文本挖掘(一)python jieba+wordcloud使用笔记+词云分析应用
系列介绍:文本挖掘比较常见,系列思路:1-基本情况介绍(分词,词云展示);2-根据语料库的tf-idf值及创建自己的idf文件;3-基于snownlp语料情感分析;4-基于gensim进行lda主题挖掘分析;

文本挖掘(一)python jieba+wordcloud使用笔记+词云分析应用
系列介绍:文本挖掘比较常见,系列思路:1-基本情况介绍(分词,词云展示);2-根据语料库的tf-idf值及创建自己的idf文件;3-基于snownlp语料情感分析;4-基于gensim进行lda主题挖掘分析;

拿来就用能的Python词云图代码|wordcloud生成词云详解
词云也叫文字云,是一种可视化的结果呈现,常用在爬虫数据分析中,原理就是统计文本中高频出现的词,过滤掉某些干扰词,将结果生成一张图片,直观的获取数据的重点信息。今天,我们就来学习一下Python生成词云的常用库「wordcloud」。
【数据挖掘 | 可视化】 WordCloud 词云(附详细代码案例)
📷
🤵♂️ 个人主页: @计算机魔术师
👨💻 作者简介:CSDN内容合伙人,全栈领域优质创作者。
开发环境
编辑器: jupyter notebook
解释器: python 3.7
在七夕节中,博主写了一篇为女友收集QQ聊天记录做可视化词云的文章获得广泛好评,一直有小伙伴希望能出一篇教程,今天他来啦! 一文带你速通词云🙋♂️
文章链接 — Python | 词云】聊天记录绘制超美词云(七夕快乐 ,曾同学)
📷
后面生成的图片是有些显示违规或奇怪(因为我是用核心价值观作为词库的,所以会被

【数据挖掘 | 可视化】 WordCloud 词云(附详细代码案例)
📷
🤵♂️ 个人主页: @计算机魔术师
👨💻 作者简介:CSDN内容合伙人,全栈领域优质创作者。
开发环境
编辑器: jupyter notebook
解释器: python 3.7
在七夕节中,博主写了一篇为女友收集QQ聊天记录做可视化词云的文章获得广泛好评,一直有小伙伴希望能出一篇教程,今天他来啦! 一文带你速通词云🙋♂️
文章链接 — Python | 词云】聊天记录绘制超美词云(七夕快乐 ,曾同学)
📷
后面生成的图片是有些显示违规或奇怪(因为我是用核心价值观作为词库的,所以会被

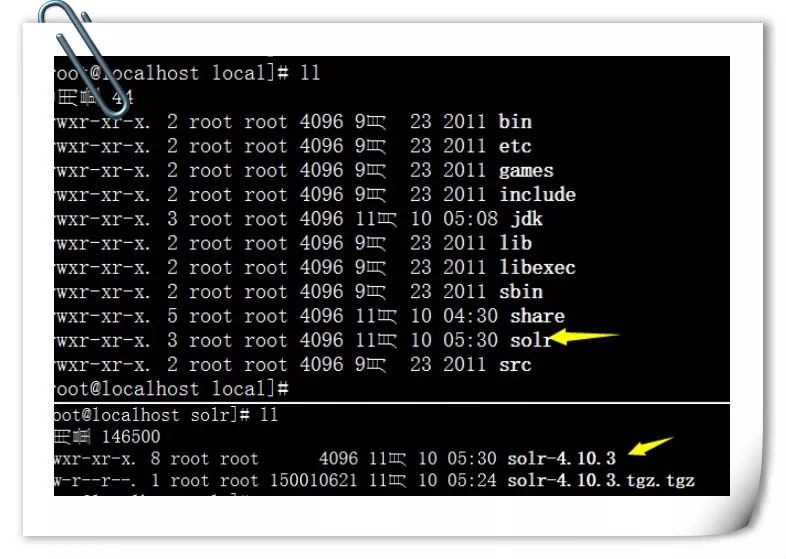
腾讯云-Solr企业级搜索引擎实战
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
【Python | 词云】聊天记录绘制超美词云(七夕快乐 ,曾同学)
本次聊天记录是收集于我和曾同学QQ一年以来的聊天记录,一起看看你们情侣间说过最多的是哪句话吧!

