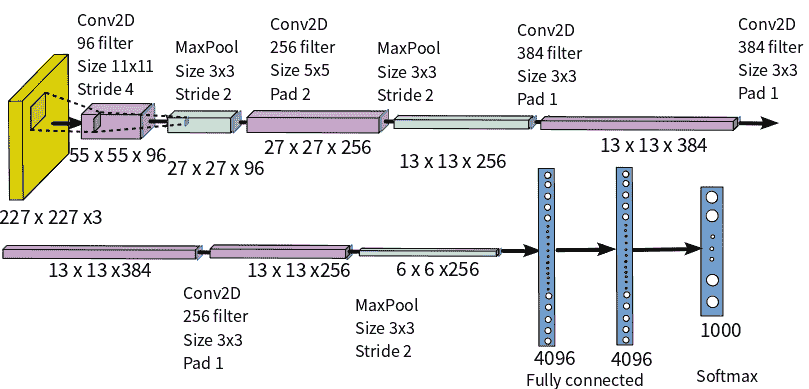
AlexNet 的基本思想总结如下:
- 它包含 8 个学习层-5 个卷积层和 3 个全连接层。
- 它使用大型核过滤器-第一层有 96 个大小为
11 x 11的过滤器,第二层有 256 个大小为11 x 11的过滤器,第三层和第四层有 384 个大小为11 x 11的过滤器,以及第五层有 256 个大小为3 x 5的过滤器。 - ReLU 激活层在每个卷积和全连接层之后应用。 它的训练比 Tanh 快得多。
- 丢弃正则化应用于第一和第二全连接层。
- 两种数据扩充技术可减少过拟合:
- 根据
256 x 256的图像大小创建256 x 256的随机色块,并执行平移和水平反射 - 更改训练图像中 RGB 通道的强度
- 训练是在两个 GPU 上进行的,在 5 或 6 天内要进行 90 个周期的训练,以在两个 Nvidia GeForce 高端 GTX 580 GPU 上进行训练。
- softmax 层的 1,000 个输出映射到 1,000 个 ImageNet 类中的每一个,以预测类的输出。
以下代码导入了运行 TensorFlow 后端所需的所有函数。 此模型导入Sequential模型,它是 Keras 中的逐层模型结构:
from __future__ import print_function
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D, ZeroPadding2D
from keras.layers.normalization import BatchNormalization
from keras.regularizers import l2以下代码加载 CIFAR 数据集。
CIFAR 数据集具有 10 个不同的类别,每个类别有 6,000 张图像。 这些类别包括飞机,汽车,鸟类,猫,鹿,狗,青蛙,马,船和卡车。 TensorFlow 具有内置的逻辑来导入 CIFAR 数据集。
数据集包含训练和测试图像,这些图像将用于开发模型(训练)并验证其结果(测试)。 每个数据集都有两个参数,x和y,分别表示图像的宽度(x)和高度(y):
from keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()神经网络具有许多不同的参数,需要对其进行优化-这些参数也称为模型常数。 对于 AlexNet,这些如下:
batch_size是一次向前或向后通过的32训练示例数。num_classes是2。epochs是100训练将重复的次数。data_augmentation是True。num_predictions是20。
让我们将输入向量转换为二进制类矩阵,因为在此示例中有两个类:
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# Initialize model
model = Sequential()下表描述了不同 AlexNet 模型层的 TensorFlow 代码。 在随后的部分中,将介绍其他模型,但是创建模型的基本思想是相似的:
卷积和合并 1
model.add(Conv2D(96, (11, 11), input_shape=x_train.shape[1:],
padding='same', kernel_regularizer=l2(l2_reg)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2))卷积和合并 5
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(1024, (3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))卷积和合并 2
model.add(Conv2D(256, (5, 5), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))全连接 1
model.add(Flatten())
model.add(Dense(3072))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.5))卷积和合并 3
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(512, (3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))全连接 2
model.add(Dense(4096))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.5))卷积和合并 4
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(1024, (3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))全连接 3
model.add(Dense(num_classes))
model.add(BatchNormalization())
model.add(Activation('softmax'))下表描述了关键模型配置参数。 这应该为您概要概述需要优化以训练神经网络模型的参数:
- 模型编译:一旦开发了模型,下一步就是使用 TensorFlow 编译模型。 对于模型编译,我们需要定义两个参数:
- 损失函数:损失函数确定模型值与实际结果的接近程度。 分类交叉熵是最常见的损失函数,它使用对数值标度来确定损失,其输出值介于 0 到 1 之间,其中小输出表示小差异,大输出表示大差异。 也可以使用的另一个损失函数是 RMS(均方根)损失函数。
- 优化器:优化器微调模型的参数以最小化损失函数。 Adadelta 优化器根据过去梯度的移动窗口微调学习率。 常用的其他优化器是 Adam 优化器和 RMSprop 优化器。
以下代码显示了在 Keras 中进行模型编译时如何使用优化器:
model.compile(loss = 'categorical_crossentropy',
optimizer = keras.optimizers.Adadelta(),
metrics = ['accuracy'])构建模型后,必须先通过前述方法编译模型,然后才能将其用于预测(model.predict())。
请注意,在本部分中,我们研究了 AlexNet,它在 2012 年赢得了 ILSVRC 竞赛。2013 年,开发了一个名为 ZFNet 的 AlexNet 更新版本,它使用 8 层像 AlexNet 一样,但是使用7 x 7过滤器而不是7 x 7过滤器。 在接下来的部分中,我们将发现使用较小的过滤器尺寸可以提高模型的准确率,因为保留了输入图像像素信息。
VGG16 概述
自 2012 年 AlexNet 成功以来,越来越多的研究人员致力于改进 AlexNet 的 CNN 架构以提高准确率。 焦点转移到较小的窗口大小,较小的过滤器和较小的跨步。 VGG16 是由 Karen Simonyan 和 Andrew Zisserman 于 2014 年在《用于大规模图像识别的超深度卷积网络》中引入的。 可以在这个页面上阅读该论文。
在 ILSVRC-2014 中,该模型在 ImageNet 中的前五名测试准确率达到 92.7%。
下图显示了 VGG16 架构:

VGG16 的基本思想总结如下:
- 过滤器的最大尺寸为
3 x 3,最小尺寸为1 x 1。这意味着与 AlexNet 的较大过滤器尺寸和较小的数量相比,使用较小的过滤器尺寸和较大的数量。 与 AlexNet 相比,这减少了参数。 - 对于
3 x 3卷积层,卷积跨步为 1,填充为 1。 最大合并在跨度为 2 的3 x 3窗口上执行。 - 使用了三个非线性 ReLU 函数,而不是每一层中的一个,这通过减少消失梯度问题并使网络能够深入学习,使决策函数更具判别力。 在这里深入学习意味着学习复杂的形状,例如边,特征,边界等。
- 参数总数为 1.38 亿。
初始模型概述
在引入初始层之前,大多数 CNN 架构都具有标准配置-堆叠(连接)卷积,规范化,最大池化和激活层,然后是全连接 softmax 层。 这种架构导致神经网络的深度不断增加,这具有两个主要缺点:
- 过拟合
- 增加计算时间
初始模型通过从密集网络转移到稀疏矩阵并将它们聚类以形成密集子矩阵来解决了这两个问题。
初始模型也称为 GoogLeNet。 它是由 Christian Szegedy,Wei Liu,贾阳清,Pierre Sermanet,Scott Reed,Dragmir Anguelov,Dumitru Erhan,Vincent Vanhoucke 和 Andrew Rabinovich 在名为《Going Deeper with Convolutions》的论文中介绍的。 Inception 的名称来自 Min Lin,陈强和 Shuicheng Yan 的论文《网络中的网络》和著名的网络模因《We need to go deeper》。 以下是指向 Inception 论文和《网络中的网络》论文的链接:
- Inception
- 网络中的网络
在论文《网络中的网络》中,作者没有在输入图像上使用常规的线性过滤器,而是构造了一个微神经网络,并以类似于 CNN 的方式在输入图像上滑动了该神经网络。 通过将这些层中的一些层堆叠在一起,可以构建一个深度神经网络。 微型神经网络(也称为多层感知器)由具有激活函数的多个全连接层组成,如下图所示:
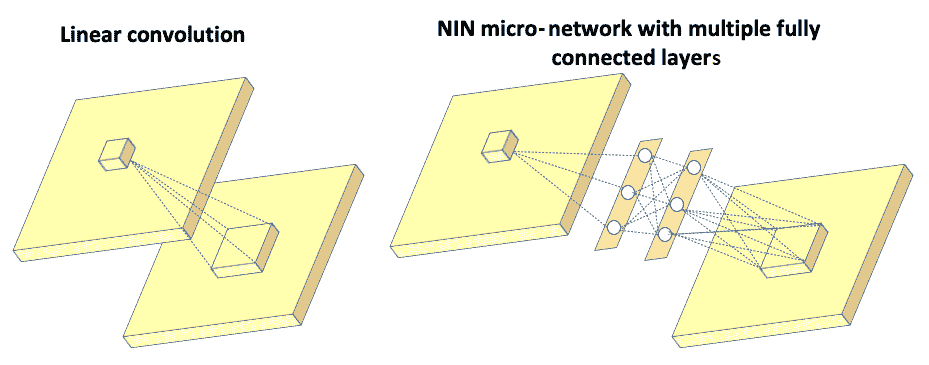
左图显示了传统 CNN 中的线性过滤器,它将输入图像连接到下一层。 右图显示了微网络,该微网络由多个全连接层组成,然后是将输入图像连接到下一层的激活函数。 这里的初始层是 NIN 的逻辑顶点,描述如下:
- 初始架构的主要思想是基于发现如何用易于获得的密集分量(
3 x 3和5 x 5)补充 CNN 中的最佳局部稀疏(并行1 x 1多个)结构。 初始论文的作者找到了答案,方法是将1 x 1卷积与3 x 3、5 x 5卷积和池化层并行使用。 可以认为,附加的1 x 1卷积和 ReLU 相当于 NIN 微网络。1 x 1卷积可作为降维机制,还有助于增加网络的宽度(通过并排堆叠)以及深度。 在同一层(起始层)中同时并行部署具有多个过滤器和池化层的多个卷积会导致该层是稀疏层,并且宽度增加。1 x 1卷积由于较小的核大小而遭受了较少的过拟合。 - 目的是让神经网络在训练网络时学习最佳权重,并自动选择更有用的特征。
- 为了进一步减小尺寸,在
3 x 3和3 x 3卷积之前使用3 x 3卷积,如下图所示:

上图显示,在3 x 3和3 x 3层之前使用3 x 3层会导致尺寸减小约 30%,从 672(左图(a))减少到 480(右图(b)) 。 下图显示了完整的初始网络。 下图的中间部分中描述的完整的初始层太大,以致无法放入一页中,因此已被压缩。 不要在这里尝试阅读图表的每个元素,而应获得重复内容的整体思路。 初始层的关键重复模块已被放大,如下图的顶部和底部所示:

该网络包括以下部分:
1 x 1卷积,带 128 个过滤器,用于减小尺寸和校正线性激活- 具有 1,024 个单元和 ReLU 激活的全连接层
- 丢弃层,其丢弃比率为 70%
- 一个具有 softmax 损失的线性层作为分类器(预测与主分类器相同的 1,000 个分类,但在推理时将其删除)
下图说明了初始网络中的 CNN 过滤器及其对应的连接:

在上图中,深度连接层可以与最大池化层连接,也可以直接与1 x 1卷积层连接。 无论哪种方式,随后的计算都遵循与上图所示相同的模式。
GoogLeNet 概述
初始网络(也称为 GoogLeNet)在区域卷积神经网络(R-CNN)的两阶段提议(基于颜色,纹理,大小和形状的区域提议,然后是 CNN 用于分类)的基础上进行了改进。
首先,它以改进的 CNN 替代了 AlexNet。 接下来,通过将选择性搜索(在 R-CNN 中)方法与用于更高对象边界框召回率的多框预测相结合,改进了区域提议步骤。 区域提议书减少了约 60%(从 2,000 减少到 1200),而覆盖率从 92% 增加到 93%,从而使单个模型案例的平均平均精度提高了 1%。 总体而言,准确率从 40% 提高到 43.9%。
ResNet 概述
ResNet 由何凯敏,张向宇,任少卿和孙健在题为《图像识别的深度残差学习》的论文中介绍,目的是解决深度神经网络的精度下降问题。这种降级不是由过拟合引起的,而是由以下事实造成的:在某个临界深度之后,输出会松散输入的信息,因此输入和输出之间的相关性开始发散,从而导致精度增加。 可以在这个页面中找到该论文。
ResNet-34 的前五位验证错误为 5.71%,优于 BN-inception 和 VGG。 ResNet-152 的前五位验证错误为 4.49%。 由六个不同深度的模型组成的集合实现了 3.57% 的前五个验证误差,并在 ILSVRC-2015 中获得了第一名。 ILSVRC 代表 ImageNet 大规模视觉识别竞赛; 它评估了 2010 年至 2017 年的目标检测和图像分类算法。
ResNet 的主要功能描述如下:
- 通过引入深层的残差学习框架来解决降级问题。
- 该框架引入了快捷方式或跳过连接(跳过一个或多个层)的概念。
- 输入和下一层之间的基础映射为
H(x)。 - 非线性层为
F(x) = H(x) – x,可以将其重组为H(x) = F(x) + x,其中x是身份映射。 - 快捷方式连接仅执行身份映射,其输出将添加到堆叠层的输出中(请参见下图):

上图具有以下功能:
F(x) + x操作是通过快捷连接和元素添加来执行的。- 身份快捷方式连接既不会增加额外的参数,也不会增加计算复杂度。
下图显示了完整的 ResNet 模型:

与**视觉几何组(VGG)**网络相比,此处显示的 ResNet 模型具有更少的过滤器和更低的复杂度。 不使用丢弃。 以下屏幕快照显示了各种神经网络模型之间的表现比较:

上图显示了以下内容:
- ImageNet 大规模视觉识别挑战(ILSVRC)的各种 CNN 架构的得分和层数。
- 分数越低,表现越好。
- AlexNet 的得分比其任何前任都要好得多,然后在随后的每一年中,随着层数越来越大,CNN 的质量不断提高。
- 如此处所述,ResNet 得分最高,比 AlexNet 高出四倍。
R-CNN 概述
基于区域的 CNN(R-CNN)由 Ross Girshick,Jeff Donahue,Trevor Darrell 和 Jitendra Malik 在题为《可用于精确的对象检测和语义分割丰富特征层次结构》的论文中进行了介绍。 它是一种简单且可扩展的对象检测算法,与 VOC2012 上的最佳结果相比,其平均平均精度提高了 30% 以上。 可以在这里阅读本文。
VOC 代表视觉对象类,而 PASCAL 代表模式分析统计建模和计算学习。 从 2005 年到 2012 年,PASCAL VOC 在对象类识别方面面临挑战。 PASCAL VOC 标注广泛用于对象检测,并且使用.xml格式。
整个对象检测模型分为图像分割,基于选择性搜索的区域提议,使用 CNN 的特征提取和分类以及使用**支持向量机(SVM)**的包围盒形成,如下图所示 :
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ID6qrUKN-1681784515017)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/master-cv-tf-2x/img/d3911e10-d7a2-4ccc-8f79-da02cad55582.png)]
上图显示了将道路上的汽车和自行车的输入图像转换为对象检测边界框的各个步骤。
在以下部分中,将详细描述每个步骤。
图像分割
图像分割是图像在多个区域中的表示。 分割图像中的每个区域都具有相似的特征,例如颜色,纹理和强度。
基于聚类的分割
K-means 是一种无监督的机器学习技术,它基于质心将相似的数据分为几组。K 均值聚类算法的关键步骤概述如下:
- 选择
K数据点作为任意位置的群集的初始数目。 - 找到每个聚类质心和每个像素之间的距离,并将其分配给最近的聚类。
- 更新每个群集的平均值。
- 通过更改群集质心,重复此过程,直到最小化每个像素及其关联群集之间的总距离。
基于图的分割
有许多基于图的分割方法可用,但此处为 R-CNN 描述的一种方法是 Pedro Felzenszwalb 和 Daniel Huttenlocher 在题为《基于图的高效图像分割》的论文中介绍的方法。 可以在这个页面上阅读该论文。
此方法涉及将图像表示为图(在本章的“GNN 概述”部分中提供了详细说明),然后从图中选择边,其中每个像素都链接到图中的节点,并且通过边连接到相邻像素。 边上的权重代表像素之间的差异。 分割标准基于被边界分开的图像的相邻区域的变化程度。 通过评估阈值函数来定义边界,该阈值函数表示与相邻像素之间的强度差相比,沿着边界的像素之间的强度差。 基于区域之间边界的存在,将分割定义为粗略或精细。
选择性搜索
对象检测的主要挑战是在图像中找到物体的精确位置。 图像中多个对象在不同的空间方向上很难找到图像中对象的边界。 例如,一个物体可以被遮盖并且只能部分可见。例如,一个人站在汽车后面; 我们可以看到汽车和汽车上方的人的身体。 选择性搜索用于解决此问题。 它将整个图像分为许多分割区域。 然后,它使用自下而上的方法将相似的区域合并为较大的区域。 选择性搜索使用生成的区域来找到对象的位置。 选择性搜索使用贪婪算法,根据大小,颜色和纹理将区域迭代地分组在一起。 选择性搜索中使用的步骤说明如下:
- 首先,对两个最相似的区域进行评估并分组在一起。
- 接下来,在所得区域和新区域之间计算新的相似度以形成新的组。
- 重复对最相似区域进行分组的过程,直到该区域覆盖整个图像为止。
选择搜索之后是区域提议,下面的部分将对此进行描述。
区域提议
在此阶段,该算法使用前面描述的选择性搜索方法来提取大约 2,000 个与类别无关的区域提议。 与类别无关的区域提议用于识别图像中的多个区域,以使每个对象都能由图像中的至少一个区域很好地表示。 人类通过在图像中定位对象来自然地做到这一点,但是对于机器而言,需要确定对象的位置,然后将其与图像中的适当区域进行匹配以检测对象。
与图像分类不同,检测涉及图像定位,因此可以创建一个适当的区域来包围对象以检测该区域内的特征。 基于选择性搜索方法选择适当的区域,该方法通过基于颜色进行搜索,然后基于纹理,大小和形状进行搜索来计算相似区域。
特征提取
特征提取是将相似特征(例如边,角和线)分组为特征向量。 特征向量将图像的维数从227 x 227(约 51,529)降低到 4,096。 每个区域提议,无论其大小如何,都首先通过膨胀和翘曲将其转换为227 x 227的大小。 这是必需的,因为 AlexNet 的输入图像大小为227 x 227。使用 AlexNet 从每个区域提取 4,096 个特征向量。 特征矩阵为4,096 x 2,000,因为每个图像都有 2,000 个区域提议。
原则上,只要修改输入图像的大小以适合网络的图像大小,R-CNN 可以采用任何 CNN 模型(例如 AlexNet,ResNet,Inception 或 VGG)作为输入。 R-CNN 的作者比较了 AlexNet 和 VGG16 作为 R-CNN 的输入,发现 VGG16 的准确率高 8%,但比 AlexNet 的准确率高 7 倍。
图像分类
通过 AlexNet 提取特征后,图像的分类包括将特征向量通过特定于类别的线性 SVM 进行分类,以对区域提议中对象的存在进行分类。 使用 SVM 是一种受监督的机器学习方法,该方法将权重和偏差分配给每个特征向量,然后画一条线将对象分成特定的类。 通过确定每个向量与直线的距离,然后定位直线,使间距最大,从而完成分隔。
边界框回归
边界框回归可预测对象在图像中的位置。 在支持向量机之后,建立线性回归模型以预测边界框检测窗口的位置和大小。 对象的边界框由四个锚定值[x,y,w,h]定义,其中x是边界框原点的x坐标,y是边界框原点的y坐标,w是边框的宽度,h是边框的高度。
回归技术试图通过调整四个锚定值中的每个锚定值,将预测值与地面真实(目标)值进行比较,以使边界框预测中的误差最小化。
快速 R-CNN 概述
R-CNN 在对象检测方面比以前的任何一种方法都有了更显着的改进,但是它很慢,因为它对每个区域提议都对 CNN 进行了前向传递。 此外,训练是一个多阶段流程,包括首先针对区域提议优化 CNN,然后运行 SVM 进行对象分类,然后使用包围盒回归器绘制包围盒。 也是 R-CNN 的创建者的 Ross Girschick 提出了一种称为快速 R-CNN 的模型,以使用单阶段训练方法来改进检测。 下图显示了快速 R-CNN 的架构:

