系列介绍:文本挖掘比较常见,系列思路:1-基本情况介绍(分词,词云展示);2-根据语料库的tf-idf值及创建自己的idf文件;3-基于snownlp语料情感分析;4-基于gensim进行lda主题挖掘分析;
本文简介:对于大量的短文本需要进行分析的话,会使用到分词及可视化展示,中文分词没有明显的边界自行处理还不太方便。“结巴”中文分词是一个优秀的 Python 中文分词库,wordcloud是一个词云图库,对他进行学习,可以快速进行基础的文本分析。
目的:介绍jieba库(v0.41)的基本使用,并结合分词结果进行词云展示
读者:应用用户。
参考链接:
jieba官方介绍:https://github.com/fxsjy/jieba/blob/master/README.md
[python] 使用scikit-learn工具计算文本TF-IDF值:https://blog.csdn.net/eastmount/article/details/50323063
Jieba分词词性标注以及词性说明:https://www.cnblogs.com/zhenyauntg/p/13206473.html
主要内容:
1、jieba库基本使用
1.1、分词
1.2、添加自定义词典
1.3、词性标注
1.4、基于TF-IDF算法的关键字抽取
2、jieba+wordcloud简单分析
1、jieba库基本使用
import jieba # 分词库
import jieba.posseg as pseg # 词性标注
import jieba.analyse as analyse # 关键字提取1.1、分词
jieba库分词有三种模型,一般来说,使用默认模式即可。
content = "韩国东大门单鞋女方头绒面一脚蹬韩版休闲2020春季新款平底毛毛鞋"seg_list = jieba.cut(content, cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式seg_list = jieba.cut(content, cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 默认模式
seg_list = jieba.cut_for_search("韩国东大门单鞋女方头绒面一脚蹬韩版休闲2020春季新款平底毛毛鞋") # 搜索引擎模式
print("Search Mode: " + "/ ".join(seg_list))
输出:
Full Mode: 韩国/ 东大/ 东大门/ 大门/ 单鞋/ 女方/ 方头/ 绒面/ 一脚/ 脚蹬/ 韩/ 版/ 休闲/ 2020/ 春季/ 新款/ 平底/ 毛毛/ 鞋
Default Mode: 韩国/ 东大门/ 单鞋/ 女方/ 头/ 绒面/ 一/ 脚蹬/ 韩版/ 休闲/ 2020/ 春季/ 新款/ 平底/ 毛毛/ 鞋
Search Mode: 韩国/ 东大/ 大门/ 东大门/ 单鞋/ 女方/ 头/ 绒面/ 一/ 脚蹬/ 韩版/ 休闲/ 2020/ 春季/ 新款/ 平底/ 毛毛/ 鞋1.2、添加自定义词典
以"Default Mode"输出为例,毛毛鞋被拆分成了毛毛和鞋两个部分,原因是P(毛毛鞋) < P(毛毛)×P(鞋),“毛毛鞋”词频不够导致其成词概率较低。
有两个方法可以添加自定义词典,添加自定义字典并不会替换自带的词典,会追加上去。其他自定义也是。
一个是载入词典:
jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径词典格式和 dict.txt(jiaba包文件夹下) 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。另一个是动态调整:
使用 add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典。使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
注意:自动计算的词频在使用 HMM 新词发现功能时可能无效。
删除该词 jieba.del_word('今天天气')
现在采用动态调整词典后,毛毛鞋能正确识别。
jieba.add_word('毛毛鞋', freq=None, tag=None)
seg_list = jieba.cut(content, cut_all=False)
print("Update Default Mode: " + "/ ".join(seg_list)) # 默认模式Update Default Mode: 韩国/ 东大门/ 单鞋/ 女方/ 头/ 绒面/ 一/ 脚蹬/ 韩版/ 休闲/ 2020/ 春季/ 新款/ 平底/ 毛毛鞋1.3、词性标注
在老版本中,词性标注采用的字典会与jieba.cut不一致,新版本已修复。
# 词性标注
words = pseg.cut(content)
print("词性标注: " + "/ ".join([word + '-' + flag for word, flag in words])) 词性标注: 韩国-ns/ 东大门-x/ 单鞋-n/ 女方-n/ 头-n/ 绒面-n/ 一-m/ 脚蹬-n/ 韩版-nt/ 休闲-v/ 2020-m/ 春季-t/ 新款-n/ 平底-t/ 毛毛鞋-x1.4、基于TF-IDF算法的关键字抽取
简单的词频统计并不能很好的反映词的重要性,tf-idf是一个识别关键字的算法。大概思路如下:
一个容易想到的思路,就是找到出现次数最多的词。如果某个词很重要,它应该在这篇文章中多次出现。于是,我们进行"词频"(Term Frequency,缩写为TF)统计。结果你肯定猜到了,出现次数最多的词是----"的"、"是"、"在"----这一类最常用的词。它们叫做"停用词"(stop words),表示对找到结果毫无帮助、必须过滤掉的词。
假设我们把它们都过滤掉了,只考虑剩下的有实际意义的词。这样又会遇到了另一个问题,我们可能发现"zg"、"蜜蜂"、"养殖"这三个词的出现次数一样多。这是不是意味着,
作为关键词,它们的重要性是一样的?显然不是这样。因为"zg"是很常见的词,相对而言,"蜜蜂"和"养殖"不那么常见。如果这三个词在一篇文章的出现次数一样多,有理由
认为,"蜜蜂"和"养殖"的重要程度要大于"zg",也就是说,在关键词排序上面,"蜜蜂"和"养殖"应该排在"zg"的前面。所以,我们需要一个重要性调整系数,衡量一个词是
不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。用统计学语言表达,就是在词频的基础上,要对每个词分配一个"重要性"权重。最常见的词("的"、"是"、"在")给予最小的权重,较常见的词("zg")给予较小的权重,较少
见的词("蜜蜂"、"养殖")给予较大的权重。这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
知道了"词频"(TF)和"逆文档频率"(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,
就是这篇文章的关键词。