分析B站弹幕,川普同志暴露的那一天,没有一个鬼畜up是无辜的
B站作为一个弹幕视频网站,有着所谓的弹幕文化,那么接下来我们看看,一个视频中出现最多的弹幕是什么?

全文检索工具solr:第一章:理论知识
大多数搜索引擎应用都必须具有某种搜索功能,问题是搜索功能往往是巨大的资源消耗并且它们由于沉重的数据库加载而拖垮你的应用的性能。
中文世界又多一个评测语言大模型能力的基准CUGE,覆盖17种主流NLP任务
在自然语言处理(NLP)领域,预训练模型刷榜已经成为行业惯例。目前,面向英文任务的评测基准有 GLUE、SuperGLUE,面向中文任务的有 ChineseGLUE(简称 CLUE)。

大数据工具:IKAnalyzer分词工具介绍与使用
为什么要分词呢,当大数据处理中要提取语句的特征值,进行向量计算。所有我们要用开源分词工具把语句中的关键词提取出来。
修改WordPress 文章内分页样式
最近写了一篇比较长的隐私文章,用到了wp的文章分页功能。却发现默认的分页的页面又小又难找。于是想修改wp的默认分页,网上找了下相关的代码基本都是下面的样子:
修改WordPress 文章内分页样式
最近写了一篇比较长的隐私文章,用到了wp的文章分页功能。却发现默认的分页的页面又小又难找。于是想修改wp的默认分页,网上找了下相关的代码基本都是下面的样子:
不知道给女朋友买什么 ?让爬虫告诉你 !
你是否曾经遇到过要给女朋友、父母、好朋友送礼物却不知道买什么的情况?小编作为一个直男,每次都在给朋友选礼物的事情上费劲脑筋,实在是不知道买什么东西好。但事情总是要解决,小编萌生了一个想法,在某购物网站搜索关键字,然后将搜索结果进行词频分析,这样不就知道有什么东西是大家买的比较多的了么?说干咱就干。
得物词分发平台技术架构建设与演进
在文章开始前先介绍下导购,导购通常是指帮助消费者在购物过程中做出最佳决策的人或系统。在电商网站中,导购可以引导用户关注热卖商品或促销活动等,帮助用户更好地进行购物。导购的目的是为了提高用户的购物体验,促进销售额的增长。

Solr和Spring Data Solr
Solr是一个开源搜索平台,用于构建搜索应用程序。 它建立在Lucene(全文搜索引擎)之上。 Solr是企业级的,快速的和高度可扩展的。Solr可以和Hadoop(http://www.yiibai.com/hadoop/)一起使用。由于Hadoop处理大量数据,Solr帮助我们从这么大的源中找到所需的信息。不仅限于搜索,Solr也可以用于存储目的。像其他NoSQL数据库一样,它是一种非关系数据存储和处理技术。总之,Solr是一个可扩展的,可部署,搜索/存储引擎,优化搜索大量以文本为中心的数据。

Lucene 和 Kibana、ElasticSeach、Spring Data ElasticSearch
结构化数据 - 行数据,可以用二维表结构来逻辑表达实现的数据;指具有固定格式或有限长度的数据,如数据库,元数据等。
Lucene 全文检索
全文检索就是先分词创建索引,再执行搜索的过程。分词就是将一段文字分成一个个单词。全文检索就将一段文字分成一个个单词去查询数据

轻量级中文分词器
6、自动词性标注:基于词库+(统计歧义去除计划),目前效果不是很理想,对词性标注结果要求较高的应用不建议使用。
【全文检索_03】Lucene 基本使用
在上一文 【全文检索_02】Lucene 入门案例 中我们使用 Lucene 默认分词器对中文版双城记进行分词,这个操作其实是有问题的。哎?!我们明明分词成功而且搜索到了啊,怎么会有问题。我们之前成功搜索是因为我们搜索的是一个关键字,而不是一个关键词。我们先来看一下默认分词器的分词效果是怎么样的。