快速 R-CNN 中使用的步骤如下:
- 快速 R-CNN 网络使用多个卷积和最大池化层处理整个图像,以生成特征映射。
- 将特征映射输入到选择性搜索中以生成区域提议。
- 对于每个区域提议,使用兴趣区域(RoI)最大池来提取固定长度的特征向量(
h = 7 x w = 7)。 - 此特征向量值成为由两个分支分隔的全连接(FC)层的输入:
- 用于类别概率的 Softmax
- 每个对象类别的边界框位置和大小(
x,y,宽度,高度)。
所有网络权重都使用反向传播进行训练,并且在前向和后向路径之间共享计算和内存,以进行损失和权重计算; 这将大型网络中的训练时间从 84 小时(R-CNN)减少到 9.5 小时(快速 R-CNN)。 快速 R-CNN 使用 softmax 分类器代替 SVM(R-CNN)。 下表针对小型(S),中型(M)和大型(L)网络显示 softmax 的平均平均精度略胜于 SVM 的平均精度:
VOC07 | S | M | L |
|---|---|---|---|
SVM | 56.3 | 58.7 | 66.8 |
Softmax | 57.1 | 59.2 | 66.9 |
SVM 和 softmax 之间的结果差异很小,这说明与使用 SVM 的多阶段训练相比,使用 softmax 的单次微调就足够了。 提案数量超过 4,000 个时,导致平均平均精度降低了大约 1%,而当提案数量达到 2,000 至 4,000 个时,实际上使精度提高了大约 0.5%。
更快的 R-CNN 概述
R-CNN 和 Fast R-CNN 都依赖于选择性搜索方法来开发 2,000 个区域的方案,这导致每幅图像的检测速度为 2 秒,而最有效的检测方法为 0.2 秒。 任少渠,何开明,罗斯·吉尔希克和孙健写了一篇名为 《Faster R-CNN:借助区域提议网络实现实时目标检测》的论文,以提高目标检测的速度和准确率。 您可以在这里阅读本文。
下图显示了更快的 R-CNN 的架构:

关键概念显示在以下列表中:
- 将输入图像引入区域提议网络(RPN),该网络为给定图像输出一组矩形区域提议。
- RPN 与最新的对象检测网络共享卷积层。
- RPN 通过反向传播和随机梯度下降(SGD)进行训练。
快速 R-CNN 中的对象检测网络类似于快速 R-CNN。 下图显示了使用更快的 R-CNN 进行的一些对象检测输出:

上图显示了使用更快的 R-CNN 模型进行的推理。 在“第 10 章”,“使用 R-CNN,SSD 和 R-FCN”进行对象检测中,您将学习如何自己生成这种类型的图形。 左图是使用 TensorFlow Hub 中的预训练模型生成的,而右图是通过训练自己的图像然后开发自己的模型来生成的。
通过遵循以下列表中概述的技术,可以获得上图中所示的高精度:
- 在两个网络之间共享卷积层:RPN 用于区域提议,快速 R-CNN 用于检测。
- 对于更快的 R-CNN,输入图像大小为
1,000 x 600。 - 通过在卷积特征映射输出上滑动大小为
60 x 40的小窗口来生成 RPN。 - 每个滑动窗口都映射到 9 个锚点框(3 个比例,框区域分别为 128、256 和 512 像素,而 3 个比例为 1:1、1:2 和 2:1)。
- 每个锚框都映射到一个区域提议。
- 每个滑动窗口都映射到 ZF 的 256-D 特征向量和 VGG 网络的 512-D 特征向量。
- 然后将此向量输入到两个全连接层中-框回归层和框分类层。
- 区域提议总数为 21,500(
60 x 40 x 9)。
为了训练 RPN,基于与训练数据重叠的交并比(IoU)为每个锚定框分配一个二进制类别标签。 IoU 用于测量对象检测的准确率。 在“第 7 章”,“使用 YOLO 的对象检测”中详细描述。 现在,您已经足够知道 IoU 是以两个边界框之间的重叠面积与其联合面积之比来衡量的。 这意味着IOU = 1,这意味着两个完整的边界框重叠,因此您只能看到一个,而当IoU = 0时,这意味着两个边界框彼此完全分开。
二进制类级别具有正样本和负样本,它们具有以下属性:
- 正样本:IoU 为最大值或大于 0.7
- 负样本:IoU 小于 0.3
用于回归的特征具有相同的空间大小(高度和宽度)。 在实际图像中,特征尺寸可以不同。 通过使用具有不同回归比例和纵横比的可变包围盒大小来考虑到这一点。 RPN 和对象检测之间的卷积特征使用以下原则共享:
- RPN 将二进制类别用于训练。
- 检测网络通过快速 R-CNN 方法进行训练,并通过使用 RPN 训练的 ImageNet 预训练模型进行初始化。
- 通过保持共享卷积层固定并仅微调 RPN 唯一的层来初始化 RPN 训练。
- 前面的步骤导致两个网络的共享。
- 最后,通过保持共享卷积层固定,可以对快速 R-CNN 的全连接层进行微调。
- 所有上述步骤的组合导致两个网络共享相同的卷积层。
下表显示了 R-CNN,快速 R-CNN 和更快的 R-CNN 之间的比较:
参数 | R-CNN | 快速 R-CNN | 更快的 R-CNN |
|---|---|---|---|
输入值 | 图片 | 图片 | 图片 |
输入图像处理 | 基于像素相似度的图像分割 | 输入图像被馈送到 CNN 以生成卷积特征映射。 | 输入图像被馈送到 CNN 以生成卷积特征映射。 |
区域提议 | 使用选择性搜索在分割的图像上生成 2K 区域提议。 | 使用卷积特征映射的选择性搜索生成 2K 区域提议。 | 区域提议是使用区域提议网络(RPN)生成的。 这个 CNN 使用60 x 40的滑动窗口,用于带有 9 个锚点框(3 个比例和 3 个宽高比)的特征映射的每个位置。 |
变形为固定大小 | 从区域提议中,每个区域都将变形为固定大小,以输入到 CNN。 | 使用 RoI 池化层中的最大池化,将区域提议扭曲为固定大小的正方形。 | 使用 RoI 池化层将区域提议扭曲为固定大小的正方形。 |
特征提取 | 每次将每个图像固定大小的 2K 变形区域提议送入 CNN。 | 2K 扭曲区域被馈送到两个分支,每个分支都包含一个全连接层。 | 2K 扭曲区域被馈送到全连接层。 |
侦测 | CNN 的输出传递到 SVM,以分类到边界框回归器以生成边界框。 | 全连接层的一个输出传递到 softmax 层进行分类,另一个输出传递到包围盒回归器以生成包围盒。 | 全连接层的一个输出传递到 softmax 层进行分类,另一个输出传递到包围盒回归器以生成包围盒。 |
CNN 类型 | AlexNet | VGG 16 | ZFNet 或 VGGNet。 ZFNet 是 AlexNet 的修改版本。 |
区域提议 | 选择性搜索用于生成约 2,000 个区域提议。 | 选择性搜索用于生成约 2,000 个区域提议。 | CNN 用于生成约 21,500 个区域提议(60 x 40 x 9)。 |
卷积运算 | 每个图像进行 2K 次卷积操作。 | 每个图像进行一次卷积操作。 | 每个图像进行一次卷积操作。 |
区域提议和检测 | 区域提议和检测是分离的。 | 区域提议和检测是分离的。 | 区域提议和检测是耦合的。 |
训练时间 | 84 小时 | 9 小时 | 150 小时 |
测试时间 | 49 秒 | 2.43 秒 | 0.2 秒 |
mAP(VOC 2007) | 66 | 66.9 | 66.9 |
上表清楚地显示了 R-CNN 算法的发展以及用于提高 R-CNN 算法准确率的方法。 这是我们从上表中学到的一些关键点:
- 图像分割和选择性搜索以确定像素相似度是一项耗时的操作,因为该操作是逐像素操作。
- 与选择搜索方法相比,使用滑动窗口的 CNN 操作在生成区域提议时要快得多。
- 将 CNN 应用于整个图像要比将 CNN 应用于图像中的区域,然后对给定图像重复此过程 2,000 次要快得多。
GAN 概述
生成对抗网络(GAN)是一类 CNN,可以学习估计数据的概率分布。 GAN 由两个相互竞争的相互连接的神经网络组成,称为生成器和判别器。 生成器基于图像特征的噪声输入生成人工图像,判别器将人工图像与真实图像进行比较,以确定图像真实的可能性。 概率信息将传递到图像输入以在下一阶段学习。 下图说明了 GAN 的机制:

GAN 算法的分步说明如下:
- 给定训练集
z,生成器网络会获取代表图像特征的随机向量,并通过 CNN 运行以生成人工图像G(z)。 - 判别器网络是一个二分类器。 它获取真实图像和人造图像,并生成创建人造图像的概率
P(Z)。 - 判别器将概率信息提供给生成器,生成器使用该信息来改进其对图像
G(z)的预测。
二分类器损失函数称为交叉熵损失函数,并表示为-ylog(p) - (1 - y)log(1 - p),其中p是概率,y是期望值。
- 判别器目标函数:

- 生成器目标函数:

GAN 已经存在许多类型(超过 20 种),并且几乎每个月都会开发出更多类型的 GAN。 以下列表涵盖了 GAN 的两个主要重要变化:
- DCGAN(深度卷积 GAN):如原始 GAN 中所述,CNN 既用于判别器,又用于生成器。
- CGAN(条件 GAN):表示标签的条件向量用作生成网络和判别网络的附加输入。 噪声与标记向量一起被添加到生成网络中,从而检测标记中的变化。
GAN 的一些实际用例如下:
- 生成人造人脸图像和图像数据集
- 合并图像以形成新的数据集
- 生成卡通人物
- 从 2D 图像生成 3D 人脸和对象
- 语义到图像翻译
- 从不同的彩色图像生成一组彩色图像
- 文字到图片翻译
- 人体姿势估计
- 照片编辑和修复
GNN 概述
图神经网络(GNN)将 CNN 学习扩展到图数据。 可以将图表示为节点和边的组合,其中节点代表图的特征,边连接相邻节点,如下图所示:

在此图像中,节点用实心白色点表示,边用连接点的线表示。
以下方程式描述了图的关键参数:
H = (N, E)N = {n[1], n[2], n[3], ...}E ⊆ N x N
将图转换为由节点,边和节点之间的关系组成的向量的过程称为图嵌入。 嵌入向量可以由以下等式表示:

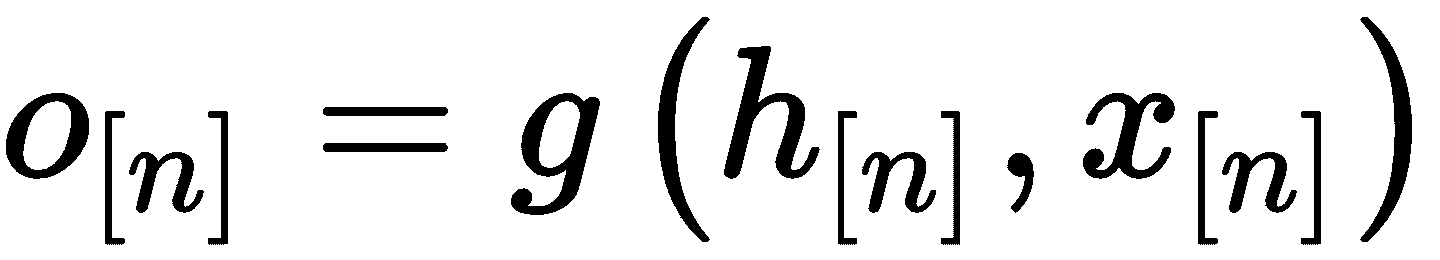
以下列表描述了上述方程式的元素:
h[n]为当前节点n的状态嵌入h_ne[n]为节点n邻域的状态嵌入x[n]为节点n的特征xe[n]为节点n的边的特征x_ne[n]为节点n的邻域特征o[n]为节点n的输出
如果H,X是通过堆叠所有状态和所有特征而构建的向量,则可以为 GNN 迭代状态写以下方程式:

根据 GNN 的类型,前面的一般等式可以导出为各种形式。 主要有两种分类:频谱 GNN 和非频谱 GNN。
频谱神经网络
频谱 GNN 首先由 Joan Bruna,Wojciech Zaremba,Arthus Szlam 和 Yann LeCun 在题为《频谱网络和图上的深局部连接网络》的论文中提出。 您可以在这个页面中找到该论文的详细信息。
频谱 GNN 是傅立叶域中的卷积。 频谱 GNN 可用以下公式表示:

以下列表描述了上述方程式的元素:
g[θ]为过滤器参数,也可以视为卷积权重x为输入信号U为标准化图拉普拉斯L = I[N] - D^(-1/2) A D^(-1/2) = U Λ U^T的特征向量矩阵
Kipf 和 Welling(在其文章《使用图卷积网络进行半监督分类》中)进一步简化了此方法,以解决诸如以下这样的过拟合问题:

使用以下重新规范化,可以进一步简化此操作:

在此,σ代表激活函数。
下图说明了 GNN 的架构:

GNN 层汇总了来自其邻居的特征信息,并应用 ReLU 激活,合并以及全连接层和 softmax 层对图像中的不同特征进行分类。
强化学习概述
强化学习是机器学习的一种类型,其中智能体根据当前累积的奖励信号的反馈来预测奖励(或结果),从而学会在当前环境中采取行动。 由克里斯托弗·沃特金斯(Christopher Watkins)在题为《从延迟奖励中学习》的论文中介绍的Q-学习是强化学习中最受欢迎的算法之一。Q表示质量-这是在产生奖励时特定行为的值:
- 在每个学习状态下,
Q表存储状态,操作和相应奖励的值。 - 智能体在
Q表中进行搜索,以执行使长期累积奖励最大化的下一个操作。 - 强化学习与有监督学习和无监督学习的主要不同之处在于:它不需要输入标签(有监督)或基础结构(无监督)就可以将对象分类。
下图说明了强化学习的概念。 智能体在某种状态下行动以产生行动,从而产生奖励。 动作值会随着时间的推移而不断提高,以最大化回报:

智能体以某种状态(s[t])启动,观察一系列观察结果,采取行动(a[t])并接收奖励。
最大化以下累积值函数,以在Q-学习方法中找到所需的输出:

以下列表描述了上述方程式的关键特征:
Q(s[t], a[t])是旧值α是学习率γ在立即奖励和预期延迟奖励之间进行折衷的折扣因子,α是学习率r[t]是奖励- 最大的
Q(s[t+1], a)是学习值
由于Q学习包括对估计的动作值的最大化步长,因此它倾向于高估值。
在强化学习中,可以使用卷积网络来创建能够在复杂情况下获得积极回报的主体行为。 这个概念最早由 Mnih 等人提出,在 2015 年发表在题为《通过深度强化学习进行人为控制》的文章中。该文章可以在这个页面中找到本文的详细信息。
这包括三个卷积层和一个全连接隐藏层。 请注意,在强化学习中,卷积网络得出的解释与监督学习中得出的解释不同。 在监督学习中,CNN 用于将图像分类为不同的类别。 在强化学习中,图片代表一种状态,而 CNN 用于创建智能体在该状态下执行的动作。
迁移学习概述
到目前为止,我们已经学会了通过隔离设计工作来解决特定任务来构造 CNN 架构。 神经网络模型是深度密集型的,需要大量的训练数据,训练运行以及进行调优的专家知识才能获得高精度; 但是,作为人类,我们不会从头开始学习所有内容,而是向他人学习,而从云(互联网)学习。 当数据不足以供我们尝试分析的新类使用时,迁移学习非常有用,但是在相似类中存在大量预先存在的数据。 每个 CNN 模型(AlexNet,VGG16,ResNet 和 Inception)都已在 ImageNet ILSVRC 比赛数据集中进行了训练。 ImageNet 是一个数据集,在 22,000 个类别中包含超过 1500 万张带标签的图像。 ILSVRC 使用 ImageNet 的子集,在 1,000 个类别中的每个类别中都有大约 1,000 个图像。
在迁移学习中,可以修改针对其他情况开发的预训练模型,以用于我们的特定情况来预测我们自己的类。 我们的想法是选择我们已经研究过的 CNN 架构,例如 AlexNet,VGG16,ResNet 和 Inception,冻结一层或两层,更改一些权重,并输入我们自己的数据来对类进行预测。 在“第 4 章”,“图像深度学习”中,我们了解了 CNN 如何查看和解释图像。
这些学习将用于构建迁移学习,因此,让我们在“第 4 章”,“图像深度学习”中总结在 CNN 可视化中学习的一些要点:
- 前几层基本上是汽车的通用特征(例如边检测,斑点检测等),中间层将边结合起来形成汽车的特征,例如轮胎,门把手,灯,仪表板, 等等,最后几层是非常抽象的,并且对于特定对象非常特定。
- 全连接层将其上一层的输出展平为单个向量,将其乘以不同的权重,然后在其上应用激活系数。 它使用机器学习支持向量机(SVM)类型的方法进行分类。
现在,我们理解了这些概念,我们将能够理解以下常用的迁移学习方法:
- 删除并交换 softmax 层:
- 使用 TensorFlow 取得在 ImageNet 上预先训练的 CNN,例如 VGG16,AlexNet,ResNet 或 Inception。
- 删除最后一个 softmax 层,并将 CNN 的其余部分视为新数据集的固定特征提取器。
- 用定义自己的类数的自定义 softmax 替换 softmax 层,并使用数据集训练结果模型。
- 微调 ConvNet。 为了减少过拟合,请保持一些较早的层固定,并且仅微调网络的较高层部分。 正如我们在“第 4 章”,“图像深度学习”的可视化示例中所看到的那样,最后一层非常抽象,并且针对特定数据集进行了调整,因此冻结整个模型,并将“步骤 1”的 softmax 更改为新的 softmax 可能会导致更高的准确率。 为了提高准确率,最好从 CNN 的中间训练您的自定义图像,这样,在全连接层之前的最后几层将具有特定于您的应用的特征,这将导致更高的预测准确率。 在“第 6 章”,“使用迁移学习的视觉搜索”中,我们将对此概念进行编码,并看到从 CNN 中部附近开始训练的准确率提高。
总结
在本章中,我们了解了不同卷积网络(ConvNet)的架构,以及如何将 ConvNet 的不同层堆叠在一起以将各种输入分类为预定义的类。 我们了解了不同的图像分类模型,例如 AlexNet,VGGNet,Inception 和 ResNet,它们为何不同,它们解决了哪些问题以及它们的整体相似性。
我们了解了对象检测方法(例如 R-CNN),以及如何将其随时间转换为快速,快速的 R-CNN 用于边界框检测。 本章介绍了两个新模型 GAN 和 GNN,作为两个新的神经网络集。 本章最后介绍了强化学习和迁移学习。 我们了解到,在强化学习中,智能体与环境交互以基于奖励学习最佳策略(例如,在十字路口向左或向右转),而在迁移学习中,通过优化 CNN 的后续层,预先训练的模型(例如 VGG16)可以根据新数据派生新类。
在下一章中,您将学习如何使用迁移学习来训练自己的神经网络,然后使用受过训练的网络进行视觉搜索。
六、使用迁移学习的视觉搜索
视觉搜索是一种显示与用户上传到零售网站的图像相似的图像的方法。 通过使用 CNN 将图像转换为特征向量,可以找到相似的图像。 视觉搜索在网上购物中具有许多应用,因为它补充了文本搜索,从而更好地表达了用户对产品的选择,并且更加精致。 购物者喜欢视觉发现,并发现它是传统购物体验所没有的独特东西。
在本章中,我们将使用在“第 4 章”,“图像深度学习”和“第 5 章”,“神经网络架构和模型”中学习的深度神经网络的概念。我们将使用迁移学习为图像类别开发神经网络模型,并将其应用于视觉搜索。 本章中的练习将帮助您开发足够的实践知识,以编写自己的神经网络代码和迁移学习。
本章涵盖的主题如下:
- 使用 TensorFlow 编码深度学习模型
- 使用 TensorFlow 开发迁移学习模型
- 了解视觉搜索的架构和应用
- 使用
tf.data处理视觉搜索输入数据管道
使用 TensorFlow 编码深度学习模型
我们在“第 5 章”,“神经网络架构和模型”中了解了各种深度学习模型的架构。 在本节中,我们将学习如何使用 TensorFlow/Keras 加载图像,浏览和预处理数据,然后应用三个 CNN 模型(VGG16,ResNet 和 Inception)的预训练权重来预测对象类别。
请注意,由于我们不是在构建模型,而是将使用已构建的模型(即具有预先训练的权重的模型)来预测图像类别,因此本部分不需要训练。
本部分的代码可以在以下位置找到。
让我们深入研究代码并了解其每一行的目的。
下载权重
下载权重的代码如下:
from tensorflow.keras.applications import VGG16
from keras.applications.vgg16 import preprocess_input
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input
from tensorflow.keras.applications import InceptionV3
from keras.applications.inception_v3 import preprocess_input前面的代码执行以下两个任务:
- 权重将作为以下代码的输出的一部分按以下方式下载:
Download VGG16 weight, the *.h5 fileDownload Resnet50 weight, the *.h5 fileDownload InceptionV3 weight, the *.h5 file
- 它对图像进行预处理,以将当前图像标准化为
ImageNet RGB数据集。 由于该模型是在ImageNet数据集上开发的,因此,如果没有此步骤,该模型可能会导致错误的类预测。
解码预测
ImageNet 数据具有 1,000 个不同的类别。 诸如在 ImageNet 上训练的 Inception 之类的神经网络将以整数形式输出该类。 我们需要使用解码将整数转换为相应的类名称。 例如,如果输出的整数值为311,则需要解码311的含义。 通过解码,我们将知道311对应于折叠椅。
用于解码预测的代码如下:
from tensorflow.keras.applications.vgg16 import decode_predictions
from tensorflow.keras.applications.resnet50 import decode_predictions
from tensorflow.keras.applications.inception_v3 import decode_predictions前面的代码使用decode_predictions命令将类整数映射到类名称。 没有此步骤,您将无法预测类名。
导入其他常用库
本节是关于导入 Keras 和 Python 的通用包的。 Keras preprocessing是 Keras 的图像处理模块。 导入其他常见库的代码如下所示:
from keras.preprocessing import image
import numpy as np
import matplotlib.pyplot as plt
import os
from os import listdir您可以在前面的代码中观察以下内容:
- 我们加载了 Keras 图像预处理库。
numpy是 Python 数组处理库。matplotlib是 Python 绘图库。- 需要
os模块才能访问输入文件的目录。
建立模型
在本节中,我们将导入一个模型。 用于模型构建的代码如下所示(每个代码段的说明都在代码下方):
model = Modelx(weights='imagenet', include_top=True,input_shape=(img_height, img_width, 3))
Modelx = VGG16 or ResNet50 or InceptionV3模型构建具有三个重要参数:
weights是我们在以前下载的 ImageNet 图像上使用的预训练模型。include_top参数指示是否应包含最终的密集层。 对于预训练模型的类别预测,始终为True; 但是,在本章的后面部分(“使用 TensorFlow 开发迁移学习模型”)中,我们将学习到,在迁移学习期间,此参数设置为False仅包含卷积层。input_shape是通道的高度,宽度和数量。 由于我们正在处理彩色图像,因此通道数设置为3。
从目录输入图像
从目录输入图像的代码如下所示:
folder_path = '/home/…/visual_search/imagecnn/'
images = os.listdir(folder_path)
fig = plt.figure(figsize=(8,8))前面的代码指定图像文件夹路径,并定义了图像属性,以便能够在以后的部分中下载图像。 它还将图像尺寸指定为8 x 8。
使用 TensorFlow Keras 导入并处理多个图像的循环
本节介绍如何批量导入多个图像以一起处理所有图像,而不是一个一个地导入它们。 这是学习的一项关键技能,因为在大多数生产应用中,您不会一步一步地导入图像。 使用 TensorFlow Keras 导入和处理多个图像的循环函数的代码如下:
for image1 in images:
i+=1
im = image.load_img(folder_path+image1, target_size=(224, 224))
img_data = image.img_to_array(im)
img_data = np.expand_dims(img_data, axis=0)
img_data = preprocess_input(img_data)
resnet_feature = model_resnet.predict(img_data,verbose=0)
label = decode_predictions(resnet_feature)
label = label[0][0]
fig.add_subplot(rows,columns,i)
fig.subplots_adjust(hspace=.5)
plt.imshow(im)
stringprint ="%.1f" % round(label[2]*100,1)
plt.title(label[1] + " " + str(stringprint) + "%")
plt.show()前面的代码执行以下步骤:
- 以
image1作为循环的中间值,循环遍历images属性。 -
image.load函数将每个新图像添加到文件夹路径。 请注意,对于 VGG16 和 ResNet,目标大小是224,对于启动,目标大小是299。 - 使用 NumPy 数组将图像转换为数组函数并扩展其尺寸,然后按照“下载权重”部分中的说明应用
preprocessing函数。 - 接下来,它使用
model.predict()函数计算特征向量。 - 然后,预测解码类别标签名称。
-
label函数存储为数组,并且具有两个元素:类名和置信度%。 - 接下来的几节涉及使用
matplotlib库进行绘图:
fig.add_subplot具有三个元素:rows,columns和i–例如,总共 9 幅图像分为三列三行,i项将从1变为9,1是第一张图片,9是最后一张图片。fig.subplots_adjust在图像之间添加垂直空间。plt.title将标题添加到每个图像。
请注意,完整的代码可以在本书的 GitHub 链接中找到。
为了验证模型,将九张不同的图像存储在目录中,并逐个通过每个模型以生成预测。 下表显示了使用三种不同的神经网络模型对每个目标图像的最终预测输出:
目标图片 | VGG16 | ResNet | Inception |
|---|---|---|---|
餐桌 | 餐桌 58% | 台球桌 30.1% | 桌子 51% |
炒锅 | 钢包 55% | 钢包 87% | 钢包 30% |
沙发 | 单人沙发 42% | 单人沙发 77% | 单人沙发 58% |
床 | 单人沙发 35% | 四海报 53% | 单人沙发 44% |
水壶 | 水壶 93% | 水壶 77% | 水壶 98% |
行李 | 折叠椅 39% | 背包 66% | 邮袋 35% |
背包 | 背包 99.9% | 背包 99.9% | 背包 66% |
长椅 | 单人沙发 79% | 单人沙发 20% | 单人沙发 48% |
越野车 | 小型货车 74% | 小型货车 98% | 小型货车 52% |
下图显示了九个类的 VGG16 输出:

在上图中,您可以观察到以下内容:
- 每个图像尺寸为
224 x 224,标签的顶部打印有置信度百分比。 - 三种错误的预测:炒锅(预测为钢包),床(预测为工作室沙发)和行李(预测为折叠椅)。
下图显示了这九类的 ResNet 预测输出:

在上图中,您可以观察到以下内容:
- 每个图像尺寸为
224 x 224,标签的顶部打印有置信度百分比。 - 有两个错误的预测:炒锅(预测为钢包)和行李(预测为背包)。
下图显示了这九类的初始预测输出:

由此,您可以观察到以下内容:
- 每个图像尺寸为
224 x 224,标签的顶部打印有置信度百分比。 - 有两个错误的预测:炒锅(预测为钢包)和床(预测为工作室沙发)。
通过本练习,我们现在了解了如何在不训练单个图像的情况下使用预先训练的模型来预测知名的类对象。 我们之所以这样做,是因为每个图像模型都使用 ImageNet 数据库中的 1,000 个类别进行了训练,并且计算机视觉社区可以使用该模型产生的权重,以供其他模型使用。
在下一节中,我们将学习如何使用迁移学习为自定义图像训练模型以进行预测,而不是从直接从 ImageNet 数据集开发的模型中进行推断。
使用 TensorFlow 开发迁移学习模型
我们在“第 5 章”,“神经网络架构和模型”中引入了迁移学习的概念,并在“使用 TensorFlow 编写深度学习模型”部分中,演示了如何基于预训练模型预测图像类别。 我们已经观察到,预训练模型在大型数据集上可以获得合理的准确率,但是我们可以通过在自己的数据集上训练模型来对此进行改进。 一种方法是构建整个模型(例如,ResNet)并在我们的数据集上对其进行训练-但是此过程可能需要大量时间才能运行模型,然后为我们自己的数据集优化模型参数。
另一种更有效的方法(称为迁移学习)是从基本模型中提取特征向量,而无需在 ImageNet 数据集上训练顶层,然后添加我们的自定义全连接层,包括激活,退出和 softmax,构成我们的最终模型。 我们冻结了基础模型,但是新添加的组件的顶层仍未冻结。 我们在自己的数据集上训练新创建的模型以生成预测。 从大型模型迁移学习的特征映射,然后通过微调高阶模型参数在我们自己的数据集上对其进行自定义的整个过程称为迁移学习。 在接下来的几节中,将从“分析和存储数据”开始,说明迁移学习工作流程以及相关的 TensorFlow/Keras 代码。
分析和存储数据
首先,我们将从分析和存储数据开始。 在这里,我们正在构建具有三个不同类别的家具模型:bed,chair和sofa。 我们的目录结构如下。 每个图像都是大小为224 x 224的彩色图像。
Furniture_images:
-
train(2,700 张图像)bed(900 张图像)chair(900 张图像)sofa(900 张图像)
-
val(300 张图像)bed(100 张图像)chair(100 张图像)sofa(100 张图像)
注意,图像数量仅是示例; 在每种情况下都是独一无二的。 要注意的重要一点是,为了进行良好的检测,我们每类需要约 1,000 张图像,并且训练和验证的比例为 90%:10%。
导入 TensorFlow 库
我们的下一步是导入 TensorFlow 库。 以下代码导入 ResNet 模型权重和预处理的输入,与上一节中的操作类似。 我们在“第 5 章”,“神经网络架构和模型”中了解了每个概念:
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input
from tensorflow.keras.layers import Dense, Activation, Flatten, Dropout
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.optimizers import SGD, Adam
img_width, img_height = 224, 224该代码还导入了几个深度学习参数,例如Dense(全连接层),Activation,Flatten和Dropout。 然后,我们导入顺序模型 API 以创建逐层模型,并使用随机梯度下降(SGD)和 Adam 优化器。 对于 ResNet 和 VGG,图像的高度和宽度为224,对于 Inception 模型,图像的高度和宽度为299。
设置模型参数
为了进行分析,我们设置模型参数,如以下代码块所示:
NUM_EPOCHS = 5
batchsize = 10
num_train_images = 900
num_val_images = 100然后,基础模型的构建类似于上一节中的示例,不同之处在于,我们不通过设置include_top=False来包括顶级模型:
base_model = ResNet50(weights='imagenet',include_top=False,input_shape=(img_height, img_width, 3))在此代码中,我们使用基本模型通过仅使用卷积层来生成特征向量。
建立输入数据管道
我们将导入一个图像数据生成器,该图像数据生成器使用诸如旋转,水平翻转,垂直翻转和数据预处理之类的数据扩充来生成张量图像。 数据生成器将重复训练和验证数据。
训练数据生成器
让我们看一下用于训练数据生成器的以下代码:
from keras.preprocessing.image import ImageDataGenerator
train_dir = '/home/…/visual_search/furniture_images/train'
train_datagen = ImageDataGenerator(preprocessing_function=preprocess_input,rotation_range=90,horizontal_flip=True,vertical_flip=True)目录 API 的流程-用于从目录导入数据。 它具有以下参数:
Directory:这是文件夹路径,应设置为存在所有三个类的图像的路径。 在这种情况下,示例为train目录的路径。 要获取路径,您可以将文件夹拖到终端,它会向您显示路径,然后可以将其复制并粘贴。Target_size:将其设置为等于模型拍摄的图像大小,例如,对于 Inception 为 299 x 299,对于 ResNet 和 VGG16 为224 x 224。Color_mode:将黑白图像设置为grayscale,将彩色图像设置为RGB。Batch_size:每批图像的数量。class_mode:如果只有两个类别可以预测,则设置为二进制;否则,请设置为二进制。 如果不是,则设置为categorical。shuffle:如果要重新排序图像,请设置为True; 否则,设置为False。seed:随机种子,用于应用随机图像增强和混排图像顺序。
以下代码显示了如何编写最终的训练数据生成器,该数据将导入模型中:
train_generator = train_datagen.flow_from_directory(train_dir,target_size=(img_height, img_width), batch_size=batchsize)验证数据生成器
接下来,我们将在以下代码中重复验证过程。 该过程与训练生成器的过程相同,除了我们将验证图像目录而不是训练图像目录:
from keras.preprocessing.image import ImageDataGenerator
val_dir = '/home/…/visual_search/furniture_images/val'
val_datagen = ImageDataGenerator(preprocessing_function=preprocess_input,rotation_range=90,horizontal_flip=True,vertical_flip=True)
val_generator = val_datagen.flow_from_directory(val_dir,target_size=(img_height, img_width),batch_size=batchsize)前面的代码显示了最终的验证数据生成器。
使用迁移学习构建最终模型
我们首先定义一个名为build_final_model()的函数,该函数接收基本模型和模型参数,例如丢弃,全连接层以及类的数量。 我们首先使用layer.trainable = False冻结基本模型。 然后,我们将基础模型输出特征向量展平,以进行后续处理。 接下来,我们添加一个全连接层并将其放置到展平的特征向量上,以使用 softmax 层预测新类:
def build_final_model(base_model, dropout, fc_layers, num_classes):
for layer in base_model.layers:
layer.trainable = False
x = base_model.output
x = Flatten()(x)
for fc in fc_layers:
# New FC layer, random init
x = Dense(fc, activation='relu')(x)
x = Dropout(dropout)(x)
# New softmax layer
predictions = Dense(num_classes, activation='softmax')(x)
final_model = Model(inputs=base_model.input, outputs=predictions)
return final_model
class_list = ["bed", "chair", "sofa"]
FC_LAYERS = [1024, 1024]
dropout = 0.3
final_model = build_final_model(base_model,dropout=dropout,fc_layers=FC_LAYERS,num_classes=len(class_list))使用带有分类交叉熵损失的adam优化器编译模型:
adam = Adam(lr=0.00001)
final_model.compile(adam, loss='categorical_crossentropy', metrics=['accuracy'])使用model.fit_generator命令开发并运行最终模型。 历史记录存储周期,每步时间,损失,准确率,验证损失和验证准确率:
history = final_model.fit(train_dir,epochs=NUM_EPOCHS,steps_per_epoch=num_train_images // batchsize,callbacks=[checkpoint_callback],validation_data=val_dir, validation_steps=num_val_images // batchsize)此处说明model.fit()的各种参数。 注意mode.fit_generator将来会被弃用,并由model.fit()函数代替,如上所示:
train_dir:输入训练数据; 其操作的详细信息已在上一节中进行了说明。epochs:一个整数,指示训练模型的周期数。 周期从1递增到epochs的值。steps_per_epoch:这是整数。 它显示了训练完成和开始下一个周期训练之前的步骤总数(样本批量)。 其最大值等于(训练图像数/batch_size)。 因此,如果有 900 张训练图像且批量大小为 10,则每个周期的步数为 90。workers:较高的值可确保 CPU 创建足够的批量供 GPU 处理,并且 GPU 永远不会保持空闲状态。shuffle:这是布尔类型。 它指示每个周期开始时批量的重新排序。 仅与Sequence(keras.utils.Sequence)一起使用。 当steps_per_epoch不是None时,它无效。Validation_data:这是一个验证生成器。validation_steps:这是validation_data生成器中使用的步骤总数(样本批量),等于验证数据集中的样本数量除以批量大小。
使用检查点保存模型
一个 TensorFlow 模型可以运行很长时间,因为每个周期都需要几分钟才能完成。 TensorFlow 有一个名为Checkpoint的命令,使我们能够在每个周期完成时保存中间模型。 因此,如果由于损失已经饱和而不得不在中间中断模型或将 PC 用于其他用途,则不必从头开始—您可以使用到目前为止开发的模型进行分析。 下面的代码块显示了对先前代码块的添加,以执行检查点:
from tensorflow.keras.callbacks import ModelCheckpoint filecheckpath="modelfurn_weight.hdf5" checkpointer = ModelCheckpoint(filecheckpath, verbose=1, save_best_only=True)
history = final_model.fit_generator(train_generator, epochs=NUM_EPOCHS, workers=0,steps_per_epoch=num_train_images // batchsize, shuffle=True, validation_data=val_generator,validation_steps=num_val_images // batchsize, callbacks = [checkpointer])
前面代码的输出如下:
89/90 [============================>.] - ETA: 2s - loss: 1.0830 - accuracy: 0.4011 Epoch 00001: val_loss improved from inf to 1.01586, saving model to modelfurn_weight.hdf5 90/90 [==============================] - 257s 3s/step - loss: 1.0834 - accuracy: 0.4022 - val_loss: 1.0159 - val_accuracy: 0.4800
Epoch 2/5 89/90 [============================>.] - ETA: 2s - loss: 1.0229 - accuracy: 0.5067 Epoch 00002: val_loss improved from 1.01586 to 0.87938, saving model to modelfurn_weight.hdf5 90/90 [==============================] - 253s 3s/step - loss: 1.0220 - accuracy: 0.5067 - val_loss: 0.8794 - val_accuracy: 0.7300
Epoch 3/5 89/90 [============================>.] - ETA: 2s - loss: 0.9404 - accuracy: 0.5719 Epoch 00003: val_loss improved from 0.87938 to 0.79207, saving model to modelfurn_weight.hdf5 90/90 [==============================] - 256s 3s/step - loss: 0.9403 - accuracy: 0.5700 - val_loss: 0.7921 - val_accuracy: 0.7900
Epoch 4/5 89/90 [============================>.] - ETA: 2s - loss: 0.8826 - accuracy: 0.6326 Epoch 00004: val_loss improved from 0.79207 to 0.69984, saving model to modelfurn_weight.hdf5 90/90 [==============================] - 254s 3s/step - loss: 0.8824 - accuracy: 0.6322 - val_loss: 0.6998 - val_accuracy: 0.8300
Epoch 5/5 89/90 [============================>.] - ETA: 2s - loss: 0.7865 - accuracy: 0.7090 Epoch 00005: val_loss improved from 0.69984 to 0.66693, saving model to modelfurn_weight.hdf5 90/90 [==============================] - 250s 3s/step - loss: 0.7865 - accuracy: 0.7089 - val_loss: 0.6669 - val_accuracy: 0.7700输出显示每个周期的损失和准确率,并且相应的文件另存为hdf5文件。
绘制训练历史
使用 Python matplotlib函数显示了显示训练精度和每个周期的训练损失的折线图。 我们将首先导入matplotlib,然后为训练和验证损失以及准确率定义参数:
import matplotlib.pyplot as plt
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']以下代码是使用 Keras 和 TensorFlow 绘制模型输出的标准代码。 我们首先定义图像大小(8 x 8),并使用子图函数显示(2,1,1)和(2,1,2)。 然后,我们定义标签,限制和标题:
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,5.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()让我们看一下前面代码的输出。 以下屏幕截图显示了不同模型之间的精度比较。 它显示了 Inception 的训练参数:

在前面的屏幕截图中,您可以观察到 Inception 的准确率在五个周期内达到了约 90%。 接下来,我们绘制 VGG16 的训练参数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GVlmsbWl-1681784515027)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/master-cv-tf-2x/img/b2b36265-00ac-461f-871b-730f38818235.png)]
上图显示 VGG16 的精度在五个周期内达到了约 80%。 接下来,我们绘制 ResNet 的训练参数:
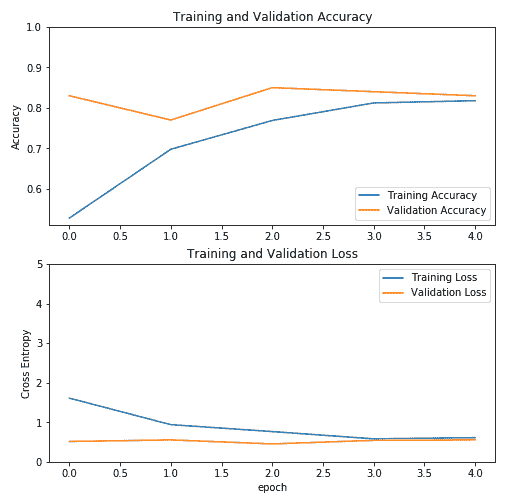
前面的屏幕截图显示 ResNet 的准确率在四个周期内达到了约 80%。
对于所有三个模型,在四个周期内,精度始终达到至少 80%。 Inception 模型的结果具有最高的准确率。
了解视觉搜索的架构和应用
视觉搜索使用深度神经网络技术来检测和分类图像及其内容,并使用它在图像数据库内搜索以返回匹配结果列表。 视觉搜索与零售行业特别相关,因为它允许零售商显示大量类似于客户上传图像的图像以增加销售收入。视觉搜索可以与语音搜索结合使用,从而进一步增强搜索效果。 视觉信息比文本信息更相关,这导致视觉搜索更加流行。 许多不同的公司,包括 Google,Amazon,Pinterest,Wayfair,Walmart,Bing,ASOS,Neiman Marcus,IKEA,Argos 等,都建立了强大的视觉搜索引擎来改善客户体验。
视觉搜索的架构
诸如 ResNet,VGG16 和 Inception 之类的深度神经网络模型实质上可以分为两个部分:
- 第一个组件标识图像的低级内容,例如特征向量(边缘)。
- 第二部分表示图像的高级内容,例如最终的图像特征,它们是各种低级内容的集合。 下图说明了将七个类别分类的卷积神经网络:

上图显示了整个图像分类神经网络模型可以分为两个部分:卷积层和顶层。 在全连接层之前的最后一个卷积层是形状的特征向量(图像数, X, Y, 通道数),并且被展平(图像数 * X * Y * 通道数)以生成n维向量。
特征向量形状具有四个分量:
图像数表示训练图像的数量。 因此,如果您有 1,000 个训练图像,则该值为 1,000。X表示层的宽度。 典型值为 14。Y表示层的高度,可以是 14。通道数表示过滤器的数量或深度 Conv2D。 典型值为 512。
在视觉搜索中,我们通过使用欧几里得距离或余弦相似度等工具比较两个特征向量的相似度来计算两个图像的相似度。 视觉搜索的架构如下所示:

此处列出了各个步骤:
- 通过将顶层与知名模型(例如 ResNet,VGG16 或 Inception)分离,然后添加自定义顶层(包括全连接层,退出,激活和 softmax 层),使用迁移学习来开发新模型。
- 使用新的数据集训练新模型。
- 通过刚刚开发的新模型运行图像,上传图像并找到其特征向量和图像类。
- 为了节省时间,请仅在与上载图像相对应的目录类中进行搜索。
- 使用诸如欧几里得距离或余弦相似度的算法进行搜索。
- 如果余弦相似度
> 0.999,则显示搜索结果;否则,显示搜索结果。 如果不是,请使用上传的图像重新训练模型,或者调整模型参数并重新运行该过程。 - 为了进一步加快搜索速度,请使用生成的边界框检测上载图像内以及搜索图像数据库和目录内对象的位置。
上述流程图包含几个关键组件:
- 模型开发:这包括选择一个合适的预训练模型,除去其顶部附近的层,冻结之前的所有层,并添加一个新的顶层以匹配我们的类。 这意味着,如果我们使用在 1,000 个类的 ImageNet 数据集上训练的预训练模型,我们将删除其顶层,并仅用 3 类
bed,chair和sofa替换为新的顶层。 。 - 模型训练:这涉及首先编译模型,然后使用
model.fit()函数开始训练。 - 模型输出:将上传的图像和测试图像数据库中的每个图像传递给模型,以生成特征向量。 上载的图像也用于确定模型类别。
- 搜索算法:搜索算法在给定类别指定的测试图像文件夹中执行,而不是在整个测试图像集中执行,从而节省了时间。 搜索算法依赖于 CNN 模型选择的正确类别。 如果类匹配不正确,则最终的视觉搜索将导致错误的结果。 要解决此问题,可以采取几个步骤:
- 使用新的图像集重新运行模型,增加训练图像的大小,或改善模型参数。
- 但是,无论使用多少数据,CNN 模型都永远不会具有 100% 的准确率。 因此,为解决此问题,通常在视觉搜索结果中添加文本关键字搜索。 例如,客户可能会写,“您能找到一张与上图中显示的床相似的床吗?” 在这种情况下,我们知道上载的类是床。 这是使用自然语言处理(NLP)完成的。
- 解决该问题的另一种方法是针对多个预先训练的模型运行相同的上载图像,如果类别预测彼此不同,则采用模式值。
接下来,我们将详细说明用于视觉搜索的代码。
视觉搜索代码和说明
在本部分中,我们将解释用于视觉搜索的 TensorFlow 代码及其功能:
- 首先,我们将为上传的图像指定一个文件夹(共有三个文件夹,我们将针对每种图像类型切换文件夹)。 请注意,此处显示的图像仅是示例; 您的图片可能有所不同:
#img_path = '/home/…/visual_search/ test/bed/bed1.jpg'
#img_path ='/home/…/visual_search/test/chair/chair1.jpg'
#img_path ='/home/…/visual_search/test/sofa/sofa1.jpg'- 然后,我们将上传图像,将图像转换为数组,并像之前一样对图像进行预处理:
img = image.load_img(img_path, target_size=(224, 224))
img_data = image.img_to_array(img)
img_data = np.expand_dims(img_data, axis=0)
img_data = preprocess_input(img_data)前面的代码是在进一步处理之前将图像转换为数组的标准代码。
预测上传图像的类别
一旦上传了新图像,我们的任务就是找出它属于哪个类。 为此,我们计算图像可能属于的每个类别的概率,然后选择概率最高的类别。 此处的示例说明了使用 VGG 预训练模型进行的计算,但相同的概念在其他地方也适用:
vgg_feature = final_model.predict(img_data,verbose=0)
vgg_feature_np = np.array(vgg_feature)
vgg_feature1D = vgg_feature_np.flatten()
print (vgg_feature1D)
y_prob = final_model.predict(img_data)
y_classes = y_prob.argmax(axis=-1)
print (y_classes)在前面的代码中,我们使用model.predict()函数计算了图像属于特定类别的概率,并使用probability.argmax计算了类别名称以指示具有最高概率的类别。
预测所有图像的类别
以下函数导入必要的包,以从目录和相似度计算中获取文件。 然后,根据上传图像的输入类别指定要定位的文件夹:
import os
from scipy.spatial import distance as dist
from sklearn.metrics.pairwise import cosine_similarity
if y_classes == [0]:
path = 'furniture_images/val/bed'
elif y_classes == [1]:
path = 'furniture_images/val/chair'
else:
path = 'furniture_images/val/sofa'以下函数循环遍历测试目录中的每个图像,并将该图像转换为数组,然后使用训练后的模型将其用于预测特征向量:
mindist=10000
maxcosine =0
i=0
for filename in os.listdir(path):
image_train = os.path.join(path, filename)
i +=1
imgtrain = image.load_img(image_train, target_size=(224, 224))
img_data_train = image.img_to_array(imgtrain)
img_data_train = np.expand_dims(img_data_train, axis=0)
img_data_train = preprocess_input(img_data_train)
vgg_feature_train = final_model.predict(img_data_train)
vgg_feature_np_train = np.array(vgg_feature_train)
vgg_feature_train1D = vgg_feature_np_train.flatten()
eucldist = dist.euclidean(vgg_feature1D,vgg_feature_train1D)
if mindist > eucldist:
mindist=eucldist
minfilename = filename
#print (vgg16_feature_np)
dot_product = np.dot(vgg_feature1D,vgg_feature_train1D)#normalize the results, to achieve similarity measures independent #of the scale of the vectors
norm_Y = np.linalg.norm(vgg_feature1D)
norm_X = np.linalg.norm(vgg_feature_train1D)
cosine_similarity = dot_product / (norm_X * norm_Y)
if maxcosine < cosine_similarity:
maxcosine=cosine_similarity
cosfilename = filename
print ("%s filename %f euclediandist %f cosine_similarity" %(filename,eucldist,cosine_similarity))
print ("%s minfilename %f mineuclediandist %s cosfilename %f maxcosinesimilarity" %(minfilename,mindist, cosfilename, maxcosine))您可以在前面的代码中观察以下内容:
- 将每个特征向量与上传的图像特征向量进行比较,以计算出欧几里得距离和余弦相似度。
- 通过确定欧几里得距离的最小值和余弦相似度的最大值来计算图像相似度。
- 确定并显示与最小距离相对应的图像文件。
可以在本书的 GitHub 存储库中找到包括迁移学习和可视搜索的完整代码。
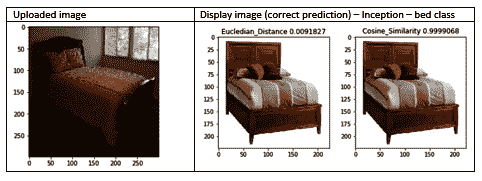
下图显示了使用三种不同的模型和两种不同的搜索算法(欧几里得距离和余弦相似度)对一张床的上传图像的视觉搜索预测:

在上图中,可以观察到以下内容:
- Inception 模型预测的类别不准确,这导致可视搜索模型预测了错误的类别。
- 请注意,视觉搜索模型无法捕获预测错误类的神经网络。 我们还可以使用其他模型检查同一张上载图片的类别预测,以查看模式(多数)值-在这种情况下,ResNet 和 VGG 预测为
bed时为bed,而 Inception 预测为sofa。 - 综上所述,由于我们不知道给定的模型是否可以正确预测类别,因此建议的方法是同时使用三个或更多不同的模型预测上传图像的类别,然后选择具有多数值的预测类别。 使用这种方法,我们将增加我们预测的信心。
下图显示了使用其他上载图像的预测,这似乎是正确的:
下图显示了使用三种不同的模型和两种不同的搜索算法(欧几里得距离和余弦相似度)对椅子上载图像的视觉搜索预测:

您可以在上图中观察到以下内容:
- 尽管余弦相似度函数显示的图像与欧几里得距离函数的图像不同,但在所有情况下预测都是正确的。
- 两者似乎都非常接近,这两种显示方法为我们提供了一种显示多个图像的方法。 这意味着,如果用户上传一张椅子的图像并希望在在线目录中找到类似的椅子,我们的系统将显示两幅图像供用户选择,而不仅仅是一张图像,这将增加我们的椅子的销售机会。 如果两个图像相同,则算法将仅显示一个图像,否则将显示两个图像。 另一个选择是使用相同算法显示前两个匹配项。
下图显示了使用三种不同的模型和两种不同的搜索算法(欧几里得距离和余弦相似度)对沙发上载图像的视觉搜索预测:

您可以在上图中观察到以下内容:
- 尽管余弦相似度函数显示的图像与欧几里得距离函数的图像不同,但在所有情况下预测都是正确的。
- 两者似乎都非常接近,显示的两种方法为我们提供了一种显示多个图像的方法。 如前所述,对于与上载图像相似的两个图像,用户可以选择更多选项。
使用tf.data的视觉搜索输入管道
TensorFlow tf.data API 是一种高效的数据管道,其处理数据的速度比 Keras 数据输入过程快一个数量级。 它在分布式文件系统中聚合数据并对其进行批量。 有关更多详细信息,请参阅这里。
以下屏幕截图显示了tf.data与 Keras 图像输入过程的图像上传时间比较:

请注意,一千张图像大约需要 1.58 秒,比 Keras 图像输入过程快 90 倍。
这是tf.data的一些常见函数:
- 为了使该 API 起作用,您需要导入
pathlib库。 tf.data.Dataset.list_files用于创建与模式匹配的所有文件的数据集。tf.strings.splot基于定界符分割文件路径。tf.image.decode_jpeg将 JPEG 图像解码为张量(请注意,转换必须没有文件路径)。tf.image.convert_image_dtype将图像转换为dtype float32。
以下链接提供了更新的视觉搜索代码。
如前所述,该代码包含tf.data。 除了tf.data以外,它还通过在build_final_model中进行以下更改来解冻模型的顶部:
layer.trainable = True
layer_adjust = 100
for layer in base_model.layers[:layer_adjust]:
layer.trainable = False前面的更改使模型可以在第一百层之后开始训练,而不是仅训练最后几层。 如下图所示,此更改提高了准确率:

训练花费更多时间,但是模型的准确率接近 100%,而不是 90%。
在总结本章之前,让我们回顾一下训练 CNN 的两个重要概念:准确率和损失性。 Keras 将y-pred和y-true定义为模型预测值和地面真实值。 准确率定义为将y-pred与y-true进行比较,然后平均差异。 损失项(也称为熵)定义为乘积类别概率与分类指数的负和。 可能还有其他损失项,例如 RMSProp。 通常,如果accuracy > 0.9和loss < 1,训练会给出正确的输出。
总结
在本章中,我们学习了如何使用 TensorFlow/Keras 为上一章研究的深度学习模型开发迁移学习代码。 我们学习了如何从包含多个类的目录中导入经过训练的图像,并使用它们来训练模型并进行预测。 然后,我们学习了如何使模型的基础层保持冻结状态,移除顶层并用我们自己的顶层替换它,并使用它来训练结果模型。
我们研究了视觉搜索的重要性以及如何使用迁移学习来增强视觉搜索方法。 我们的示例包括三种不同类别的家具-我们了解了模型的准确率以及如何改善由此造成的损失。 在本章中,我们还学习了如何使用 TensorFlow tf.data输入管道在训练期间更快地处理图像。
在下一章中,我们将研究 YOLO,以便在图像和视频上绘制边界框对象检测,并将其用于进一步改善视觉搜索。
七、YOLO 对象检测
在上一章中,我们详细讨论了各种神经网络图像分类和对象检测架构,这些架构利用多个步骤进行对象检测,分类和边界框优化。 在本章中,我们将介绍两种单阶段的快速对象检测方法-仅查看一次(YOLO)和 RetinaNet。 我们将讨论每个模型的架构,然后使用 YOLO v3 在真实的图像和视频中进行推理。 我们将向您展示如何使用 YOLO v3 优化配置参数和训练自己的自定义映像。
本章涵盖的主题如下:
- YOLO 概述
- 用于对象检测的 Darknet 简介
- 使用 Darknet 和 Tiny Darknet 进行实时预测
- 比较 YOLO – YOLO 与 YOLO v2 与 YOLO v3
- 什么时候训练模型?
- 使用 YOLO v3 训练自己的图像集以开发自定义模型
- 特征金字塔和 RetinaNet 概述
YOLO 概述
我们在“第 5 章”,“神经网络架构和模型”中了解到,每个已发布的神经网络架构都通过学习其架构和功能,然后开发一个全新的分类器来改进前一架构,从而改进它的准确率和检测时间。 YOLO 参加了计算机视觉和模式识别会议(CVPR),在 2016 年中,Joseph Redmon,Santosh Divvala,Ross Girshick 和 Ali Farhadi 的论文 《只看一次:统一的实时对象检测》。 YOLO 是一个非常快速的神经网络,可以以每秒 45 帧(基本 YOLO)到每秒 155 帧(快速 YOLO)的惊人速度一次检测多种物体。 相比之下,大多数手机相机以每秒 30 帧的速度捕获视频,而高速相机以每秒 250 帧的速度捕获视频。 YOLO 的每秒帧数等于大约 6 到 22 ms 的检测时间。 将此与人类大脑检测大约 13 毫秒图像所需的时间进行比较-YOLO 以与人类相似的方式立即识别图像。 因此,它为机器提供了即时目标检测功能。
在进一步研究细节之前,我们将首先讨论交并比(IOU)的概念。
IOU 的概念
IOU 是基于预测边界框和地面真实边界框(手工标记)之间的重叠程度的对象检测评估指标。 让我们看一下 IOU 的以下派生:

下图说明了 IOU,显示了一辆大型货车的预测和地面实况边界框:

在这种情况下,IOU 值接近0.9,因为重叠区域非常大。 如果两个边界框不重叠,则 IOU 值为0,如果它们确实重叠 100%,则 IOU 值为1。
YOLO 如何如此快速地检测物体?
YOLO 的检测机制基于单个卷积神经网络(CNN),该预测同时预测对象的多个边界框以及在每个边界框中检测给定对象类别的可能性。 下图说明了这种方法:

前面的照片显示了三个主要步骤,从边界框的开发到使用非最大抑制和最终边界框。 具体步骤如下:
- YOLO 中的 CNN 使用整个图像中的特征来预测每个边界框。 因此,预测是全局的,而不是局部的。
- 整个图像分为
S x S个网格单元,每个网格单元预测B个边界框以及边界框包含对象的概率(P)。 因此,总共有S x S x B个边界框,每个边界框都有相应的概率。 - 每个边界框包含五个预测(
x,y,w,h和c),以下内容适用:
o(x, y)是边界框中心相对于网格单元坐标的坐标。o(w, h)是边框相对于图像尺寸的宽度和高度。o(c)是置信度预测,表示预测框和地面真实框之间的 IOU。
- 网格单元包含对象的概率定义为类乘以 IOU 值的概率。 这意味着,如果网格单元仅部分包含一个对象,则其概率将较低,而 IOU 值将保持较低。 这将对该网格单元的边界框产生两个影响:
- 边界框的形状将小于完全包含对象的网格单元的边界框的大小,因为网格单元只能看到对象的一部分并从中推断出其形状。 如果网格单元仅包含对象的一小部分,则它可能根本无法识别该对象。
- 边界框类置信度将很低,因为部分图像产生的 IOU 值将不符合地面真实性预测。
- 通常,每个网格单元只能包含一个类,但是使用锚框原理,可以将多个类分配给一个网格单元。 锚框是预定义的形状,表示要检测的类的形状。 例如,如果我们检测到三个类别(汽车,摩托车和人),那么我们可能可以通过两个锚框形状来解决-一个代表摩托车和人,另一个代表汽车。 可以通过查看先前图像中最右边的图像来确认。 我们可以通过使用 K 均值聚类等算法分析每个类的形状来确定锚框形状以形成训练 CSV 数据。
让我们以前面的图像为例。 在这里,我们有三类:car,motorcycle和human。 我们假设一个5 x 5的网格具有 2 个锚定框和 8 个维度(5 个边界框参数(x,y,w,h和c)和 3 类(c1,c2和c3))。 因此,输出向量大小为5 x 5 x 2 x 8。
我们为每个锚框重复两次Y = [x, y, w, h, c, c1, c2, c3, x, y, w, h, c, c1, c2, c3]参数。 下图说明了边界框坐标的计算:

图像的大小为448 x 448。此处,出于说明目的,显示了human和car两类的计算方法。 请注意,每个锚定框的大小为448/5 ~ 89。
YOLO v3 神经网络架构
TYOLO v3 由 Joseph Redmon 和 Ali Farhadi 于 2018 年在论文《YOLOv3:增量改进》中引入。 下图显示了 YOLO v3 神经网络架构。 该网络具有 24 个卷积层和 2 个全连接层。 它没有任何 softmax 层。
下图以图形方式说明了 YOLO v3 架构:
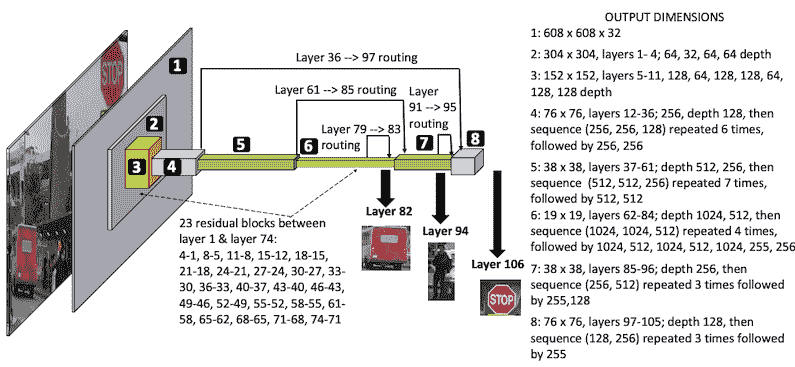
YOLO v3 的最重要的功能是它的检测机制,它是在三种不同的规模上完成的-在第 82、94 和 106 层:
- 该网络由第 1 层和第 74 层之间的 23 个卷积和残差块组成,其中输入图像大小从
608降低到19,深度通过交替的3 x 3和1 x 1个过滤器从3增长到1,024。 - 除 5 种情况下,将跨步值
2与3 x 3过滤器一起用于减小尺寸外,跨步通常保持为1。 - 剩余的块之后是交替的
1 x 1和1 x 1过滤器的预卷积块,直到在第 82 层进行第一次检测为止。已经使用了两次短路-一个在第 61 和 85 层之间,另一个在第 36 和 97 层之间 。
YOLO 与 Faster R-CNN 的比较
下表显示了 YOLO 和 Faster R-CNN 之间的相似之处:
YOLO | R-CNN |
|---|---|
预测每个网格单元的边界框。 | 选择性搜索会为每个区域提议(实际上是一个网格单元)生成边界框。 |
使用边界框回归。 | 使用边界框回归。 |
下表显示了 YOLO 和 Faster R-CNN 之间的区别:
YOLO | R-CNN |
|---|---|
分类和边界框回归同时发生。 | 选择性搜索会为每个区域提议生成一个边界框-这些是单独的事件。 |
每个图像 98 个边界框。 | 每个图像约有 2,000 个区域提议边界框。 |
每个网格单元 2 个锚点。 | 每个网格单元 9 个锚点。 |
它无法检测到小物体和彼此相邻的物体。 | 检测小物体和彼此相邻的物体。 |
快速算法。 | 更快的 R-CNN 比 YOLO 慢。 |
因此,总而言之,如果您需要生产级的准确率并且不太关心速度,请选择 Faster R-CNN。 但是,如果需要快速检测,请选择 YOLO。 像任何神经网络模型一样,您需要有足够的样本(大约 1,000 个)以不同的角度,不同的颜色和形状定向以做出良好的预测。 完成此操作后,根据我的个人经验,YOLO v3 会给出非常合理且快速的预测。
用于对象检测的 Darknet 简介
Darknet 是一个开放的神经网络框架,由 C 编写,并由 YOLO 的第一作者 Joseph Redmon 管理。 有关 Darknet 的详细信息,请访问 pjreddie.com。 在本节中,我们将讨论用于对象检测的 Darknet 和 Tiny Darknet。
使用 Darknet 检测对象
在本节中,我们将从官方 Darknet 站点安装 Darknet,并将其用于对象检测。 请按照以下步骤在您的 PC 上安装 Darknet 并进行推断:
- 在终端中应输入以下五行。 在每个命令行之后点击
Enter。 这些步骤将从 GitHub 克隆 Darknet,这将在您的 PC 中创建 Darknet 目录,并获取 YOLO v3 权重,然后检测图像中的对象:
git clone https://github.com/pjreddie/darknet.git
cd darknet
make
wget https://pjreddie.com/media/files/yolov3.weights
./darknet detect cfg/yolov3.cfg yolov3.weights data/carhumanbike.png- 执行
git clone命令后,您将在终端中获得以下输出:
Cloning into 'darknet'...
remote: Enumerating objects: 5901, done.
remote: Total 5901 (delta 0), reused 0 (delta 0), pack-reused 5901
Receiving objects: 100% (5901/5901), 6.16 MiB | 8.03 MiB/s, done.
Resolving deltas: 100% (3916/3916), done.- 输入
wget yolov3权重后,将在终端中获得以下输出:
Resolving pjreddie.com (pjreddie.com)... 128.208.4.108
Connecting to pjreddie.com (pjreddie.com)|128.208.4.108|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 248007048 (237M) [application/octet-stream]
Saving to: 'yolov3.weights'
yolov3.weights 100%[======================================================>] 236.52M 8.16MB/s in 29s
… (8.13 MB/s) - 'yolov3.weights' saved [248007048/248007048]- 然后,一旦输入
darknet$ ./darknet detect cfg/yolov3.cfg yolov3.weight data/carhumanbike.png,您将在终端中获得以下输出:
layer filters size input output
0 conv 32 3 x 3 / 1 608 x 608 x 3 -> 608 x 608 x 32 0.639 BFLOPs --> image size 608x608
1 conv 64 3 x 3 / 2 608 x 608 x 32 -> 304 x 304 x 64 3.407 BFLOPs
2 conv 32 1 x 1 / 1 304 x 304 x 64 -> 304 x 304 x 32 0.379 BFLOPs
3 conv 64 3 x 3 / 1 304 x 304 x 32 -> 304 x 304 x 64 3.407 BFLOPs
4 res 1 304 x 304 x 64 -> 304 x 304 x 64 --> this implies residual block connecting layer 1 to 4
5 conv 128 3 x 3 / 2 304 x 304 x 64 -> 152 x 152 x 128 3.407 BFLOPs
6 conv 64 1 x 1 / 1 152 x 152 x 128 -> 152 x 152 x 64 0.379 BFLOPs
7 conv 128 3 x 3 / 1 152 x 152 x 64 -> 152 x 152 x 128 3.407 BFLOPs
8 res 5 152 x 152 x 128 -> 152 x 152 x 128 --> this implies residual block connecting layer 5 to 8
...
...
...
83 route 79 --> this implies layer 83 is connected to 79, layer 80-82 are prediction layers
84 conv 256 1 x 1 / 1 19 x 19 x 512 -> 19 x 19 x 256 0.095 BFLOPs
85 upsample 2x 19 x 19 x 256 -> 38 x 38 x 256 --> this implies image size increased by 2X
86 route 85 61 --> this implies shortcut between layer 61 and 85
87 conv 256 1 x 1 / 1 38 x 38 x 768 -> 38 x 38 x 256 0.568 BFLOPs
88 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs
89 conv 256 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 256 0.379 BFLOPs
90 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs
91 conv 256 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 256 0.379 BFLOPs
92 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs
93 conv 255 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 255 0.377 BFLOPs
94 yolo --> this implies prediction at layer 94
95 route 91 --> this implies layer 95 is connected to 91, layer 92-94 are prediction layers
96 conv 128 1 x 1 / 1 38 x 38 x 256 -> 38 x 38 x 128 0.095 BFLOPs
97 upsample 2x 38 x 38 x 128 -> 76 x 76 x 128 à this implies image size increased by 2X
98 route 97 36\. --> this implies shortcut between layer 36 and 97
99 conv 128 1 x 1 / 1 76 x 76 x 384 -> 76 x 76 x 128 0.568 BFLOPs
100 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs
101 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs
102 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs
103 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs
104 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs
105 conv 255 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 255 0.754 BFLOPs
106 yolo --> this implies prediction at layer 106执行代码后,您将看到完整的模型。 为简便起见,我们仅在前面的代码段中显示了模型的开头。
上面的输出描述了 YOLO v3 的详细神经网络构建块。 花一些时间来了解所有 106 个卷积层及其目的。 上一节提供了所有唯一代码行的说明。 前面的代码导致图像的以下输出:
Loading weights from yolov3.weights...Done!
data/carhumanbike.png: Predicted in 16.140244 seconds.
car: 81%
truck: 63%
motorbike: 77%
car: 58%
person: 100%
person: 100%
person: 99%
person: 94%预测输出如下所示:

YOLO v3 模型在预测方面做得很好。 即使是很远的汽车也能正确检测到。 前面的汽车分为汽车(在图中看不到标签)和卡车。 所有四个人(两个步行摩托车和两个骑摩托车)被检测到。 在两辆摩托车中,检测到一辆摩托车。 请注意,尽管汽车的颜色是黑色,但模型不会错误地将阴影检测为汽车。
使用 Tiny Darknet 检测对象
Tiny Darknet 是一个小型且快速的网络,可以非常快速地检测到对象。 它的大小为 4 MB,而 Darknet 的大小为 28 MB。 您可以在这个页面中找到其实现的详细信息。
完成上述步骤后,Darknet 应该已经安装在您的 PC 上。 在终端中执行以下命令:
$ cd darknet
darknet$ wget https://pjreddie.com/media/files/tiny.weights前面的命令会将 Darknet 权重安装在darknet文件夹中。 您还应该在cfg文件夹中包含tiny.cfg。 然后,执行以下命令以检测对象。 在这里,我们将使用与参考 Darknet 模型相同的图像进行检测。 我们只是将权重和cfg文件从 Darknet 更改为 Tiny Darknet:
darknet$ ./darknet detect cfg/tiny.cfg tiny.weights data /carhumanbike.png与 Darknet 一样,前面的命令将显示 Tiny Darknet 模型的所有 21 层(Darknet 则为 106 层),如下所示:
layer filters size input output
0 conv 16 3 x 3 / 1 224 x 224 x 3 -> 224 x 224 x 16 0.043 BFLOPs
1 max 2 x 2 / 2 224 x 224 x 16 -> 112 x 112 x 16
2 conv 32 3 x 3 / 1 112 x 112 x 16 -> 112 x 112 x 32 0.116 BFLOPs
3 max 2 x 2 / 2 112 x 112 x 32 -> 56 x 56 x 32
4 conv 16 1 x 1 / 1 56 x 56 x 32 -> 56 x 56 x 16 0.003 BFLOPs
5 conv 128 3 x 3 / 1 56 x 56 x 16 -> 56 x 56 x 128 0.116 BFLOPs
6 conv 16 1 x 1 / 1 56 x 56 x 128 -> 56 x 56 x 16 0.013 BFLOPs
7 conv 128 3 x 3 / 1 56 x 56 x 16 -> 56 x 56 x 128 0.116 BFLOPs
8 max 2 x 2 / 2 56 x 56 x 128 -> 28 x 28 x 128
9 conv 32 1 x 1 / 1 28 x 28 x 128 -> 28 x 28 x 32 0.006 BFLOPs
10 conv 256 3 x 3 / 1 28 x 28 x 32 -> 28 x 28 x 256 0.116 BFLOPs
11 conv 32 1 x 1 / 1 28 x 28 x 256 -> 28 x 28 x 32 0.013 BFLOPs
12 conv 256 3 x 3 / 1 28 x 28 x 32 -> 28 x 28 x 256 0.116 BFLOPs
13 max 2 x 2 / 2 28 x 28 x 256 -> 14 x 14 x 256
14 conv 64 1 x 1 / 1 14 x 14 x 256 -> 14 x 14 x 64 0.006 BFLOPs
15 conv 512 3 x 3 / 1 14 x 14 x 64 -> 14 x 14 x 512 0.116 BFLOPs
16 conv 64 1 x 1 / 1 14 x 14 x 512 -> 14 x 14 x 64 0.013 BFLOPs
17 conv 512 3 x 3 / 1 14 x 14 x 64 -> 14 x 14 x 512 0.116 BFLOPs
18 conv 128 1 x 1 / 1 14 x 14 x 512 -> 14 x 14 x 128 0.026 BFLOPs
19 conv 1000 1 x 1 / 1 14 x 14 x 128 -> 14 x 14 x1000 0.050 BFLOPs
20 avg 14 x 14 x1000 -> 1000
21 softmax 1000
Loading weights from tiny.weights...Done!
data/carhumanbike.png: Predicted in 0.125068 seconds.但是,该模型无法检测图像中的对象。 我将检测更改为分类,如下所示:
darknet$ ./darknet classify cfg/tiny.cfg tiny.weights data/dog.jpg前面的命令生成的结果类似于 Tiny YOLO 链接中发布的结果(wget https://pjreddie.com/media/files/tiny.weights):
Loading weights from tiny.weights...Done!
data/dog.jpg: Predicted in 0.130953 seconds.
14.51%: malamute
6.09%: Newfoundland
5.59%: dogsled
4.55%: standard schnauzer
4.05%: Eskimo dog但是,同一图像在通过对象检测时不会返回边界框。
接下来,我们将讨论使用 Darknet 对视频进行实时预测。
使用 Darknet 的实时预测
涉及 Darknet 的预测都可以使用终端中的命令行来完成。 有关更多详细信息,请参阅这里。
到目前为止,我们已经在图像上使用 Darknet 进行了推断。 在以下步骤中,我们将学习如何在视频文件上使用 Darknet 进行推理:
- 通过在终端中键入
cd darknet转到darknet目录(已在前面的步骤中安装)。 - 确保已安装 OpenCV。 即使您已安装 OpenCV,它仍可能会创建一个错误标志。 使用
sudo apt-get install libopencv-dev命令将 OpenCV 安装在darknet目录中。 - 在
darknet目录中,有一个名为Makefile的文件。 打开该文件,设置OpenCV = 1并保存。 - 通过转到这里从终端下载权重。
- 此时,由于更改了
Makefile,因此必须重新编译。 您可以通过在终端中键入make来执行此操作。 - 然后,通过在终端中键入以下命令来下载视频文件:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights data/road_video.mp4- 如前所述,这里将编译具有 106 层的 YOLO 模型,并播放视频。 您会注意到视频播放非常慢。 可以通过以下两个步骤解决此问题。 它们应该一一执行,因为每个步骤都会产生影响。
- 再次打开
Makefile。 将GPU更改为1,保存Makefile,然后重复步骤 4 至 6。此时,我注意到步骤 6 提供了以下 CUDAout of memory错误:
…….
57 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs
58 res 55 38 x 38 x 512 -> 38 x 38 x 512
59 conv 256 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 256 0.379 BFLOPs
60 CUDA Error: out of memory
darknet: ./src/cuda.c:36: check_error: Assertion `0' failed.
Aborted (core dumped)通过两种机制解决了该错误:
- 更改图像尺寸。
- 将 NVIDIA CUDA 版本从 9.0 更改为 10.1。 请访问 NVIDIA 网站以更改 NVIDIA 版本。
首先,尝试更改图像尺寸。 如果这不起作用,则检查 CUDA 版本并更新(如果您仍在使用 9.0 版)。
- 在
darknet目录中,在cfg目录下有一个名为yolov3.cfg的文件。 打开该文件,并将宽度和高度从608更改为416或288。 我发现当将该值设置为304时,它仍然会失败。 保存文件并重复步骤 5 和 6。
这是将图像尺寸设置为304时将得到的错误代码:
.....
80 conv 1024 3 x 3 / 1 10 x 10 x 512 -> 10 x 10 x1024 0.944 BFLOPs
81 conv 255 1 x 1 / 1 10 x 10 x1024 -> 10 x 10 x 255 0.052 BFLOPs
82 yolo
83 route 79
84 conv 256 1 x 1 / 1 10 x 10 x 512 -> 10 x 10 x 256 0.026 BFLOPs
85 upsample 2x 10 x 10 x 256 -> 20 x 20 x 25
86 route 85 61
87 Layer before convolutional layer must output image.: File exists
darknet: ./src/utils.c:256: error: Assertion `0' failed.
Aborted (core dumped)下图显示了带有交通标志标签和汽车检测的视频文件的屏幕截图:
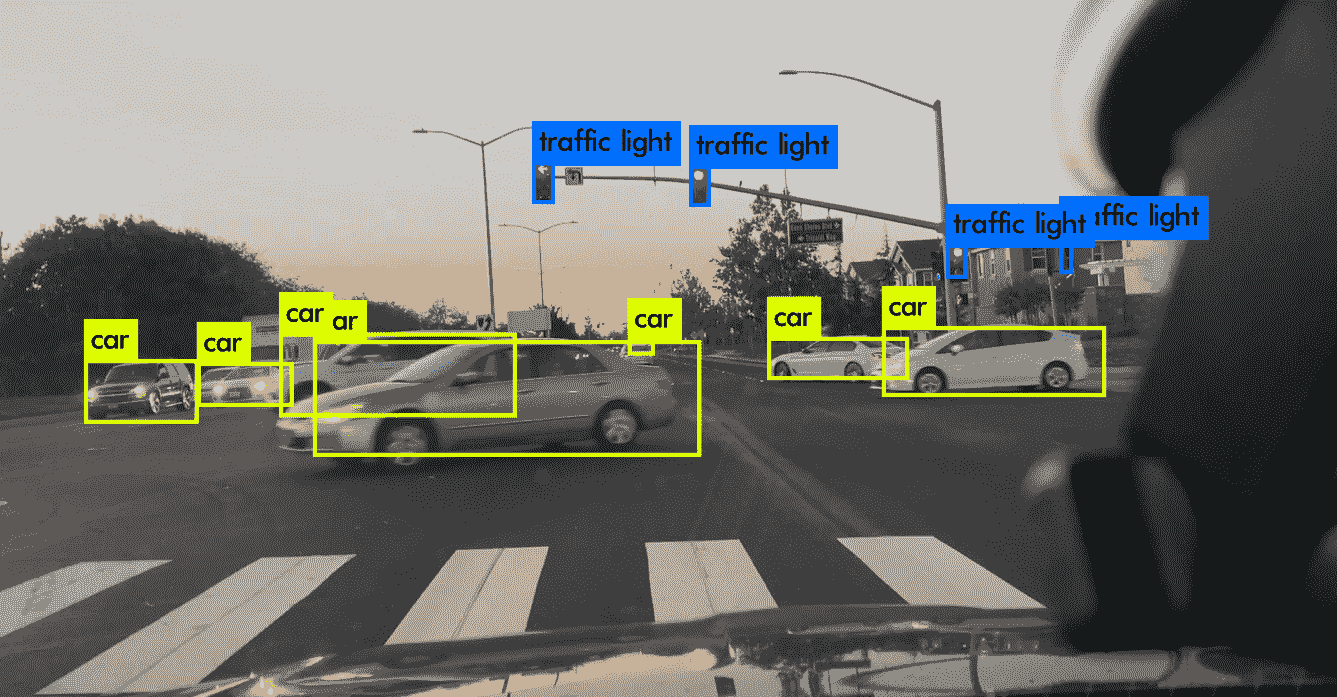
请注意,所有汽车均被正确检测,甚至主交通灯和侧面交通灯也被检测到。
我们之前讨论了默认大小为608的 YOLO v3 层。 以下是相同的输出,其大小更改为416,以便正确显示视频文件:
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs
2 conv 32 1 x 1 / 1 208 x 208 x 64 -> 208 x 208 x 32 0.177 BFLOPs
3 conv 64 3 x 3 / 1 208 x 208 x 32 -> 208 x 208 x 64 1.595 BFLOPs
4 res 1 208 x 208 x 64 -> 208 x 208 x 64
5 conv 128 3 x 3 / 2 208 x 208 x 64 -> 104 x 104 x 128 1.595 BFLOPs
6 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BFLOPs
7 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BFLOPs
8 res 5 104 x 104 x 128 -> 104 x 104 x 128
...
...
...
94 yolo
95 route 91
96 conv 128 1 x 1 / 1 26 x 26 x 256 -> 26 x 26 x 128 0.044 BFLOPs
97 upsample 2x 26 x 26 x 128 -> 52 x 52 x 128
98 route 97 36
99 conv 128 1 x 1 / 1 52 x 52 x 384 -> 52 x 52 x 128 0.266 BFLOP
100 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
101 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
102 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
103 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs
106 yolo
Loading weights from yolov3.weights...Done!
video file: data/road_video.mp4执行前面的代码后,您将看到完整的模型。 为简便起见,我们仅在前面的代码段中显示了模型的开头。
下表总结了两种不同图像尺寸的输出:
层 | 608 尺寸 | 416 尺寸 |
|---|---|---|
82 | 19 x 19 | 13 x 13 |
94 | 38 x 38 | 26 x 26 |
106 | 76 x 76 | 52 x 52 |
注意,原始图像尺寸和第 82 层输出尺寸之间的比率保持为 32。 到目前为止,我们已经比较了使用 Darknet 和 Tiny Darknet 的推论。 现在,我们将比较不同的 YOLO 模型。
YOLO 与 YOLO v2 与 YOLO v3
下表显示了三种 YOLO 版本的比较:
YOLO | YOLO v2 | YOLO v3 | |
|---|---|---|---|
输入尺寸 | 224 x 224 | 448 x 448 | |
构架 | Darknet 在 ImageNet-1,000 上接受了训练。 | Darknet-19,19 个卷积层和 5 个最大池化层。 | Darknet-53,53 个卷积层。 为了进行检测,增加了 53 层,总共有 106 层。 |
小尺寸检测 | 它找不到小图像。 | 在检测小图像方面比 YOLO 更好。 | 在小图像检测方面优于 YOLO v2。 |
使用锚框。 | 使用残差块。 |
下图比较了 YOLO v2 和 YOLO v3 的架构:

基本卷积层相似,但是 YOLO v3 在三个独立的层上执行检测:82、94 和 106。
您应该从 YOLO v3 中获取的最关键的项目是在三个不同的层级和三个不同的级别进行对象检测:82(最大),94(中级)和 106(最小)。
什么时候训练模型?
在迁移学习中,通过训练大量数据来开发训练模型。 因此,如果您的类属于以下类之一,则无需为这些类训练模型。 为 YOLO v3 训练的 80 个类如下:
Person, bicycle, car, motorbike, airplane, bus, train, truck, boat, traffic light, fire hydrant, stop sign, parking meter, bench, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe, backpack, umbrella, handbag, tie, suitcase, frisbee, skis, snowboard, sports ball, kite, baseball bat, baseball glove, skateboard, surfboard. tennis racket, bottle, wine glass, cup, fork, knife, spoon, bowl, banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, donut, cake, chair, sofa, potted plant, bed, dining table, toilet, tv monitor, laptop, mouse, remote, keyboard, cell phone, microwave, oven, toaster, sink, refrigerator, book, clock, vase, scissors, teddy bear, hair drier, toothbrush因此,如果您要检测食物的类型,YOLO v3 会很好地检测banana,apple,sandwich,orange,broccoli,carrot,hot dog, pizza,donut和cake,但无法检测到hamburger。
同样,在 PASCAL VOC 数据集上训练的 YOLO v3 将能够检测所有 20 个类别,即airplane,bicycle,bird,boat,bottle,bus和car ,cat,chair,cow,dining table,dog,horse,motorbike,person,potted plant,sheep,sofa,train和 tv monitor,但它无法检测到新类别hot dog。
因此,这就是训练您自己的图像集的地方,下一节将对此进行介绍。
使用 YOLO v3 训练自己的图像集来开发自定义模型
在本节中,我们将学习如何使用 YOLO v3 训练您自己的自定义检测器。 训练过程涉及许多不同的步骤。 为了清楚起见,以下流程图中显示了每个步骤的输入和输出。 YOLO 的《YOLOv3:Incremental Improvement》由 Redmon,Joseph,Farhadi 和 Ali 于 2018 年在 arXiv 上发布,其中包含许多训练步骤。这些训练步骤也包含在 VOC 的“训练 YOLO”部分。
下图显示了如何使用 YOLO v3 训练 VOC 数据集。 在我们的案例中,我们将使用我们自己的自定义家具数据,该数据用于在“第 6 章”,“使用迁移学习的视觉搜索”中使用 Keras 对图像进行分类:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ld3sGLZ9-1681784515043)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/master-cv-tf-2x/img/7122d128-6932-40d9-a661-4964d8653a0b.png)]
在此描述第 1 至 11 部分的详细说明。
准备图像
请按照以下步骤准备图像:
- 研究您要检测的类数-在此示例中,我们将考虑在第 6 章“使用迁移学习的视觉搜索”中讨论的
bed,chair和sofa类。 - 确保每个类的图像数量相同。
- 确保您的类名称中没有空格; 例如,使用
caesar_salad代替caesar salad。 - 每个类至少收集 100 张图像以开始初始训练(因此,请完成步骤 1 至 10 以开发模型),然后随着图像数量的增加而增加数量。 理想情况下,1,000 张图像是训练的不错数目。
- 将所有图像批量调整为
416 x 416— 您可以在 macOS 预览窗格中选择选项,然后选择多个图像,然后批量调整大小,或者可以使用 Ubuntu 中的 ImageMagick 等程序在终端中批量调整大小。 之所以需要执行此步骤,是因为 YOLO v3 希望图像的尺寸为416 x 416,因此会自行调整图像的尺寸,但这可能会导致该图像的边界框出现不同的外观,从而在某些情况下无法检测到。
生成标注文件
此步骤涉及为数据集中每个图像中的每个对象创建边界框坐标。 此边界框坐标通常由四个参数表示:(x, y)用于确定初始位置以及宽度和高度。 边界框可以表示为.xml或.txt形式。 该坐标文件也称为标注文件。 请按照以下步骤完成本节:
- 许多图像标注软件应用都用于标记图像。 在面部关键点检测期间,我们已经在“第 3 章”,“使用 OpenCV 和 CNN 进行面部检测”中介绍了 VGG 图像标注器。 在“第 11 章”,“具有 CPU/GPU 优化功能的边缘设备深度学习”中,我们将介绍用于自动图像标注的 CVAT 工具。 在本章中,我们将介绍一个称为
labelImg的标注工具。 - 从这里下载
pypi的labelImg标注软件。 您可以按照此处的说明为操作系统安装labelImg-如果有任何问题,一种简单的安装方法是在终端中键入pip3 install lableImg。 然后,要运行它,只需在终端中键入labelImg。 - 在
labelImg中,在“打开目录”框中单击图像目录。 选择每个图像并通过单击Create/RectBox创建一个包围框,然后为包围框添加一个类名,例如bed,chair或sofa。 保存标注,然后单击右箭头转到下一张图像。 - 如果图片中图像中有多个类别或同一类别的多个位置,请在每个类别周围绘制矩形。 多个类别的示例是同一图像中的汽车和行人。 同一类别内多个位置的示例是同一图像中不同位置的不同汽车。 因此,如果图像由多把椅子和一张沙发组成,则在每把椅子周围绘制矩形,并在类名称中为每张沙发分别键入
chair,在其周围绘制一个矩形并键入sofa。 如果图像仅由沙发组成,则在沙发周围绘制一个矩形,并输入sofa作为类名。 下图说明了这一点:

此图显示了如何标记属于同一类的多个图像。
将.xml文件转换为.txt文件
YOLO v3 需要将标注文件另存为.txt文件而不是.xml文件。 本节介绍如何转换和排列.txt文件以输入模型。 有许多工具可用于此类转换-我们将在此处提及两个工具:
RectLabel:具有内置的转换器,可将.xml文件转换为.txt文件。- 命令行
xmltotxt工具:您可以在 GitHub 页面上找到此工具。
该过程的输出将是一个包含.jpg,.xml和.txt文件的目录。 每个图像.jpg文件将具有一个对应的.xml和.txt文件。 您可以从目录中删除.xml文件,因为我们将不再需要这些文件。
创建合并的train.txt和test.txt文件
顾名思义,此步骤涉及一个表示所有图像的.txt文件。 为此,我们将运行一个简单的 Python 文件(每个文件用于训练和测试图像)以创建combinedtrain.txt和combinedtest.txt文件。 转到这里获取 Python 文件。
以下屏幕快照显示了 Python 代码的示例输出:
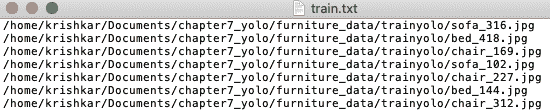
每个文本文件由几行组成-每行包括图像文件的路径,如前所示。
创建类名列表文件
该文件包含所有类的列表。 因此,在我们的例子中,它是一个扩展名为.names的简单文本文件,如下所示:
bed
chair
sofa创建一个 YOLO .data文件
这些步骤涉及train和valid文件夹的路径。 开始之前,请将合并的train,合并的test和.names文件复制到darknet目录。 以下代码块显示了典型的.data文件(在本示例中为furniture.data)的外观:
classes= 3
train = /home/krishkar/darknet/furniture_train.txt
valid = /home/krishkar/darknet/furniture_test.txt
names = /home/krishkar/darknet/furniture_label.names
backup = backup这里,我们有三个类(bed,chair和sofa),因此classes的值设置为 3。train,valid和names文件夹显示了合并训练,合并测试和标签.names文件。 将此文件保存在cfg目录中。
调整 YOLO 配置文件
完成这些步骤后,文件排列部分完成,我们现在将致力于优化 YOLO 配置文件中的参数。 为此,请在 Darknet cfg目录下打开YOLO-VOC.cfg并进行以下更改。 生成的代码也可以从这里下载:
请注意,在以下部分中,我们将描述各种行号和要更改的值–这些行号对应于YOLO-VOC.cfg文件。
- 第 6 行-批量大小。 将此设置为
64。 这意味着在每个训练步骤中将使用 64 张图像来更新 CNN 参数。 - 第 7 行-
subdivisions。 这将按批量大小/细分划分批量,然后将其馈送到 GPU 中进行处理。 将对细分的数量重复该过程,直到完成批量大小(64)并开始新的批量为止。 因此,如果subdivisions设置为1,则所有 64 张图像都将发送到 GPU,以在给定批量中同时进行处理。 如果批量大小设置为8,则将 8 张图像发送到 GPU 进行处理,并在开始下一个批量之前重复此过程 8 次。 将该值设置为1可能会导致 GPU 出现故障,但可能会提高检测的准确率。 对于初始运行,将值设置为8。 - 第 11 行-
momentum。 这用于最小化批量之间的较大权重变化,因为在任何时间点都只处理少量图像(在此示例中为 64)。0.9的默认值是 OK。 - 第 12 行-
decay。 通过控制权重值以获取较大的值,可以将过拟合程度降至最低。0.005的默认值是 OK。 - 第 18 行-
learning_rate。 这表明了解当前批量的速度。 下图显示了学习率与批量的关系,下面将对其进行说明。0.001的默认值是一个合理的开始,如果值是不是数字(NaN),则可以减小默认值:

- 第 19 行-
burn_in。这表示学习率上升的初始时间。 将其设置为1000,如果减小max_batches,则将其降低。
请注意,如果您按照前面的步骤设置代码,并且注意到当周期在200至300左右时,您没有学到太多,原因可能是您当时的学习率很低。 您将开始看到学习率逐渐超过1000周期。
- 第 20 行-
max_batches。 最大批量数。 将其设置为 2,000 乘以类数。 对于3类,6000的值是合理的。 请注意,默认值为500200,该值非常高,如果保持不变,则训练将持续数天。 - 第 22 行-
steps。 这是将学习率乘以第 23 行中的标度之后的步骤。将其设置为max_batches的 80% 和 90%。 因此,如果批量大小为6000,则将值设置为4800和5400。 - 第 611、695、779 行。将
classes值从其默认值[20或80)更改为您的类值(在此示例中为3)。 - 605、689、773 行。这些是 YOLO 预测之前的最后卷积层。 将
filters值从其默认值255设置为(5+ # of classes)x3。 因此,对于 3 个类别,过滤器值应为 24。 - 线 610、694、778。这是锚点,是具有高宽比的预设边界框,如此处所示。 锚点的大小由(宽度,高度)表示,它们的值不需要更改,但是了解其上下文很重要。
(10, 13),(16, 30),(32, 23),(30, 61),(62, 45),(59, 119),(116, 90),(156, 198),(373 (326)。 总共有九个锚点,范围从10的高度到373的高度。 这表示从最小到最大的图像检测。 对于此练习,我们不需要更改锚点。 - 609、693、777 行。这些是蒙版。 他们指定我们需要选择哪些锚框进行训练。 如果较低级别的值为
0, 1, 2,并且您在区域94和106的输出中继续观察到NaN,请考虑增加该值。 选择该值的最佳方法是查看训练图像边界框从最小到最大图像的比例,了解它们的下落位置,并选择适当的蒙版来表示。 在我们的测试案例中,最小尺寸的边界框从62, 45, 40开始,因此我们选择5, 6, 7作为最小值。 下表显示了蒙版的默认值和调整后的值:
默认值 | 调整值 |
|---|---|
6, 7, 8 | 7, 8, 9 |
3, 4, 5 | 6, 7, 8 |
0, 1, 2 | 6, 7, 8 |
9的最大值表示bed,并且6的最小值表示chair。
请注意,如果图像中的边界框不同,则可以调整mask值以获得所需的结果。 因此,从默认值开始并进行调整以避免出现NaN结果。
为训练启用 GPU
在您的darknet目录中打开Makefile并按如下所示设置参数:
GPU = 1
CUDNN = 1开始训练
在终端中一一执行以下命令:
- 下载预训练的
darknet53模型权重以加快训练速度。 在终端中运行这个页面中找到的命令。 - 完成预训练权重的下载后,在终端中执行以下命令:
./darknet detector train cfg/furniture.data cfg/yolov3-furniture.cfg darknet53.conv.74 -gpus 0训练将开始并将继续,直到使用 82、94 和 106 层写入的值创建最大批量为止。 在下面的代码中,我们将显示两个输出-一个用于一切正常进行时的输出,另一个用于当训练未能正确进行时的输出:
Correct training Region 82 Avg IOU: 0.063095, Class: 0.722422, Obj: 0.048252, No Obj: 0.006528, .5R: 0.000000, .75R: 0.000000, count: 1 Region 94 Avg IOU: 0.368487, Class: 0.326743, Obj: 0.005098, No Obj: 0.003003, .5R: 0.000000, .75R: 0.000000, count: 1 Region 106 Avg IOU: 0.144510, Class: 0.583078, Obj: 0.001186, No Obj: 0.001228, .5R: 0.000000, .75R: 0.000000, count: 1 298: 9.153068, 7.480968 avg, 0.000008 rate, 51.744666 seconds, 298 images
Incorrect training
Region 82 Avg IOU: 0.061959, Class: 0.404846, Obj: 0.520931, No Obj: 0.485723, .5R: 0.000000, .75R: 0.000000, count: 1
Region 94 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.525058, .5R: -nan, .75R: -nan, count: 0
Region 106 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.419326, .5R: -nan, .75R: -nan, count: 0
在前面的代码中,IOU描述联合之上的交集,Class表示对象分类-需要接近1的Class值。 Obj是检测到对象的概率,其值应接近1。 NoObj的值应接近0. 0.5。 R是检测到的阳性样本除以图像中实际样本的比率。
到目前为止,我们已经学习了如何使用 Darknet 来对预训练的 YOLO 模型进行推理,并为自定义图像训练了我们自己的 YOLO 模型。 在下一部分中,我们将概述另一个称为 RetinaNet 的神经网络模型。
特征金字塔网络和 RetinaNet 概述
我们从“第 5 章”,“神经网络架构和模型”了解到,CNN 的每一层本身就是一个特征向量。 与此相关的有两个关键且相互依赖的参数,如下所示:
- 当我们通过各种卷积层将图像的 CNN 提升到全连接层时,我们会确定更多的特征(表面上很强),从简单的边缘到对象的特征再到完整的对象。 但是,这样做时,图像的分辨率会随着特征宽度和高度的减小而深度的增加而降低。
- 不同比例的对象(小到大)受此分辨率和尺寸的影响。 如下图所示,较小的对象在最高层将更难检测,因为其特征将变得非常模糊,以至于 CNN 将无法很好地检测到它:

如前所述,由于小物体的分辨率问题,很难同时检测不同比例的多幅图像。 因此,如上图所示,我们以金字塔形式而不是图像堆叠特征,顶部的尺寸较小,底部的尺寸较大。 这称为特征金字塔。
特征金字塔网络(FPN)由多个特征金字塔组成,这些特征金字塔由每个 CNN 层之间的较高维度和较低分辨率组成。 FPN 中使用此金字塔特征来检测不同比例的物体。 FPN 使用最后一个全连接层特征,该特征将基于其最近的邻居应用 2x 的上采样,然后将其添加到其先前的特征向量中,然后将3 x 3卷积应用于合并的层。 这个过程一直重复到第二个卷积层。 结果是在所有级别上都具有丰富的语义,从而导致不同级别的对象检测。
RetinaNet 由林宗义,Priya Goyal,Ross Girshick,Kakaiming He 在《密集对象检测的焦点损失》中引入, 和皮奥特·多拉尔(PiotrDollár)。 RetinaNet 是一个密集的一级网络,由一个基本的 ResNet 型网络和两个特定于任务的子网组成。 基本网络使用 FPN 为不同的图像比例计算卷积特征映射。 第一个子网执行对象分类,第二个子网执行卷积包围盒回归。
大多数 CNN 对象检测器可分为两类-一级和二级网络。 在诸如 YOLO 和 SSD 的单阶段网络中,单个阶段负责分类和检测。 在诸如 R-CNN 的两阶段网络中,第一阶段生成对象位置,第二阶段评估其分类。 一级网络以其速度而闻名,而二级网络以其准确率而闻名。
已知由于只有几个候选位置实际包含对象,因此一级网络遭受类不平衡的困扰。 该类不平衡使得训练在图像的大部分部分中无效。 RetinaNet 通过引入焦距损失(FL)来解决类别不平衡问题,该焦距微调交叉熵(CE)损失来专注于困难的检测问题。 损失 CE 的微调是通过对损失 CE 应用检测概率(pt)的调制因子(g)来完成的,如下所示:
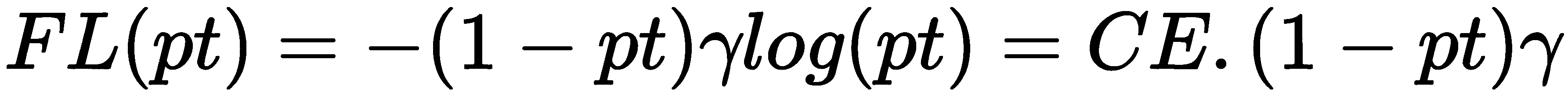
RetinaNet 通过使用 FL 概念与一级网络的速度相匹配,而与二级网络的精度相匹配。
可以通过以下命令在终端中下载 RetinaNet 的 Keras 版本:
pip install keras-retinanet在精度和速度方面,YOLO v3 保持平均精度超过 50,并且比 RetinaNet 更快。
总结
在本章中,我们了解了 YOLO 对象检测方法的基本组成部分,并了解了与其他对象检测方法相比,YOLO 如何能够如此快速,准确地检测到对象。 我们了解了 YOLO 的不同演变(原始版本的 YOLO,YOLO v2 和 YOLO v3)及其差异。 我们使用 YOLO 来检测图像和视频文件中的物体,例如交通标志。
我们学习了如何调试 YOLO v3,以便它可以生成正确的输出而不会崩溃。 我们了解了如何使用预训练的 YOLO 进行推断,并了解了使用我们的自定义图像开发新的 YOLO 模型的详细过程,以及如何调整 CNN 参数以生成正确的结果。 本章还向您介绍了 RetinaNet,以及它如何使用特征金字塔的概念来检测不同比例的对象。
在下一章中,我们将学习有关使用语义分割和图像修复的图像内容填充。
八、语义分割与神经样式迁移
深度神经网络的应用不仅限于在图像中找到对象(我们在前面的章节中已经学习过),还可以用于将图像分割成空间区域,从而生成人造图像并从一个图像中迁移样式。 形象给另一个。
在本章中,我们将使用 TensorFlow Colab 执行所有这些任务。 语义分割可预测图像的每个像素是否属于某个类别。 这是用于图像叠加的有用技术。 您将了解 TensorFlow DeepLab,以便可以对图像执行语义分割。 深度卷积生成对抗网络(DCGAN)是强大的工具,可用于生成人造图像,例如人脸和手写数字。 它们也可以用于图像修复。 我们还将讨论如何使用 CNN 将样式从一个图像迁移到另一个图像。
在本章中,我们将介绍以下主题:
- 用于语义分割的 TensorFlow DeepLab 概述
- 使用 DCGAN 生成人工图像
- 使用 OpenCV 修复图像
- 了解神经样式迁移
用于语义分割的 TensorFlow DeepLab 概述
语义分割是在像素级别理解和分类图像内容的任务。 与对象检测不同,在对象检测中,在多个对象类上绘制了一个矩形边界框(类似于我们从 YOLOV3 中学到的知识),语义分割可学习整个图像,并将封闭对象的类分配给图像中的相应像素。 因此,语义分段可以比对象检测更强大。 语义分段的基本架构基于编码器-解码器网络,其中编码器创建一个高维特征向量并在不同级别上对其进行聚合,而解码器在神经网络的不同级别上创建一个语义分段掩码。 编码器使用传统的 CNN,而解码器使用解池,解卷积和上采样。 DeepLab 是 Google 引入的一种特殊类型的语义分段,它使用空洞卷积,空间金字塔池而不是常规的最大池以及编码器-解码器网络。 DeepLabV3+ 是由 Liang-Chieh Chen,Yukun Zhu,George Papandreou,Florian Schro 和 Hartwig Adam 在他们的论文《用于语义图像分割的实用 Atrous 可分离卷积的编码器-解码器》中提出的。
DeepLab 于 2015 年开始使用 V1,并于 2019 年迅速移至 V3+。下表列出了不同 DeepLab 版本的比较:
DeepLab V1 | DeepLab V2 | DeepLab V3 | DeepLab V3+ | |
|---|---|---|---|---|
论文 | 《具有深度卷积网络和全连接 CRF 的语义图像分割》,2015 | 《DeepLab:使用深度卷积网络,空洞卷积和全连接 CRF 进行语义图像分割》,2017 | 《重新思考原子卷积以进行语义图像分割》,2017 | 《具有可分割卷积的语义语义分割的编解码器》,2018 |
作者 | 陈良杰,乔治·帕潘德里欧,Iasonas Kokkinos,凯文·墨菲和艾伦·尤里 | 陈良杰,乔治·帕潘德里欧,Iasonas Kokkinos,凯文·墨菲和艾伦·尤里 | 陈良杰,乔治·帕潘德里欧,弗洛里安·施罗夫和哈特维格·Adam | 陈良杰,朱玉坤,乔治·帕潘德里欧,弗洛里安·施罗和哈特维格·Adam |
关键概念 | 原子卷积,全连接条件随机场(CRF) | 多孔空间金字塔池(ASPP) | ASPP,图像级特征和批量规范化 | ASPP 和编码器/解码器模块 |
DeepLabV3+ 使用空间金字塔池(SPP)的概念来定义其架构。
空间金字塔池化
我们在“第 5 章”,“神经网络架构和模型”中介绍的大多数 CNN 模型都需要固定的输入图像大小,这限制了输入图像的纵横比和比例。 固定大小约束不是来自卷积运算; 相反,它来自全连接层,该层需要固定的输入大小。 卷积操作从 CNN 的不同层中的图像的边缘,拐角和不同形状生成特征映射。 特征映射在不同的层中是不同的,并且是图像中形状的函数。 它们不会随着输入大小的变化而显着变化。 SPP 代替了最后一个合并层,紧接在全连接层之前,由并行排列的空间容器组成,其空间大小与输入图像的大小成正比,但其总数固定为全连接层数。 空间池化层通过保持过滤器大小固定但更改特征向量的大小来消除输入图像的固定大小约束。
DeepLabV3 的架构基于两种神经网络-空洞卷积和编码器/解码器网络。
空洞卷积
我们在“第 4 章”,“图像深度学习”中介绍了卷积的概念,但是我们没有涉及各种空洞卷积。空洞卷积,也称为膨胀卷积,增加了卷积的视野。 传统的 CNN 使用最大池化和跨步来快速减小层的大小,但这样做也会降低特征映射的空间分辨率。空洞卷积是一种用于解决此问题的方法。 它通过使用 Atrous 值修改跨步来实现此目的,从而有效地更改了过滤器的值字段,如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ySAk8cL2-1681784515044)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/master-cv-tf-2x/img/add28c06-3e36-4992-90a1-874e884951f1.png)]
上图显示了速率为 2 的空洞卷积。与深度卷积相比,它跳过了其他每个像元。 实际上,如果应用stride = 2,则3 x 3核就是3 x 3核。与简单的深度方向较小的特征映射相比,空洞卷积增加了视野并捕获了边界信息(与最大池化相比, 缺少对象边界),从而导致图像上下文丰富。 由于其在每个后续层中保持视野相同的特性,空洞卷积用于图像分割。
DeepLabV3 执行几个并行的空洞卷积,所有这些卷积以不同的速率运行,就像我们前面描述的空间池化层概念一样。 上图说明了空洞卷积模块和并行模块彼此相邻堆叠以形成 SPP。 与传统卷积不同,传统卷积与原始图像相比减少了最终特征向量的深度和宽度,而空洞卷积保留了图像大小。 因此,图像的精细细节不会丢失。 在构建具有丰富图像上下文的分割图时,这很有用。
编解码器网络
编码器是获取图像并生成特征向量的神经网络。 解码器执行与编码器相反的操作; 它采用特征向量并从中生成图像。 编码器和解码器一起训练以优化组合损失函数。
编码器-解码器网络可在编码器路径中实现更快的计算,因为不必在编码器路径中扩张特征,并且在解码器路径中恢复了清晰的物体。 编码器-解码器网络包含一个编码器模块,该模块捕获更高的语义信息,例如图像中的形状。 它通过逐渐缩小特征映射来实现。 另一方面,解码器模块保留空间信息和更清晰的图像分割。
编码器和解码器主要在多个比例上使用1 x 1和3 x 3空洞卷积。 让我们更详细地了解它们。
编码器模块
编码器模块的主要功能如下:
- 空洞卷积用于提取特征。
- 输出跨步是输入图像分辨率与最终输出分辨率之比。 其典型值为 16 或 8,这会导致特征提取更加密集。
- 在最后两个块中使用速率为 2 和 4 的空洞卷积。
- ASPP 模块用于在多个尺度上应用卷积运算。
解码器模块
解码器模块的主要功能如下:
1 x 1卷积用于减少来自编码器模块的低级特征映射的通道。3 x 3卷积用于获得更清晰的分割结果。- 4x 上采样。
DeepLab 中的语义分割 - 示例
可在以下由 TensorFlow 管理的 GitHub 页面上找到使用 TensorFlow 训练 DeepLab 的详细代码。
Google Colab 包含基于几个预先训练的模型的内置 DeepLab Python 代码。 可以在这个页面中找到。
Google Colab,Google Cloud TPU 和 TensorFlow
在深入研究示例代码之前,让我们了解 Google 机器学习的一些基本功能,所有这些功能都是免费提供的,以便我们可以开发强大的计算机视觉和机器学习代码:
- Google Colab:您可以从 Google 云端硬盘打开 Google Colab,如以下屏幕截图所示。 如果您是第一次使用它,则必须先单击“新建”,然后单击“更多”,才能将 Google Colab 安装到您的云端硬盘。 Google Colab 可让您无需安装即可打开 Jupyter 笔记本。 它还内置了 TensorFlow,这意味着处理包含给您的所有 TensorFlow 依赖项要容易得多:

上面的屏幕快照显示了 Google Colab 文件夹相对于 Google 云端硬盘的位置。 它使您可以处理.ipynb文件,然后进行存储。
- Google Cloud TPU:这是张量处理单元。 它使您可以更快地运行神经网络代码。 进入 Google Colab 笔记本后,您可以为 Python
.ipynb文件激活 TPU,如以下屏幕截图所示:
如前面的屏幕快照所示,打开 Cloud TPU 将有助于加快处理神经网络的训练和预测阶段的速度。
Google Colab DeepLab 笔记本包含三个示例图像,还为您提供获取 URL 的选项,以便您可以加载自定义图像。 当您获得图像的 URL 时,请确保 URL 末尾带有.jpg。 从互联网上提取的许多图像没有此扩展名,程序会说找不到它。 如果您有自己想要使用的图像,请将其存储在 GitHub 页面上,然后下载 URL。 以下屏幕截图显示了根据mobilenetv2_coco_voctrainaug接收到的输出:

上面的屏幕快照显示了四个不同的图像-停放的自行车,繁忙的纽约街道,城市道路和带家具的房间。 在所有情况下检测都非常好。 应当注意,该模型仅检测以下 20 个类别,以及背景类别:背景,飞机,自行车,鸟 ,船,瓶,公共汽车,车,猫,椅子,牛,餐桌,狗,马,摩托车,人, 盆栽植物,绵羊,沙发,火车,电视。 以下屏幕快照显示了使用不同模型xception_coco_voctrainval运行的相同四个图像:

与 MobileNet 模型相比,对象对异常模型的预测显示出更多的改进。 与 MobileNet 模型相比,对于例外模型,可以清楚地检测出自行车,人和桌子的细分。
MobileNet 是一种有效的神经网络模型,可用于手机和边缘设备。 与常规卷积相反,它使用深度卷积。 要详细了解 MobileNet 和深度卷积,请参阅“第 11 章”,“具有 GPU/CPU 优化功能的边缘深度学习”。
使用 DCGAN 生成人工图像
在“第 5 章”,“神经网络架构和模型”中,我们了解了 DCGAN。 它们由生成器模型和判别器模型组成。 生成器模型采用表示图像特征的随机向量,并通过 CNN 生成人工图像G(z)。 因此,生成器模型返回生成新图像及其类别的绝对概率具有可分割卷积的语义语义分割的编解码器。 判别器(D)网络是二分类器。 它从样本概率,图像分布(p_data)和来自生成器的人造图像中获取真实图像,以生成最终图像P(z)的概率。 从真实图像分布中采样。 因此,判别器模型返回条件概率,即最终图像的类别来自给定分布。
判别器将生成真实图像的概率信息馈送到生成器,生成器使用该信息来改进其预测,以创建人造图像G(z)。 随着训练的进行,生成器会更好地创建可以欺骗判别器的人工图像,并且判别器将发现很难将真实图像与人工图像区分开。 这两个模型相互对立,因此命名为对抗网络。 当判别器不再能够将真实图像与人工图像分离时,模型收敛。
GAN 训练遵循针对几个周期的判别器和生成器训练的替代模式,然后重复进行直到收敛为止。 在每个训练期间,其他组件保持固定,这意味着在训练生成器时,判别器保持固定,而在训练判别器时,生成器保持固定,以最大程度地减少生成器和判别器相互追逐的机会 。
前面的描述应该已经为您提供了 GAN 的高级理解。 但是,为了编码 GAN,我们需要更多地了解模型架构。 让我们开始吧。
生成器
下图显示了 DCGAN 的生成器网络的架构:

从上图中,我们可以看到以下内容:
- 所有具有跨步但没有最大池化的卷积网络都允许该网络在生成器中学习自己的上采样。 注意,最大池化被跨步卷积代替。
- 第一层从判别器获得概率
P(z),通过矩阵乘法连接到下一个卷积层。 这意味着不使用正式的全连接层。 但是,网络可以达到其目的。 - 我们将批量归一化到所有层以重新调整输入,生成器生成器层除外,以提高学习的稳定性。
判别器
下图显示了 DCGAN 判别器网络的架构:
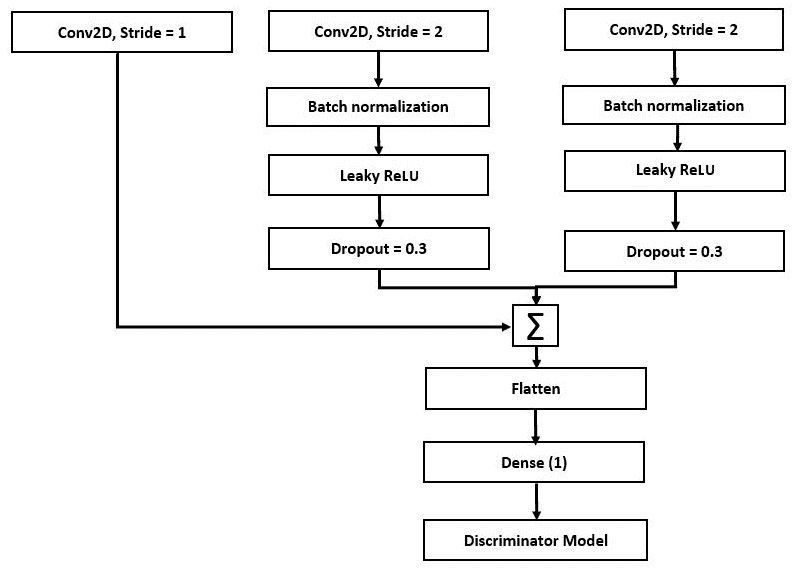
从上图中,我们可以看到以下内容:
- 所有具有跨步但没有最大池化的卷积网络都允许网络在判别器中学习自己的下采样。
- 我们消除了全连接层。 最后的卷积层被展平并直接连接到单个 Sigmoid 输出。
- 我们对除判别器输入层以外的所有层应用批归一化,以提高学习的稳定性。
训练
训练时要考虑的关键特征如下:
- 激活:Tanh
- 随机梯度下降(SGD),最小批量为 128
- 泄漏 ReLU:斜率为 0.2
- 学习率为 0.0002 的 Adam 优化器
- 动量项 0.5:值 0.9 引起振荡
下图显示了训练阶段 DCGAN 的损失项:
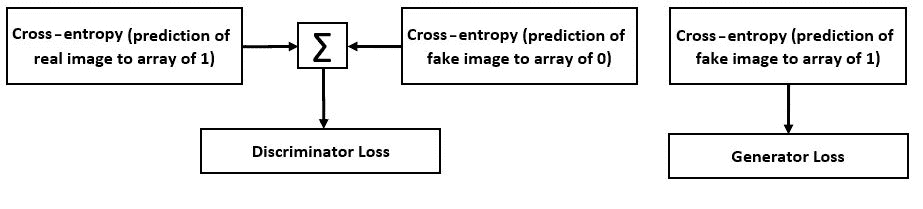
当生成器接收到随机输入并且生成器损失定义为其产生假输出的能力时,训练便开始了。 判别器损失定义为其将实际输出与伪输出分离的能力。 梯度用于更新生成器和判别器。 在训练过程中,同时对生成器和判别器进行训练。 训练过程通常只要我们需要同时训练两个模型即可。 请记住,两个模型是相互同步的。
使用 DCGAN 修复图像
图像修补是根据来自相邻点的信息填充图像或视频缺失部分的过程。 图像修补工作流程涉及以下步骤:
- 图像中缺少片段。
- 收集相应缺失部分的像素信息。 这称为层蒙版。
- 向神经网络馈送步骤 1 和 2 中描述的图像,以确定需要填充图像的哪一部分。这意味着,首先对具有缺失部分的图像进行处理,然后对层蒙版进行处理。
- 输入图像经过类似的 DCGAN,如前所述(卷积和反卷积)。 层蒙版允许网络基于其相邻像素数据仅关注缺失部分,并丢弃图像中已经完成的部分。 生成器网络生成伪造的图像,而判别器网络确保最终绘画看起来尽可能真实。
TensorFlow DCGAN – 示例
TensorFlow.org 有一个很好的图像修复示例,您可以在 Google Colab 或您自己的本地计算机上运行。 该示例可以在 Google Colab。
此示例显示了根据 MNIST 数据集训练 GAN,然后生成人工数字的方法。 使用的模型与前面各节中描述的模型相似。
使用 OpenCV 修复图像
OpenCV 提供了两种图像修复方法,如下所示:
cv.INPAINT_TELEA基于论文《一种基于快速行进方法的图像修复技术》,2004 年由 Alexandru Telea 提出。该方法用所有图像的归一化加权和替换待修复邻域中的像素。 附近的已知像素。 那些位于该点附近和边界轮廓上的像素将获得更大的权重。 修复像素后,将使用快速行进方法将像素移动到下一个最近的像素:
import numpy as np
import cv2 as cv
img = cv.imread('/home/.../krishmark.JPG')
mask = cv.imread('/home/.../markonly.JPG',0)
dst = cv.inpaint(img,mask,3,cv.INPAINT_TELEA)
cv.imshow('dst',dst)
cv.waitKey(0)
cv.destroyAllWindows()cv.INPAINT_NS基于 Bertalmio,Marcelo,Andrea L. Bertozzi 和 Guillermo Sapiro 在 2001 年发表的论文《Navier-Stokes,流体动态以及图像和视频修补》。它连接具有相同强度的点,同时在修复区域的边界匹配梯度向量。 此方法使用流体动态算法:
import numpy as np
import cv2 as cv
img = cv.imread('/home/.../krish_black.JPG')
mask = cv.imread('/home/.../krish_white.JPG',0)
dst = cv.inpaint(img,mask,3,cv.INPAINT_NS)
cv.imshow('dst',dst)
cv.waitKey(0)
cv.destroyAllWindows()下图显示了最终输出:

如我们所见,这两个预测都部分成功,但并未完全删除该行。
了解神经样式迁移
神经样式迁移是一种技术,您可以通过匹配内容图像和样式图像的特征分布来混合它们,以生成与内容图像相似但在艺术上以样式化的图像样式绘制的最终图像。 可以在 TensorFlow 中以两种不同方式完成样式迁移:
- 在 TensorFlow Hub 中使用预训练的模型。 这是您上传图像和样式的地方,该工具包将生成样式输出。 您可以在这个页面上上传图像。 请注意,TensorFlow Hub 是许多预训练网络的来源。
- 通过训练神经网络来开发自己的模型。 为此,请按照下列步骤操作:
- 选择 VGG19 网络-它具有五个卷积(
Conv2D)网络,每个Conv2D具有四层,然后是全连接层。 - 通过 VGG19 网络加载内容图像。
- 预测前五个卷积。
- 加载没有顶层的 VGG19 模型(类似于我们在“第 6 章”,“使用迁移学习的视觉搜索”中所做的工作),并列出该层的名称。
- VGG19 中的卷积层具有特征提取功能,而全连接层执行分类任务。 如果没有顶层,则网络将仅具有顶层五个卷积层。 从前面的章节中我们知道,初始层传达原始图像的输入像素,而最终层捕捉图像的定义特征和图案。
- 这样,图像的内容就由中间特征映射表示–在这种情况下,这是第五个卷积块。
- 选择 VGG19 网络-它具有五个卷积(
gram 矩阵是向量G = I[i]^T I[j]的内积的矩阵。 在此,I[i]和I[j]是原始图像和样式图像的特征向量。 内积代表向量的协方差,代表相关性。 这可以用样式来表示。
以下代码输入一个 VGG 模型,并从该模型中提取样式和内容层:
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
vgg.trainable = False
for layer in vgg.layers:
print(layer.name)以下结果显示了卷积块及其顺序:
input_2
block1_conv1
block1_conv2
block1_pool
block2_conv1
block2_conv2
block2_pool
block3_conv1
block3_conv2
block3_conv3
block3_conv4
block3_pool
block4_conv1
block4_conv2
block4_conv3
block4_conv4
block4_pool
block5_conv1
block5_conv2
block5_conv3
block5_conv4
block5_pool我们将使用从前面的输出生成的卷积结果来开发内容层和样式层,如以下代码所示:
#Content layer: content_layers = ['block5_conv2']
#Style layer: style_layers = ['block1_conv1','block2_conv1','block3_conv1', 'block4_conv1', 'block5_conv1']
style_outputs = [vgg.get_layer(name).output for name in style_layers]
content_outputs = [vgg.get_layer(name).output for name in content_layers]
vgg.input = style_image*255输入的四个维度是批量大小,图像的宽度,图像的高度和图像通道的数量。 255 乘数将图像强度转换为 0 到 255 的比例:
model = tf.keras.Model([vgg.input], outputs)如前所述,这种样式可以用克矩阵表示。 在 TensorFlow 中,gram 矩阵可以表示为tf.linalg.einsum。
因此,我们可以编写以下代码:
for style_output in style_outputs:
gram_matrix = tf.linalg.einsum(‘bijc,bijd->bcd’, style_outputs,style_outputs)/tf.cast(tf.shape(style_outputs[1]*style_outputs[2]))损失计算如下:
style_loss = tf.add_n([tf.reduce_mean((style_outputs[name]-style_targets[name])**2) for name in style_outputs.keys()]) style_loss *= style_weight / num_style_layers
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name]-content_targets[name])**2) for name in content_outputs.keys()])
content_loss *= content_weight / num_content_layers
loss = style_loss + content_loss
可以从 TensorFlow 教程中获得最终代码。 代码结构如此处所述。 我在以下图像上运行它,其输出如下:

请注意,图像输出如何从沙漠中的少量石粒过渡到完全充满石头,同时又保持了沙漠的某些结构。 最后的迭代(迭代 1,000)确实显示出一种艺术融合。
总结
在本章中,我们学习了如何使用 TensorFlow 2.0 和 Google Colab 训练神经网络来执行许多复杂的图像处理任务,例如语义分割,图像修复,生成人工图像和神经样式迁移。 我们了解了生成器网络和判别器网络的功能,以及如何可以平衡地同时训练神经网络以创建伪造的输出图像。 我们还学习了如何使用空洞卷积,空间池和编码器/解码器网络来开发语义分割。 最后,我们使用 Google Colab 训练了一个神经网络来执行神经样式迁移。
在下一章中,我们将使用神经网络进行活动识别。