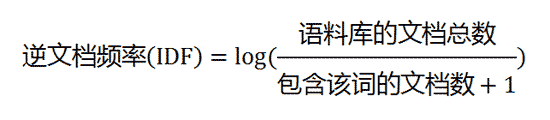

介绍完基本的思路以后,这里我们发现有两个文件,一个是停用词,一个是idf值。jieba库默认有一些基本的停用词及idf文件(jieba\analyse\idf.txt)。
# jieba\analyse\tfidf.py
STOP_WORDS = set((
"the", "of", "is", "and", "to", "in", "that", "we", "for", "an", "are",
"by", "be", "as", "on", "with", "can", "if", "from", "which", "you", "it",
"this", "then", "at", "have", "all", "not", "one", "has", "or", "that",
))那么jieba计算tf-idf的值的过程,大致为,讲输入的文档进行分词并计算tf值,通过已经生成好的idf文件获取相应单词的idf值,如果没有,使用中位数值。
如自定义词典,停用词和idf文档也可以自定义。
jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径最后的使用:
# topK:输入前topK个关键字,为None则输出全部withWeight:是否返回权重
allowPOS:只计算哪类词性,'n','v','ns'
withFlag:是否返回词性标注
tfidf_fre =analyse.extract_tags(content, topK=20, withWeight=True, allowPOS=(),withFlag=True)
df = pd.DataFrame(data=tfidf_fre,columns=['单词','tf-idf'])
print(tfidf_fre)
关键字提取: [('单鞋', 1.0159638824153847), ('东大门', 0.9195975002230768), ('韩版', 0.9195975002230768), ('2020', 0.9195975002230768), ('毛毛鞋', 0.9195975002230768), ('绒面', 0.8781362309384615), ('平底', 0.8157569835384616), ('脚蹬', 0.7435823959523076), ('新款', 0.6984920066438461), ('女方', 0.6978741472823077), ('休闲', 0.6547389170892307), ('春季', 0.6055691639807692), ('韩国', 0.5340907908538461)]2、jieba+wordcloud简单分析
最后做一个简单的应用分析。数据使用“2019年新年贺词.txt"。文档如下。
# 数据读取
with open('2019新年贺词.txt','r') as f :
text = f.read()# 统计词频函数
def jieba_count_tf(words,is_filter_stop_words = True):
stop_words = []
if is_filter_stop_words:
# 获取Jieba库载入的停用词库
stop_words = analyse.default_tfidf.stop_words
freq = {}
for w in words:
if len(w.strip()) < 2 or w.lower() in stop_words:
continue
freq[w] = freq.get(w, 0.0) + 1.0
# 总词汇数量
total = sum(freq.values())
return freqwords = jieba.cut(text, cut_all=False)
tfs = jieba_count_tf(words,is_filter_stop_words = False)形成表格数据
df = pd.DataFrame(data=list(zip(list(tfs.keys()),list(tfs.values()))),columns=['单词','频数'])
df
# 关键字分析
tfidf_fre =analyse.extract_tags(text, topK=100, withWeight=True, allowPOS=(),withFlag=True)形成表格数据
df = pd.DataFrame(data=tfidf_fre,columns=['单词','tf-idf'])
# 生成词云图展示
alice_mask = np.array(Image.open('test.png')) # 使用图片作为背景
font_path='C:\Windows\Fonts\simfang.ttf' # 设置文本路径创建图云对象
wc = WordCloud(font_path=font_path, background_color='white',mask = alice_mask,width=400, height=200,stopwords = None)
wc.fit_words(dict(zip(df['单词'], df['tf-idf']))) # 输入词频字典,或者 {词:tf-idf}
wc_img = wc.to_image() # 输出为图片对象
wc.to_file("alice.png")

结论,从初步的新年贺词的展示来看,贺词中主要关注点为tuop,预示着对tuop攻坚战的祝福和肯定。
同时,从词汇的展示中,一些如同“我们”,“他们”,“大家”的一些停用词没有去掉,可以参考1.3添加停用词典,或在词云对象中添加停用词列表。
更新后如下:

更新以后,关键字更加明显。“ggkf”、“发展”等词汇要凸显了出来。祝祖国繁荣昌盛。
总结:
1、需要拥有一个好的词典,不同场景应使用不同词典。
2、一个好的停用词典。
3、一个较广的idf文件,可进一步自行构建idf文件。